에이전트 시스템에서 점점 더 중요한 질문은 “가장 강한 모델 하나를 붙이면 끝나는가”가 아니다.
실제 복잡한 작업은 검색, 코드 실행, 함수 호출, 도메인별 특화 모델, 범용 대형 모델을 언제 어떤 순서로 부를지 결정하는 문제가 더 커진다.
다시 말해 병목은 모델의 순수 추론 능력만이 아니라, 여러 도구와 모델을 얼마나 경제적으로 조합하느냐로 이동하고 있다.
NVIDIA의 Nemotron-Orchestrator-8B는 바로 이 지점을 정면으로 겨냥한다.
Hugging Face 모델 카드는 이를 “complex, multi-turn agentic tasks”를 해결하기 위한 8B orchestration model로 소개하고, 연결된 논문과 프로젝트 이름은 ToolOrchestra다.
핵심 발상은 하나의 거대 monolithic model이 모든 하위 문제를 직접 풀도록 하기보다, 비교적 작은 orchestrator가 더 강한 모델과 도구들을 상황별로 호출해 전체 시스템 지능을 끌어올리자는 것이다.
내가 보기엔 이 모델의 흥미로운 점은 단순히 “작은 모델이 큰 모델을 호출한다”는 데 있지 않다.
더 중요한 것은 이 호출 정책 자체를 reinforcement learning으로 학습했다는 점이다.
어떤 답이 맞는지뿐 아니라, 얼마의 비용과 지연으로 그 답에 도달했는지, 그리고 사용자가 선호한 도구를 얼마나 잘 따랐는지까지 보상 설계에 넣었다.
즉 Nemotron-Orchestrator-8B는 또 하나의 foundation model이라기보다, 비용·지연·선호도를 함께 최적화하는 agent control policy에 더 가깝다.
무엇을 해결하려는가
이 모델이 푸는 문제는 frontier model을 더 크게 만드는 것이 아니다.
오히려 이미 존재하는 여러 모델과 도구를 어떻게 조합해야, 복잡한 멀티턴 작업에서 정확도는 유지하거나 높이면서도 비용과 latency를 낮출 수 있는가에 가깝다.
논문은 Humanity’s Last Exam(HLE) 같은 난도 높은 문제에서 단일 강모델이 여전히 강력한 generalist이지만, 계산 비용이 크고 tool-use 정책도 비효율적일 수 있다고 본다.
특히 공개 자료가 반복해서 강조하는 문제는 두 가지다.
첫째, 프롬프트만으로 오케스트레이션을 시키면 모델이 자기와 계열이 비슷한 도구나 가장 강한 도구를 과도하게 호출하는 bias가 생긴다.
논문은 이를 self-enhancement bias와 strongest-tool defaulting 문제로 설명한다.
둘째, 기존 tool-use agent는 정답률을 높이는 방향에는 신경을 쓰지만, 실제 서비스 운영에서 중요한 비용·속도·사용자 선호까지 함께 제어하는 경우는 드물다.
Nemotron-Orchestrator-8B는 이 공백을 메우려 한다.
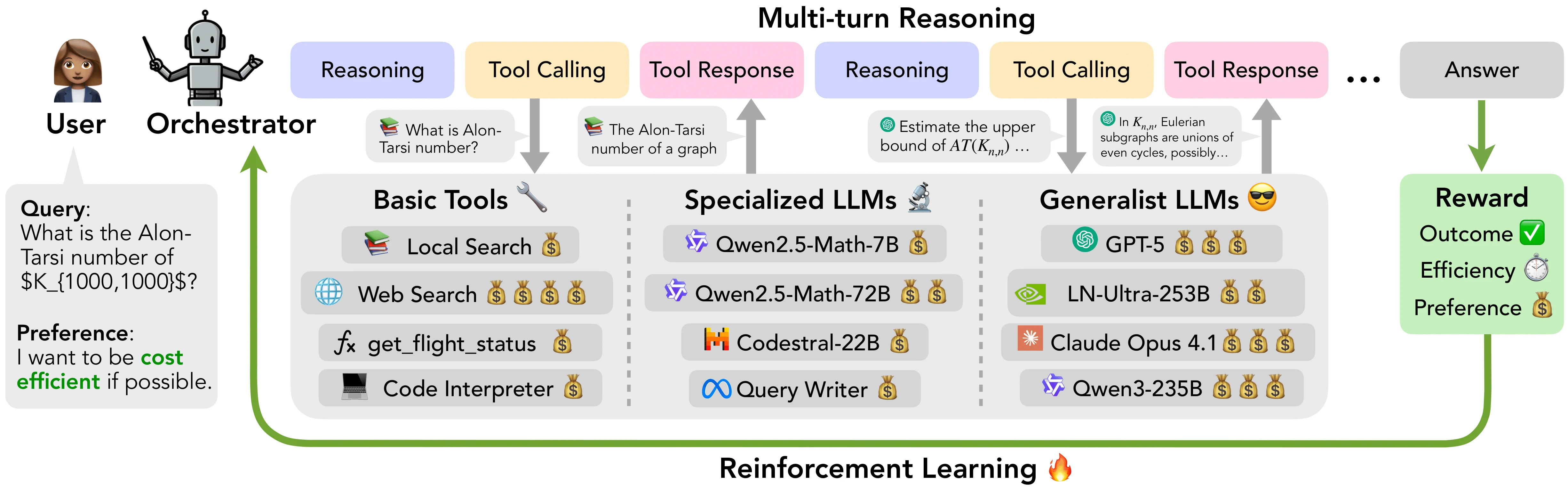
작은 orchestrator가 기본 도구(web search, code interpreter, 함수 호출)뿐 아니라 coding/math용 specialized LLM, GPT-5나 Claude Opus 4.1 같은 generalist LLM까지 포함한 heterogeneous toolset을 조율한다.
목적은 단순한 정답률 최대화가 아니라, “이 작업에는 어떤 도구를 어느 정도까지 써야 가장 합리적인가”를 학습하는 것이다.
핵심 아이디어 / 구조 / 동작 방식
구조적으로 보면 Nemotron-Orchestrator-8B는 Qwen3-8B를 기반으로 파인튜닝된 decoder-only orchestration model이다.
Hugging Face API와 모델 카드 기준 base model은 Qwen/Qwen3-8B, 파라미터 수는 8B, config의 max_position_embeddings는 40,960, weight는 7개 safetensors shard로 공개되어 있다.
모델과 데이터에는 NVIDIA License가 붙어 있으며, 라이선스 본문은 비상업적 연구 사용 제한을 포함한다.
중요한 것은 이 8B 모델이 직접 모든 하위 문제를 끝까지 푸는 것이 아니라, 다단계 reasoning–tool calling 루프의 중심 controller 역할을 맡는다는 점이다.
논문과 프로젝트 페이지를 종합하면 동작 루프는 비교적 명확하다.
사용자의 과제가 들어오면 Orchestrator는 현재 상태를 보고 reasoning을 수행하고, 그다음 어떤 도구나 어떤 모델을 부를지 선택한다.
호출 결과가 observation으로 다시 들어오면 이를 바탕으로 다음 행동을 결정한다.
이 과정을 여러 턴 반복하면서 최종 답을 만든다.
즉 단발성 function calling이 아니라, 상태를 보며 도구 시퀀스를 계획하고 수정하는 multi-turn policy다.
ToolOrchestra의 핵심 차별점은 reward design에 있다. arXiv 초록과 본문에 따르면 이 모델은 outcome reward(문제를 맞췄는가), efficiency reward(비용·지연을 얼마나 줄였는가), preference reward(사용자가 선호하는 도구 정책을 얼마나 따랐는가)를 함께 사용하는 RL로 학습된다.
논문 본문은 이 setup을 end-to-end agentic reinforcement learning으로 설명하고, 자동 데이터 합성 파이프라인을 통해 복잡한 multi-turn tool-use training example을 대규모로 만든다고 말한다.
또한 도구 노출 방식도 실용적이다.
논문은 모든 도구를 JSON 기반의 unified tool interface로 노출한다고 설명한다.
여기에 deterministic utility뿐 아니라 다른 LLM도 하나의 tool처럼 넣는다.
다시 말해 Nemotron-Orchestrator-8B의 진짜 역할은 “답변 생성기”보다 “도구 스케줄러”에 가깝다.
어느 문제에 search를 쓰고, 어느 문제에 code interpreter를 쓰고, 언제 더 강한 generalist model에 하위 작업을 넘길지 결정하는 시스템 브레인인 셈이다.
| 레이어 | 공개 자료에서 확인되는 구성요소 | 역할 |
|---|---|---|
| Base model | Qwen3-8B 기반 8B decoder-only model | 경량 orchestrator 본체 |
| Tool space | 검색, 코드 실행, 함수 호출, specialized LLM, generalist LLM | 문제별로 다른 지능·비용 프로파일을 가진 도구 풀 |
| Policy loop | reasoning → tool call → observation 반복 | 멀티턴 에이전트 제어 |
| RL objective | outcome + efficiency + preference rewards | 정확도뿐 아니라 비용·지연·사용자 선호까지 최적화 |
| Training data | ToolScale + 자동 합성된 multi-turn tool-use examples | orchestration policy 학습용 환경/과제 공급 |
공개된 근거에서 확인되는 점
Hugging Face 모델 카드와 논문 초록, NVIDIA 프로젝트 페이지가 공통으로 제시하는 대표 수치는 꽤 선명하다.
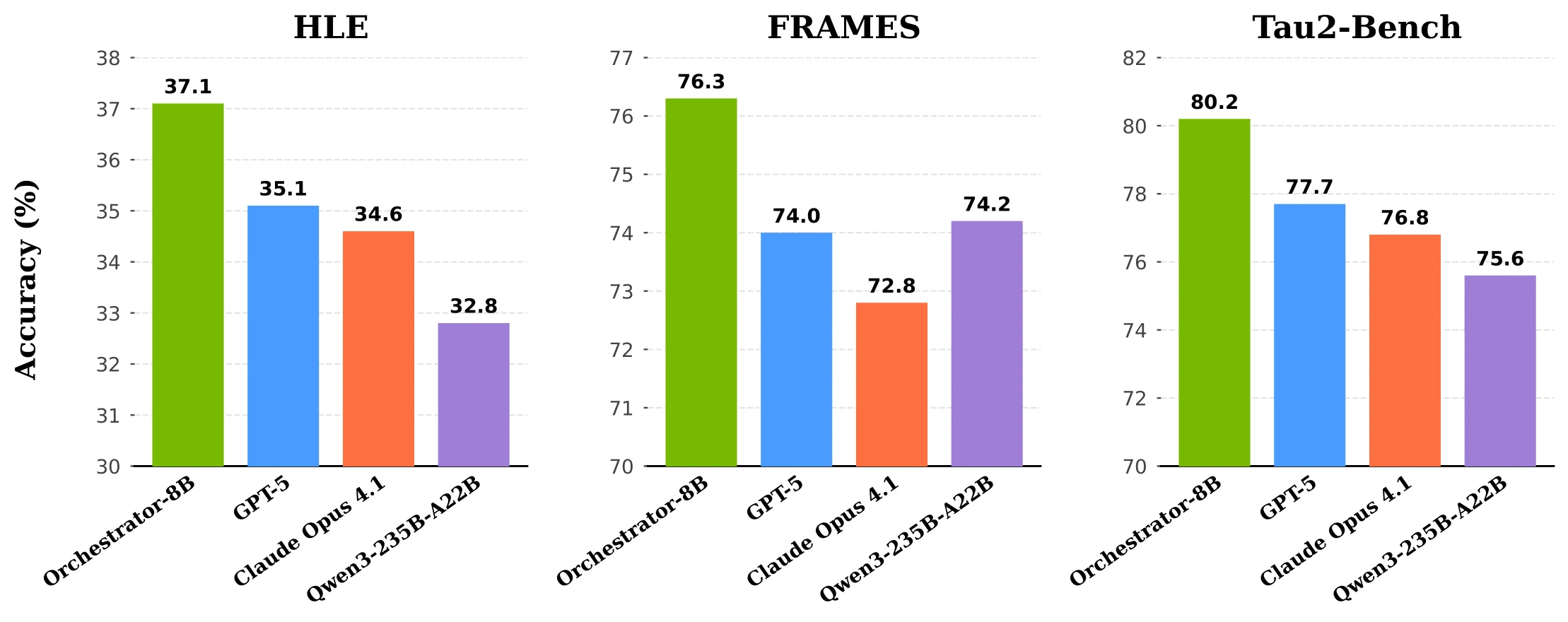
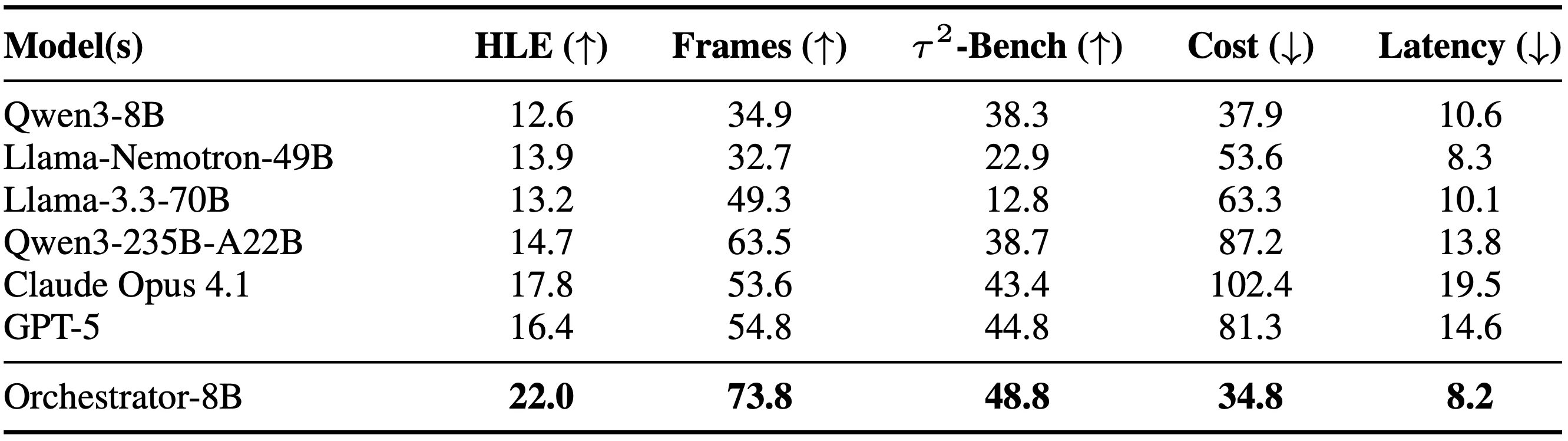
HLE에서 Nemotron-Orchestrator-8B는 37.1%를 기록했고, 비교 기준으로 제시된 GPT-5는 35.1%다.
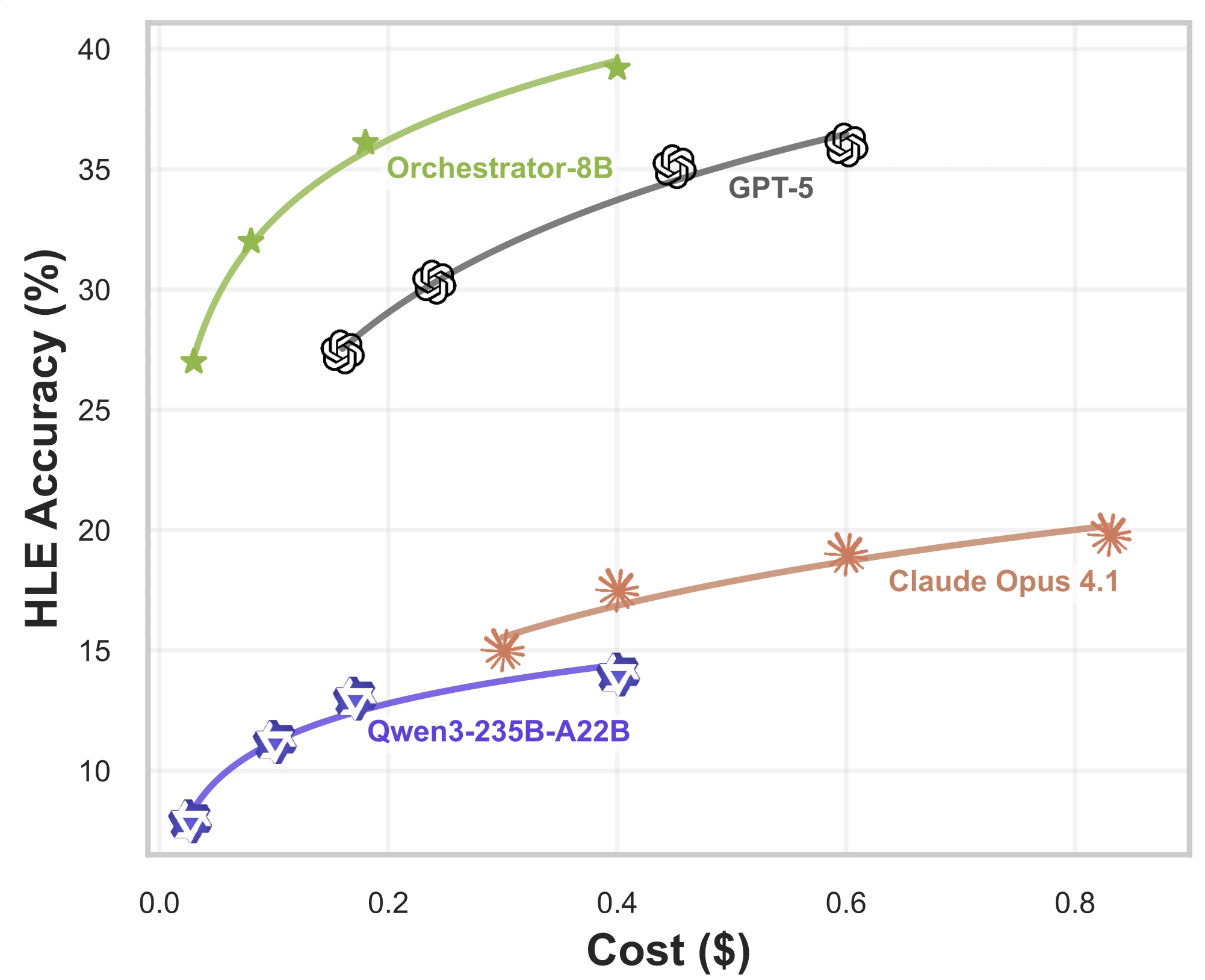
같은 공개 자료는 이 모델이 GPT-5 대비 약 2.5배 더 효율적이며, FRAMES와 τ²-Bench에서는 약 30% 수준의 비용만으로 더 강한 결과를 보인다고 주장한다.
프로젝트 페이지는 비용-성능 그래프와 unseen tools/generalization 분석도 함께 제시한다.
여기서는 Nemotron-Orchestrator-8B가 단순히 더 싼 도구를 쓰는 것이 아니라, test-time에서 performance-cost trade-off가 더 좋고, 훈련 때 보지 못한 도구에서도 성능과 비용 측면의 개선을 유지한다고 설명한다.
또한 tool distribution 분석에서는 특정 도구 하나에 과도하게 쏠리지 않고 보다 balanced tool call pattern을 보인다고 주장한다.
데이터와 구현 공개 범위도 확인 가능하다.
2026년 5월 25일 KST 기준 Hugging Face 모델 API에서 이 모델은 public·ungated 상태이며, 2025-11-25에 생성되고 2025-12-02에 마지막 수정되었다.
API 카운터는 downloads 10,004, likes 571로 표시되고, repository에는 19개 파일과 7개 safetensors shard가 있으며 model.safetensors.index.json의 total size는 약 32.76GB다.
모델 카드에는 훈련 데이터로 GeneralThought-430K와 nvidia/ToolScale가 적혀 있다.
ToolScale 데이터셋도 public·ungated이고, default train split은 4,063 examples, 단일 parquet 파일, downloads 1,239, likes 197로 확인된다.
각 샘플은 user scenario, evaluation criteria, tool-call action schema 등을 포함하므로, 단순 instruction dataset이 아니라 환경과 성공 조건이 함께 정의된 agent-training dataset이라는 점이 드러난다.
코드 저장소도 구현 난도를 보여준다.
GitHub API 기준 NVlabs/ToolOrchestra는 Apache-2.0 code license, 729 stars, 100 forks, 17 open issues, 기본 브랜치 main으로 확인되지만, /releases/latest는 404이고 tags도 비어 있다.
README에는 HLE, FRAMES, τ²-Bench 평가 스크립트, retrieval 환경, vLLM 모델 서빙, flash-attn, flashinfer, tau2-bench 로컬 설치, Tavily·W&B·NGC 등 다수의 인증 키와 모델 호스팅 설정이 등장한다.
이것은 ToolOrchestra가 “모델 하나 다운로드해서 바로 끝”인 패키지가 아니라, 꽤 복합적인 실험·평가·서빙 스택 위에서 돌아가는 연구 시스템임을 시사한다.
| 공개 근거 | 확인된 내용 | 해석 |
|---|---|---|
| Hugging Face 모델 카드 | HLE 37.1%, GPT-5 35.1%, 약 2.5x 효율, FRAMES/τ²-Bench에서 약 30% 비용 | orchestration policy의 비용-성능 포지셔닝을 전면에 둠 |
| arXiv 초록 | outcome/efficiency/preference-aware reward, unseen tools generalization | 단순 tool-use prompting이 아니라 RL 기반 policy 학습 |
| NVIDIA 프로젝트 페이지 | balanced tool calls, unseen tools 성능, preference reward 우위 시각화 | 정책 품질을 정확도 외 지표로도 설명 |
| HF API / model metadata | public·ungated, base model=Qwen3-8B, 8B, 7 safetensors shards, 약 32.76GB total size, downloads 10,004, likes 571 | 연구용 공개 모델이자 실제 checkpoint 배포 surface 보유 |
| GitHub repo | Apache-2.0 code license, 729 stars, 100 forks, 17 issues, releases/tags 없음 | 관심도는 높지만 아직 versioned release라기보다 연구 코드베이스에 가까움 |
| ToolScale dataset card | public·ungated, 4,063 train examples, downloads 1,239, likes 197, NVIDIA License | agent environment 중심 데이터 설계이지만 model/data license는 code license와 다름 |
실무 관점에서의 해석
내가 보기에 Nemotron-Orchestrator-8B의 진짜 의미는 “작은 모델이 큰 모델을 이긴다”는 자극적인 비교보다, 에이전트 시스템의 가치가 점점 single-model quality보다 orchestration policy quality로 이동하고 있음을 보여준다는 점이다.
강한 LLM 하나를 모든 단계에 쓰는 전략은 간단하지만, 비용이 비싸고 특정 도구 편향이 생기기 쉽다.
반면 이 모델은 더 약한 본체가 도구 선택을 잘하면 전체 시스템이 오히려 더 똑똑하고 더 싸질 수 있다는 방향을 실험적으로 밀어붙인다.
특히 agent product를 운영하는 팀에게는 시사점이 크다.
대부분의 실제 시스템은 이미 검색, 사내 함수, 코드 실행, 외부 API, 여러 벤더 모델을 함께 쓴다.
그렇다면 다음 경쟁력은 foundation model을 하나 더 바꾸는 일이 아니라, 어떤 작업에서 어떤 리소스를 얼마만큼 쓰게 할 것인지 정책을 학습하거나 제어하는 능력이 될 가능성이 높다.
Nemotron-Orchestrator-8B는 그 정책층을 독립 모델로 분리해 다루는 사례다.
물론 한계도 분명하다.
공개 자료 스스로도 larger-than-8B scaling이 아직 확인되지 않았고, broader domains 예컨대 code generation이나 실제 웹 interaction 전반에 대한 검증은 제한적이라고 적고 있다.
또한 코드 저장소가 보여주듯 재현과 운영 환경은 결코 가볍지 않다.
여러 서빙 백엔드, 외부 API 키, 평가용 환경 구성이 필요하며, 코드 라이선스는 Apache-2.0인 반면 모델과 데이터는 NVIDIA License의 비상업적 연구 사용 제한을 갖는다.
따라서 모델 카드만 보고 곧바로 production-ready orchestration layer라고 받아들이기는 어렵다.
그럼에도 이 모델은 에이전트 연구의 다음 초점을 꽤 잘 드러낸다.
앞으로는 “더 큰 모델”만이 아니라 “더 좋은 조율자”가 중요해질 가능성이 크다.
그런 관점에서 Nemotron-Orchestrator-8B는 하나의 8B model release가 아니라, tool-augmented reasoning 시스템에서 control policy 자체를 학습 가능한 핵심 자산으로 본다는 선언에 가깝다.