RAG와 semantic search에서 embedding 모델을 바꾸는 일은 생각보다 비싸다.
모델 하나를 더 빠른 것으로 교체하고 싶어도, 이미 인덱싱된 문서 벡터가 새 모델의 벡터 공간과 호환되지 않으면 전체 corpus를 다시 인코딩해야 한다.
모델 크기별 선택지는 많아졌지만, 같은 model family 안에서도 작은 모델과 큰 모델의 embedding geometry가 맞지 않는 경우가 대부분이다.
LEAF: Knowledge Distillation of Text Embedding Models with Teacher-Aligned Representations는 이 병목을 “작은 모델을 따로 잘 학습한다”가 아니라 작은 모델을 teacher의 embedding space에 직접 정렬한다는 문제로 바꾼다.
MongoDB Research가 공개한 mdbr-leaf-ir와 mdbr-leaf-mt는 모두 23M parameter 수준의 compact embedding 모델이지만, 각각 더 큰 teacher가 만든 representation을 근사하도록 학습된다.
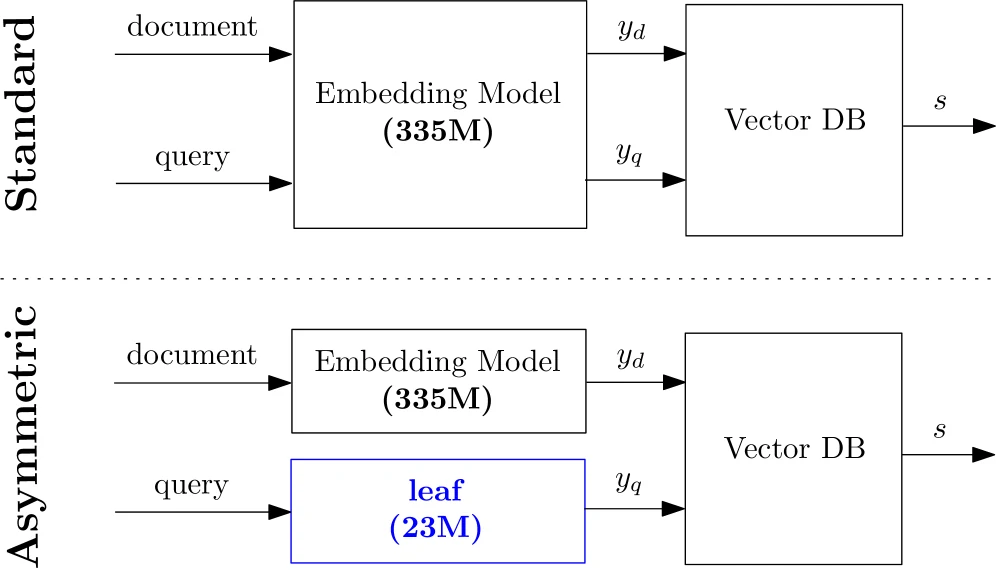
이 정렬이 중요한 이유는 비대칭 검색 구조 때문이다.
문서 embedding은 index time에 한 번만 만들면 되므로 큰 teacher를 써도 된다.
반면 사용자 query는 매 요청마다 인코딩되므로 latency와 운영비가 민감하다.
LEAF는 문서는 teacher로, query는 작은 leaf 모델로 인코딩해도 같은 벡터 공간에서 similarity를 계산할 수 있게 만드는 방향을 제시한다.
무엇을 해결하려는가
일반적인 bi-encoder retrieval에서는 query encoder와 document encoder가 같은 모델이거나, 적어도 같은 훈련 체계에서 나온 호환 가능한 encoder여야 한다.
큰 embedding 모델이 더 좋은 recall을 내더라도 query path에 그대로 올리면 사용자 요청마다 큰 모델을 실행해야 하고, 작은 모델로 바꾸면 기존 document index를 다시 만들 가능성이 높다.
또 다른 병목은 학습 데이터다.
강한 embedding 모델을 contrastive loss로 훈련하려면 query-document judgment, hard negative, 큰 batch가 필요하다.
공개 benchmark에서는 가능해 보이지만, 실제 조직 내부 검색에서는 품질 좋은 relevance label과 hard negative를 계속 유지하는 것이 쉽지 않다.
LEAF의 문제 정의는 더 단순하다. teacher embedding model이 이미 좋은 벡터 공간을 만들었다면, 작은 student가 그 공간 자체를 근사하면 된다.
즉 “어떤 문서가 어떤 query에 정답인가”를 새로 학습하기보다, (text, teacher embedding) pair를 만들어 teacher의 mapping function을 따라가게 한다.
이 접근은 특히 검색 인프라 관점에서 의미가 있다.
문서 index는 큰 teacher로 만들어 품질을 유지하고, query path에는 작은 모델을 둬 latency를 낮출 수 있다.
이미 teacher 기반 문서 벡터를 갖고 있는 팀이라면, 작은 leaf query encoder는 전체 재색인 없이 serving cost를 줄이는 compatibility layer가 될 수 있다.
핵심 아이디어 / 구조 / 동작 방식
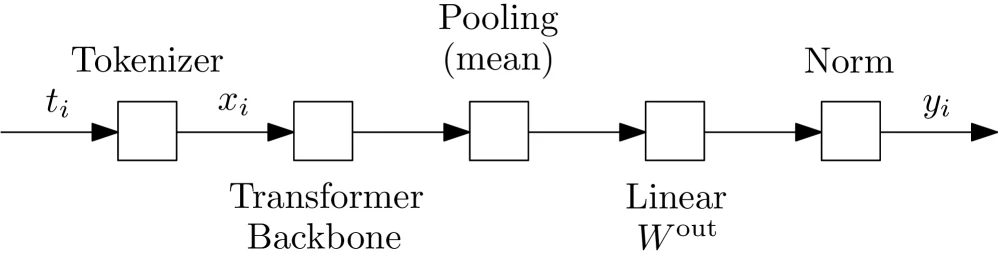
LEAF 모델 구조는 의도적으로 단순하다.
논문 구현은 MiniLM-L6-v2 계열 23M parameter encoder backbone 위에 mean pooling을 두고, teacher의 embedding dimension에 맞추는 linear projection을 붙인다. teacher가 normalized vector를 출력하는 경우에는 마지막에 normalization을 둔다.
학습 목표도 단순하다.
각 text t_i에 대해 teacher가 만든 embedding ŷ_i를 미리 계산해 두고, student output y_i가 이 벡터와 가까워지도록 L2 approximation error를 줄인다.
논문이 강조하는 장점은 이 loss가 teacher 내부 구조를 요구하지 않는다는 점이다. attention head 수, tokenizer, hidden dimension, layer 수가 달라도 되고, keys/queries/values 같은 내부 representation에 접근할 필요도 없다.
이 점 때문에 LEAF는 black-box teacher에도 적용 가능하다. teacher API로 텍스트별 embedding만 얻을 수 있으면 (text, embedding) training tuple을 만들 수 있다.
또한 contrastive learning과 달리 query-document judgment나 hard negative를 쓰지 않는다.
논문은 일부 원천 데이터가 judgment를 포함하더라도, LEAF loss 계산에는 그 judgment를 사용하지 않는다고 명시한다.
훈련 데이터는 document segment와 query segment를 함께 쓴다.
문서 쪽에는 FineWeb, CC-News, BERT vocabulary token, 그리고 저자들이 만든 Vocabulary 데이터셋이 들어간다.Vocabulary는 영어 단어 47.9만 개 목록을 바탕으로 Claude 3.5 Sonnet에게 정의나 중요한 사실을 생성하게 만든 데이터셋이다.
Query 쪽에는 Amazon QA, LoTTE, MSMARCO, PubMedQA, TriviaQA 등이 포함된다.
논문은 query-only보다 문서와 query를 함께 쓸 때 downstream 성능이 더 좋아진다고 보고한다.
훈련 설정도 큰 cluster를 전제로 하지 않는다.
논문 기준 AdamW, batch size 32, 10 epoch짜리 linear decay cycle 3회, 총 30 epoch를 사용하며 teacher embedding은 미리 캐시한다.
저자들은 두 공개 모델을 각각 단일 NVIDIA A100 40GB GPU, 100시간 예산 안에서 훈련했다고 설명한다.
공개 모델은 두 갈래다.
| 모델 | teacher | 목적 | output dimension | 공개 형태 |
|---|---|---|---|---|
MongoDB/mdbr-leaf-ir |
Snowflake/snowflake-arctic-embed-m-v1.5 |
information retrieval / RAG 검색 | 768 | Sentence Transformers, ONNX, Transformers.js |
MongoDB/mdbr-leaf-ir-asym |
query: leaf-ir, document: arctic teacher | 비대칭 retrieval 패키징 | teacher space | Sentence Transformers router-style package |
MongoDB/mdbr-leaf-mt |
mixedbread-ai/mxbai-l-v1 |
classification, clustering, STS, retrieval 등 multi-task | 1024 | Sentence Transformers, ONNX, Transformers.js |
MongoDB/mdbr-leaf-mt-asym |
query: leaf-mt, document: mxbai teacher | 비대칭 multi-task/retrieval 패키징 | teacher space | Sentence Transformers router-style package |
Hugging Face API 기준 네 모델은 gated가 아니며, model card는 Apache 2.0 license를 표시한다.
또한 mdbr-leaf-ir model card는 MongoDB Research ML team이 개발했지만 작성 시점에는 MongoDB의 상용 제품·서비스에 사용되지 않는다고 적고 있다. arXiv abs/html과 GitHub repository search에서 별도 공식 training code repository는 확인되지 않았으므로, 공개 surface는 논문과 Hugging Face 모델 카드·checkpoint 중심으로 보는 편이 정확하다.
공개된 근거에서 확인되는 점
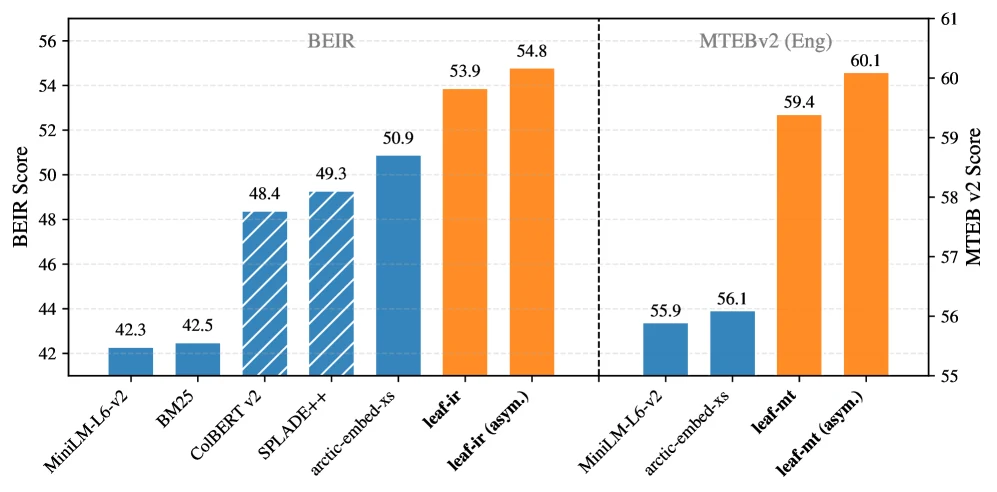
논문의 첫 번째 결과는 information retrieval용 leaf-ir다. leaf-ir는 109M parameter teacher를 23M 모델로 압축한 결과이고, BEIR benchmark에서 compact retrieval model 기준 강한 점수를 보고한다.
논문 Table 1 기준 standard mode의 평균 nDCG@10은 53.9, asymmetric mode는 54.8이다. teacher인 arctic-embed-m-v1.5의 56.1에 꽤 가까우며, 같은 23M급 arctic-embed-xs의 50.9보다 높다.
| 모델 | 크기 | 평가 / 모드 | 평균 점수 | 논문이 강조하는 해석 |
|---|---|---|---|---|
leaf-ir |
23M | BEIR, standard | 53.9 nDCG@10 | teacher 성능의 96.1% 유지, 9/14 dataset에서 비교군 SOTA |
leaf-ir (asym.) |
23M query + 109M doc teacher | BEIR, asymmetric | 54.8 nDCG@10 | standard보다 11/14 dataset에서 개선, teacher 성능의 97.7% |
arctic-embed-xs |
23M | BEIR baseline | 50.9 nDCG@10 | 같은 크기대의 기존 compact baseline |
arctic-embed-m-v1.5 |
109M | teacher | 56.1 nDCG@10 | 문서 인코딩에 쓸 수 있는 큰 teacher 기준점 |
두 번째 결과는 multi-task embedding용 leaf-mt다.
여기서는 335M parameter mxbai-l-v1 teacher를 23M 모델로 더 공격적으로 압축한다.
MTEB v2 English에서 leaf-mt standard는 평균 59.4, asymmetric mode는 60.1을 기록한다. teacher의 62.0에는 못 미치지만, MiniLM-L6-v2 55.9와 arctic-embed-xs 56.1을 확실히 넘는다.
| 모델 | 크기 | 평가 / 모드 | 평균 점수 | 해석 |
|---|---|---|---|---|
leaf-mt |
23M | MTEB v2 English, standard | 59.4 | teacher 성능의 95.8%, 5/7 task group에서 compact SOTA로 보고 |
leaf-mt (asym.) |
23M query + 335M doc teacher | MTEB v2 English, asymmetric | 60.1 | reranking/retrieval 쪽 개선으로 평균 상승 |
MiniLM-L6-v2 |
23M | MTEB v2 English baseline | 55.9 | 같은 backbone 계열의 기본 compact baseline |
mxbai-l-v1 |
335M | teacher | 62.0 | multi-task teacher 기준점 |
흥미로운 부분은 성능만이 아니다.
논문은 LEAF가 teacher의 Matryoshka Representation Learning(MRL)과 quantization robustness를 별도 학습 없이 상속한다고 주장한다.
MRL은 embedding dimension을 잘라 저장 비용을 줄이는 기법이고, quantization은 float32 대신 int8 또는 binary로 저장해 메모리와 검색 비용을 줄이는 방향이다.
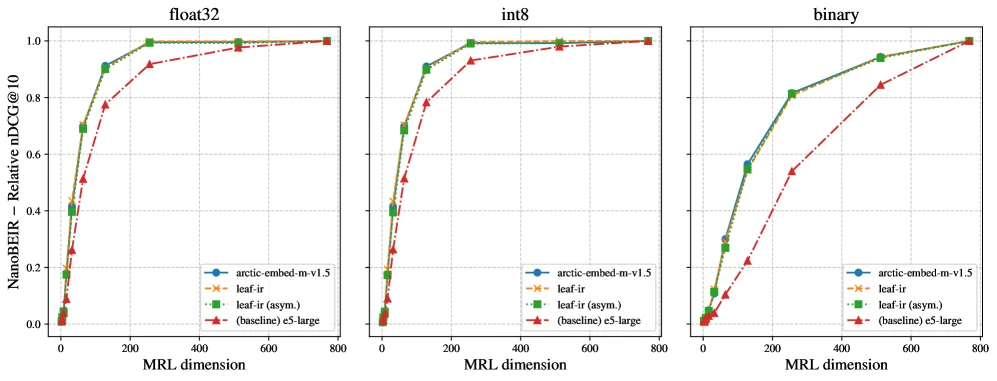
Figure 6은 leaf-ir의 MRL truncation과 quantization 성능 곡선이 teacher와 거의 비슷한 profile을 갖는다고 보여 준다. int8에서는 float32와 가까운 형태로 유지되고, binary에서는 낮은 dimension에서 성능 손실이 커지지만 MRL을 학습하지 않은 e5-large baseline보다 낮은 dimension에서 더 안정적인 곡선을 보인다.
실무적으로는 “작은 query encoder”뿐 아니라 “짧거나 quantized된 vector로 저장하는 검색 비용 절감”까지 같은 설계 안에 들어온다는 의미다.
CPU inference 결과도 실전형 근거에 가깝다.
저자들은 AWS EC2 i3.large 인스턴스, 즉 2 vCPU와 15.25GB RAM을 가진 CPU-only VM에서 ONNX Runtime으로 측정한다. leaf-ir는 document throughput에서 teacher 대비 6.5배, query throughput에서 7.3배 빠르다. leaf-mt는 teacher가 더 크기 때문에 docs/query에서 각각 24.4배, 23.7배 speedup을 보인다.
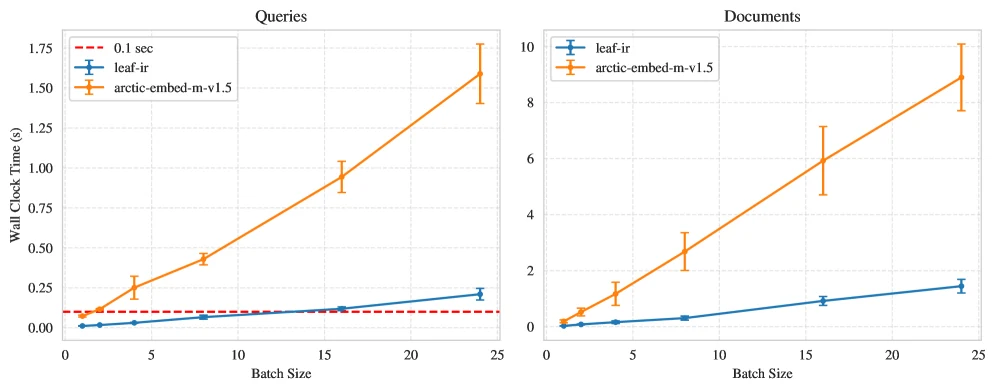
| 비교 | docs/s speedup | query/s speedup | batch 1 query latency | 의미 |
|---|---|---|---|---|
leaf-ir vs arctic-embed-m-v1.5 |
6.5× | 7.3× | 11.4ms vs 73.2ms | retrieval query path에서 지연시간 절감 |
leaf-mt vs mxbai-l-v1 |
24.4× | 23.7× | 11.5ms vs 236ms | 큰 multi-task teacher를 작은 online encoder로 대체 가능 |
현재 Hugging Face 배포도 사용 경로를 꽤 넓게 열어 둔다. mdbr-leaf-ir와 mdbr-leaf-mt는 sentence-transformers, ONNX 파일, Transformers.js 태그와 예제 notebook을 포함한다.
API 조회 시점 기준 mdbr-leaf-ir는 downloads 91,503 / likes 66, mdbr-leaf-mt는 downloads 3,451 / likes 26으로 표시된다.
이 숫자는 Hub API의 현재 값이므로 장기 성숙도보다 배포가 실제로 공개되어 있음을 확인하는 신호로 읽는 편이 안전하다.
실무 관점에서의 해석
LEAF의 핵심 가치는 “23M embedding 모델이 점수가 좋다”보다 embedding model compatibility를 학습 목표로 정면에 놓았다는 점이다.
많은 검색 시스템은 이미 document index를 갖고 있고, 그 index를 만드는 데 시간과 비용을 썼다.
문서 쪽은 큰 모델로 천천히 처리하고, query 쪽은 작은 모델로 빠르게 처리할 수 있다면 serving cost 구조가 달라진다.
이 관점은 embedding distillation을 product infrastructure 문제로 바꾼다.
기존의 작은 embedding 모델은 “큰 모델보다 싸지만 다른 공간을 만든다”에 가까웠다.
LEAF식 모델은 “큰 모델의 공간에 맞춰진 작은 online encoder”다.
즉 vector DB, RAG retrieval, semantic cache, agent memory처럼 query traffic이 계속 발생하는 시스템에서 더 직접적인 운영 가치를 갖는다.
또 하나의 장점은 학습 요구사항이 낮다는 점이다.
L2 representation matching은 화려하지 않지만, judgment와 hard negative 없이 dense supervision을 제공한다. teacher embedding을 많이 찍어 낼 수 있는 조직이라면, 내부 corpus와 query distribution에 맞춘 작은 encoder를 만들 가능성을 열어 준다.
특히 teacher가 API 형태의 black-box여도 적용 가능하다는 점은 기업 환경에서 중요하다.
다만 caveat도 분명하다.
첫째, 논문과 공개 모델은 영어만 학습·평가했다.
한국어 문서, code search, multilingual RAG로 확장되는지는 별도 검증이 필요하다.
둘째, Hugging Face config 기준 공개 모델의 max sequence length는 512다.
긴 문서를 직접 하나의 embedding으로 처리하는 use case에서는 chunking과 indexing 전략이 여전히 중요하다.
셋째, 비대칭 구조는 “언제나 재색인이 필요 없다”는 뜻이 아니다.
문서가 이미 teacher space로 인코딩되어 있거나, 앞으로 teacher로 인덱싱할 계획일 때 leaf query encoder가 빛난다.
기존 index가 전혀 다른 모델의 벡터 공간에 있다면 여전히 migration cost가 있다.
또한 teacher를 바꾸면 그 teacher space에 맞춘 leaf 모델도 다시 필요해진다.
마지막으로, 공개 release는 모델 중심이다.
논문은 training recipe와 dataset 구성을 자세히 설명하지만, 별도의 공식 구현 repository는 확인되지 않았다.
따라서 LEAF는 당장 pip package처럼 가져다 쓰는 training framework라기보다, 공개 checkpoint와 논문으로 검증된 distillation pattern에 가깝다.
검색팀이 바로 활용할 수 있는 것은 mdbr-leaf-ir 계열의 serving path이고, 자체 teacher에 맞춘 leaf 모델을 만들려면 논문 recipe를 재구현해야 한다.
그럼에도 LEAF가 제시하는 방향은 꽤 실용적이다. embedding 모델 경쟁이 benchmark 점수 경쟁에 머무르면 운영자는 매번 “성능이 오른 대신 index를 다시 만들 것인가”라는 질문을 받는다.
LEAF는 이 질문을 “큰 teacher의 embedding space를 유지하면서 query path만 작게 만들 수 있는가”로 바꾼다.
RAG와 vector search가 더 큰 규모의 제품 인프라가 될수록, 이런 compatibility-first distillation은 단순한 compression 기법이 아니라 검색 시스템 설계의 한 축이 될 가능성이 있다.