컴퓨터 사용 에이전트는 이제 마우스와 키보드를 움직이며 브라우저, 문서 편집기, 메신저, 스프레드시트 같은 실제 소프트웨어를 다루려 한다.
하지만 이 영역에서 강화학습을 하려면 한 가지 어려운 전제가 필요하다.
에이전트가 작업을 끝냈는지 결정적으로 검증할 수 있는 보상 함수가 있어야 한다는 점이다.
수학 문제나 코드 실행처럼 정답 검증이 비교적 명확한 영역과 달리, GUI 작업은 시작 상태, 목표 상태, 앱 내부 데이터, 사용자 인터페이스가 모두 맞물린다.
CUA-Gym: Scaling Verifiable Training Environments and Tasks for Computer-Use Agents는 이 병목을 정면으로 다룬다.
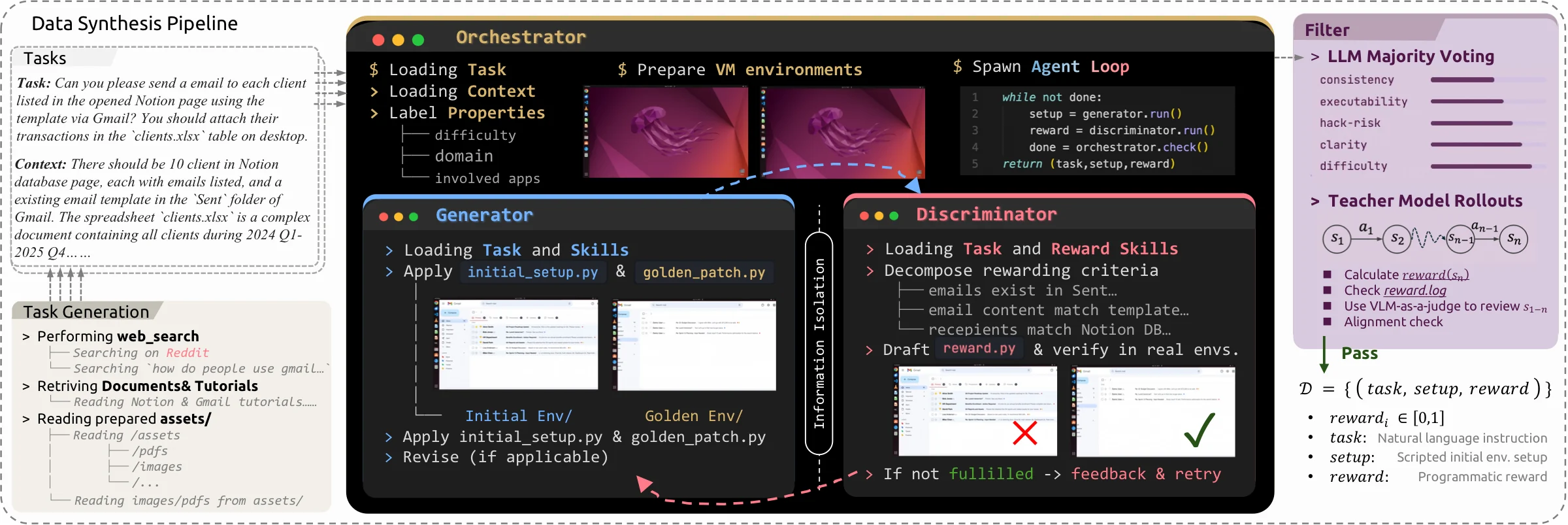
논문과 공식 저장소의 핵심 주장은 단순하다. computer-use agent용 RLVR(Reinforcement Learning with Verifiable Rewards)을 키우려면 자연어 지시만 많이 모으는 것으로는 부족하고, 매 작업마다 task instruction, executable environment, verifiable reward가 함께 맞아야 한다.
CUA-Gym은 이 삼중항을 coding agent들이 자동으로 합성하고 실행 검증하는 파이프라인이다.
무엇을 해결하려는가
CUA-Gym이 겨냥하는 문제는 CUA 학습 데이터의 검증성 부족이다. hand-curated benchmark는 reward fidelity가 높지만 앱과 작업 범위가 작다.
반대로 LLM-as-judge 기반 데이터는 더 넓게 만들 수 있지만, 보상이 확률적이고 judge bias에 흔들린다.
실제 RL 학습에서는 reward가 조금만 불안정해도 모델은 목표를 배우는 대신 보상 함수의 빈틈을 파고든다.
논문은 CUA용 RLVR 데이터 하나를 만들려면 세 가지가 동시에 필요하다고 본다.
| 구성 요소 | CUA-Gym에서의 의미 | 왜 어려운가 |
|---|---|---|
| Task instruction | 에이전트가 수행할 자연어 목표 | 실제 앱 상태와 맞지 않으면 실행 불가능한 지시가 된다 |
| Executable environment | 초기 상태와 golden target state를 재현할 수 있는 앱/파일/웹 상태 | GUI 작업은 state injection, reset, session isolation이 필요하다 |
| Verifiable reward | 완료 여부를 프로그램으로 판단하는 reward.py |
화면 캡처나 LLM judge 대신 내부 상태를 검증해야 안정적이다 |
여기서 중요한 점은 CUA-Gym이 “벤치마크 문제집”만 만들려는 것이 아니라는 것이다.
목표는 RL 학습 루프에 바로 넣을 수 있는 실행 가능한 training tuple을 대량으로 만들고, 그 결과가 OSWorld-Verified나 WebArena 같은 held-out 평가로 전이되는지를 보는 데 있다.
핵심 아이디어 / 구조 / 동작 방식
CUA-Gym의 synthesis loop는 세 역할로 나뉜다.
첫째, Generator 또는 setup-gen agent가 initial_setup.py와 golden_patch.py를 만든다.
이는 작업 전 환경 상태와 작업 완료 후의 목표 상태를 구성한다.
예를 들어 문서 편집, 스프레드시트, 메일, mock SaaS 앱 같은 환경에서 어떤 데이터가 미리 있어야 하고, 성공 시 어떤 데이터로 바뀌어야 하는지를 코드로 만든다.
둘째, Discriminator 또는 reward-gen agent가 reward.py를 작성한다.
흥미로운 설계는 Discriminator가 Generator의 코드를 보지 않고 task description만 보고 reward를 만든다는 점이다.
이 information barrier는 reward가 golden patch의 구현 세부를 역공학하는 실패를 줄이기 위한 장치다. reward는 semantic task completion을 검증해야지, Generator가 남긴 우연한 흔적을 맞히면 안 된다.
셋째, Orchestrator가 두 결과를 실행하면서 반복한다.
최종적으로 CUA-Gym은 다음 조건을 만족하는지 확인한다.
reward(golden) = 1.0
reward(initial) = 0.0
이 조건은 간단해 보이지만 중요하다. golden state에서 보상이 1이어야 하고, 초기 상태에서는 0이어야 한다.
즉 reward가 항상 1을 주는 허술한 함수도 아니고, 목표 상태를 제대로 인식하지 못하는 함수도 아니어야 한다.
이후에도 LLM majority-vote filter와 teacher rollout filter를 거쳐 reward가 fragile하거나 ambiguous한 task를 걸러낸다.
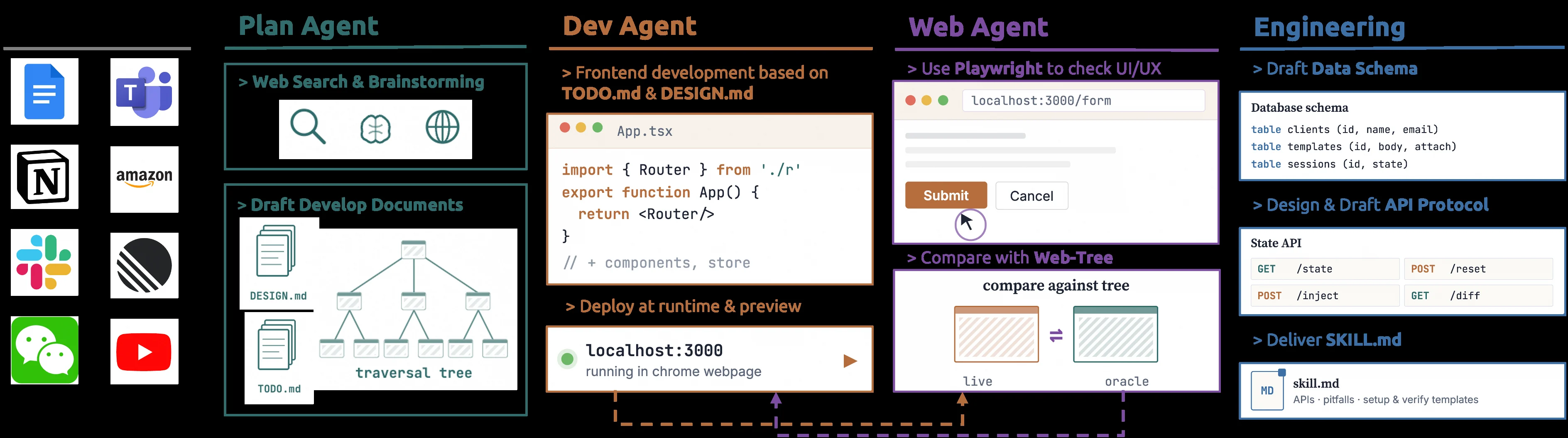
CUA-Gym-Hub는 이 파이프라인의 환경 계층이다.
공식 README는 110개 환경을 제시한다.
이 중 16개는 desktop application이고, 94개는 실제 software-use distribution을 바탕으로 합성한 mock web application이다.
각 mock web app은 session id 기반 격리, 상태 주입, 상태 조회, diff, reset 같은 API를 제공해 병렬 RL worker가 같은 앱을 쓰더라도 서로 상태가 섞이지 않도록 설계된다.

공개된 근거에서 확인되는 점
공식 project page는 CUA-Gym을 “open dataset contains 32,122 verified RLVR tuples”라고 설명한다.
반면 arXiv abstract와 README의 dataset 문단은 “32,112 verified RLVR training tuples”라고 쓴다.
같은 README의 비교 표에는 다시 32,122가 등장한다.
따라서 이 글에서는 약 3.2만 개 규모로 해석하고, 정확한 숫자는 소스별 표기가 조금 다르다는 점을 caveat로 둔다.
공식 자료에서 확인되는 핵심 스케일은 다음과 같다.
| 항목 | 공개 수치 | 해석 |
|---|---|---|
| Verified RLVR tuples | 32,112 또는 32,122 | arXiv abstract와 project page 사이 표기가 10개 차이 난다 |
| Environments | 110 | desktop + web 환경을 함께 포함 |
| Desktop applications | 16 | OSWorld류 실제 소프트웨어 작업에 가까운 축 |
| Mock web applications | 94 | CUA-Gym-Hub로 합성한 browser training environment |
| Reward type | Programmatic | LLM-as-judge가 아니라 task-specific reward.py 중심 |
README의 비교 표는 CUA-Gym을 기존 CUA RLVR 데이터셋과 이렇게 놓는다.
| Dataset | Platform | Data size | Env. size | Reward | Open |
|---|---|---|---|---|---|
| GUI-Genesis | Mobile | 969 | 1 | Programmatic | No |
| WebArena-Infinity | Web | 1,260 | 10 | Programmatic | Yes |
| InfiniteWeb | Web | 600 | — | Programmatic | No, partial |
| UltraCUA | Desktop | 17,000 | 9 | Programmatic | No, partial |
| Gym-Anything | Desktop | 7,277 | 193 | VLM | Yes |
| CUA-Gym | Desktop + Web | 32,122 | 110 | Programmatic | Yes |
성능 결과도 CUA-Gym의 메시지를 잘 보여준다.
논문 abstract와 공식 page는 GSPO로 학습한 CUA-Gym-A3B와 CUA-Gym-A17B가 OSWorld-Verified에서 각각 62.1%, 72.6%를 달성했다고 보고한다.
README의 결과 표는 WebArena에서도 각각 44.5%, 56.0%를 제시한다.
특히 A3B가 base Qwen3.5-35B-A3B의 54.5%에서 62.1%로 올라가고, A17B가 base Qwen3.5-397B-A17B의 62.2%에서 72.6%로 올라간다는 점이 핵심이다.
| Model | OSWorld-Verified | WebArena | 읽을 때의 포인트 |
|---|---|---|---|
| Qwen3.5-35B-A3B base | 54.5 | 40.8 | 같은 active-parameter scale의 출발점 |
| CUA-Gym-A3B | 62.1 | 44.5 | 작은 active model도 verifiable CUA data로 큰 폭 개선 |
| Qwen3.5-397B-A17B base | 62.2 | 54.0 | 더 큰 base지만 CUA 특화 RL 전 |
| CUA-Gym-A17B | 72.6 | 56.0 | OSWorld-Verified에서 open-source CUA SOTA로 제시 |
이 결과에서 흥미로운 부분은 환경 다양성과 데이터 수량이 함께 scaling signal을 낸다는 점이다.
단순히 더 많은 trajectory를 모으는 것이 아니라, reward가 프로그램으로 검증되고, 환경이 reset 가능하며, task가 initial/golden state와 맞아야 한다.
CUA-Gym은 이 세 조건을 자동 합성 파이프라인으로 묶으려 한다.
왜 중요한가
첫 번째 의미는 computer-use agent 학습이 이제 prompt engineering이나 imitation dataset 수집을 넘어 환경 공학 문제가 되고 있다는 점이다.
OSWorld, WebArena, Gym-Anything, CUA-Gym은 모두 조금씩 다른 각도에서 “에이전트가 실제 소프트웨어를 쓰게 하려면 환경을 어떻게 만들어야 하는가”를 묻는다.
CUA-Gym의 답은 verifiable reward를 가진 환경 삼중항을 대량 합성하는 것이다.
두 번째 의미는 reward design의 중심이 화면에서 state로 이동한다는 점이다.
GUI agent는 화면을 보고 행동하지만, reward는 화면 이미지만으로 판단하면 불안정하다.
CUA-Gym-Hub가 unified state API와 session-scoped state를 제공하는 이유도 여기에 있다. agent는 UI를 조작하고, evaluator는 내부 상태를 확인한다.
이 분리는 학습 안정성과 감사 가능성을 동시에 높인다.
세 번째 의미는 coding agent가 데이터셋 제작자로 쓰인다는 점이다.
Generator, Discriminator, Orchestrator, majority vote filter, teacher rollout filter는 모두 일종의 agentic data factory다.
사람은 개별 task를 손으로 만들기보다, 생성 파이프라인과 검증 규칙, release policy를 설계한다.
이는 Hermes나 OpenClaw식 skill/workflow 생태계에서도 중요한 패턴이다.
좋은 agent를 만들려면 agent가 연습할 수 있는 task factory와 verifier factory가 필요하다.
한계와 실무 caveat
가장 먼저 볼 caveat는 release maturity다.
GitHub README는 full pipeline과 dataset release를 공지하지만, model badge는 여전히 “Models coming soon”으로 표시한다.
Hugging Face dataset API도 공개 데이터셋을 “public preview contains a randomly sampled subset”이라고 설명하고, card의 size category는 1K<n<10K로 보인다.
즉 논문/프로젝트 페이지의 전체 3.2만 튜플 규모와, 지금 바로 Hugging Face에서 내려받아 볼 수 있는 preview release 사이에는 차이가 있을 수 있다.
두 번째 caveat는 실행 비용과 운영 복잡도다.
README의 getting started는 OPENAI_API_KEY와 ALIYUN_* credential 설정을 요구한다.
또한 web task setup/reward file 일부는 __CUA_GYM_GMAIL_URL__ 같은 placeholder endpoint를 사용하므로, 대규모 실험을 하려면 CUA-Gym-Hub mock app을 직접 배포하고 URL 변수를 materialize해야 한다.
즉 “dataset download 후 바로 모든 task를 대규모 학습에 투입”하는 형태라기보다, controlled deployment와 sandboxing이 필요한 연구 인프라에 가깝다.
세 번째 caveat는 reward overfitting이 완전히 사라지는 것은 아니라는 점이다.
Generator와 Discriminator 사이 information barrier는 중요한 완화책이지만, programmatic reward는 여전히 task specification의 모호성, state schema의 빈틈, mock app의 realism 한계에 영향을 받는다.
CUA-Gym이 majority vote와 teacher rollout filter를 추가한 것도 이 때문이다.
AI Lab 관점의 해석
CUA-Gym은 “컴퓨터 사용 에이전트가 얼마나 똑똑한가”보다 “그 에이전트를 학습시킬 수 있는 검증 가능한 세계를 얼마나 많이 만들 수 있는가”에 초점을 둔다.
이 관점은 앞으로 agent benchmark가 정적 문제집에서 생성 가능한 환경 플랫폼으로 이동한다는 신호에 가깝다.
실무적으로는 다음 세 가지 질문을 던지게 만든다.
- 우리 에이전트가 쓰는 앱/도구에는 reward를 내부 상태로 검증할 수 있는 API가 있는가.
- 한 task를 매번 깨끗한 상태에서 reset하고, 병렬 worker가 서로 오염되지 않게 session isolation할 수 있는가.
- task generator와 reward generator를 분리해 reward hacking을 줄이는 information barrier를 만들 수 있는가.
이 세 질문에 답하지 못하면 computer-use agent RL은 금방 demo 수준에 머물 가능성이 높다.
반대로 CUA-Gym처럼 task, environment, reward를 함께 설계하면, GUI 조작 능력은 단순 benchmark score가 아니라 재현 가능한 학습 루프로 바뀐다.
참고 링크
- arXiv: CUA-Gym: Scaling Verifiable Training Environments and Tasks for Computer-Use Agents
- Project page: cua-gym.xlang.ai
- GitHub: xlang-ai/CUA-Gym
- CUA-Gym-Hub: xlang-ai/CUA-Gym-Hub
- Hugging Face dataset: xlangai/CUA-Gym