RAG와 semantic search를 제품에 넣다 보면, 모델 자체보다 먼저 배포 경계가 문제가 된다.
애플리케이션은 Rust나 Go로 짜여 있는데 embedding은 Python sidecar로 띄우고, reranker는 또 다른 HTTP endpoint로 붙이고, 모델 파일과 tokenizer cache는 운영 환경마다 따로 맞추는 식이다.
이 구조는 빠르게 시작하기에는 좋지만, 로컬·온프레미스·엣지·프라이버시 민감 환경에서는 의존성과 장애 지점이 늘어난다.
fastembed-rs는 이 경계를 Rust 쪽으로 끌어온다.
공식 README는 이 프로젝트를 “Rust library for generating vector embeddings, reranking locally”라고 소개한다.
핵심은 새로운 embedding 모델을 제안하는 것이 아니라, Hugging Face Hub의 공개 모델 자산과 Rust inference runtime을 묶어 텍스트 임베딩, sparse 임베딩, 이미지 임베딩, 후보 reranking을 같은 crate API로 실행하게 하는 데 있다.
작성 시점 GitHub API 기준 저장소는 Apache 2.0 라이선스, 901 stars, 127 forks를 갖고 있고, crates.io의 fastembed 최신 버전은 5.13.4다. crates.io API의 누적 다운로드 값은 1,163,816으로 표시된다.
숫자보다 중요한 것은 release shape다.
이 프로젝트는 단순 예제 repo가 아니라, Cargo package, docs.rs 문서, semantic release, 모델 enum, 테스트까지 갖춘 Rust 검색 인프라 building block에 가깝다.
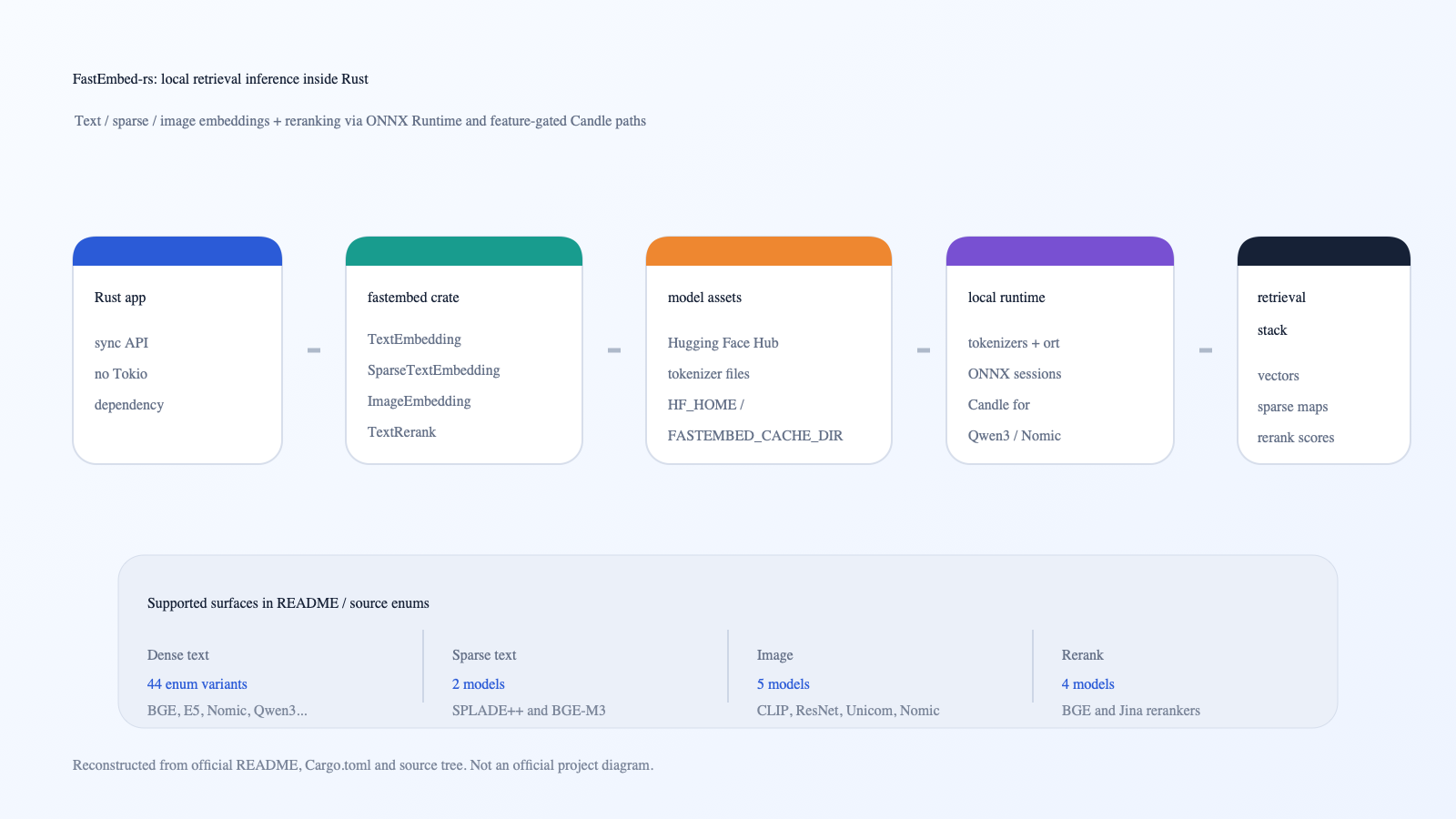
공식 README, Cargo.toml, source enum을 바탕으로 재구성한 로컬 inference pipeline 개념도.
프로젝트 공식 diagram은 아니며, fastembed-rs가 Rust API, Hugging Face 모델 자산, ONNX/Candle runtime, retrieval stack 출력을 어떻게 연결하는지 설명하기 위한 도식이다.
무엇을 해결하려는가
검색형 AI 시스템에서 embedding 단계는 생각보다 운영 색깔이 강하다.
첫 번째 문제는 배포 단위다.
Rust 애플리케이션 안에서 바로 embedding을 만들 수 없다면, Python process나 외부 API를 붙여야 한다.
그러면 latency, 장애 처리, version pinning, cache 위치, 모델 파일 배포가 애플리케이션 경계 밖으로 밀려난다.
두 번째 문제는 retrieval pipeline의 단절이다. dense embedding만 있으면 끝나는 것이 아니다.
BM25류와 섞기 위한 sparse vector, 이미지-텍스트 검색을 위한 vision embedding, first-stage 후보를 다시 정렬하는 reranker가 필요해진다.
각각을 다른 언어·다른 런타임·다른 모델 로더로 붙이면 실험은 가능하지만 운영 surface가 커진다.
fastembed-rs가 해결하려는 지점은 바로 이 얇지만 귀찮은 glue layer다.
Rust 코드에서 cargo add fastembed 후 TextEmbedding, SparseTextEmbedding, ImageEmbedding, TextRerank를 호출해 로컬 inference를 수행한다.
README가 강조하듯 synchronous usage를 지원하고 Tokio 의존성이 없다.
따라서 비동기 서버뿐 아니라 CLI, desktop tool, embedded worker, batch job 같은 환경에서도 비교적 단순하게 붙일 수 있다.
다만 이것을 “벡터 DB 대체재”로 읽으면 안 된다. fastembed-rs는 모델 실행과 후처리 계층이다.
인덱싱, ANN search, metadata filter, 권한 모델, evaluation set, online serving autoscaling은 별도의 시스템 문제로 남는다.
정확한 위치는 Rust-native retrieval application 안에 들어가는 local embedding/reranking runtime이다.
핵심 아이디어 / 구조 / 동작 방식
기본 경로는 간단하다.
사용자가 model enum과 init option을 고르면, fastembed-rs는 Hugging Face Hub에서 모델 파일과 tokenizer 관련 파일을 가져오고, 로컬 cache에 둔 뒤, tokenizer로 입력을 batch encoding한다.
이후 ONNX Runtime 세션을 통해 모델을 실행하고, pooling·normalization·sparse post-processing·score sorting 같은 출력 처리를 Rust 코드 안에서 수행한다.
README의 기본 예제는 다음처럼 생겼다.
use fastembed::{TextEmbedding, InitOptions, EmbeddingModel};
let mut model = TextEmbedding::try_new(
InitOptions::new(EmbeddingModel::AllMiniLML6V2)
.with_show_download_progress(true),
)?;
let documents = vec![
"passage: Hello, World!",
"query: Hello, World!",
"passage: This is an example passage.",
];
let embeddings = model.embed(documents, None)?;
구현을 보면 기본 batch size는 256이고, TextEmbedding::try_new 경로는 ort의 Session::builder()를 사용해 ONNX 모델을 로드한다. tokenizer 쪽은 Hugging Face tokenizers crate를 사용한다. cache는 FASTEMBED_CACHE_DIR 기본값 .fastembed_cache를 쓰되, 내부 다운로드 함수는 HF_HOME이 있으면 그 값을 우선한다.
운영 환경에서는 이 cache 위치를 명시적으로 고정하는 것이 좋다.
흥미로운 점은 ONNX 경로만 고집하지 않는다는 것이다.Cargo.toml에는 기본 기능으로 ort-download-binaries-native-tls, hf-hub-native-tls, image-models가 켜져 있다.
반면 Qwen3 embedding과 Nomic Embed Text v2 MoE는 qwen3, nomic-v2-moe feature flag 뒤에 있고, 이 경로는 candle-core와 candle-nn을 사용한다.
즉 현재 fastembed-rs는 “대부분의 표준 embedding/reranker는 ONNX Runtime으로, 일부 최신 모델군은 Candle backend로” 가져가는 혼합 구조에 가깝다.
지원 surface는 README와 source enum 기준으로 꽤 넓다.
| 영역 | 확인된 지원 범위 | 기본값 / 특징 |
|---|---|---|
| Dense text embedding | source enum 기준 44개 variant | BAAI/bge-small-en-v1.5가 기본값, 일부 quantized variant는 enum 이름에 Q suffix |
| Sparse text embedding | 2개 모델 | prithivida/Splade_PP_en_v1 기본, BAAI/bge-m3 지원 |
| Image embedding | 5개 모델 | Qdrant/clip-ViT-B-32-vision 기본, ResNet50·Unicom·Nomic vision 포함 |
| Reranking | 4개 모델 | BAAI/bge-reranker-base 기본, BGE v2 M3와 Jina reranker 계열 포함 |
| 최신 feature-gated 경로 | Qwen3, Qwen3-VL embedding, Nomic v2 MoE | qwen3, nomic-v2-moe feature로 Candle backend 사용 |
이 조합은 검색 stack의 여러 층을 한 crate 안에서 맞춘다는 점에서 의미가 있다. dense vector를 만들고, sparse vector를 만들고, 이미지 embedding을 만들고, 마지막 후보 reranking까지 같은 API family로 다룰 수 있기 때문이다.
실제 production에서는 이 출력이 Qdrant, LanceDB, Vespa, PostgreSQL+pgvector, 자체 ANN index 등으로 흘러가겠지만, 모델 실행 부분의 언어 경계는 줄어든다.
공개된 근거에서 확인되는 점
가장 먼저 확인되는 것은 패키징 성숙도다.Cargo.toml의 package version은 5.13.4, description은 “Library for generating vector embeddings, reranking locally.”
이며, documentation은 docs.rs, repository는 GitHub, homepage는 crates.io로 연결된다.
GitHub latest release도 v5.13.4이고, 2026년 4월 27일 릴리스 노트에는 Qwen3 F16 dtype mismatch를 attention과 l2_normalize에서 수정했다는 bug fix가 기록되어 있다.
이는 Qwen3 계열 support가 단순 README 문구가 아니라 최근 유지보수 대상이라는 신호다.
두 번째는 dependency 선택이다. ort = =2.0.0-rc.12, tokenizers = 0.22.2, hf-hub = 0.5.0, safetensors = 0.7.0, 선택적 candle-core = 0.10.2, candle-nn = 0.10.2가 보인다.
즉 fastembed-rs는 자체 runtime을 만드는 프로젝트가 아니라, Rust 생태계의 모델 실행·토크나이저·Hub 접근 라이브러리를 조합해 retrieval-friendly API를 제공하는 wrapper에 가깝다.
세 번째는 사용자 정의 모델 경로다.
README는 각 struct의 try_new_from_user_defined(...) 계열 method로 local model files를 사용할 수 있다고 설명한다. source에서도 UserDefinedEmbeddingModel, UserDefinedSparseModel, UserDefinedImageEmbeddingModel, UserDefinedRerankingModel이 노출된다.
이는 사내에서 fine-tuned ONNX 모델을 들고 있거나, Hub 다운로드를 차단한 환경에서 모델 bytes와 tokenizer files를 직접 주입하는 경로가 있다는 뜻이다.
네 번째는 실행 provider에 대한 현실적 처리다.
README는 Windows DirectML을 별도 섹션으로 설명하며, DirectML execution provider를 넘기면 ONNX Runtime session에서 memory pattern optimization과 parallel execution을 자동으로 끈다고 적고 있다. source 코드에서도 DirectML provider가 감지될 때 with_memory_pattern(false)와 with_parallel_execution(false)를 적용하는 흐름이 보인다.
이런 세부 처리는 단순 “GPU 지원” 문구보다 운영적으로 더 중요하다. provider별 제약을 runtime option으로 흘려보내지 않으면, 로컬 inference는 플랫폼마다 깨지기 쉽다.
다만 공개 근거에는 빈칸도 있다.
README는 다양한 모델 지원과 사용 예제를 보여 주지만, 프로젝트 자체의 표준 latency benchmark나 품질 benchmark를 전면에 내세우지는 않는다.
따라서 “fast”라는 이름을 곧바로 특정 처리량 수치로 읽으면 안 된다.
속도와 정확도는 선택한 모델, ONNX/Candle 경로, execution provider, batch size, sequence length, cache warm-up, CPU/GPU 환경에 따라 다시 측정해야 한다.
라이선스는 전반적으로 Apache 2.0으로 확인된다.
GitHub API의 license field, checked-in LICENSE, Cargo.toml, docs.rs version page, crates.io version metadata가 모두 Apache-2.0을 가리킨다.
README badge의 alt text에는 “MIT Licensed”라는 오래된 표현이 남아 있지만, 링크와 실제 license file은 Apache 2.0이다.
공개 repo를 운영에 넣을 때는 이런 작은 metadata drift도 확인하는 편이 좋다.
실무 관점에서의 해석
내가 보기에 fastembed-rs의 가치는 “Rust에서도 embedding을 돌릴 수 있다”보다 조금 더 구체적이다.
검색형 AI 제품에서 모델 실행은 종종 애플리케이션 구조를 바꾼다.
Python service를 하나 더 띄울 것인지, 외부 embedding API를 호출할 것인지, GPU batch server를 둘 것인지, 아니면 로컬 process 안에서 작은 embedding/reranker를 돌릴 것인지가 latency·비용·보안 경계를 결정한다. fastembed-rs는 이 중 로컬 process 안에서 충분히 작은 검색 모델을 직접 실행하는 선택지를 Rust 생태계에 제공한다.
특히 다음 유형의 팀에는 실용적이다.
| 사용 환경 | fastembed-rs가 맞는 이유 | 별도 확인할 점 |
|---|---|---|
| Rust backend의 RAG 전처리 | Python sidecar 없이 embedding 생성 가능 | cache volume, 모델 파일 배포, cold start |
| 온프레미스·프라이버시 민감 검색 | 외부 API 호출 없이 local inference 가능 | 모델 라이선스와 데이터 반출 정책 |
| CLI·desktop·edge tool | synchronous API와 no-Tokio path가 단순함 | CPU 성능, binary size, 모델 다운로드 UX |
| hybrid retrieval 실험 | dense·sparse·rerank surface를 한 crate에서 실험 | vector DB와 evaluation harness는 별도 필요 |
| Windows local inference | DirectML 경로 문서화 | provider별 성능/호환성 재측정 |
반대로 대규모 multi-tenant embedding serving을 원한다면 fastembed-rs만으로는 부족하다. queueing, dynamic batching, autoscaling, per-tenant quota, observability, model rollout, vector index update policy는 별도의 serving/data plane 문제다.
또한 최신 Qwen3, Nomic v2 MoE처럼 feature flag 뒤의 Candle 경로는 빠르게 변하는 영역이다.
최근 릴리스의 Qwen3 F16 bug fix는 유지보수 신호이기도 하지만, 동시에 이 부분을 production에 넣을 때 더 꼼꼼한 regression test가 필요하다는 뜻이기도 하다.
그래도 이 프로젝트의 방향은 중요하다.
RAG 인프라가 성숙할수록 embedding과 reranker는 “LLM 앞단의 작은 유틸리티”가 아니라, 제품 품질과 비용을 좌우하는 별도 runtime layer가 된다. fastembed-rs는 그 layer를 Rust 애플리케이션 내부로 끌고 들어와, 모델 파일·tokenizer·runtime session·post-processing을 하나의 package boundary 안에 묶는다.
좋은 adoption path는 간단하다.
먼저 bge-small, MiniLM, BGE reranker 같은 작은 기본 모델로 local baseline을 만들고, 자체 query set에서 recall@k, nDCG, answer success rate, P50/P95 latency를 재자.
그 다음 dense-only에서 sparse/dense hybrid로 넓히거나, first-stage top-k 뒤에 TextRerank를 붙여 retrieval quality가 실제 답변 품질로 이어지는지 확인하면 된다. fastembed-rs는 이 실험을 대신해 주지는 않지만, Rust 안에서 그 실험을 시작하는 friction을 꽤 낮춰 준다.