자동 연구 시스템을 볼 때 가장 위험한 착시는 “논문 형태의 문서가 나왔다”를 “연구가 됐다”로 착각하는 것이다. 실제 연구는 훨씬 더 지저분하다. 가설은 서로 충돌하고, 실험은 깨지고, 코드가 돌아가도 결과가 질문에 답하지 못할 수 있으며, 마지막 논문 문장은 실험 로그에 없는 숫자를 그럴듯하게 끼워 넣을 수 있다.
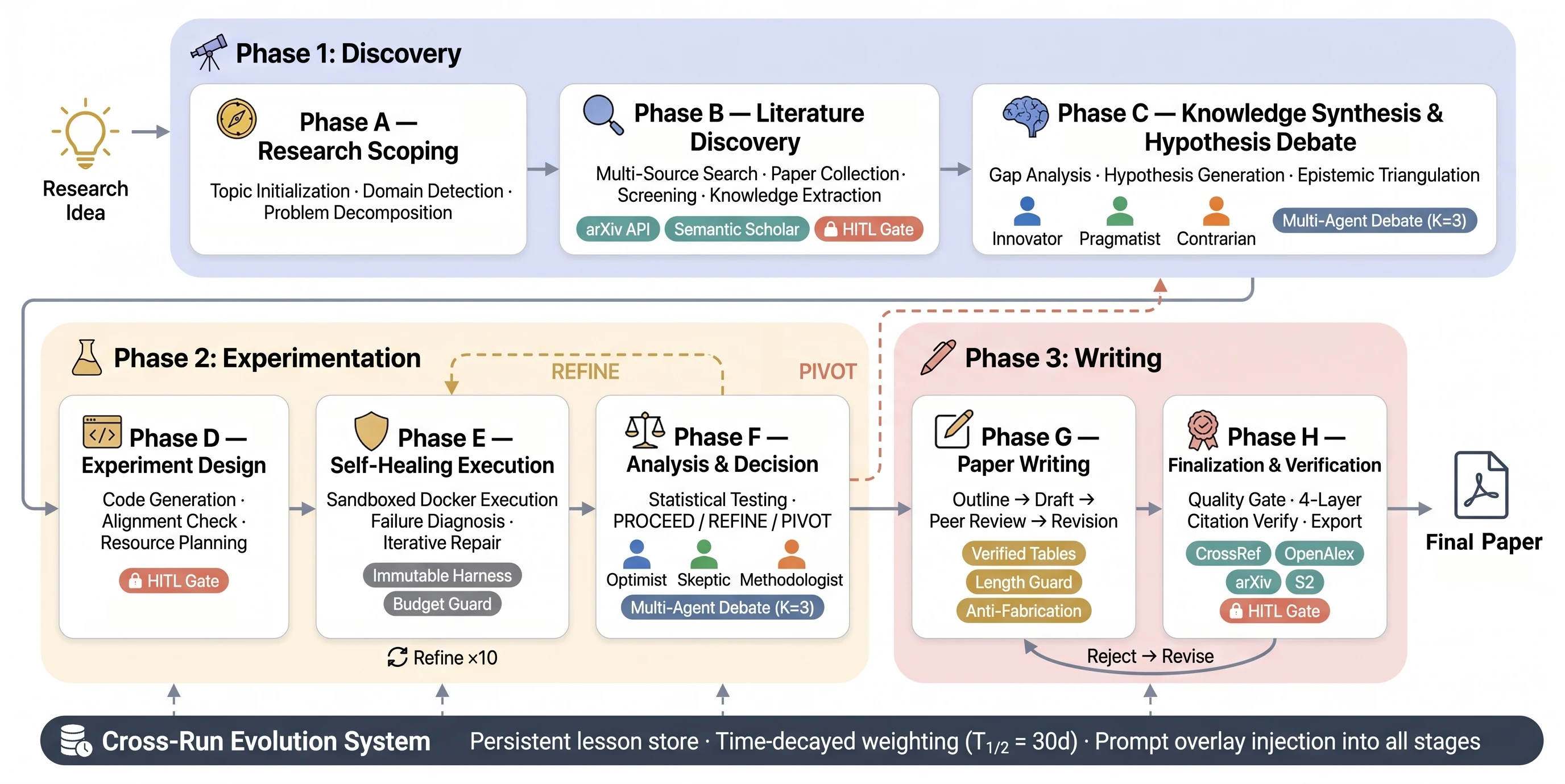
AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration는 이 문제를 정면으로 다룬다. 이 논문은 자동 연구를 단일 LLM의 긴 글쓰기 능력으로 보지 않고, 가설 생성, 문헌 수집, 코드 실행, 실패 수습, 결과 검증, 논문 작성, 인용 확인이 이어지는 23-stage 연구 운영체제로 재구성한다. 핵심은 완전 자율 그 자체가 아니라, 실패와 검증을 pipeline의 일급 객체로 만드는 데 있다.
흥미로운 점은 이름처럼 “self-reinforcing”이 단순한 마케팅 문구가 아니라는 것이다. AutoResearchClaw는 한 번의 연구 run에서 나온 실패, 경고, lesson을 다음 run의 prompt overlay와 skill 형태로 다시 주입한다. 즉 매번 빈 상태에서 “논문 한 편 생성”을 시도하는 시스템이 아니라, 반복 실행을 통해 어떤 실패를 피해야 하는지 축적하는 research agent stack에 가깝다.
무엇을 해결하려는가
기존 autonomous research 시스템의 약점은 보통 세 가지로 압축된다. 첫째, 단일 agent가 스스로 낸 가설을 스스로 정당화하면서 confirmation bias가 생긴다. 둘째, 실험 실행이 실패하면 전체 run이 멈추거나, 실패에서 얻은 정보를 다음 시도로 제대로 넘기지 못한다. 셋째, 논문 작성 단계에서 실제 측정값과 존재하는 인용만 사용했다는 보장이 약하다.
AutoResearchClaw는 이 세 병목을 하나의 pipeline 설계 문제로 본다. 좋은 자동 연구 시스템은 좋은 문장을 생성하는 모델이 아니라, 반박하는 agent, 복구 가능한 실행 환경, 검증 가능한 metric registry, human gate, cross-run memory를 함께 가진 시스템이어야 한다는 것이다.
논문이 잡은 목표도 꽤 구체적이다. 한 줄의 연구 아이디어를 받아 문헌 조사, 가설 토론, 실험 설계, sandbox 실행, 결과 분석, 논문 초안, peer review, revision, export, citation verification까지 연결한다. 하지만 저자들은 이를 “연구자 대체”로 포장하지 않는다. 오히려 인간이 어디에서 개입해야 품질이 올라가는지, 그리고 어떤 검증 장치를 넣어야 자동화가 과학적 integrity를 덜 해치는지를 실험한다.
핵심 아이디어 / 구조 / 동작 방식
AutoResearchClaw의 구조는 23개 stage를 8개 phase로 나누는 긴 pipeline이다. 크게 보면 discovery, experimentation, writing이라는 세 구간이 있고, 그 아래에 research scoping, literature discovery, hypothesis debate, experiment design, self-healing execution, analysis & decision, paper writing, finalization & verification이 들어간다.
핵심 구성요소를 더 좁히면 다섯 가지다.
| 구성요소 | 논문에서의 역할 | 실무적으로 읽히는 의미 |
|---|---|---|
| Multi-agent debate | hypothesis generation과 result analysis에서 서로 다른 역할 agent가 반박·종합 | 단일 LLM의 자기확증을 줄이고, feasibility와 confound를 초기에 드러낸다 |
| Self-healing execution | runtime error, degenerate result, weak evidence를 진단하고 refine/pivot 결정 | 실패를 termination이 아니라 research signal로 취급한다 |
| Verified result reporting | 측정값 registry와 citation verification으로 숫자·인용을 제한 | “그럴듯한 논문”보다 “로그에 근거한 논문”을 우선한다 |
| HITL collaboration | gate-only, co-pilot, step-by-step 등 여러 개입 regime | 사람을 모든 단계에 붙이는 대신 high-leverage 지점에 배치한다 |
| Cross-run evolution | 과거 실패 lesson을 skill/prompt overlay로 다음 run에 주입 | 매번 같은 실패를 반복하지 않는 연구 memory layer를 만든다 |
Multi-agent debate는 두 지점에서 특히 중요하다. 가설 단계에서는 Innovator, Pragmatist, Contrarian이 각각 고위험 아이디어, 실행 가능성, 반례와 confound를 본다. 결과 분석 단계에서는 Optimist, Skeptic, Methodologist가 강한 발견, 통계적 약점, 재현성·data leakage 가능성을 나눠 검토한다. 즉 agent 수를 늘리는 것이 아니라, 어떤 인식론적 역할을 분리할 것인가가 설계의 핵심이다.
Self-healing 쪽은 더 엔지니어링에 가깝다. 실험 계획의 복잡도를 보고 외부 coding agent나 내부 code agent로 분기하고, AST validation과 security scan을 거친 뒤 sandbox에서 실행한다. 실패하면 원인을 진단하고, 방향이 유효하면 refine하며, 근본적으로 잘못된 접근이면 pivot한다. 논문 기준 refine은 최대 10회, pivot은 최대 2회까지 허용된다.
마지막으로 writing 단계는 단순한 summarization이 아니다. 논문은 verified table injection, length guard, anti-fabrication, four-layer citation verification을 결합한다. 저자들의 framing은 분명하다. AI가 논문 문장을 유창하게 쓰는 능력보다, 그 문장이 실제 실행 로그와 실제 인용에 묶여 있는지가 더 중요하다.
공개된 근거에서 확인되는 점
가장 직접적인 실험은 ARC-Bench다. 논문은 25개 topic으로 구성된 experiment-stage benchmark에서 AutoResearchClaw를 AI Scientist v2와 AIDE-ML에 비교한다. 모든 framework는 같은 LLM backbone과 같은 sandbox execution 환경을 사용했다고 설명한다.
| Framework | Code Dev | Code Exec | Result Analysis | Overall |
|---|---|---|---|---|
| AutoResearchClaw (CoPilot) | 0.968 | 0.578 | 0.523 | 0.648 |
| AutoResearchClaw (Full-Auto) | 0.938 | 0.562 | 0.442 | 0.596 |
| AIDE-ML | 0.958 | 0.415 | 0.336 | 0.511 |
| AI Scientist v2 | 0.712 | 0.442 | 0.261 | 0.419 |
논문이 강조하는 수치는 CoPilot이 AI Scientist v2보다 overall strict score 기준 54.7%, AIDE-ML보다 26.8% 높다는 점이다. 더 중요한 차이는 result analysis다. CoPilot은 0.523으로 AI Scientist v2의 0.261 대비 약 100.4% 상대 개선을 보인다. 이 축은 “결론이 hypothesis와 맞는가”, “표에 verified number만 들어가는가”, “한계를 정직하게 말하는가”를 본다는 점에서 AutoResearchClaw의 설계 철학과 직접 연결된다.
HITL ablation은 더 흥미롭다. 완전 자율이 항상 최선도 아니고, 모든 단계에 사람이 붙는 step-by-step도 최선이 아니다.
| Mode | Valid | Mean Quality | Accept | Interventions |
|---|---|---|---|---|
| Full-Auto | 8/10 | 4.03 | 25.0% | 0 |
| Gate-Only | 10/10 | 5.03 | 50.0% | 3 |
| CoPilot | 8/10 | 7.27 | 87.5% | 6 |
| Thorough | 7/10 | 4.86 | 42.9% | 8 |
| Step-by-Step | 10/10 | 5.19 | 50.0% | 23 |
| Pre-Experiment | 8/10 | 4.28 | 37.5% | 3 |
| Post-Experiment | 6/10 | 5.08 | 50.0% | 3 |
이 표의 메시지는 꽤 강하다. 인간 개입의 양이 아니라 위치가 중요하다. CoPilot은 6번의 개입으로 가장 높은 품질과 accept rate를 보였고, step-by-step은 23번 개입했지만 50% accept에 그쳤다. 연구 agent 설계에서 “모든 단계 승인”은 안전해 보이지만, 실제로는 context switching과 저품질 승인 누적 때문에 좋은 실험 설계를 보장하지 못할 수 있다.
Cross-domain 실험도 있다. ARC-Bench core는 ML 중심이지만, 논문은 biology, statistics, high-energy physics phenomenology로 확장한 20개 science-domain task를 추가한다. AutoResearchClaw CoPilot은 biology 0.912, statistics 0.898, HEP-ph 0.489, run-weighted overall 0.867을 보고한다. 특히 biology는 COBRApy와 BiGG genome-scale model, HEP는 FeynRules/MadGraph/MadAnalysis 같은 domain-specific stack을 쓰는 agent를 sandbox 안에 넣는 방식이다.
다만 이 결과는 “모든 과학 도메인이 같은 수준으로 자동화됐다”는 뜻은 아니다. HEP-ph 점수는 biology/statistics보다 낮고, 일부 domain-specific software stack은 설치·실행·정량 재현성에서 훨씬 까다롭다. 오히려 실무적으로는 AutoResearchClaw가 잘하는 부분과 아직 취약한 부분을 동시에 보여 준다. domain adapter와 sandboxed specialist agent가 없으면 cross-domain research automation은 쉽게 표면적인 글쓰기로 후퇴한다.
Component ablation도 설계 의도를 뒷받침한다.
| Configuration | Completion | Quality | Accept | Fabrication |
|---|---|---|---|---|
| Full AutoResearchClaw | 10/10 | 5.62 | 3/10 | 없음 |
| w/o Debate | 10/10 | 4.25 | 1/10 | 없음 |
| w/o Self-Healing | 6/10 | 4.83 | 1/6 | 없음 |
| w/o Evolution | 9/10 | 5.14 | 2/10 | 없음 |
| w/o Verification | 10/10 | 5.48 | 5/10 | 있음 |
| w/o Debate & Healing | 4/10 | 3.47 | 0/4 | 없음 |
여기서 가장 중요한 줄은 w/o Verification이다. 검증을 제거하면 겉보기 accept는 5/10으로 올라가지만, manual audit에서 accepted paper 중 일부가 measurement record에 없는 값을 포함했다고 보고된다. 즉 verification gate는 점수를 높이는 장치가 아니라, 높아 보이는 점수를 일부러 깎아서라도 fabricated result를 막는 integrity layer다.

T10 case study는 이 논문의 실용적 메시지를 잘 보여 준다. Full-Auto는 manuscript를 만들었지만, 8개 cross-validation strategy가 모두 0.0 bias를 보고해 사실상 비교가 불가능했다. 이는 fabrication은 아니지만 과학적으로는 비정보적인 결과다. 반면 CoPilot은 human guidance가 “전략들이 실제로 다른 값을 내는지 확인하라”, “LOOCV가 시간 예산에 맞는지 보라”, “로그에 없는 metric을 주장하지 말라”는 식으로 실험 병목을 겨냥했고, 결과적으로 9개 pipeline에서 구분 가능한 bias 값을 보고했다.
공개 구현 상태도 확인할 만하다. 공식 GitHub 저장소 aiming-lab/AutoResearchClaw는 Python 기반이며 MIT license로 공개되어 있다. GitHub API 확인 시점 기준 stars 12,330, forks 1,442, default branch는 main이고, latest release는 v0.4.0: Human-in-the-Loop Co-Pilot System이다. README는 OpenAI-compatible API뿐 아니라 Claude Code, Codex CLI, Gemini CLI, Kimi CLI 같은 ACP-compatible agent backend와 OpenClaw bridge를 통한 Discord/Telegram/Lark/WeChat 실행 흐름도 설명한다.
동시에 연구 코드 특유의 빠른 변화도 보인다. README는 v0.4.0 HITL 기능과 2,699 tests passed badge를 내세우지만, researchclaw/__init__.py의 package version은 0.3.1로 남아 있다. 즉 공개 surface는 꽤 풍부하고 실행 가이드는 있지만, 안정적인 product package라기보다는 빠르게 진화 중인 research framework / agent workflow bundle로 읽는 편이 안전하다.
실무 관점에서의 해석
내가 보기에 AutoResearchClaw의 핵심 가치는 “AI가 논문을 쓴다”는 데 있지 않다. 더 중요한 변화는 연구 agent의 평가 기준을 문서 생성 능력에서 실행·검증·복구·기억 능력으로 옮긴다는 점이다. 좋은 research agent는 fluent draft를 뽑는 모델이 아니라, 실패한 실험을 버리지 않고 다음 action으로 번역하며, 결과를 registry에 묶고, 인간이 개입해야 할 지점을 드러내는 시스템이다.
이 관점은 실제 연구 조직에도 바로 연결된다. 자동화하고 싶은 것은 과학자의 판단 전체가 아니라, 반복적이고 취약한 운영 루프다. 문헌 후보를 모으고, baseline을 빠뜨리지 않게 하고, 실험 코드를 실행하고, 실패 로그를 구조화하고, 표에 들어갈 값의 provenance를 보존하고, draft가 실제 evidence를 넘어서지 않게 하는 일이다. AutoResearchClaw는 이 작업들을 하나의 workflow로 묶는 꽤 구체적인 설계안을 제시한다.
또 하나의 교훈은 HITL 설계다. 인간을 루프에 넣는다고 자동으로 안전해지지 않는다. 모든 단계에 approve 버튼을 붙이면 사람은 쉽게 피로해지고, 오히려 중요한 실험 설계 판단을 놓칠 수 있다. 논문 결과만 놓고 보면 더 좋은 방향은 문헌 screening, hypothesis/design, result semantics, writing claim, quality gate처럼 품질을 크게 좌우하는 지점에 인간 판단을 집중시키는 것이다.
물론 한계도 분명하다. ARC-Bench와 HITL 실험은 rubric-assisted judge와 scripted intervention에 의존한다. 실제 연구실의 live researcher가 장기간 협업할 때 같은 accept rate가 나올지는 별도 검증이 필요하다. 또한 verified registry가 fabricated number를 막을 수는 있어도, 그 숫자가 과학적으로 충분히 의미 있는지까지 자동으로 보장하지는 못한다. T10 사례가 보여 주듯, “로그에 있는 숫자”와 “질문에 답하는 숫자”는 다르다.
그래도 방향성은 강하다. AutoResearchClaw는 AI scientist 담론을 조금 더 현실적인 엔지니어링 문제로 끌어내린다. 연구 자동화의 미래가 있다면, 그것은 논문 생성 버튼 하나가 아니라 debate, sandbox, verifier, human gate, memory가 결합된 self-reinforcing research loop에 가까울 가능성이 높다. 그런 의미에서 이 논문과 공개 저장소는 자동 연구를 둘러싼 과장된 서사보다, 실제로 어떤 시스템 부품이 필요한지 보여 주는 꽤 중요한 reference design으로 읽힌다.