RAG 시스템을 만들 때 청킹은 종종 “문서를 몇 토큰씩 자를 것인가”라는 설정값으로 취급된다.
하지만 실제 품질 문제는 그렇게 단순하지 않다.
검색기가 찾는 최소 단위가 곧 청크이고, LLM이 답변을 만들 때 보는 근거도 결국 검색된 청크이기 때문이다.
문서를 어디서 자르느냐는 곧 무엇을 검색 가능한 지식 단위로 인정할 것인가를 정하는 일이다.
요즘IT의 「RAG 애플리케이션 개발을 위한 Chunking 최적화」는 PyCon Korea 2025의 강성우 개발자 발표를 바탕으로 이 문제를 실무자의 언어로 풀어낸다.
글의 중심 메시지는 명확하다.
LLM은 내부에 장기 기억을 갖고 있는 것이 아니라 주어진 context에 의존하며, RAG는 그 context 안에 넣을 근거를 검색으로 고르는 구조다.
따라서 RAG의 성능은 임베딩 모델이나 벡터 DB만이 아니라, 그 전에 만들어지는 청크의 품질에 크게 좌우된다.
특히 흥미로운 지점은 이 글이 고정 크기, 재귀적 청킹, 시맨틱 청킹을 소개하는 데서 멈추지 않고, 메타데이터 보존, 오버랩 병합, contextual retrieval, late chunking, MoC(Mixture-of-Chunkers)까지 이어 간다는 점이다.
즉 청킹을 전처리 스크립트가 아니라 검색 품질을 제어하는 데이터 모델링 계층으로 읽게 만든다.

요즘IT/PyCon Korea 2025 발표 정리 이미지.
질문과 청크를 임베딩 공간에서 비교해 관련 청크를 context에 넣는 RAG 검색 흐름을 단순화해 보여 준다.
무엇을 해결하려는가
RAG의 기본 흐름은 익숙하다.
문서를 청크로 나누고, 각 청크를 임베딩하고, 벡터 DB에 저장한 뒤, 사용자의 질문도 임베딩해서 가까운 청크를 찾는다.
문제는 이 구조에서 검색의 대상이 “문서”가 아니라 “청크”라는 점이다.
답이 문서 안에 있어도, 답을 포함한 의미 단위가 잘못 잘려 있으면 검색기는 온전한 근거를 가져오지 못한다.
작게 자르면 청크는 더 구체적이 된다.
특정 사실이나 문장을 정확히 찾는 데 유리하고, 불필요한 토큰도 줄어든다.
하지만 너무 작으면 “이러한 변화”, “그 결과”, “위 모델”처럼 앞뒤 문맥에 의존하는 표현이 고립된다.
검색된 청크만으로는 무엇을 가리키는지 알 수 없고, LLM은 모호한 근거를 가지고 답해야 한다.
크게 자르면 문맥은 보존된다.
하나의 주장, 배경, 결론이 한 청크에 들어갈 가능성이 높아진다.
대신 청크 안에 여러 주제가 섞이면서 임베딩은 여러 의미의 평균처럼 변한다.
질문과 정확히 맞는 부분이 청크 안에 있어도, 주변 잡음 때문에 검색 순위가 밀릴 수 있고, context window도 빨리 소모된다.

요즘IT/PyCon Korea 2025 발표 정리 이미지.
청크를 너무 작게 자르면 문맥이 끊기고, 너무 크게 자르면 검색 신호가 희석된다.
따라서 청킹 최적화의 핵심 질문은 “512 토큰이 좋은가, 1024 토큰이 좋은가”가 아니다.
더 정확히는 다음 질문에 답해야 한다.
| 질문 | 왜 중요한가 | 대표적으로 봐야 할 신호 |
|---|---|---|
| 사용자의 질문은 사실 조회인가, 설명형인가 | 질문 형태가 필요한 근거 길이를 바꾼다 | query log, FAQ, 실패 답변 사례 |
| 문서는 구조가 강한가, 약한가 | 제목·절·표·코드 블록은 자연스러운 경계가 된다 | Markdown/PDF/HTML 구조, section depth |
| 청크가 독립적으로 의미를 갖는가 | 임베딩과 생성 단계 모두에서 문맥 손실을 줄인다 | 지시어, 대명사, 표/그림 참조, 전후 문장 의존성 |
| 검색 후 청크를 어떻게 합칠 것인가 | overlap과 이웃 청크 검색은 중복·충돌을 만든다 | duplicate rate, context token waste, citation consistency |
| 메타데이터 필터가 필요한가 | 같은 주제라도 연도·권한·문서 버전이 다르면 답이 달라진다 | source, date, tenant, section, page, ACL |
핵심 아이디어 / 구조 / 동작 방식
가장 단순한 방식은 고정 크기 청킹이다.
토큰 수나 글자 수 기준으로 문서를 일정하게 자른다.
구현이 쉽고 baseline으로 좋지만, 문단이나 문장 경계를 무시하면 청크 경계에서 의미가 끊어진다.
그래서 실무에서는 보통 재귀적 청킹이 더 나은 출발점이 된다.
문단, 문장, 공백 같은 구분자를 큰 단위부터 시도하고, 그래도 길면 더 작은 단위로 내려가는 방식이다.
시맨틱 청킹은 한 단계 더 나아가 인접 문장 간 임베딩 유사도를 보고 의미가 가까운 문장을 묶는다.
이름은 매력적이지만, 요즘IT 글이 지적하듯 이것도 완전한 의미 이해라기보다 벡터 근접성에 의존하는 분할이다.
도메인 문서에서는 “표현은 다르지만 같은 절의 일부”인 문장과 “표현은 비슷하지만 다른 맥락”인 문장을 구분해야 하는데, 단순 유사도만으로는 이 경계를 안정적으로 잡기 어렵다.
MoC 논문은 이 한계를 더 정교하게 다루려는 연구 흐름이다.MoC: Mixtures of Text Chunking Learners for Retrieval-Augmented Generation System은 Boundary Clarity와 Chunk Stickiness라는 두 가지 청킹 품질 지표를 제안하고, LLM 기반 청킹의 비용과 정밀도 사이 균형을 맞추기 위해 granularity-aware Mixture-of-Chunkers 구조를 제시한다.
흥미로운 점은 최종적으로 원문에서 청크를 추출할 수 있는 구조화된 정규식 목록을 생성하도록 유도한다는 것이다.
즉 “LLM이 적당히 잘라 준다”가 아니라, 문서에 맞는 분할 규칙을 만들고 적용하는 쪽에 가깝다.
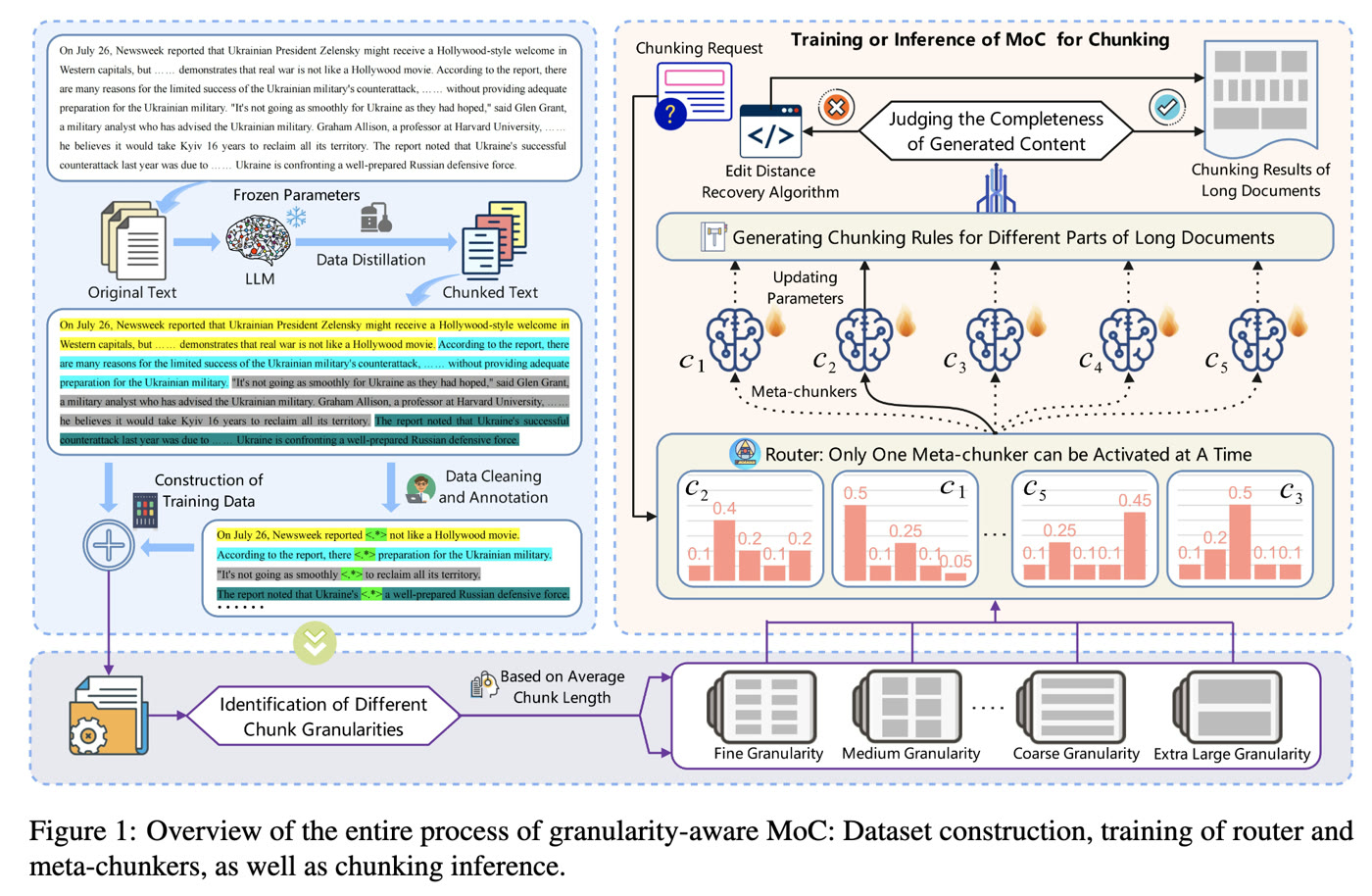
MoC 논문을 인용한 요즘IT/PyCon Korea 2025 발표 정리 이미지.
여러 granularity의 청커와 라우터를 통해 문서 특성에 맞는 분할 정책을 선택하는 구조를 보여 준다.
다만 MoC 같은 학습 기반 접근은 비용과 운영 복잡도가 크다.
모든 팀이 도메인별 청커와 라우터를 유지할 수는 없다.
그래서 실무적으로 더 즉시 효과가 큰 축은 대개 메타데이터와 후처리다.
청크 본문만 저장하는 대신 문서명, 작성일, 버전, 페이지, 섹션 제목, 권한 범위, 앞뒤 청크 ID를 함께 저장하면 검색기가 “비슷한 문장”만이 아니라 “정확한 문맥의 문장”을 고를 수 있다.
오버랩도 같은 맥락에서 봐야 한다. overlap은 청크 경계에서 문장이 잘리는 문제를 완화하지만, 검색 결과를 그대로 이어 붙이면 중복이 생긴다.
코드나 표처럼 구조가 중요한 문서에서는 중복이 단순한 낭비를 넘어 구문 오류나 잘못된 근거 병합으로 이어질 수 있다.
따라서 overlap을 쓴다면 겹친 범위, 원문 offset, 이전·다음 청크 관계를 메타데이터로 남기고, 검색 후 context assembly 단계에서 중복 제거를 해야 한다.
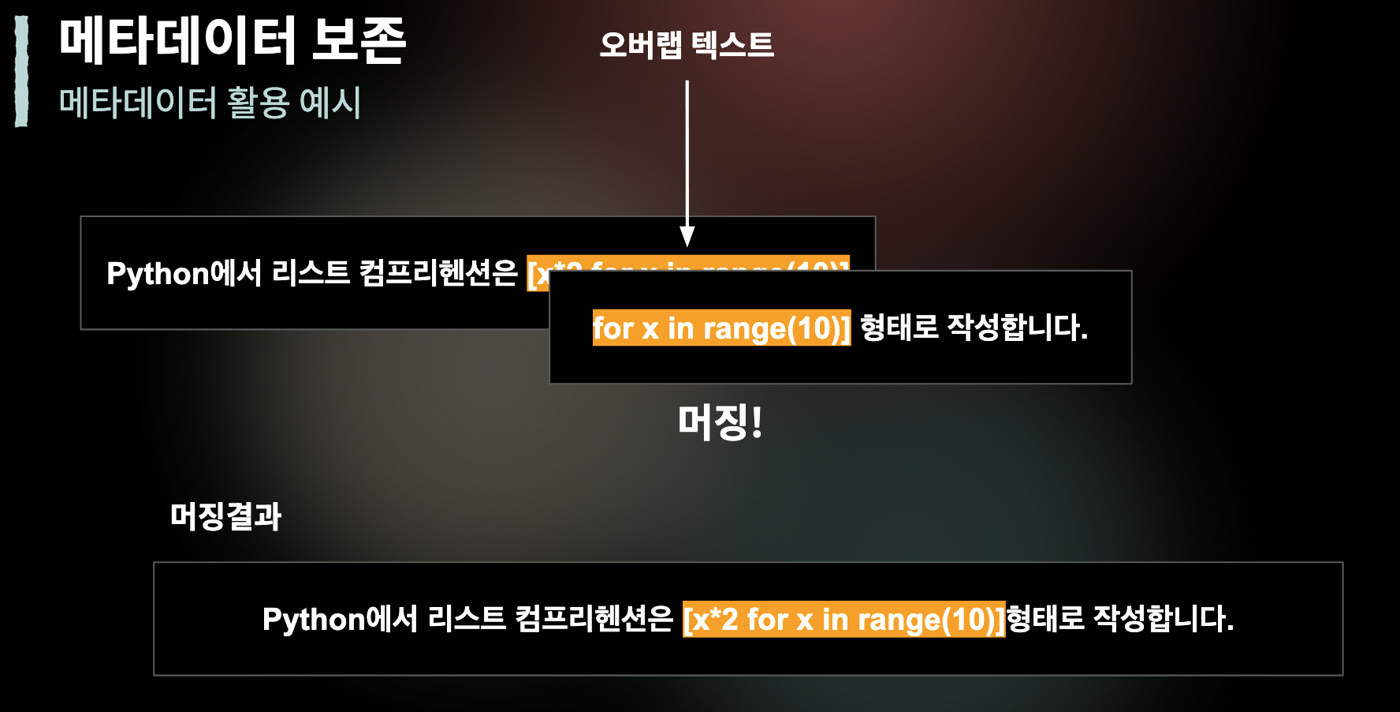
요즘IT/PyCon Korea 2025 발표 정리 이미지. overlap은 경계 문맥을 보존하지만, 검색 후 병합 단계에서는 중복 구간을 제거할 수 있어야 한다.
Contextual retrieval과 late chunking은 청크의 독립성 문제를 다른 방식으로 다룬다. contextual retrieval은 각 청크 앞에 “이 청크는 문서 3.1절의 이미지 모델 성능 평가에 관한 내용” 같은 짧은 설명을 붙여, 작은 청크도 독립적으로 검색될 수 있게 만든다.
반면 late chunking은 긴 문서 전체를 먼저 long-context embedding model에 통과시킨 뒤, transformer 이후 단계에서 청크별 pooling을 수행한다.
이렇게 하면 각 청크 임베딩이 주변 문맥을 본 상태에서 만들어질 수 있다.
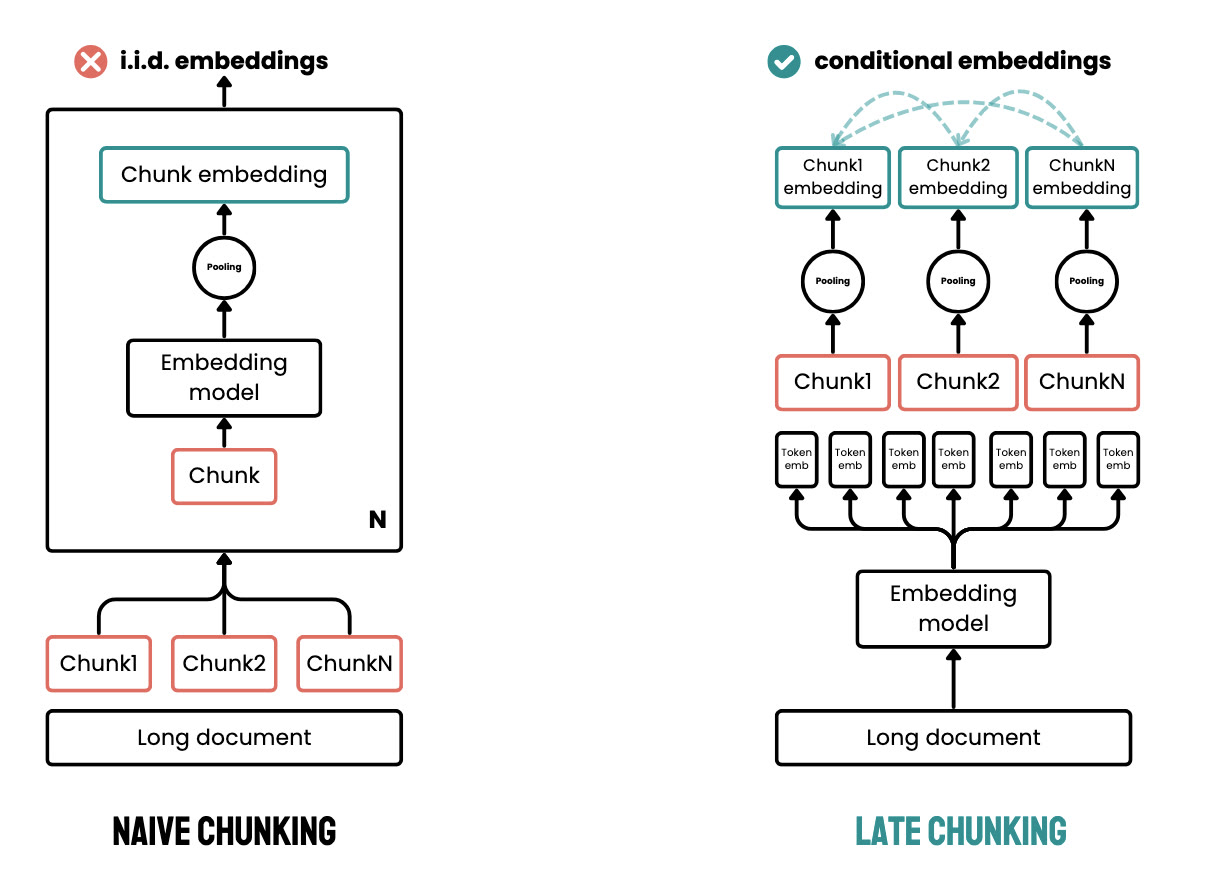
Late Chunking: Contextual Chunk Embeddings Using Long-Context Embedding Models 논문을 인용한 요즘IT/PyCon Korea 2025 발표 정리 이미지.
먼저 자르고 임베딩하는 방식과, 전체 문맥을 본 뒤 청크 임베딩을 만드는 방식을 비교한다.
이들을 한 장의 운영 선택지로 정리하면 다음과 같다.
| 접근 | 장점 | 비용/주의점 | 적합한 상황 |
|---|---|---|---|
| 고정 크기 청킹 | 단순하고 빠르다 | 의미 경계를 쉽게 끊는다 | baseline, 균질한 plain text |
| 재귀적 청킹 | 문단·문장 구조를 보존한다 | 구조가 약한 문서에서는 한계가 있다 | 기술 문서, Markdown, 일반 보고서 |
| 시맨틱 청킹 | topic shift를 더 잘 감지할 수 있다 | 문장별 임베딩 비용과 threshold 튜닝이 필요하다 | 긴 설명문, 주제 전환이 잦은 문서 |
| 메타데이터 보존 | 날짜·권한·섹션 기준 검색 정확도를 높인다 | schema 설계와 filter index가 필요하다 | 기업 문서, 법률/정책/버전 문서 |
| overlap + 병합 | 경계 문맥 손실을 줄인다 | 중복 제거와 offset 관리가 필요하다 | 코드, 긴 문장, 절 경계가 애매한 문서 |
| contextual retrieval | 작은 청크의 독립성을 높인다 | 청크별 요약 생성 비용과 품질 관리가 필요하다 | 청크 안 지시어·대명사가 많은 문서 |
| late chunking | 전체 문맥을 반영한 chunk embedding을 만든다 | long-context embedding model과 긴 입력 비용이 필요하다 | 긴 문서 retrieval, 문맥 의존 표현이 많은 문서 |
| MoC / adaptive chunker | 도메인별 분할 정책을 학습·선택할 수 있다 | 학습·라우팅·평가 체계가 무겁다 | 법률·의료·기술 문서가 섞인 고가치 corpus |
공개된 근거에서 확인되는 점
요즘IT 원문은 2025년 11월 5일 게시된 글로, PyCon Korea 2025의 「RAG 애플리케이션 개발을 위한 Chunking 최적화」 세션을 정리한 콘텐츠다.
PyCon Korea 2025 공식 API에서도 같은 제목의 발표가 확인되며, 발표자는 강성우, 카테고리는 인공지능, 일정은 2025년 8월 16일 16:50–17:20으로 표시된다.
공식 세션 요약은 Semantic Chunking의 주요 한계로 문맥 이해 부족, 계산 비용 증가, 도메인 특화 지식 반영의 어려움을 든다.
논문 근거도 글의 흐름과 맞물린다.
MoC 논문은 RAG 파이프라인에서 청킹이 자주 과소평가된다고 보고, 전통적·시맨틱 청킹이 복잡한 문맥 뉘앙스를 처리하는 데 한계가 있음을 분석한다.
그 위에서 Boundary Clarity와 Chunk Stickiness로 청킹 품질을 직접 측정하고, granularity-aware MoC 프레임워크로 RAG 성능 향상을 보고한다.
다만 공개 초록 수준에서 확인되는 것은 구조와 방향성이지, 모든 도메인에서 MoC가 항상 비용 대비 최선이라는 결론은 아니다.
Late Chunking 논문은 다른 축의 근거를 제공한다.
이 논문은 기존 dense retrieval이 짧은 텍스트 조각에서 더 좋은 임베딩을 얻을 수 있지만, chunk-first 방식은 주변 문맥을 잃는다고 설명한다.
제안 방식은 긴 텍스트 전체를 long-context embedding model에 먼저 넣고, transformer 이후 mean pooling 직전에 청킹을 적용한다.
기본 방법은 추가 학습 없이 여러 long-context embedding model에 적용 가능하다고 설명되며, 별도 fine-tuning 접근도 함께 제안된다.
정리하면, 공개 근거는 세 층으로 나뉜다.
요즘IT 글은 PyCon 발표를 실무 친화적으로 압축한 2차 정리이고, PyCon 공식 페이지/API는 발표 제목·요약·발표자·일정을 확인하는 행사 출처다.
MoC와 Late Chunking arXiv 논문은 각각 adaptive/learned chunking과 context-preserving embedding이라는 연구적 뒷받침을 제공한다.
이 구분을 유지해야 글의 메시지가 과장되지 않는다.
실무 관점에서의 해석
실무에서 청킹 최적화는 “좋아 보이는 전략 하나를 고르는 일”보다 “내 corpus와 query에 맞는 실험면을 만드는 일”에 가깝다.
같은 RAG라도 사내 정책 검색, API 문서 QA, 코드베이스 검색, 법률 계약서 검토, 논문 기반 리서치 에이전트는 실패 형태가 다르다.
어떤 시스템은 답이 있는 작은 문장을 놓쳐서 실패하고, 어떤 시스템은 맞는 문서를 가져왔지만 너무 많은 주변 잡음 때문에 실패한다.
그래서 시작점은 대개 구조 보존형 baseline이 좋다.
Markdown, HTML, PDF에서 제목·문단·표·코드 블록을 가능한 한 보존하고, 재귀적 청킹으로 기본 index를 만든다.
이때 청크 본문만 저장하지 말고 source, section, page, date, version, ACL, offset, previous/next chunk ID를 함께 저장해야 한다.
이것만으로도 “비슷하지만 다른 연도 문서”나 “권한 밖 문서”를 잘못 끌고 오는 문제를 크게 줄일 수 있다.
그다음은 평가다.
청킹은 감으로 고르면 안 된다.
최소한 다음 지표를 작은 held-out query set 위에서 봐야 한다.
| 지표 | 의미 | 실패 시 의심할 부분 |
|---|---|---|
| recall@k / nDCG | 정답 근거 청크가 후보에 들어오는가 | 청크 크기, embedding model, metadata filter |
| full-span recall | 답에 필요한 전체 근거 범위가 들어오는가 | 너무 작은 청크, overlap 부족, 이웃 청크 확장 부족 |
| duplicate rate | context에 중복 청크가 많이 들어오는가 | overlap 후처리, near-duplicate 제거 |
| citation correctness | 답변 출처가 실제 근거와 맞는가 | metadata, page/section mapping, reranking |
| answer success rate | 최종 답이 맞는가 | retrieval + reranking + prompt assembly 전체 |
| latency / indexing cost | 운영 예산 안에 들어오는가 | 시맨틱 청킹, contextual summary, late chunking 비용 |
문제가 “정답은 근처에 있는데 문맥이 부족하다”라면 청크를 무작정 키우기보다 parent-child retrieval, neighboring chunk expansion, contextual retrieval, overlap 병합을 먼저 검토할 수 있다.
반대로 “너무 많은 잡음이 top-k에 들어온다”면 청크를 더 작게 만들거나, 섹션 메타데이터 필터, reranker, 질의 확장/분해를 함께 봐야 한다.
문서 유형이 많이 섞여 있으면 하나의 chunk size를 전체 corpus에 강제하기보다, 문서 타입별 policy나 adaptive routing을 검토하는 편이 낫다.
Late chunking은 매력적이지만 전제 조건이 있다.
긴 입력을 처리할 수 있는 embedding model이 필요하고, 문서 전체를 먼저 통과시키는 비용도 감당해야 한다.
따라서 모든 문서에 기본 적용하기보다, 문맥 의존 표현이 많고 답변 품질의 가치가 높은 긴 문서군에서 실험하는 것이 합리적이다.
MoC 같은 학습 기반 청커도 마찬가지다.
도메인별 문서가 충분히 많고, 청킹 품질이 제품 KPI에 직접 연결되며, 평가셋을 유지할 수 있을 때 의미가 커진다.
내가 보기에는 청킹을 둘러싼 가장 큰 오해가 “더 긴 context window가 나오면 청킹은 덜 중요해진다”는 생각이다. context window가 길어지면 더 많은 근거를 넣을 수는 있지만, 무엇을 넣을지 고르는 검색 단위의 문제는 사라지지 않는다.
오히려 긴 context에서는 중복·잡음·오래된 문서가 함께 들어갈 가능성이 커지고, citation과 권한 관리도 더 중요해진다.
따라서 RAG 청킹의 성숙한 운영 방식은 다음에 가깝다.
먼저 문서 구조를 최대한 살려 baseline을 만들고, 메타데이터를 schema로 승격하고, 실패 질의를 모아 평가셋을 만든 뒤, chunk size·overlap·contextual retrieval·late chunking 같은 선택지를 비용-품질 곡선 위에서 실험한다.
청킹은 전처리 옵션이 아니라, retrieval product의 데이터 인프라 API다.
그 API가 어떤 단위를 반환하느냐가 결국 RAG가 무엇을 알고 있다고 말할 수 있는지 결정한다.