MoE는 보통 클라우드의 거대 모델을 떠올리게 한다.
수십·수백 개 expert를 두고 토큰마다 일부 expert만 활성화하면 총 파라미터는 크게 키우면서도 토큰당 연산은 줄일 수 있기 때문이다.
하지만 이 논리는 대부분 데이터센터 GPU와 대형 모델을 기준으로 검증되어 왔다.
휴대폰 안에서 배치 1로 실행되는 1B 이하 활성 파라미터 모델에도 같은 장점이 남는지는 별개의 문제다.
Meta의 MobileMoE: Scaling On-Device Mixture of Experts는 그 질문을 정면으로 다룬다.
논문은 0.3B, 0.5B, 0.9B급 활성 파라미터를 갖는 MobileMoE-S/M/L을 제안하고, 총 파라미터는 1.3B, 2.8B, 5.3B까지 늘린다.
핵심은 단순히 “작은 MoE를 만들었다”가 아니다.
모바일 메모리, 토큰당 연산, INT4 가중치 크기, 실제 스마트폰 런타임을 함께 놓고 MoE 설계 공간을 다시 최적화했다는 점이다.
이 글은 arXiv 원문·HTML·source tarball의 표와 그림을 직접 확인해 정리한 글이다.
현재 공개 표면도 함께 봐야 한다.
Hugging Face와 GitHub 공개 검색 기준으로 MobileMoE 자체 체크포인트나 전용 구현 repo는 아직 확인되지 않는다.
대신 논문 소스에는 도표와 수치가 충분히 공개되어 있고, baseline으로 쓰인 facebook/MobileLLM-Pro-base-int4-accelerator, PyTorch ExecuTorch, 평가 harness와 데이터셋 링크가 동반 근거로 제시된다.
따라서 이 연구는 “즉시 내려받아 앱에 넣는 모델 릴리스”라기보다 온디바이스 MoE 설계와 런타임 프로파일링을 보여 주는 연구 보고서로 읽는 편이 정확하다.
무엇을 해결하려는가
온디바이스 LLM의 병목은 모델 크기 하나로 설명되지 않는다.
실제 앱에서는 첫 토큰까지 걸리는 시간, prefill 지연, decode tokens/s, KV cache와 activation buffer, INT4/INT8 양자화 후 품질, thermal budget, 배터리, 런타임 커널 지원이 같이 맞아야 한다.
1B dense 모델이 품질을 조금 올리려고 FFN을 키우면 토큰당 연산과 메모리 대역폭이 그대로 늘어난다.
MobileMoE의 문제의식은 여기서 출발한다.
MoE라면 총 파라미터를 늘려 지식 저장 용량을 키우면서도, 토큰당 활성 파라미터는 낮게 유지할 수 있다.
다만 모바일에서는 “총 파라미터가 크다”는 사실 자체가 메모리 문제를 만든다.
서버 GPU에서는 expert를 넉넉히 올려도 되지만, 스마트폰에서는 INT4 가중치로 압축해도 resident memory와 mmap, expert routing, dispatch overhead가 모두 지연에 영향을 준다.
그래서 논문은 MoE를 그냥 축소하지 않고, 모바일 제약을 목적함수에 넣은 scaling law로 다시 설계한다.
최적화 대상은 세 가지다.
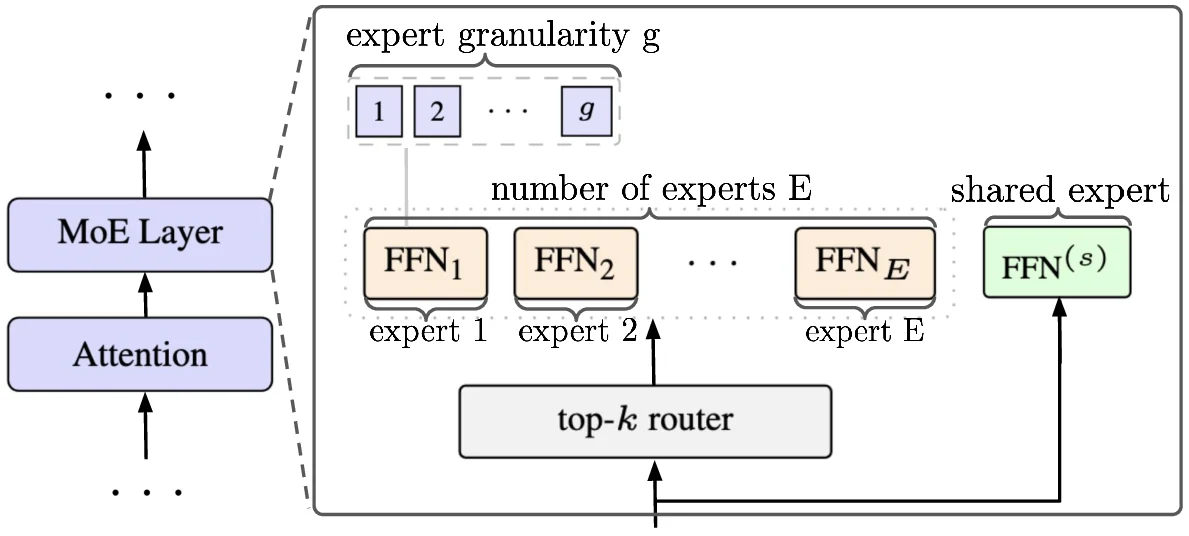
첫째 expert 수 E로 결정되는 sparsity와 총 파라미터, 둘째 expert를 더 작은 조각으로 나누는 granularity g, 셋째 모든 토큰이 지나가는 shared expert의 유무다.
이 세 축을 고정 활성 파라미터, 학습 FLOPs, 온디바이스 메모리 예산 안에서 비교해 “모바일에서 MoE가 dense보다 실제로 유리해지는 지점”을 찾는다.
핵심 아이디어 / 구조 / 동작 방식
MobileMoE의 최종 설계는 논문이 말하는 온디바이스 sweet spot을 따른다. expert 수는 중간 정도인 E=8을 택하고, 각 expert를 g=8개의 fine-grained expert로 쪼개며, 항상 활성화되는 shared expert를 둔다.
최종적으로는 60개 routed fine-grained experts, top-4 routing, shared expert 조합이 된다.
이 구성은 routed expert만 두는 방식보다 학습 loss가 낮고, g=16처럼 더 잘게 쪼갠 구성보다 학습 시간 대비 이득이 낫다고 보고된다.
모델 스케일은 세 가지다.
| 모델 | 활성 / 총 파라미터 | INT4 weight memory | QAT 후 14개 benchmark 평균 | 역할 |
|---|---|---|---|---|
| MobileMoE-S | 272M / 1.3B | 0.68GB | 44.0 | 가장 빠른 소형 온디바이스 축 |
| MobileMoE-M | 528M / 2.8B | 1.48GB | 52.5 | 품질·지연 균형점 |
| MobileMoE-L | 922M / 5.3B | 2.75GB | 57.8 | 가장 높은 품질 축 |
| MobileLLM-Pro baseline | 1.1B dense | 0.55GB | 45.5 | 비교 대상 dense 모바일 LLM |
아키텍처 기반은 온디바이스 dense LLM 설계 관례를 따른다. decoder-only Transformer, SwiGLU, 4 KV heads의 GQA, d_ff / d_model = 4, deep-and-thin aspect ratio를 사용한다.
여기에 MoE FFN을 얹되, 모바일에서는 expert dispatch와 kernel launch overhead가 곧 병목이 되므로 런타임 구현도 별도로 설계한다.

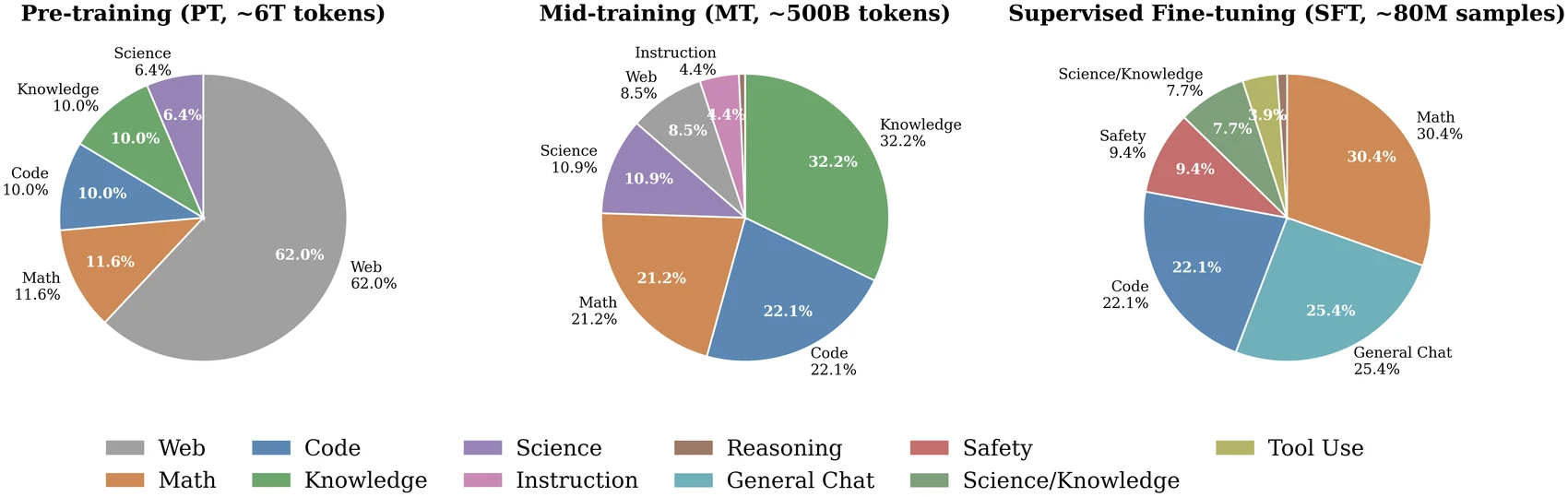
학습 레시피도 제품 배포를 의식한다. pre-training은 6T tokens, mid-training은 500B tokens, SFT는 8천만 개 이상의 sample을 사용한다.
마지막에는 INT4 QAT를 적용한다.
논문은 모든 학습 단계가 open-source datasets 기반이라고 설명하며, source bundle의 데이터 표에는 Dolma/OLMo 계열, FineWeb-Edu, FineMath, Natural Reasoning, Nemotron post-training 데이터, OpenMathInstruct, OpenCode 계열 등 공개 데이터 출처가 나열되어 있다.
런타임 구현의 핵심은 sparse routing을 그대로 두지 않는 것이다.
논문은 ExecuTorch 위에 커스텀 MoE operator를 구현했다고 설명한다.
토큰을 expert ID 기준으로 재정렬해 같은 expert로 가는 토큰을 연속 배치하고, expert별 matmul을 dense grouped GEMM처럼 처리한다. top-k selection, dispatch, gate/up projection, SwiGLU, down projection, weighted scatter를 하나의 fused op로 묶어 kernel launch와 activation quantization overhead를 줄인다. attention과 embedding은 XNNPACK INT4 dense path를 계속 사용한다.
공개된 근거에서 확인되는 점
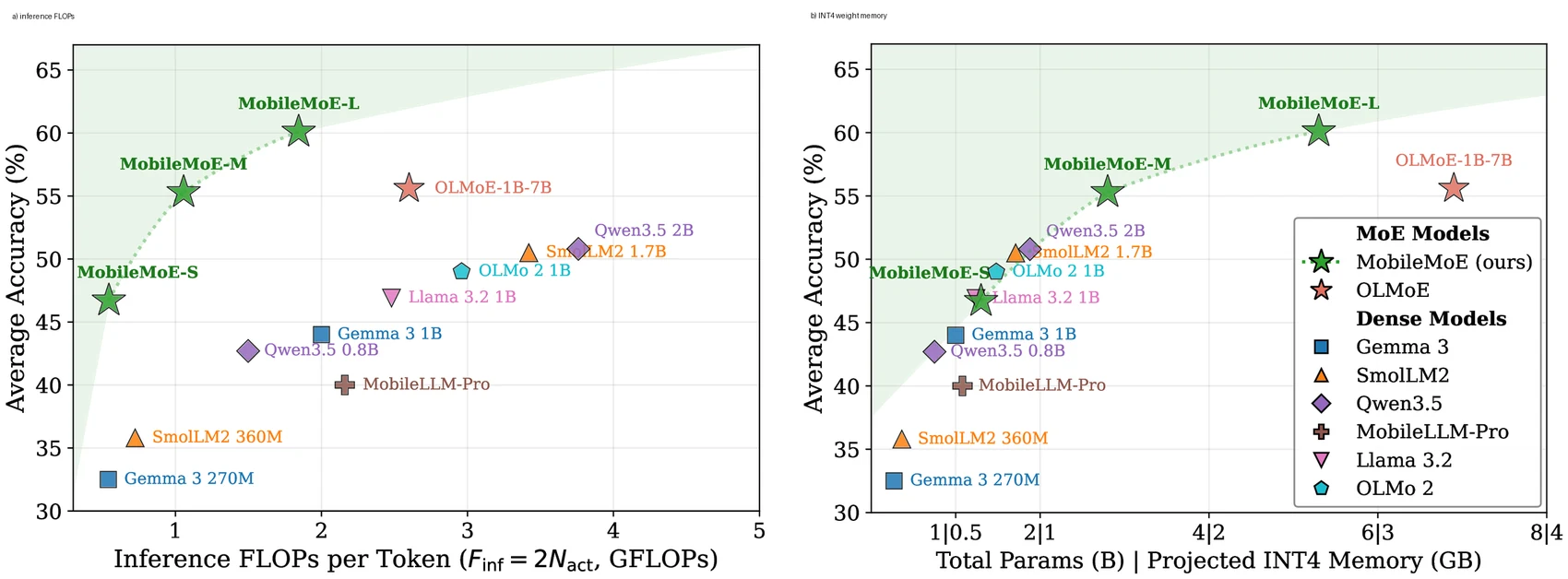
가장 큰 수치는 Pareto frontier다. base 모델 비교에서 MobileMoE-L은 922M active / 5.3B total로 14개 foundational benchmark 평균 59.8을 기록한다.
같은 표의 OLMoE-1B-7B base는 1.3B active / 6.9B total, 평균 52.4다.
MobileMoE-M은 528M active로 평균 55.4를 보이며, MobileLLM-Pro 1.1B dense의 평균 47.0보다 높다.
S는 272M active, 평균 46.5로 270M~360M dense baseline보다 높은 축에 위치한다.
instruction SFT 후에는 MobileMoE-L이 foundational benchmark 평균 60.1, advanced benchmark overall 44.4를 보인다.
MobileMoE-M은 각각 55.3과 38.4다.
다만 이것을 “모든 작은 모델을 이긴다”로 읽으면 안 된다.
예를 들어 reasoning 계열에서는 더 큰 Qwen3.5-2B가 강하게 나오는 항목이 있고, MobileMoE-S는 QAT 후 평균이 MobileLLM-Pro보다 1.5점 낮다.
이 논문의 핵심은 절대 최고점이 아니라 활성 파라미터·INT4 메모리·스마트폰 지연을 함께 놓은 균형점이다.
QAT 결과도 중요하다.
논문은 BF16 SFT 대비 INT4 QAT 후 평균 하락이 MobileMoE-S/M/L 각각 2.7, 2.8, 2.3점이라고 보고한다.
4배 weight compression을 걸어도 MoE routing과 expert computation이 크게 무너지지 않는다는 주장이다.
MobileMoE-L은 INT4 weight memory 2.75GB, 평균 57.8을 보이며, 논문은 이를 BF16 SFT OLMoE-1B-7B 평균 55.6보다 높고 메모리 footprint는 약 5배 작다고 해석한다.
스마트폰 latency 표는 더 직접적이다.
Samsung Galaxy S25는 Snapdragon 8 Elite CPU 4 threads, iPhone 16 Pro는 Apple A18 Pro CPU 2 threads 조건이다.
둘 다 ExecuTorch+XNNPACK, INT4 weights, INT8 dynamic activations, batch size 1로 측정했다.
입력은 dummy prompt가 아니라 knowledge, code, math real prompts를 사용했다고 명시한다.
| 디바이스 / context | MobileLLM-Pro prefill TTFT | MobileMoE-S prefill TTFT | MobileLLM-Pro decode | MobileMoE-S decode |
|---|---|---|---|---|
| Galaxy S25 / 1k | 4.26s | 2.01s | 45.8 tok/s | 112.0 tok/s |
| Galaxy S25 / 4k | 35.62s | 16.36s | 18.6 tok/s | 48.9 tok/s |
| iPhone 16 Pro / 1k | 6.03s | 2.14s | 48.5 tok/s | 148.4 tok/s |
| iPhone 16 Pro / 4k | 39.08s | 13.86s | 17.9 tok/s | 54.2 tok/s |
논문이 요약하는 speedup은 MobileMoE-S가 dense MobileLLM-Pro 대비 prefill 1.8–3.8배, decode 2.2–3.4배 빠르다는 것이다.
특히 iPhone 16 Pro의 MLX GPU path까지 포함한 speedup 표에서는 512/1k/2k context prefill이 3.6–3.8배 빨라진다.
이 결과는 MoE의 이론적 활성 파라미터 절감이 모바일 런타임에서도 관측 가능하다는 강한 신호다.
메모리 결과는 더 미묘하다.
MobileMoE-S는 Samsung S25 real prompts 기준 4k context에서 1.23GB Peak RSS로 MobileLLM-Pro의 1.35GB보다 낮고, 8k에서는 1.49GB로 MobileLLM-Pro 1.91GB보다 낮다.
하지만 short context에서는 MobileMoE-S가 약간 더 높고, M/L은 당연히 더 많은 RAM을 쓴다.
또 dummy prompt와 real prompt의 차이가 크다.
MoE는 입력에 따라 활성 expert가 달라지므로 반복 토큰 dummy prompt는 실제 메모리를 과소평가할 수 있다.
논문이 real prompts를 강조하는 이유도 여기에 있다.

release 관점에서는 보수적으로 봐야 한다. arXiv HTML과 source에는 평가 harness, 데이터셋, ExecuTorch, baseline MobileLLM-Pro checkpoint 링크가 포함되어 있지만, 공개 검색 기준으로 MobileMoE 자체 모델 repo나 학습/추론 코드 repo는 확인되지 않았다. arXiv 라이선스는 CC BY 4.0이라 논문과 도표 재사용 조건은 비교적 명확하지만, 모델 가중치·커스텀 커널·QAT checkpoint가 공개 artifact로 패키징된 상태라고 말할 근거는 아직 부족하다.
실무 관점에서의 해석
내가 보기에 MobileMoE의 가장 중요한 메시지는 MoE가 모바일에서 안 되는 이유가 아니라, 모바일에 맞게 다시 설계해야 하는 이유를 보여 준다는 점이다.
서버용 MoE를 그대로 축소하면 expert dispatch overhead, 메모리 footprint, kernel fusion 부족 때문에 장점이 사라질 수 있다.
MobileMoE는 scaling law로 설계 지점을 찾고, QAT로 weight memory를 줄이고, ExecuTorch 커스텀 op로 sparse routing overhead를 줄여야 스마트폰에서 이득이 난다고 말한다.
두 번째 의미는 작은 모델 평가 기준의 이동이다.
“1B 모델 평균 점수”만 보면 dense 모델과 sparse 모델의 차이가 흐려진다.
하지만 사용자가 체감하는 것은 1k/4k/8k context에서 첫 토큰이 언제 나오고, decode가 몇 tok/s로 유지되며, RAM peak가 몇 GB까지 튀는지다.
MobileMoE 논문은 이 지표를 정면으로 표에 올린다.
특히 real prompt와 dummy prompt를 구분한 메모리 측정은 온디바이스 MoE를 실제 제품에 넣을 때 매우 중요한 포인트다.
세 번째 의미는 MobileLLM-Pro와의 관계다.
MobileLLM-Pro는 128k context, local-global attention, int4 quantization checkpoint를 제공하는 강한 dense 모바일 baseline이다.
MobileMoE는 이 baseline과 비교해 S에서는 비슷한 품질을 훨씬 빠르게, M/L에서는 더 높은 품질을 적당한 런타임 비용으로 얻는 방향을 보여 준다.
즉 dense 모바일 LLM을 대체한다기보다, dense 모델이 지연·대역폭 한계에 닿는 구간에서 sparse capacity를 쓰는 새 선택지를 제시한다.
하지만 실무 적용은 아직 한 단계 더 남아 있다.
논문 수치가 강하더라도, 실제 앱 팀이 확인해야 할 것은 가중치 공개 여부, 라이선스, 커스텀 MoE op의 upstream 여부, iOS/Android packaging, NPU/ANE 지원, thermal throttling, long-session 안정성, 모델 업데이트 경로다.
현재 공개 표면만 놓고 보면 MobileMoE는 “제품에 바로 꽂을 수 있는 drop-in checkpoint”라기보다 온디바이스 MoE가 성립할 수 있음을 보인 설계·런타임 레퍼런스에 가깝다.
그럼에도 이 논문은 볼 가치가 크다.
MoE를 대형 클라우드 모델의 전유물로 보던 관성을 깨고, 스마트폰의 메모리와 compute budget 안에서 expert 수, granularity, shared expert, INT4 QAT, fused runtime kernel이 어떻게 같이 움직이는지 보여 준다.
앞으로 온디바이스 AI 경쟁은 단순히 “몇 B 모델인가”가 아니라, 활성 파라미터·총 파라미터·실제 RAM·first-token latency·decode throughput을 동시에 맞추는 sparse system design 쪽으로 더 자주 이동할 가능성이 높다.
MobileMoE는 그 방향의 꽤 선명한 early signal이다.