온디바이스 LLM에서 “추론이 된다”는 말은 서버 LLM에서의 추론과 조금 다르다.
클라우드에서는 긴 chain-of-thought를 몇천 토큰씩 생성하고, 여러 후보를 샘플링하고, 별도 verifier로 고르는 방식이 비교적 자연스럽다.
하지만 스마트폰이나 edge device에서는 그 긴 trace가 곧 지연 시간, 전력, KV cache, 메모리 대역폭 문제로 바뀐다.
사용자의 간단한 질의까지 매번 reasoning mode로 처리하면, 모델이 똑똑해진 것이 아니라 배터리와 대기 시간을 태우는 시스템이 된다.
Qualcomm AI Research의 Efficient Reasoning on the Edge는 이 병목을 정면으로 다룬다.
논문은 Qwen2.5-7B-Instruct를 기반으로 reasoning 능력을 붙이되, 전체 모델을 항상 무겁게 돌리지 않는다.
핵심은 reasoning을 LoRA adapter로 분리하고, adapter가 켜졌을 때도 budget forcing으로 trace를 짧게 만들며, 애초에 reasoning이 필요 없는 질문은 switcher가 base model로 우회시키고, 메모리-bound decoding 구간에서는 병렬 생성과 경량 verifier로 정확도를 끌어올리는 것이다.
마지막에는 4-bit weight quantization과 Qualcomm FastForward / GENIE SDK 기반 배포 경로까지 붙인다.

내가 보기에 이 논문의 가치는 “작은 reasoning model을 만들었다”보다 더 구체적이다.
온디바이스 reasoning을 항상 켜진 모델 능력이 아니라 필요할 때 켜고, 짧게 쓰고, 병렬 자원을 활용하고, 양자화된 runtime으로 내리는 실행 정책으로 재정의한다는 점이 중요하다.
무엇을 해결하려는가
논문이 출발하는 문제는 세 가지다.
첫째, reasoning trace가 길다. chain-of-thought는 복잡한 문제에서 성능을 올리지만, 수천 토큰의 중간 추론을 생성한다.
프로젝트 페이지는 CoT trace가 4,000 tokens를 넘을 수 있고, 이로 인해 모바일 메모리 대역폭과 KV cache footprint가 바로 병목이 된다고 설명한다.
둘째, latency가 커진다. reasoning trace는 한 토큰씩 autoregressive하게 생성되므로, 스마트폰에서는 최종 답을 받기까지 몇 분이 걸릴 수 있다.
온디바이스 AI의 장점은 private data를 기기 안에 두고, 네트워크 왕복 없이 반응하는 것인데, reasoning trace가 너무 길면 이 장점이 사라진다.
셋째, 대부분의 질의에는 그런 reasoning이 필요 없다.
“오늘 일정 보여줘”, “이 문장 번역해줘”, “이 버튼 어디 있어?”
같은 요청은 긴 수학 풀이형 CoT가 필요하지 않다.
그런데 reasoning model을 항상 같은 방식으로 돌리면 단순 chat에도 비싼 경로를 사용한다.
논문은 이 낭비를 줄이기 위해 base instruct model과 reasoning adapter mode를 분리한다.
| 병목 | 논문이 보는 원인 | 제안하는 대응 |
|---|---|---|
| 메모리 / KV cache | 긴 CoT와 긴 context가 KV cache를 키움 | base prompt KV를 재사용하는 masked LoRA training |
| 지연 시간 | reasoning token을 순차 생성 | budget forcing으로 trace 길이 축소 |
| 일상 질의 낭비 | 모든 요청에 reasoning을 적용 | switcher가 reasoning 필요 여부를 판단 |
| 정확도와 latency 절충 | 더 많이 샘플링하면 느려짐 | memory-bound decoding에서 parallel responses와 verifier 사용 |
| 배포 비용 | 7B 모델과 adapter를 기기에 올려야 함 | W4A16KV8, INT8 KV/cache 요소, FastForward/GENIE 경로 |
이 표에서 핵심은 “모델 하나”가 아니라 “실행 경로”다.
논문은 reasoning을 학습하는 방법, 켜는 방법, 짧게 만드는 방법, 여러 후보를 검증하는 방법, 그리고 양자화해서 기기에 올리는 방법을 한 흐름으로 본다.
LoRA reasoning adapter: 추론 능력을 backbone 밖으로 분리한다
첫 번째 구성요소는 LoRA다.
논문은 Qwen2.5-3B-Instruct와 Qwen2.5-7B-Instruct를 실험 backbone으로 사용하고, reasoning 능력을 dense fine-tuning이 아니라 Low-Rank Adapter로 붙인다.
이유는 명확하다.
LoRA adapter는 base model과 분리되어 있으므로 runtime에서 켜고 끌 수 있다. base model은 일반 chat을 담당하고, 복잡한 문제에서는 reasoning adapter를 활성화한다.
학습 데이터로는 두 계열을 비교한다.
Mixture of Thoughts는 DeepSeek-R1에서 distill된 350k reasoning traces이고, OpenThoughts3-1.2M은 math, code, science 영역을 포함한 120만 규모 reasoning dataset이다.
프로젝트 페이지 기준 최종 reasoning adapter는 OpenThoughts3-1.2M으로 학습되며, LoRA rank 128, alpha 256, all linear layers, 5 epochs 구성을 사용한다.
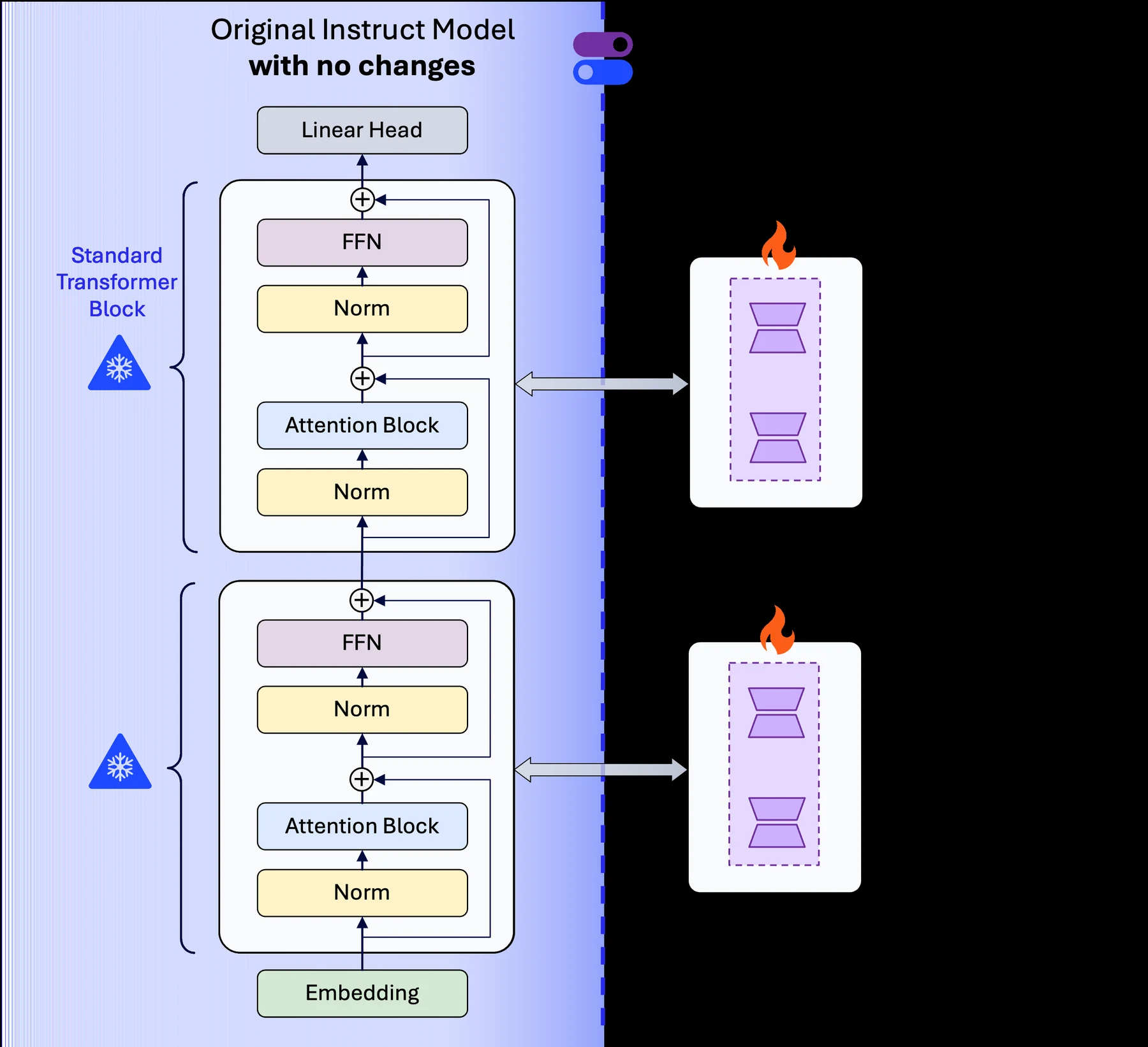
Table 1에서 Qwen2.5-7B 기준 결과를 보면 방향이 분명하다. base Qwen-7B는 AIME25 0.17, MATH500 0.76, GPQA 0.37, AMC23 0.60이다.
OT3 dense fine-tuning은 AIME25 0.54, MATH500 0.95, GPQA 0.47, AMC23 0.89까지 오른다.
LoRA rank 128은 AIME25 0.38, MATH500 0.93, GPQA 0.43, AMC23 0.82로 dense에는 못 미치지만, R1-Distill-Qwen-7B baseline의 AIME25 0.40, MATH500 0.92, GPQA 0.49, AMC23 0.89에 꽤 가까운 영역까지 간다.
논문은 Qwen2.5-7B의 OT3 LoRA rank 128이 dense fine-tuning 대비 4.24%의 parameter만 업데이트한다고 설명한다.
이 수치가 중요하다.
온디바이스 배포에서 adapter는 단순한 parameter-efficient training 기법이 아니라, 같은 frozen backbone 위에서 capability를 모듈처럼 켜고 끄는 배포 단위가 된다.
다만 LoRA만으로는 충분하지 않다. reasoning adapter를 켜면 모델은 여전히 verbose한 CoT를 생성한다.
즉 LoRA는 “추론을 할 수 있게” 만들지만, 모바일에서 “짧고 빠르게” 추론하도록 만들지는 않는다.
그래서 논문은 두 번째 단계로 budget forcing을 넣는다.
Budget forcing: 정답을 유지하면서 “망설임 토큰”을 줄인다
Budget forcing은 reasoning trace의 길이를 직접 줄이기 위한 RL 단계다.
논문은 SFT 후 reasoning model이 장황하고 반복적인 trace를 생성하는 경향이 있다고 본다.
그래서 GRPO 기반 RL에서 reward를 accuracy와 budget compliance의 곱으로 정의한다.
핵심은 단순히 길이에 additive penalty를 붙이는 것이 아니라, 목표 budget 주변에서 piecewise-linear하게 감소하는 soft-barrier reward를 사용한다는 점이다.
논문이 특히 강조하는 부분은 reward hacking이다.
CoT 내부 토큰만 벌점으로 주면 모델이 </think>를 일찍 닫고 final answer 영역에서 계속 장황하게 reasoning을 이어갈 수 있다.
그래서 최종 formulation은 reasoning trace만이 아니라 전체 generation length를 penalize한다.
이는 형식적 꼼수를 줄이고, 실제 사용자가 기다려야 하는 전체 토큰 수를 줄이기 위한 선택이다.

정량 결과는 budget별로 보면 더 이해하기 쉽다.
MATH500에서 forced budget을 1K, 2K, 4K, 6K로 제한했을 때 SFT baseline은 각각 34%, 57%, 73%, 83%다.
반면 budget-forced RL 모델은 βKL=1e-3 설정에서 62%, 78%, 85%, 90%를 기록하고, βKL=1e-4 설정에서는 72%, 80%, 84%, 85%를 기록한다.
32K처럼 사실상 긴 budget을 허용하면 SFT baseline의 average가 95%, BF 모델이 92% 또는 90%로 내려가지만, 제한된 budget 구간에서는 오히려 budget-forced 모델이 더 잘 버틴다.
| MATH500 설정 | SFT baseline | BF RL βKL=1e-3 | BF RL βKL=1e-4 |
|---|---|---|---|
| Budget 1K | 34% | 62% | 72% |
| Budget 2K | 57% | 78% | 80% |
| Budget 4K | 73% | 85% | 84% |
| Budget 6K | 83% | 90% | 85% |
| Average, 32K budget | 95% | 92% | 90% |
이 결과를 “항상 더 정확하다”로 읽으면 안 된다.
긴 budget을 넉넉히 주면 baseline이 더 높은 경우가 있다.
하지만 모바일 배포에서는 32K completion을 마음껏 쓰는 것이 목적이 아니다.
논문이 말하는 practical trade-off는 짧은 budget에서도 정답률을 유지하고, 평균 trace를 줄여 time-to-final-answer를 낮추는 것이다.
질적 예시도 흥미롭다.
논문 Figure 6과 7은 baseline이 정답 전략을 초반에 찾고도, 같은 계산을 여러 방식으로 반복 검증하면서 2,8003,100 tokens를 쓰는 사례를 보여 준다. budget-forced trace는 같은 문제를 559810 tokens로 푼다.
여기서 줄어드는 것은 “추론 깊이”라기보다, 이미 충분한 근거가 있는데도 계속 확인하는 epistemic hesitation에 가깝다.
Switcher: reasoning을 매번 켜지 않는다
세 번째 구성요소는 dynamic LoRA routing이다.
모든 prompt에 reasoning adapter를 켜는 대신, switcher가 prompt hidden state를 보고 reasoning이 필요한지 분류한다.
구조는 꽤 작다. base LLM의 final transformer layer hidden states를 평균 pooling하고, hidden dimension 8의 작은 MLP classifier를 붙인다.
ReLU와 dropout 0.2를 사용한다.
온디바이스 prefill은 긴 prompt를 한 번에 처리하기 어렵기 때문에, 논문은 chunked prefill도 고려한다. switcher는 전체 hidden state를 저장해 평균내는 대신, chunk size 128과 smoothing coefficient α=0.5의 running exponential moving average를 사용한다. quantization artifact에 견디도록 training 중 averaged representation에 Gaussian noise도 주입한다.
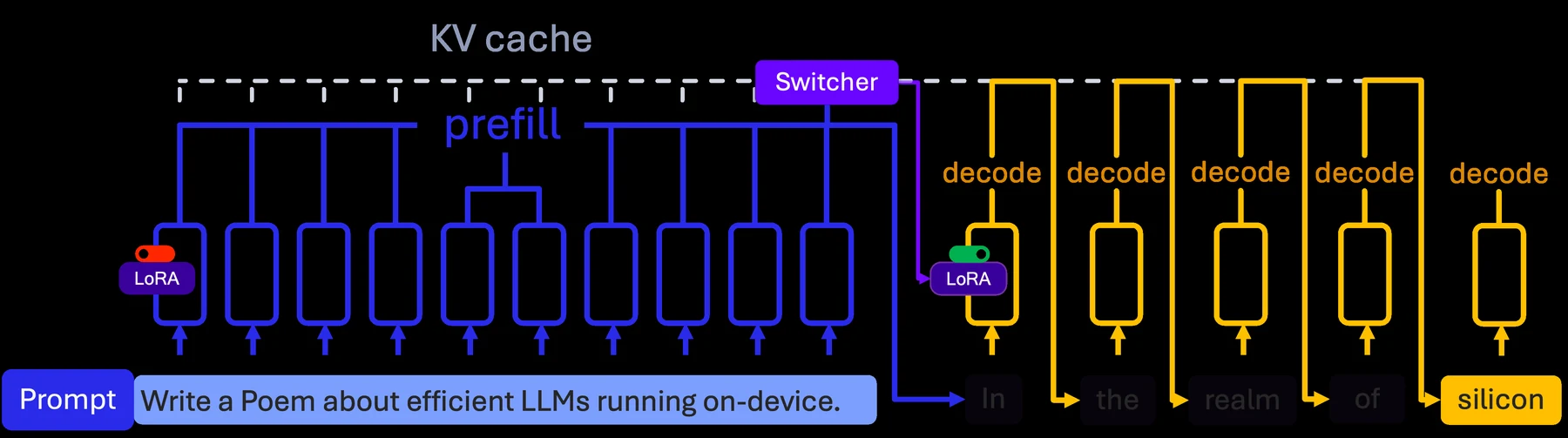
여기서 가장 중요한 시스템 디테일은 masked LoRA training for KV-cache reuse다.
일반적으로 LoRA를 켠 모델은 prompt prefill 단계에서도 LoRA가 적용된 KV cache를 기대한다.
그런데 switcher가 prompt를 본 뒤에야 reasoning mode를 켜기로 결정한다면, 이미 base model로 만든 prompt KV cache를 버리고 LoRA를 켠 상태로 다시 prefill해야 할 수 있다.
모바일에서는 이것이 큰 지연 비용이다.
논문은 이를 피하기 위해 reasoning adapter 학습 중 prompt token forward에서는 LoRA를 disable하고, response token generation에서만 LoRA를 activate한다.
이렇게 하면 reasoning LoRA adapter가 base model이 만든 prompt KV cache를 조건으로 decode하는 데 적응한다.
결과적으로 chat mode와 reasoning mode가 같은 prompt KV cache를 공유하고, adapter activation 때문에 prompt를 다시 encode하지 않아도 된다.
Switcher 실험은 MATH500에서 threshold를 바꾸며, prompt 중 얼마를 reasoning adapter로 보낼지 조절한다. base instruct mode는 76.4%, reasoning-only mode는 93.0% accuracy로 표시된다. switcher threshold를 조정하면 reasoning으로 보내는 비율과 average completion length가 같이 올라가고, 정확도도 부드럽게 상승한다.
즉 switcher는 단일 정답이 아니라, 제품 요구에 따라 latency와 accuracy operating point를 고르는 knob에 가깝다.
Parallel verification: decoding이 memory-bound일 때 병렬 후보를 활용한다
Budget forcing은 순차 생성 길이를 줄인다.
하지만 modern mobile processor에서는 다른 기회도 있다. autoregressive decoding은 매 token마다 layer weights를 불러오는 memory-bound 성격이 강하다.
이때 여러 reasoning trajectory를 병렬로 생성하면, latency 증가를 완전히 선형으로 내지 않고도 더 많은 후보를 탐색할 수 있다.
논문은 이 병렬 생성에 lightweight verifier를 결합한다.
별도의 verifier model을 로드하면 edge device에서는 storage, memory movement, latency가 커진다.
대신 같은 generator representation 위에 작은 verifier head를 붙인다.
구체적으로 final token embedding에 separate linear layer와 sigmoid를 적용해 correctness score를 만든다.
그리고 각 후보 response 뒤에 짧은 verification prompt를 붙여, verifier가 “이 풀이가 맞는가”를 판단하도록 한다.
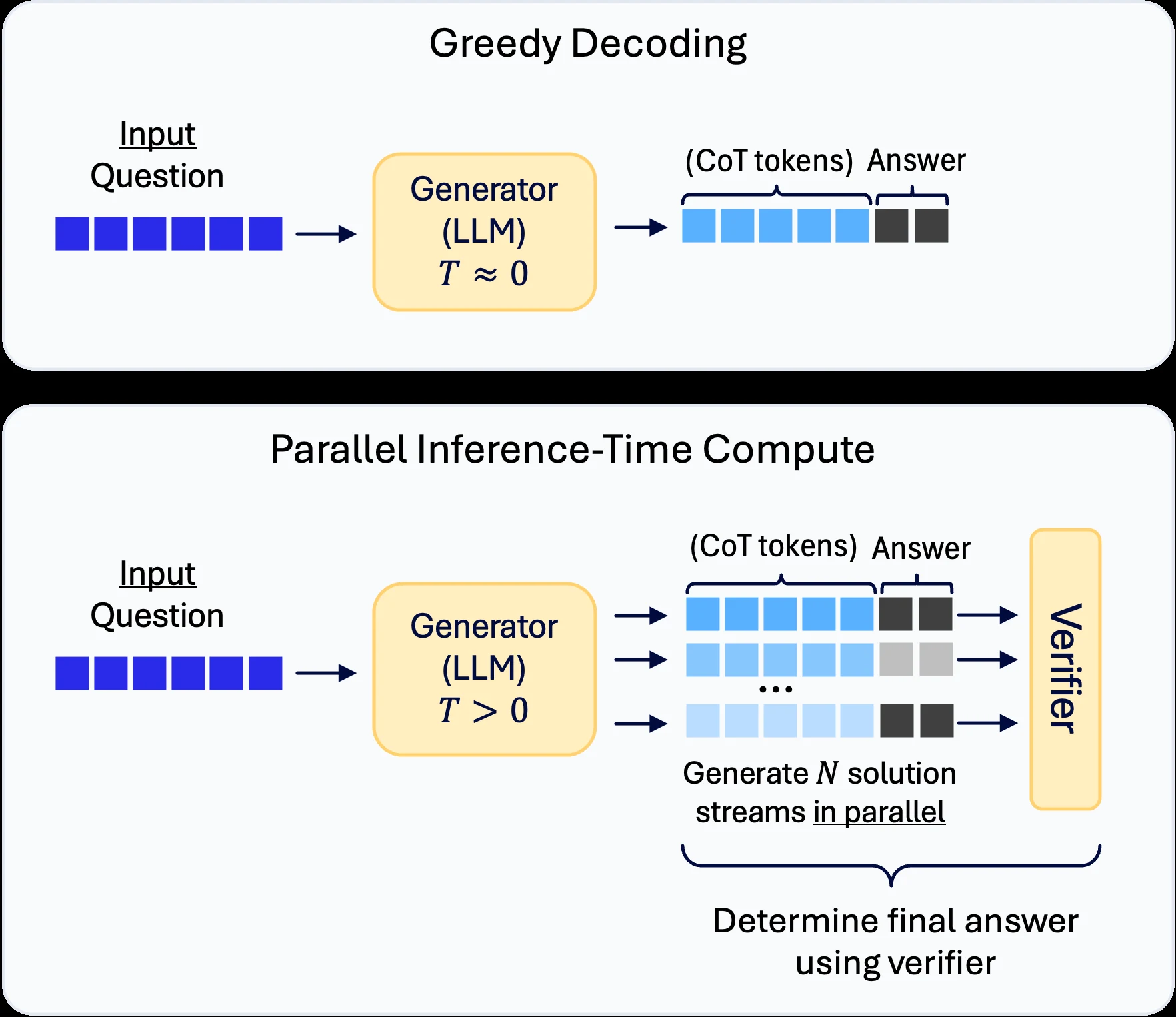
집계 방식은 majority voting과 verifier score를 결합한 weighted majority vote다.
후보 답을 단순히 빈도수로 세지 않고, verifier가 높게 평가한 후보에 더 큰 weight를 준다.
MATH500에서 4-bit-weight-quantized Qwen2.5-7B-Instruct responses 16개 중 random draw를 사용한 Table 9 결과는 다음과 같다.
| Parallel responses | Greedy baseline | Majority vote | Weighted MV |
|---|---|---|---|
| 1 | 71.0 | 69.9 ± 1.3 | 69.9 ± 1.3 |
| 2 | - | 70.0 ± 1.3 | 72.7 ± 1.0 |
| 4 | - | 75.1 ± 1.0 | 76.1 ± 0.9 |
| 6 | - | 76.6 ± 1.0 | 77.5 ± 0.8 |
| 8 | - | 77.5 ± 0.8 | 78.2 ± 0.7 |
논문은 8 parallel responses에서 weighted majority voting이 baseline 대비 약 10% 개선된다고 설명한다.
절대값으로는 greedy 71.0에서 weighted MV 78.2로 오른다.
더 중요한 시스템 포인트는 verifier가 별도 대형 모델이 아니라는 점이다.
논문 표현대로 verifier overhead는 stream당 사실상 extra token 하나에 가까우며, generator의 KV cache를 재사용하므로 prompt와 response를 별도 verifier model로 다시 처리하는 비용을 피한다.
Quantization과 배포: 논문은 모델이 아니라 “기기까지 가는 경로”를 다룬다
마지막 축은 quantization과 deployment다.
논문은 Qwen2.5-7B-Instruct base model에 대해 모든 linear layer와 LM head를 INT4 per-channel uniform affine quantization으로 낮추고, KV cache와 input embeddings는 INT8, 나머지 activations는 INT16을 사용하는 W4A16KV8 설정을 사용한다.
단순 min-max quantization은 WikiText-2 perplexity 102.4, CSR 51.71, MMLU 62.35로 크게 무너지지만, FPTQuant 계열 function-preserving transformations와 end-to-end training을 적용하면 WikiText-2 7.26, CSR 72.94, MMLU 72.81까지 회복한다.
BF16 full precision이 각각 6.85, 72.90, 74.28이라는 점을 보면, base model quantization은 꽤 많은 성능을 되찾는다.
Reasoning adapter 쪽도 그냥 붙이면 안 된다.
논문은 quantized base activation distribution 위에서 LoRA를 학습하는 Quantization-Aware Modular Reasoning, 즉 QAMR을 사용한다.
Table 11에서 1.2M OT data로 학습한 BF16 reasoning model은 AIME24 53.3, AIME25 33.0, MATH500 94.0, GPQA 39.9, AMC23 82.5, 평균 60.54다.
W4A16KV8 + FPTQuant + QAMR은 AIME24 46.6, AIME25 36.6, MATH500 89.6, GPQA 37.8, AMC23 80.0, 평균 58.12다.
논문은 이를 full-precision reasoning model 평균과 roughly 2% 이내라고 요약한다.
배포 흐름은 Qualcomm 도구와 연결된다.
FastForward로 quantization과 graph transformation을 수행하고, GENIE SDK가 지원하는 representation에 맞춰 PyTorch graph를 ONNX/DLC 쪽으로 내보내며, target이 Android라면 aarch64-android 대상으로 compile하고 adb로 device에 올리는 경로를 설명한다.
그래서 이 논문은 “벤치마크에서 좋았다”에서 끝나지 않고, 실제 mobile inference engine에 모델·adapter·verifier를 올리기 위해 어떤 제약을 같이 봐야 하는지를 보여 준다.
다만 이 부분은 그대로 제품 성능 보증으로 읽으면 안 된다.
결과는 저자들이 구성한 pipeline과 hardware/runtime assumption 위에서의 author-reported 실험이다.
특정 스마트폰 NPU, OS, 앱 runtime, memory budget, thermal limit에서 같은 latency가 나온다는 의미는 아니다.
오히려 실무적으로는 “이 정도까지 함께 설계해야 온디바이스 reasoning이라고 부를 수 있다”는 checklist에 가깝다.
실무 관점에서의 해석
이 논문은 edge LLM 팀에게 네 가지 질문을 던진다.
첫째, reasoning capability를 checkpoint 내부에 영구적으로 섞을 것인가, adapter로 분리할 것인가.
Adapter로 분리하면 base model을 한 번 로드하고, task별 능력을 필요한 순간에만 켤 수 있다.
이는 개인비서, device control, lightweight chat처럼 요청 난도가 넓게 분포하는 모바일 앱에서 특히 중요하다.
둘째, reasoning budget을 누가 정할 것인가.
서버에서는 long CoT를 넉넉히 허용하고 나중에 답만 보여주는 방식도 가능하지만, 기기에서는 생성 토큰 하나하나가 latency와 battery로 연결된다.
이 논문은 budget forcing을 통해 모델이 “짧게 생각하는 법”을 학습해야 한다고 본다.
단순 truncation이 아니라 RL objective로 trace density를 높이는 방향이다.
셋째, routing policy를 어디에 둘 것인가.
Switcher는 작지만, 제품 관점에서는 꽤 큰 의사결정 장치다.
너무 보수적으로 routing하면 쉬운 질문에도 reasoning adapter가 켜져 비용이 늘고, 너무 공격적으로 우회하면 어려운 질문을 base model이 대충 답할 수 있다.
따라서 switcher threshold는 모델 성능 지표가 아니라 제품의 latency SLA, battery policy, 사용 시나리오와 함께 튜닝해야 한다.
넷째, parallel compute를 정확도 개선에 어떻게 쓸 것인가.
일반적으로 병렬 샘플링은 서버에서나 가능한 사치처럼 보인다.
하지만 논문은 memory-bound decoding에서는 병렬 후보와 경량 verifier가 edge에서도 의미 있는 accuracy/latency trade-off를 만들 수 있다고 주장한다.
물론 이것은 hardware utilization, batching, verifier overhead, thermal behavior를 함께 봐야 하는 문제다.
내가 보기에는 Efficient Reasoning on the Edge가 가장 잘 보여 주는 것은 reasoning model의 배포 단위가 바뀌고 있다는 점이다.
앞으로 온디바이스 LLM은 “몇 B 모델인가”보다, 같은 backbone 위에 어떤 adapter bank를 두는지, 어떤 router가 그것을 켜는지, trace budget을 어떻게 학습시키는지, verifier와 quantization이 runtime에서 실제로 맞물리는지가 더 중요해질 가능성이 높다.
결론: 온디바이스 reasoning은 모델 압축이 아니라 실행 정책이다
이 논문은 cloud reasoning model을 작게 distill해서 스마트폰에 넣으면 끝난다는 접근을 택하지 않는다.
대신 base instruct model, reasoning LoRA adapter, budget-forced RL, switcher, KV-cache sharing, parallel verification, quantization-aware training, FastForward/GENIE deployment를 하나의 시스템으로 묶는다.
그래서 결론은 꽤 실용적이다.
모바일에서 reasoning을 하려면 모델이 똑똑해야 할 뿐 아니라, 언제 reasoning을 켤지, 얼마나 길게 reasoning할지, 여러 후보를 어떻게 싸게 검증할지, 양자화된 backbone과 adapter가 어떤 cache를 공유할지를 함께 설계해야 한다.
Efficient Reasoning on the Edge는 그 설계 공간을 꽤 선명하게 보여 주는 논문이다.
아직 모든 기기와 앱에 바로 꽂을 수 있는 범용 솔루션이라기보다, 온디바이스 reasoning 제품을 만들 때 확인해야 할 시스템 checklist에 가깝다.
하지만 그 checklist 자체가 중요하다. edge LLM 경쟁은 더 작은 checkpoint를 만드는 경쟁에서, 더 작은 실행 경로를 만드는 경쟁으로 이동하고 있다.