RAG와 검색형 AI 시스템에서 병목은 더 이상 “벡터 DB를 붙였는가”만으로 설명되지 않는다.
실제 품질은 첫 번째 retrieval이 후보를 얼마나 넓게 잡는지, reranker가 그 후보를 얼마나 정확하게 다시 정렬하는지, 그리고 그 모든 과정이 latency·비용·보안·배포 조건 안에서 돌아가는지에 달려 있다.
ZeroEntropy의 Models 문서는 이 문제를 꽤 실용적인 방식으로 정리한다.
표면적으로는 zembed-1 임베딩 모델과 zerank-2/zerank-1 계열 reranker 사용법을 설명하는 API 문서다.
하지만 자세히 보면 개별 모델 카드가 아니라 검색 품질을 embedding, reranking, managed search engine, self-hosting, marketplace 배포까지 묶어 운영하는 스택에 가깝다.
흥미로운 점은 “모델이 좋다”는 주장만 하지 않는다는 데 있다.
문서는 API 호출 파라미터, 출력 차원, latency mode, byte 기반 rate limit, token 가격, Hugging Face 공개 weight, AWS Marketplace/SageMaker 배포, 그리고 zsearch end-to-end 검색 엔진까지 한 화면에서 연결한다.
즉 ZeroEntropy가 팔고 있는 것은 단일 embedding endpoint라기보다, 검색 품질을 제품화하는 control surface다.
무엇을 해결하려는가
검색 파이프라인은 보통 두 단계로 나뉜다.
먼저 embedding 또는 hybrid retriever가 후보 문서를 빠르게 가져오고, 그다음 cross-encoder reranker가 (query, document) 쌍을 직접 읽어 순서를 다시 매긴다.
첫 단계는 scale에 강하지만 의미가 비슷한 distractor를 가져오기 쉽고, 두 번째 단계는 정확하지만 후보 수와 입력 길이에 따라 비용이 커진다.
ZeroEntropy가 겨냥하는 병목은 이 둘을 따로 최적화할 때 생기는 운영 공백이다.
좋은 embedding 모델만 있어도 부족하고, 좋은 reranker만 있어도 production retrieval이 자동으로 완성되지는 않는다.
실제 팀은 query/document 비대칭 embedding, reranker score calibration, multilingual/domain vocabulary, metadata filtering, OCR·chunking, rate limit, VPC/on-prem 배포, 가격까지 함께 봐야 한다.
그래서 Models 문서의 핵심 메시지는 “zembed-1을 쓰라”보다 넓다. zembed-1은 직접 호출할 수 있는 embedding 모델이면서 zsearch의 기본 embedding 모델이고, zerank-2는 별도 /models/rerank endpoint로도 쓰지만 /top-snippets query parameter로 managed search engine 안에도 들어간다.
모델 endpoint와 완성형 검색 엔진을 같은 설계 공간에 놓는 셈이다.
핵심 아이디어 / 구조 / 동작 방식
ZeroEntropy의 공개 문서에서 확인되는 모델 계층은 세 부분으로 정리할 수 있다.
| 계층 | 공개 artifact | 문서에서 확인되는 역할 | 실무적 의미 |
|---|---|---|---|
| Embedding | zembed-1 |
query/document input_type, 2560·1280·640·320·160·80·40 차원 선택, float/base64 인코딩 |
1차 후보 검색의 recall, 저장 비용, latency를 조절하는 계층 |
| Reranking | zerank-2, zerank-1, zerank-1-small |
/models/rerank endpoint, /top-snippets의 reranker 옵션, cross-encoder score |
후보 문서의 최종 순서를 바꾸는 precision 계층 |
| Search engine | zsearch |
OCR/parse, chunk, embed, vector/BM25/sparse index, document/page/snippet query | 모델 호출을 완성형 문서 검색 API로 묶는 운영 계층 |
zembed-1 쪽에서 중요한 설계는 inference-time control이다.
API 스키마 기준 model, input_type, input이 필수이고, 선택적으로 dimensions, encoding_format, latency를 지정한다.
차원은 2560을 기본으로 40까지 줄일 수 있으며, encoding_format="base64"는 float 배열보다 효율적인 반환 형식으로 설명된다. input_type이 query와 document로 분리된 것도 검색 문제에서는 중요하다.
같은 문장이라도 질문으로 넣을 때와 문서로 넣을 때 임베딩 공간에서 맡는 역할이 다르기 때문이다.
zerank-2와 zerank-1 계열은 cross-encoder reranker다.
API 스키마 기준 /models/rerank는 model, query, documents를 필수로 받고, top_n과 latency를 선택적으로 받는다.
결과는 relevance score와 원래 document index를 내림차순으로 반환한다.
문서 설명은 reranker score가 deterministic하고 hybrid search보다 해석하기 쉽다고 설명하지만, 동시에 byte 계산식이 query를 문서 수만큼 반복해 센다는 점도 드러낸다.
후보 수가 늘면 비용·rate limit이 선형으로 커진다는 뜻이다.
zsearch는 이 모델들을 더 높은 수준의 검색 엔진으로 묶는다.
문서 업로드 시 auto 입력은 PDF, DOCX, PPT 같은 바이너리 파일을 OCR·파싱하고, coarse/fine chunk를 만들고, zembed-1로 임베딩한다. query 쪽은 document, page, snippet 세 granularity를 제공하고, metadata filtering과 reranker 옵션을 함께 둔다.
즉 직접 모델 endpoint를 조립할 수도 있고, ingestion과 query orchestration을 ZeroEntropy 쪽 managed path에 맡길 수도 있다.
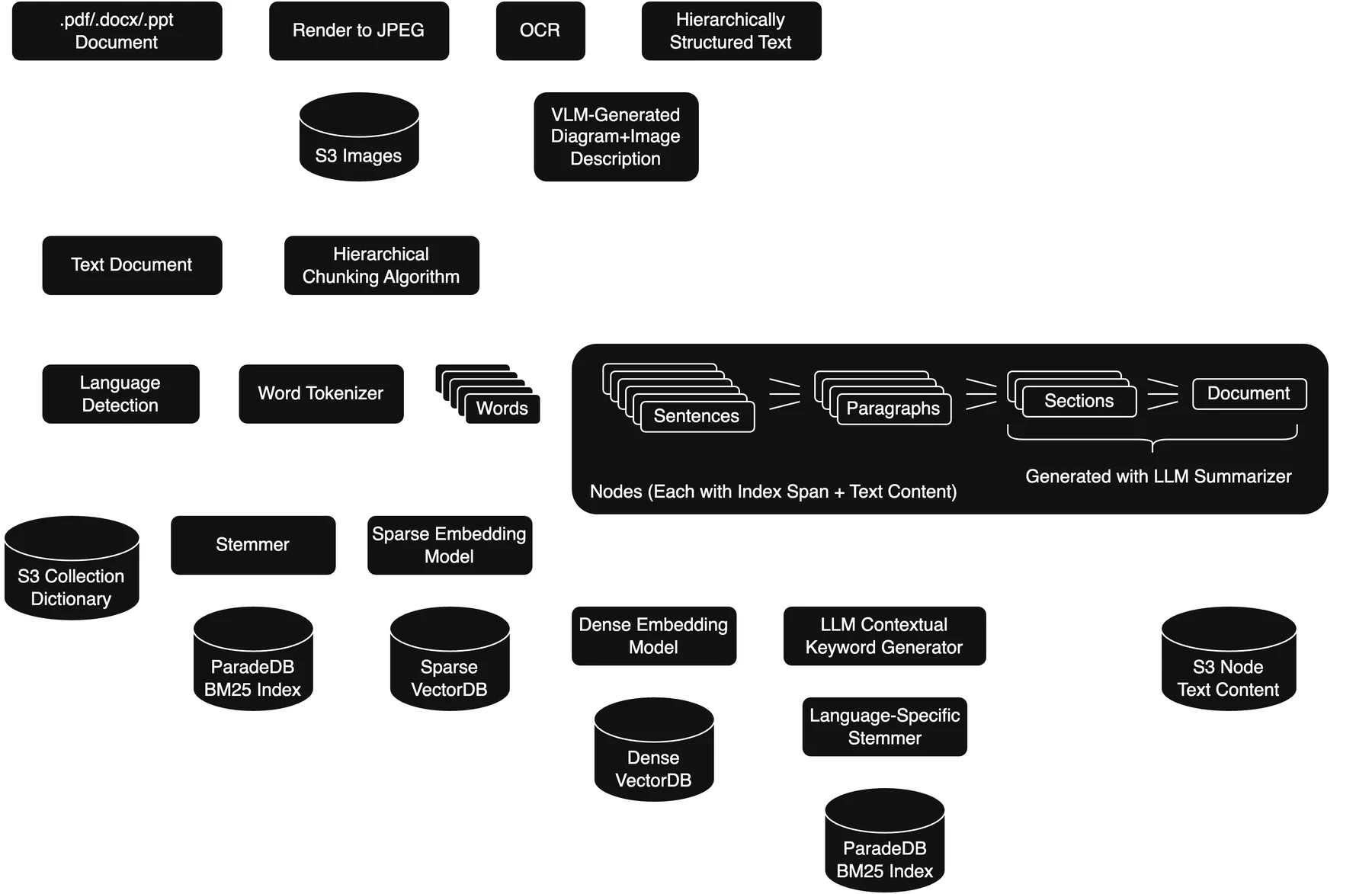
아키텍처 문서는 이 방향을 더 노골적으로 보여 준다. ingestion pipeline은 문서 렌더링, OCR, 계층적 chunking, 이미지/다이어그램 설명, dense embedding, sparse embedding, BM25 index를 함께 다룬다. data storage에는 object storage, PostgreSQL, turbopuffer vector index, ParadeDB BM25 index, S3 dictionary/BK-tree가 언급된다. query processing engine에는 자연어 query 해석, keyword generation, semantic search, LLM-in-the-loop 최종 검토가 들어간다.
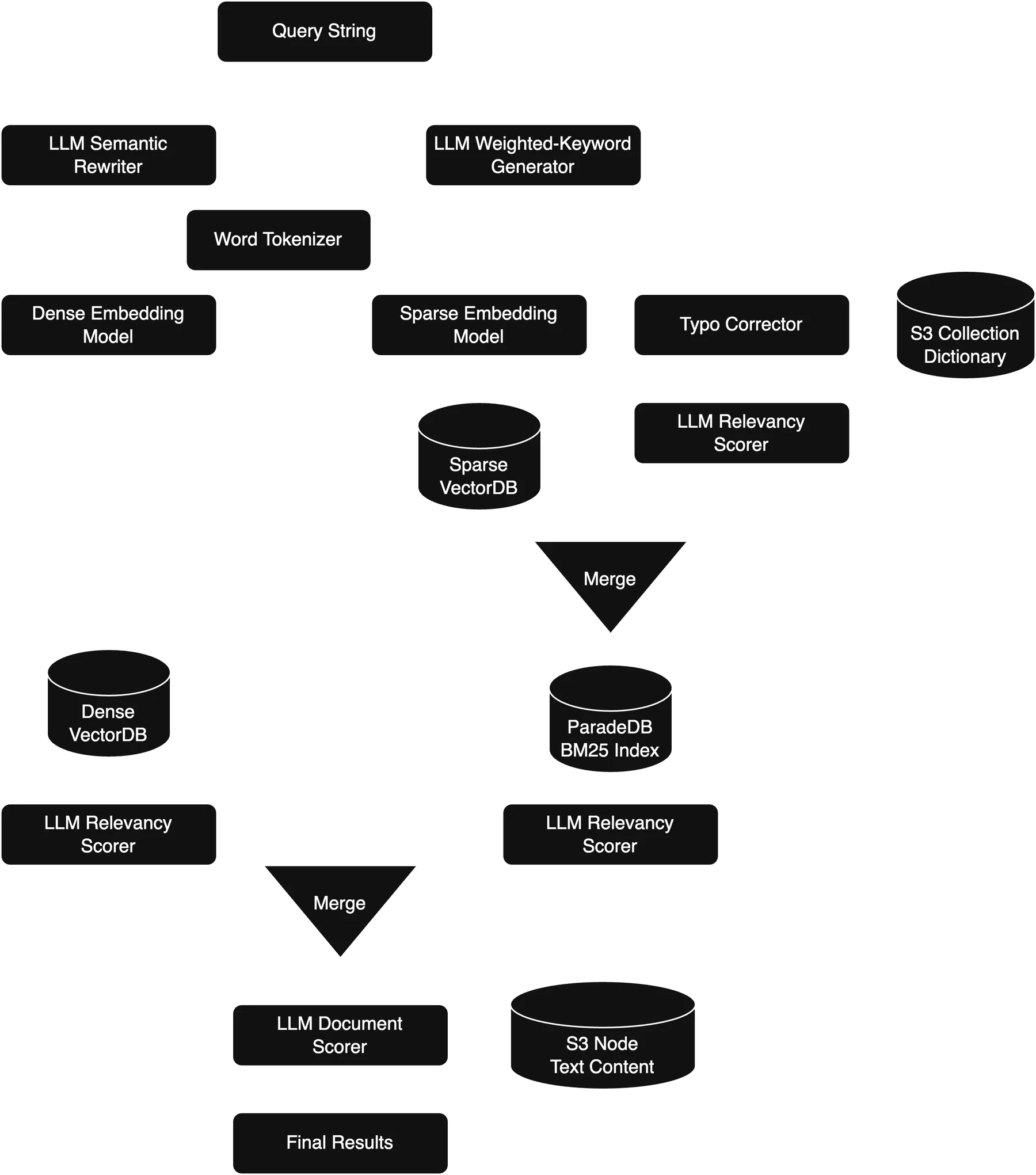
공개된 근거에서 확인되는 점
먼저 배포 표면이 넓다.Models 문서는 zembed-1을 API/SDK, Hugging Face self-hosting, AWS Marketplace through SageMaker로 사용할 수 있다고 설명한다. reranker도 /models/rerank, /top-snippets parameter, Hugging Face, AWS Marketplace 경로를 함께 제공한다.
API/SDK 탭은 Python과 Node SDK, dashboard API key, US-East·US-West·Europe region, status page, latency benchmark repository를 안내한다.
같은 문서에서 “your data is never used for model training”도 명시되어 있다.
둘째, 라이선스와 공개 weight의 의미는 모델마다 다르다.
Hugging Face API와 model card 기준 zembed-1-embedding과 zerank-2-reranker는 모두 Qwen3-4B 기반 4B 모델, 32K context, CC-BY-NC-4.0 license로 표시된다. zerank-1-reranker도 CC-BY-NC-4.0이고, zerank-1-small-reranker는 1.7B 모델로 Apache 2.0 license다.
따라서 “open-weight”라고 해서 모두 같은 상업적 사용 조건을 갖는 것은 아니다.
상업 배포에서는 모델별 license와 ZeroEntropy commercial license 조건을 따로 확인해야 한다.
| 모델 | 공개 표면 기준 확인 사항 | 라이선스 / 배포 해석 |
|---|---|---|
zembed-1 / zembed-1-embedding |
4B, Qwen3-4B base, 32K context, 2560→40 차원, feature-extraction | Hugging Face 공개 weight는 CC-BY-NC-4.0, API·SageMaker 경로 제공 |
zerank-2 / zerank-2-reranker |
4B, Qwen3-4B base, 32K context, text-ranking, instruction-following reranker | Hugging Face 공개 weight는 CC-BY-NC-4.0, 상업 사용은 별도 license 검토 필요 |
zerank-1 / zerank-1-reranker |
4B reranker, 32K context, first-generation flagship | CC-BY-NC-4.0, zerank-1-small과 성능·라이선스 trade-off |
zerank-1-small / zerank-1-small-reranker |
1.7B reranker, 32K context, smaller generation | Apache 2.0으로 가장 OSS 친화적인 선택지 |
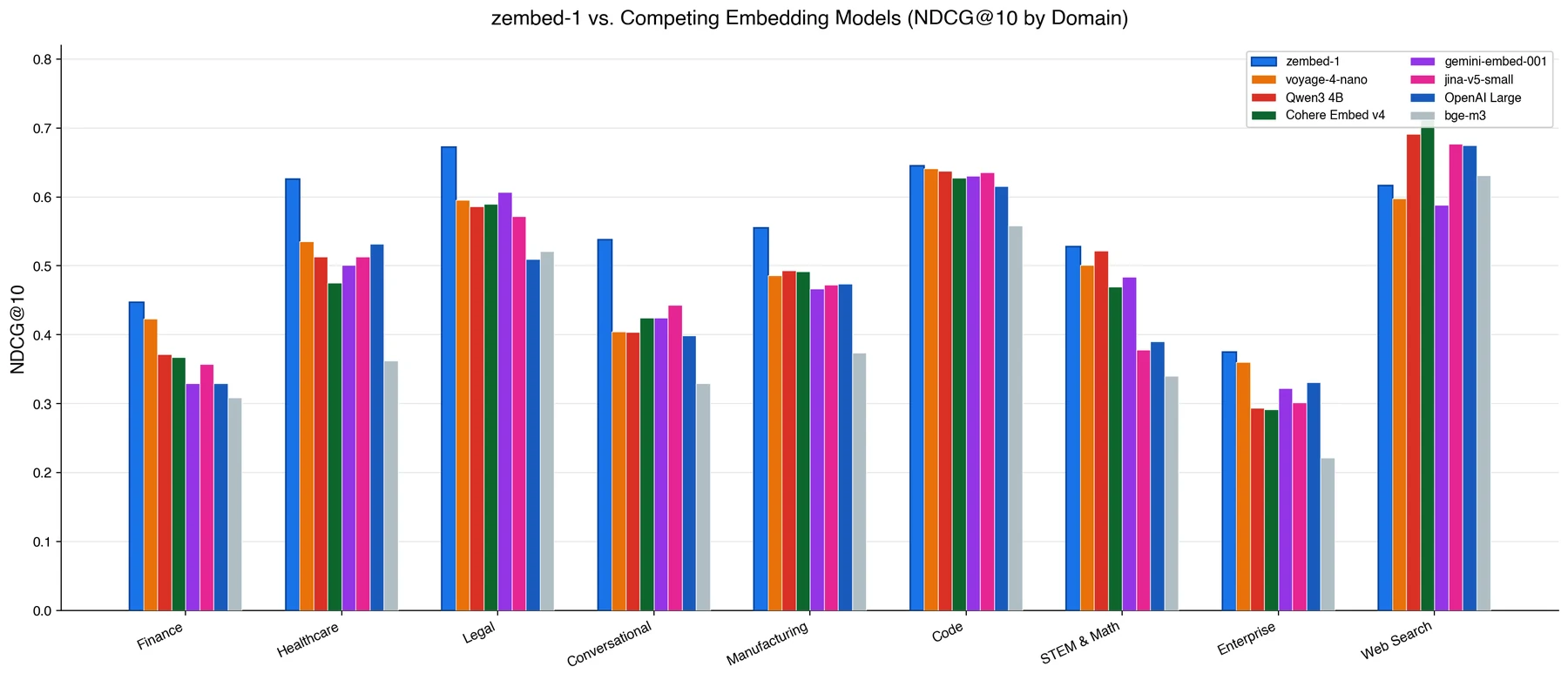
셋째, 성능 근거는 문서별로 evaluation surface가 나뉜다. zembed-1 모델 카드는 도메인별 NDCG@10 표를 공개하며, 평균 기준 zembed-1 0.5561, voyage-4-nano 0.5050, Qwen3 4B 0.5013, Cohere Embed v4 0.4957, OpenAI Large 0.4727로 제시한다.
특히 finance, healthcare, legal, conversational, manufacturing, code, STEM & Math, enterprise domain에서 zembed-1이 가장 높은 값으로 표시된다.
반면 web search 항목에서는 Cohere Embed v4가 더 높은 수치를 보인다.
이 점은 모델 카드가 모든 범주에서 무조건 1위라는 식이 아니라, domain mix에 따른 장단점을 함께 보여 준다는 의미가 있다.
zerank-2 모델 카드는 reranker 평가에서 OpenAI embedding retrieval을 top-100 후보 생성기로 둔 뒤 NDCG@10을 비교한다.
평균값은 zerank-2 0.6714, zerank-1 0.6456, Gemini 2.5 Flash listwise 0.5999, Cohere rerank-3.5 0.5847, OpenAI embedding-only baseline 0.4509다.
도메인별로는 web, conversational, STEM & logic, code, legal, biomedical에서 zerank-2가 가장 높고, finance에서는 Gemini listwise가 0.7694로 zerank-2 0.7600보다 높다.
이 역시 “reranking은 후보 생성기와 evaluation set 위에서 봐야 한다”는 좋은 reminder다.
넷째, rate limit과 가격은 모델 선택만큼 중요하다.
Free tier 기준 fast latency mode는 500,000 UTF-8 bytes/min과 100 RPM, slow mode는 5,000,000 UTF-8 bytes/min과 100 RPM으로 표시된다.
Starter, Teams, Enterprise로 갈수록 fast/slow byte limit과 RPM이 올라간다.
문서는 latency를 지정하지 않으면 fast를 먼저 시도하고, fast limit을 넘으면 slow로 fallback한다고 설명한다.
반대로 latency="fast"를 명시하면 fallback 대신 429를 받을 수 있다.
| 항목 | 문서 기준 값 | 운영상 해석 |
|---|---|---|
| Embed/Rerank max payload | 5,000,000 bytes/request | 긴 문서 후보를 한 번에 많이 넣는 설계는 요청 크기부터 점검해야 함 |
| Free fast limit | 500,000 UTF-8 bytes/min, 100 RPM | 프로토타입에는 충분하지만 대량 reranking에는 빠르게 부족해질 수 있음 |
| Free slow limit | 5,000,000 UTF-8 bytes/min, 100 RPM | throughput은 크지만 latency가 수 초 이상으로 늘 수 있음 |
zembed-1 가격 |
$0.050 / 1M tokens | embedding 저장 비용과 호출 비용을 분리해서 봐야 함 |
zerank-* 가격 |
$0.025 / 1M tokens | 후보 수와 query 길이가 실제 reranking 비용을 좌우함 |
| Search API | OCR $1.75/1,000 pages, indexing $0.50/MB, storage $0.10/MB/month, queries $1.50/TB queried | managed search를 쓰면 모델 inference 외 비용 항목도 생김 |
실무 관점에서의 해석
내가 보기에 ZeroEntropy Models 문서의 가치는 개별 benchmark headline보다 검색 시스템의 운영 단면을 한 곳에 모아 놓은 점에 있다.
많은 모델 릴리스는 “우리 embedding이 MTEB에서 강하다”거나 “우리 reranker가 더 정확하다”에서 끝난다.
ZeroEntropy는 그다음 질문, 즉 API로 쓸지, self-host할지, zsearch에 맡길지, 차원과 encoding format을 어떻게 줄일지, rate limit을 어떻게 처리할지까지 문서 surface에 올려둔다.
특히 RAG 팀에게 중요한 선택지는 두 갈래다.
이미 자체 ingestion과 vector DB가 있는 팀은 zembed-1과 zerank-2를 독립 모델 endpoint나 Hugging Face weight로 붙여 볼 수 있다.
반대로 PDF/OCR/chunking/query orchestration까지 같이 해결해야 하는 팀은 zsearch 경로를 검토할 수 있다.
같은 모델군이 두 경로를 모두 지원한다는 것은 migration이나 A/B test 측면에서 장점이다.
하지만 도입 전에 조심할 점도 분명하다.
첫째, 공개 weight와 상업 사용 가능성은 같은 말이 아니다.
4B flagship 모델들은 CC-BY-NC-4.0으로 표시되고, 문서도 commercial setting에서는 ZeroEntropy에 연락하라고 안내한다.
둘째, 모델 카드의 benchmark는 유용하지만, 사내 corpus의 query distribution, 언어, chunking, top-k 후보 품질을 대체하지 않는다.
특히 한국어·코드·의료·법률처럼 도메인별 용어와 권한 정책이 강한 환경에서는 자체 held-out query set으로 reranker gain을 다시 측정해야 한다.
셋째, latency mode는 단순한 속도 옵션이 아니라 제품 정책이다.
자동 fallback은 장애를 줄여 주지만 tail latency를 키울 수 있고, fast 고정은 latency SLO를 지키는 대신 429 handling을 애플리케이션에 넘긴다.
또한 reranker byte 계산은 query가 각 document마다 반복 계산되는 구조라, top-100을 항상 rerank하는 설계와 top-20만 rerank하는 설계의 비용 차이가 곧바로 드러난다.
요약하면 ZeroEntropy의 Models 문서는 “retrieval 모델 카탈로그”보다 “검색 품질 운영 매뉴얼”에 가깝다. zembed-1은 후보 recall과 저장 비용을 조절하는 embedding 계층이고, zerank-2는 production relevance의 마지막 정렬 계층이며, zsearch는 그 둘을 OCR·chunking·hybrid retrieval·metadata filtering과 묶는 managed search 계층이다.
RAG 제품을 만드는 팀이라면 여기서 볼 것은 단순한 leaderboard 순위가 아니라, retrieval quality를 모델 선택에서 운영 정책까지 이어 붙이는 방식이다.