AI agent를 이야기할 때 가장 흔한 오해는 에이전트를 하나의 큰 상자로 보는 것이다.
사용자가 목표를 넣으면 모델이 알아서 계획하고, 검색하고, 도구를 쓰고, 결과를 검증한 뒤 답을 낸다는 식이다.
하지만 실제 제품 구조에서는 이 상자가 여러 개의 설계 패턴으로 쪼개진다.
어떤 패턴은 제어 루프를 정의하고, 어떤 패턴은 action interface를 바꾸며, 어떤 패턴은 검색·메모리·협업 구조를 바꾼다.
Akshay Pachaar가 LinkedIn에서 공유한 6 popular Agentic design patterns와 Daily Dose of Data Science의 같은 주제 인포그래픽은 이 점을 직관적으로 정리한다.
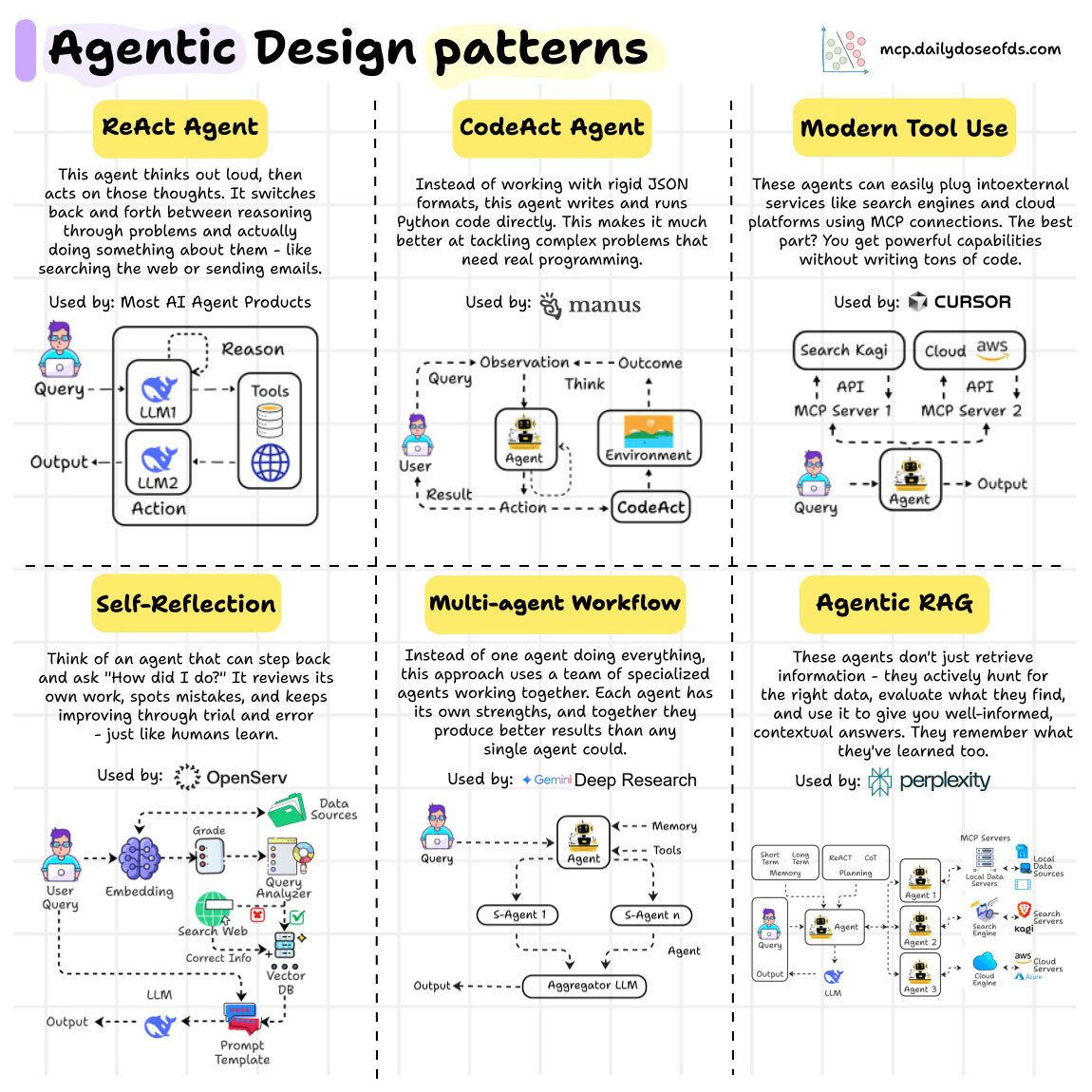
여섯 가지 패턴은 ReAct Agent, CodeAct Agent, Modern Tool Use, Self-Reflection, Multi-agent Workflow, Agentic RAG다.
이 목록은 학술 taxonomy라기보다 제품 엔지니어가 agent system을 볼 때 유용한 체크리스트에 가깝다.
중요한 것은 “우리도 여섯 패턴을 모두 넣자”가 아니다.
Anthropic의 Building effective agents가 반복해서 강조하듯, agentic system은 latency, cost, complexity를 성능과 맞바꾸는 구조다.
Microsoft Azure Architecture Center도 multiagent orchestration을 설명하면서 “요구사항을 안정적으로 만족하는 가장 낮은 복잡도”에서 시작하라고 권한다.
따라서 이 글의 초점은 패턴을 외우는 것이 아니라, 어떤 실패를 봤을 때 어떤 패턴을 추가해야 하는가에 있다.
무엇을 해결하려는가
Agentic design pattern이 필요한 이유는 모델이 약해서만은 아니다.
더 큰 문제는 실패의 종류가 서로 다르다는 데 있다.
어떤 실패는 모델이 다음 행동을 정하지 못해서 생기고, 어떤 실패는 올바른 도구를 호출하지 못해서 생긴다.
어떤 실패는 retrieval이 한 번으로 끝나서 생기고, 어떤 실패는 한 에이전트의 context window 안에 너무 많은 역할을 밀어 넣어서 생긴다.
그래서 “agent를 붙인다”는 말은 너무 거칠다.
제품 관점에서는 최소한 다음 질문으로 분해해야 한다.
| 관찰되는 병목 | 필요한 설계 질문 | 가까운 패턴 |
|---|---|---|
| 중간 관찰값을 보고 다음 행동을 바꿔야 함 | 모델이 reason-act-observe loop를 돌 수 있는가 | ReAct |
| 계산, 데이터 처리, API 조합이 JSON tool call로 답답함 | 실행 가능한 코드가 더 좋은 action space인가 | CodeAct |
| 연결해야 할 외부 시스템이 계속 늘어남 | 도구 권한, 스키마, transport를 표준화할 수 있는가 | Modern Tool Use / MCP |
| 초안 품질이 들쭉날쭉하고 검증 기준이 있음 | critic/evaluator loop가 비용 대비 품질을 올리는가 | Self-Reflection |
| 한 모델이 모든 역할을 맡아 context와 prompt가 비대해짐 | 역할 분리, 병렬 탐색, aggregation이 필요한가 | Multi-agent Workflow |
| 검색 결과가 부족하거나 근거 검증이 약함 | retrieval을 반복 의사결정과 memory로 운영할 수 있는가 | Agentic RAG |
이렇게 보면 패턴은 유행어가 아니라 failure-mode vocabulary가 된다.
운영 로그에서 어떤 문제가 반복되는지를 먼저 보고, 그 실패를 줄이는 가장 작은 구조를 추가하는 방식이 더 안전하다.
핵심 아이디어 / 구조 / 동작 방식
첫 번째 축은 제어 루프다.
ReAct는 reasoning trace와 action을 섞는 대표 패턴이다.
원 논문 ReAct: Synergizing Reasoning and Acting in Language Models는 모델이 reasoning trace와 task-specific action을 interleaved 방식으로 생성하게 하며, Wikipedia API나 WebShop 같은 환경과 상호작용하면서 hallucination과 error propagation을 줄일 수 있다고 설명한다.
단순히 생각을 길게 쓰는 것이 아니라, 생각이 외부 행동으로 이어지고 observation이 다시 다음 생각을 바꾸는 구조다.
Self-Reflection은 같은 제어 루프를 품질 개선 쪽으로 돌린다.
Reflexion 논문은 모델 가중치를 업데이트하지 않고, feedback signal에 대한 verbal reflection을 episodic memory에 저장해 다음 시도에서 더 나은 결정을 유도한다.
실무 제품에서는 이를 그대로 “모델이 스스로 반성한다”로 받아들이기보다, generator와 critic, evaluator, retry budget, memory policy를 분리하는 구조로 보는 편이 안전하다.
검증 기준이 없으면 reflection은 자기확증 루프가 될 수 있다.
두 번째 축은 행동 인터페이스다.
CodeAct는 agent의 action을 JSON이나 고정 tool schema로 제한하지 않고 실행 가능한 Python code로 표현한다.Executable Code Actions Elicit Better LLM Agents는 CodeAct가 Python interpreter와 결합해 agent-environment interaction의 action space를 통합하고, 17개 LLM과 API-Bank 및 M³ ToolEval에서 널리 쓰이는 Text/JSON 대안보다 최대 20% 높은 success rate를 보였다고 보고한다.
계산, 파일 처리, 데이터 변환, 디버깅처럼 코드 자체가 더 자연스러운 작업에서는 이 차이가 크다.
Modern Tool Use는 “무슨 도구를 쓸 수 있는가”보다 “도구를 어떻게 안전하게 연결할 것인가”에 가깝다.
MCP 문서는 MCP를 AI application이 외부 시스템에 연결되는 open-source standard로 설명하고, 파일, 데이터베이스, 검색 엔진, calculator, workflow 같은 data source와 tool을 연결하는 USB-C 같은 표준 포트로 비유한다.
이 패턴의 핵심은 도구 수를 늘리는 것이 아니라 schema, permission, credential, audit boundary를 제품 구조로 넣는 것이다.
세 번째 축은 시스템 구조다.
Multi-agent workflow는 하나의 거대 prompt에 모든 역할을 넣지 않고, planner, researcher, coder, reviewer, summarizer 같은 전문 agent를 나누는 방식이다.
Anthropic은 Claude Research의 multi-agent system에서 lead agent가 연구 과정을 계획하고 parallel subagent가 동시에 정보를 찾는 구조를 설명하며, 내부 research eval에서 single-agent Claude Opus 4 대비 90.2% 더 나은 결과를 얻었다고 밝혔다.
하지만 같은 글은 multi-agent가 일반 chat보다 약 15배 많은 token을 쓸 수 있다고도 말한다.
즉 성능 향상은 공짜가 아니다.
Agentic RAG는 검색을 한 번의 vector lookup으로 끝내지 않는다. agent가 검색할지 말지, 어떤 retriever를 쓸지, 질의를 어떻게 바꿀지, 결과가 충분한지, 다시 검색해야 하는지를 판단한다.
Weaviate와 NVIDIA의 agentic RAG 설명도 공통적으로 traditional RAG의 query → retrieve → generate 흐름과 달리, agentic RAG가 retrieve, evaluate, re-retrieve, validate를 반복하는 동적 구조라고 본다.
실무에서는 여기에 source trace, retrieval evaluation, memory expiration, fallback policy가 붙어야 한다.

공개된 근거에서 확인되는 점
이 LinkedIn/인포그래픽형 정리는 학술 survey라기보다 practitioner-facing map이다.
그래서 각 패턴을 평가할 때는 인포그래픽의 제품 예시를 그대로 성능 근거로 받아들이기보다, 해당 패턴의 원리와 공개 연구·문서가 말하는 trade-off를 함께 봐야 한다.
| 패턴 | 공개 근거에서 확인되는 핵심 | 실무 해석 |
|---|---|---|
| ReAct | ReAct 논문은 reasoning trace와 action을 interleaving해 외부 source나 environment와 상호작용한다고 설명한다 | tool call이 필요한 open-ended task의 기본 루프지만, 무한 루프와 부정확한 reasoning trace를 제어해야 한다 |
| CodeAct | CodeAct 논문은 executable Python code를 action space로 쓰고, Text/JSON 대안보다 최대 20% 높은 success rate를 보고한다 | 코드 실행 환경, sandbox, package allowlist, secret 접근 제어가 핵심 운영 조건이다 |
| Modern Tool Use | MCP 문서는 external systems 연결 표준과 broad ecosystem support를 강조한다 | 도구 연결의 병목은 SDK가 아니라 권한 모델, 스키마 안정성, 관찰성이다 |
| Self-Reflection | Reflexion은 verbal feedback과 episodic memory로 trial-and-error 학습을 흉내 낸다 | evaluator 품질, retry budget, feedback source가 약하면 같은 오류를 그럴듯하게 반복할 수 있다 |
| Multi-agent Workflow | Anthropic은 multi-agent research가 breadth-first query에 강하지만 token 사용량이 크게 증가한다고 보고한다 | 복잡한 연구·분석에는 좋지만, cost ceiling과 aggregation policy가 없으면 제품 비용이 폭증한다 |
| Agentic RAG | Agentic RAG 자료들은 query reformulation, context evaluation, re-retrieval, validation을 강조한다 | 검색 품질만이 아니라 source trace, memory, fallback, eval metric을 함께 설계해야 한다 |
또 하나 눈에 띄는 점은 Daily Dose of Data Science 글이 Google ADK와 세 가지 프로토콜, 즉 MCP, A2A, AG-UI를 함께 언급한다는 점이다.
이는 agent pattern 논의가 점점 model prompting에서 product integration layer로 이동하고 있음을 보여준다.
에이전트는 더 이상 “LLM이 도구를 부른다” 수준이 아니라, tool, other agents, user interface를 각각 다른 protocol boundary로 연결하는 system design 문제가 되고 있다.
실무 관점에서의 해석
내가 보기에 이 여섯 가지 패턴의 가장 좋은 사용법은 checklist가 아니라 진단 순서다.
먼저 agent가 꼭 필요한지 묻는다.
고정된 순서의 작업이면 prompt chaining이나 일반 workflow engine이 더 낫고, 단일 질문 분류나 요약이면 direct model call이 더 싸고 안정적이다. agent pattern은 단순 구조가 실패했다는 근거가 있을 때 추가해야 한다.
그다음에는 실패를 분류한다.
모델이 다음 action을 잘못 고른다면 ReAct나 planning loop를 본다. action은 맞지만 실행 표현이 답답하다면 CodeAct나 richer tool schema를 본다.
외부 시스템 연결이 늘어 운영이 깨진다면 MCP 같은 tool interface와 permission model을 먼저 설계한다.
초안 품질이 낮지만 평가 기준이 명확하다면 self-reflection/evaluator-optimizer가 효과적일 수 있다.
문제가 넓고 병렬 탐색이 필요하다면 multi-agent를 고려한다.
답의 근거가 약하면 agentic RAG와 retrieval observability를 먼저 본다.
반대로 피해야 할 방식도 분명하다.
ReAct에 reflection을 붙이고, 그 위에 multi-agent를 얹고, 모든 agent에게 MCP tool을 열어준 뒤, retrieval memory까지 붙이는 식의 “패턴 풀세트”는 대부분의 제품에서 디버깅 지옥이 된다.
각 패턴은 reliability를 높일 수도 있지만, 동시에 새로운 failure mode를 만든다.
CodeAct는 sandbox 위험을 만들고, MCP는 permission surface를 넓히며, multi-agent는 aggregation 오류를 만들고, reflection은 잘못된 self-critique를 강화할 수 있다.
그래서 이 인포그래픽의 가치는 “여섯 가지가 대세다”가 아니라 “agent system을 여섯 개의 설계 질문으로 쪼개자”에 있다.
좋은 agent engineering은 더 많은 agent를 붙이는 일이 아니라, 실패 로그가 요구하는 최소한의 제어 루프와 도구 경계, 검증 루프, 검색 루프를 조합하는 일이다.
그런 관점에서 Agentic Design Pattern은 유행어가 아니라 제품팀이 모델, 도구, 메모리, 평가, 비용을 같은 테이블 위에 올려놓게 해주는 공통 언어에 가깝다.