LLM의 자기개선(self-improvement)을 이야기할 때 흔한 기본값은 “좋은 샘플을 많이 뽑고, verifier가 고른 것을 학습에 쓴다”는 구조다.
GRPO류의 RLVR, best-of-N sampling, Tree-of-Thoughts, MCTS, beam search는 모두 이 축 위에 있다.
문제는 어려운 과제일수록 정답 궤적이 모델 분포 안에서 낮은 확률 영역에 있고, verifier 신호도 완성된 답 근처에서만 드문드문 나온다는 점이다.
Self-Improving Language Models with Bidirectional Evolutionary Search는 이 병목을 검색 알고리즘 자체의 문제로 본다.
Harvard와 MIT 연구진이 제안한 Bidirectional Evolutionary Search(BES) 는 전방에서는 후보 reasoning/action trajectory를 생성·재조합하고, 후방에서는 목표를 더 작은 검증 가능한 sub-goal로 분해한다.
즉 “더 많이 굴려 보기”가 아니라, 탐색 공간을 넓히는 방법과 검증 신호를 촘촘하게 만드는 방법을 함께 설계한다.
공식 공개물도 단순 논문에 그치지 않는다. arXiv HTML과 프로젝트 페이지, GitHub 저장소, Hugging Face collection이 함께 공개되어 있으며, GitHub는 logical, multihop, inference 세 실험 디렉터리와 MIT 라이선스를 포함한다.
다만 저장소는 작성 시점 기준 2026년 5월 20일 생성된 초기 연구 아티팩트에 가깝고, releases/tags는 아직 비어 있다.
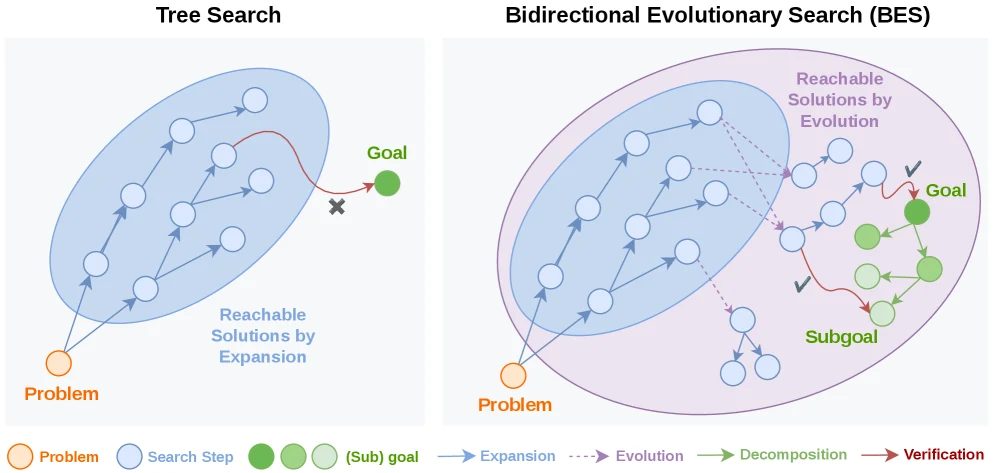
무엇을 해결하려는가
논문의 문제의식은 best-of-N이나 tree search가 “약하다”는 단순한 비판이 아니다.
두 방법 모두 LLM post-training과 inference-time scaling에서 이미 강한 baseline이다.
하지만 저자들은 두 가지 구조적 한계를 지적한다.
첫째는 희소한 검증 신호다.
RLVR이나 agent post-training에서는 verifier가 완성된 답에 대해서만 binary 또는 coarse reward를 주는 경우가 많다.
중간 추론이 어느 정도 맞았는지, 어떤 tool action이 좋은 방향이었는지, 어떤 sub-solution이 최종 답에 기여하는지는 충분히 평가되지 않는다.
이렇게 되면 search는 많은 후보를 만들더라도 무엇을 더 키워야 하는지 알기 어렵다.
둘째는 자가회귀 확장 편향이다.
일반적인 tree search는 현재 prefix에서 다음 step을 sampling해 가지를 확장한다.
이는 모델이 이미 높은 확률을 주는 영역을 더 촘촘히 탐색하게 만들지만, 낮은 확률이면서 정답에 필요한 조합은 놓치기 쉽다.
논문은 이 현상을 이론적으로 “expansion-only search가 좁은 entropy shell에 갇힌다”는 방식으로 정식화한다.
BES가 노리는 지점은 이 두 한계의 동시 해결이다.
전방 검색은 모델 rollout의 일부를 자르고, 붙이고, 교차시키며 후보 공간을 넓힌다.
후방 검색은 큰 목표를 여러 개의 checkable sub-goal로 쪼개 partial trajectory에도 점수를 줄 수 있게 만든다.
따라서 BES는 단순히 더 많은 샘플을 쓰는 방법이라기보다, 샘플이 만들어지는 경로와 샘플이 평가되는 단위를 모두 바꾸는 검색 프레임워크에 가깝다.
핵심 아이디어 / 구조 / 동작 방식
BES의 forward search는 후보 trajectory pool을 유지하면서 다섯 종류의 operator를 사용한다.
Expansion은 기존 LLM search와 같은 자가회귀 확장이고, 나머지 네 가지가 evolutionary operator다.
Combination은 공통 prefix를 가진 두 경로의 suffix를 이어 붙이고, deletion은 내부 step 하나를 제거한다.
Translocation은 한 경로의 step을 다른 경로의 step으로 바꾸며, crossover는 한 경로의 prefix와 다른 경로의 tail을 splice한다.
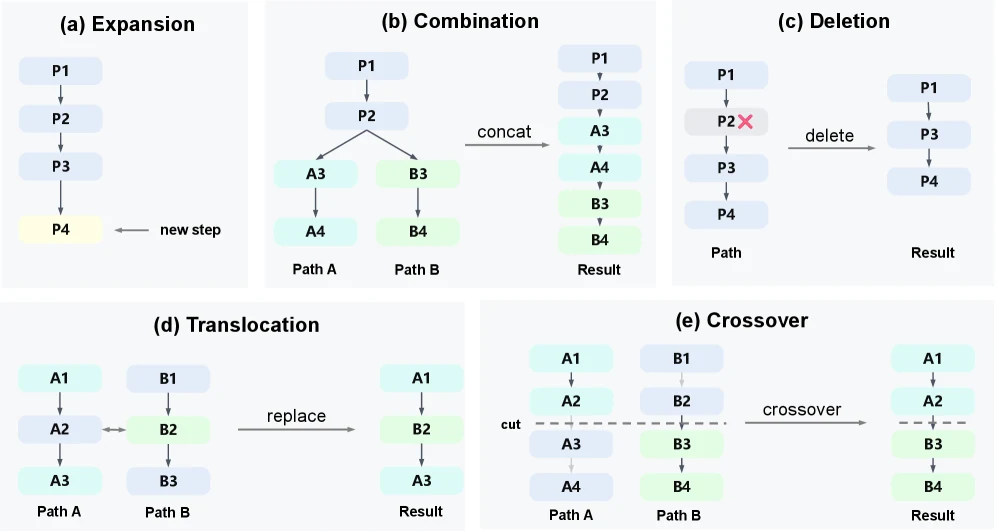
이 구조가 중요한 이유는 LLM reasoning이 완전히 독립적인 token sampling 문제가 아니기 때문이다.
어떤 풀이의 앞부분은 좋지만 뒤가 틀릴 수 있고, 다른 풀이의 중간 step은 유용하지만 전체 답은 실패할 수 있다.
Expansion-only search는 이런 조각을 경로 단위로 버리기 쉽다.
BES는 trajectory를 “완성 후보”가 아니라 재조합 가능한 구성요소로 취급한다.
Backward search는 반대 방향에서 작동한다.
원래 문제를 그대로 verifier에 던지는 대신, LLM을 이용해 목표를 여러 sub-goal로 분해하고, 각 후보가 어떤 sub-goal을 만족하는지 점수화한다.
논문 설명 기준으로는 몇 번의 forward step마다 한 번씩 backward decomposition을 수행한다.
이 goal tree는 후보 선택에 쓰이는 dense feedback 역할을 하며, 최종 정답에 도달하기 전에도 “어떤 부분은 맞아 가고 있는지”를 판단하게 해준다.
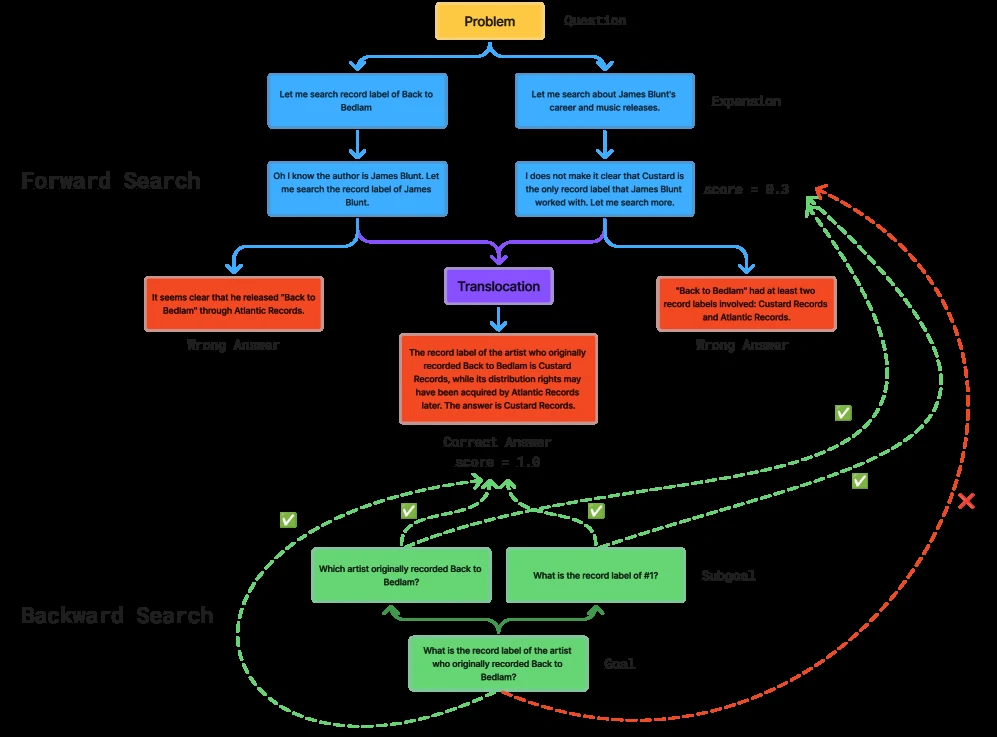
논문은 이 설계를 post-training과 inference 모두에 적용한다.
Post-training에서는 BES가 더 나은 학습 샘플을 발견하는 sampler처럼 쓰인다.
Inference에서는 ShinkaEvolve 위에 BES를 얹어 open problem solving에서 더 좋은 후보 프로그램을 찾는 방식으로 사용한다.
그래서 이 논문은 training recipe 논문이면서 동시에 test-time search 논문이기도 하다.
공개된 근거에서 확인되는 점
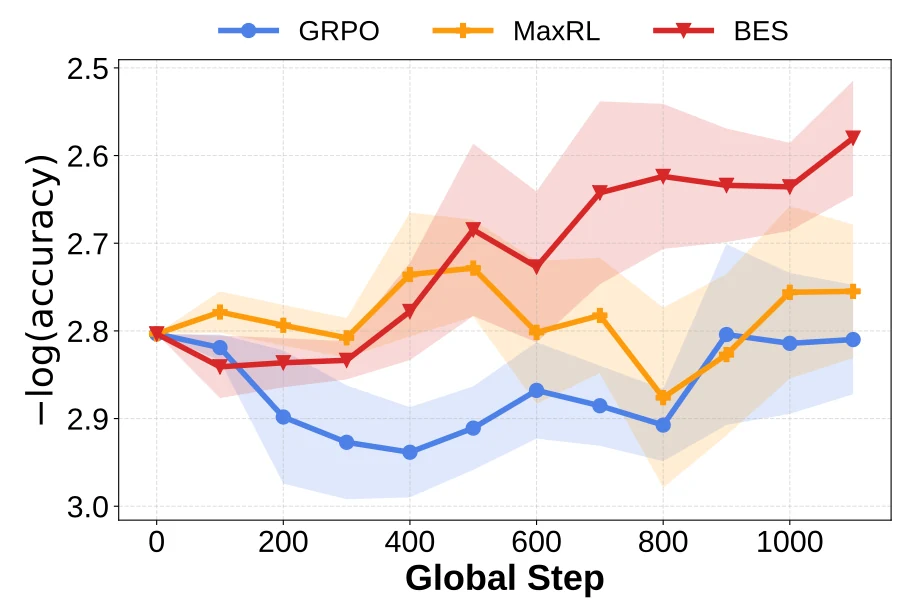
논문이 가장 먼저 보여 주는 신호는 logical reasoning post-training이다.
Knights-and-Knaves benchmark에서 Gemma-3-1B-it을 cold-start SFT 후 5K 문제로 post-training했을 때, GRPO와 MaxRL은 검증 성능 개선이 거의 없지만 BES는 학습이 진행되며 꾸준히 나아진다고 보고한다.
논문은 이 결과를 “어려운 training set에서 고품질 샘플을 발견하는 능력”의 차이로 해석한다.
MuSiQue 기반 multi-hop reasoning에서는 수치가 더 직접적이다.
Llama-3.2-3B-Instruct에서는 base accuracy 4.0%에서 GRPO가 2.1%로 떨어지고, Tree-GRPO도 3.9%에 머무는 반면 BES는 7.0%를 기록한다.
Llama-3.1-8B-Instruct에서는 base 6.6%, GRPO 5.6%, Tree-GRPO 7.4%, BES 10.4%다.
특히 BES는 valid search와 valid action 수, finish ratio도 함께 높아져 “답만 우연히 맞힌” 결과라기보다 검색 행동 자체가 더 유지되는 쪽으로 보인다.
| 설정 | Base | GRPO | Tree-GRPO | BES | 읽을 점 |
|---|---|---|---|---|---|
| MuSiQue / Llama-3.2-3B | 4.0 | 2.1 | 3.9 | 7.0 | GRPO가 오히려 하락하는 setting에서 BES만 +3.0%p 개선 |
| MuSiQue / Llama-3.1-8B | 6.6 | 5.6 | 7.4 | 10.4 | Tree-GRPO보다도 +3.0%p 높고 finish ratio 0.94 |
Inference-time open problem solving에서는 GPT-5를 backbone으로 두고 Circle Packing(Square), Circle Packing(Rectangle), Heilbronn(Convex)을 평가한다.
BES는 ShinkaEvolve 위에 얹히며, OpenEvolve·GEPA·ShinkaEvolve와 비교된다.
논문 Table 2 기준 평균 objective에서는 BES가 세 benchmark 모두 가장 높다.
Best 값은 Circle Packing 두 과제에서 AlphaEvolve/Human에 근접하지만, Heilbronn best는 OpenEvolve·GEPA·BES가 모두 0.027로 같은 수준이다.
따라서 “모든 지표를 압도한다”기보다는, open-source framework 비교에서 평균 성능을 안정적으로 끌어올린다고 읽는 편이 정확하다.
| 전략 | Circle Packing Sq. Avg / Best | Circle Packing Rect. Avg / Best | Heilbronn Convex Avg / Best |
|---|---|---|---|
| OpenEvolve | 2.531 ± .018 / 2.541 | 2.267 ± .014 / 2.276 | 0.025 ± .005 / 0.027 |
| GEPA | 2.613 ± .022 / 2.628 | 2.326 ± .023 / 2.354 | 0.025 ± .002 / 0.027 |
| ShinkaEvolve | 2.464 ± .083 / 2.541 | 2.335 ± .026 / 2.358 | 0.023 ± .005 / 0.026 |
| BES | 2.623 ± .014 / 2.632 | 2.349 ± .012 / 2.360 | 0.026 ± .001 / 0.027 |
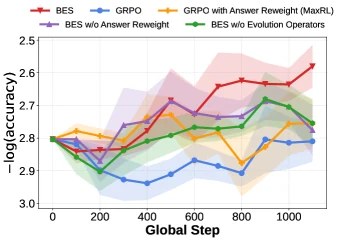
Ablation도 중요한 근거다.
Knights-and-Knaves에서 BES는 MaxRL의 answer reweighting과 bidirectional evolutionary search를 함께 쓴다.
논문 Figure 4는 answer reweighting을 제거하거나 evolution operator를 제거하면 full BES보다 성능이 낮아진다고 보고한다.
즉 결과가 단순히 MaxRL 계열 reweighting만의 효과가 아니라, backward search와 evolutionary operator가 함께 기여한다는 주장이다.
비용은 공짜가 아니다.
Multi-hop post-training에서 Llama-3.2-3B 기준 median walltime은 GRPO 64초, Tree-GRPO 240초, BES 309초로 보고된다.
다만 논문은 GRPO의 낮은 walltime이 misleading하다고 본다.
GRPO는 검색 행동을 줄이고 답을 추측하는 reward hacking 양상을 보이며 valid search가 0.84에 그친다.
BES는 Tree-GRPO보다 약 30% 이내의 추가 walltime을 쓰면서 accuracy 7.0%, valid search 2.31을 얻는다.
공개 release surface를 보면, GitHub 저장소는 Python 중심이고 logical, multihop, inference 디렉터리가 각 실험을 분리한다. logical은 verl 기반 Gemma-3-1B-it K&K post-training, multihop은 MuSiQue와 Wikipedia E5/FAISS retriever, inference는 ShinkaEvolve 기반 open problem solving 구현이다.
GitHub API 조회 기준으로 저장소는 stars 13, forks 1, open issues 0이며, releases와 tags는 비어 있다.
Hugging Face collection에는 논문 entry와 함께 Xkev/gemma-3-1b-it-kk, Xkev/gemma-3-1b-it-kk-bes, Xkev/Llama-3.2-3B-Instruct-multihop-BES, Xkev/Llama-3.1-8B-Instruct-multihop-BES가 올라와 있다.
Gemma 계열은 MIT license tag, Llama 계열은 각각 llama3.2/llama3.1 license tag를 따른다.
실무 관점에서의 해석
BES의 장점은 “search를 더 많이 한다”가 아니라, search가 모델 분포에 갇히는 방식 자체를 바꾼다는 점이다.
Best-of-N은 병렬화가 쉽지만 후보를 독립 rollout로 다룬다.
Tree search는 prefix를 공유하며 더 구조적이지만 여전히 확장 방향은 모델의 다음 step 분포에 강하게 묶인다.
BES는 이미 만들어진 여러 실패/부분성공 궤적에서 쓸 만한 조각을 다시 조합한다.
이 관점은 코드 생성, tool-use agent, multi-hop search agent처럼 “부분적으로 맞은 행동”이 자주 나오는 영역과 잘 맞는다.
Backward search는 verifier engineering의 대안처럼 읽힌다.
고품질 dense reward model을 별도로 학습하지 못하더라도, 목표를 sub-goal로 분해하면 partial credit을 만들 수 있다.
물론 이 decomposition 자체도 LLM 품질에 의존한다.
잘못 쪼갠 sub-goal은 search를 오히려 편향시킬 수 있고, domain-specific verifier가 있는 수학·코딩·검색 과제와 그렇지 않은 창의적 과제 사이에서 효과가 달라질 수 있다.
운영 관점에서는 비용과 복잡도를 조심해야 한다.
BES는 backward server, retriever, vLLM, SLURM script, ShinkaEvolve 기반 inference harness 등 여러 실행 구성요소를 요구한다.
GitHub README도 환경 차이와 재현 난이도를 명시적으로 인정한다.
따라서 현재 공개물은 “pip install 한 번으로 쓰는 범용 agent runtime”이라기보다, self-improvement/post-training 연구자가 자신의 실험 harness에 붙여 볼 수 있는 초기 연구 구현에 가깝다.
그럼에도 이 논문이 흥미로운 이유는 test-time scaling과 post-training sample generation을 같은 검색 문제로 묶는다는 데 있다.
학습 때 좋은 샘플을 찾는 문제와 추론 때 좋은 답을 찾는 문제는 보통 따로 다뤄진다.
BES는 둘 다 “희소한 feedback 아래에서 낮은 확률의 좋은 trajectory를 찾는 문제”로 본다.
이 통합 프레이밍은 앞으로 verifier, evolutionary operator, goal decomposition, agent memory를 결합한 자기개선 시스템 설계에 꽤 직접적인 영향을 줄 수 있다.
결론적으로 BES는 완성된 production framework라기보다, LLM 자기개선에서 search를 다시 설계하자는 강한 연구 제안이다.
논문 수치만 보면 아직 domain과 backbone이 제한되어 있고 비용도 올라간다.
하지만 “모델이 낸 후보를 더 많이 고르는 것”에서 “후보의 조각을 재조합하고, 목표를 뒤에서부터 쪼개 검증하는 것”으로 관점을 옮기는 점은 중요하다.
LLM post-training과 agent inference가 모두 더 비싼 search를 쓰는 방향으로 가고 있다면, 다음 병목은 sample 수가 아니라 어떤 search topology가 고품질 trajectory를 실제로 발견하게 만드는가일 가능성이 크다.