Embedding 모델을 바꾸는 일은 단순한 모델 교체가 아니다.
이미 수백만 개 문서나 아이템을 벡터 DB에 넣어 둔 상태라면, 새 embedding 모델이 더 좋은 성능을 내더라도 전체 corpus를 다시 인코딩해야 할 수 있다.
추천 시스템에서도 주기적으로 모델을 재학습하면 새 embedding 공간이 이전 공간과 회전·반사되어 downstream classifier나 ranking logic이 그대로 작동하지 않을 수 있다.
When Embedding Models Meet: Procrustes Bounds and Applications는 이 문제를 embedding space interoperability 문제로 정리한다.
핵심 질문은 단순하다.
두 embedding 모델이 같은 객체들 사이의 dot product, 즉 유사도 구조를 거의 보존한다면, 한쪽 공간을 직교 변환만으로 다른 쪽 공간에 맞출 수 있는가?
논문의 답은 “그렇다”에 가깝다.
저자들은 pairwise dot product가 가까우면 orthogonal Procrustes로 얻은 alignment error도 작아진다는 tight bound를 제시하고, 이 원리를 모델 재학습, text retrieval에서의 partial upgrade, mixed-modality search 세 가지 실험으로 검증한다.
무엇을 해결하려는가
Embedding 모델은 보통 거리나 dot product를 기준으로 학습된다.
이런 목적 함수는 직교 변환에 불변이다.
같은 기하 구조를 가진 embedding이라도 전체 공간이 회전되거나 반사되면 loss 관점에서는 똑같이 좋은 해가 된다.
문제는 실제 시스템에서는 그 벡터를 서로 비교해야 한다는 점이다.
논문은 세 가지 운영 상황을 동기로 든다.
| 상황 | 실제 병목 | 단순 재학습/교체가 어려운 이유 |
|---|---|---|
| 모델 재학습 | 추천·검색 embedding을 주기적으로 새 데이터로 갱신 | downstream 모델이 이전 embedding 공간에 맞춰져 있으면 같이 재학습해야 한다 |
| Partial upgrade | query encoder만 더 강한 모델로 바꾸고 싶음 | document embedding을 다시 만들 수 없거나 비용이 너무 큼 |
| 멀티모달 검색 | text, image, text+image 문서를 한 ranking 안에서 비교 | CLIP/SigLIP 계열도 modality gap 때문에 heterogeneous pair 비교가 흔들림 |
여기서 Procrustes alignment가 매력적인 이유는 embedding 자체의 기하 구조를 망가뜨리지 않는다는 점이다.
일반적인 linear transformation은 alignment error를 더 줄일 수 있지만, 원래 모델이 만든 거리 관계를 왜곡할 수 있다.
반면 orthogonal transformation은 회전과 반사만 허용하므로 각 embedding space 내부의 dot product와 distance를 그대로 보존한다.
핵심 아이디어 / 구조 / 동작 방식
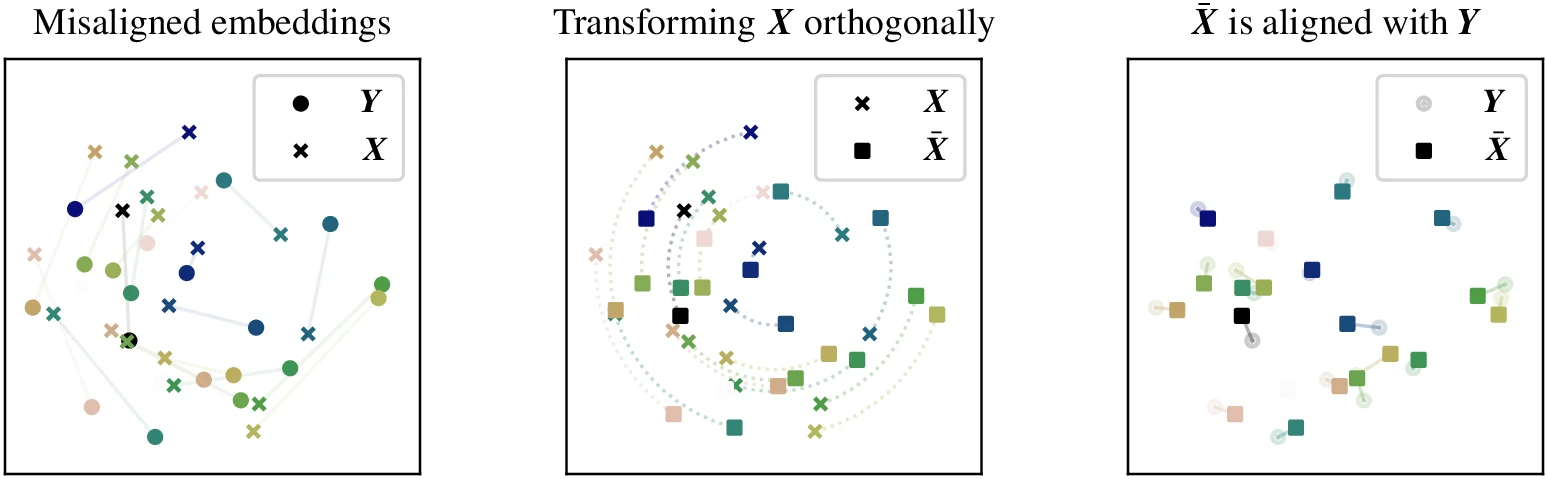
문제 설정은 두 embedding 행렬 X, Y에서 시작한다.
각 column은 같은 객체를 두 모델로 인코딩한 벡터다.
목표는 직교 행렬 Q를 찾아 QX가 Y에 가까워지게 만드는 것이다.
논문이 사용하는 orthogonal Procrustes recipe는 오래된 방법이지만 매우 간단하다.
- 같은 객체 샘플을 두 모델로 각각 embedding한다.
Y Xᵀ의 singular value decomposition을 계산한다.- SVD가
UΣVᵀ라면Q* = U Vᵀ를 사용한다. - 이후 source embedding에는
Q*를 곱해 target embedding space에 맞춘다.
이 과정은 별도 neural network를 학습하지 않는다.
기존 embedding 모델도 수정하지 않는다.
필요한 것은 동일 객체에 대한 paired embeddings와 하나의 SVD다.
논문의 이론적 기여는 이 직관에 bound를 붙인 것이다.
두 embedding set의 Gram matrix 차이, 즉 XᵀX와 YᵀY의 Frobenius norm 차이가 ε 이하라면 다음이 성립한다.
min_Q ||QX - Y||_F ≤ (2D)^(1/4) √ε
여기서 Q는 직교 행렬이고, D는 embedding dimension이다.
평균 squared dot product error를 δ²로 쓰면 aligned embedding의 평균 squared distance가 √(2D) δ 이하가 된다는 corollary도 제시한다.
중요한 점은 기존 일부 bound와 달리 데이터별 최소 singular value 같은 조건에 의존하지 않고, 관심 있는 regime에서는 sample 수 N에 직접적으로 나빠지는 형태가 아니라는 것이다.
실무적으로 해석하면 이렇다.
두 모델이 “완전히 같은 벡터”를 만들 필요는 없다.
같은 객체들 사이의 유사도 구조를 충분히 비슷하게 보존한다면, 후처리 alignment layer 하나로 두 모델의 embedding을 같은 검색 시스템에서 쓸 가능성이 생긴다.
공개된 근거에서 확인되는 점
첫 번째 실험은 MovieLens-25M 기반 모델 재학습 시나리오다.
저자들은 6개월 rolling window로 4개 시점의 BPR matrix factorization embedding을 학습하고, 첫 번째 버전 t0에 downstream classifier나 retrieval logic이 맞춰져 있을 때 이후 버전 t의 embedding을 어떻게 호환시킬지 비교한다.
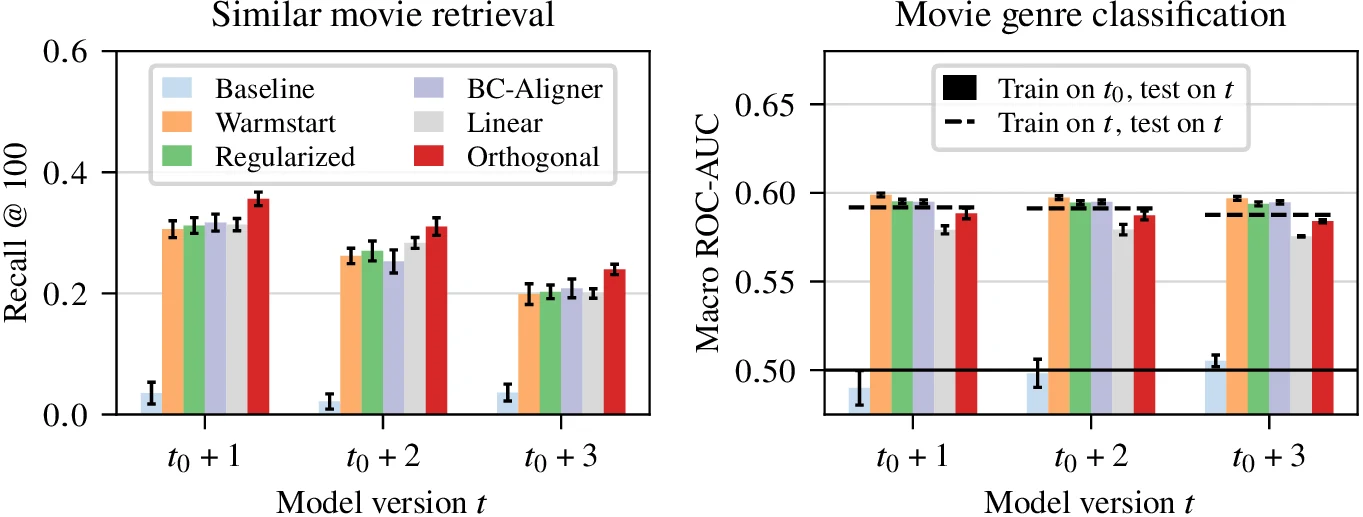
MovieLens 실험의 결론은 분명하다.
유사 영화 retrieval에서는 정렬하지 않은 embedding이 거의 작동하지 않고, orthogonal Procrustes가 post-processing 계열 중 가장 좋은 recall@100을 보인다.
장르 예측에서는 warmstart, autoencoding loss, BC-Aligner처럼 학습 과정 자체에 inductive bias를 넣은 방법이 더 좋은 경우도 있지만, Procrustes는 training objective를 건드리지 않는 순수 후처리 방법이라는 점이 다르다.
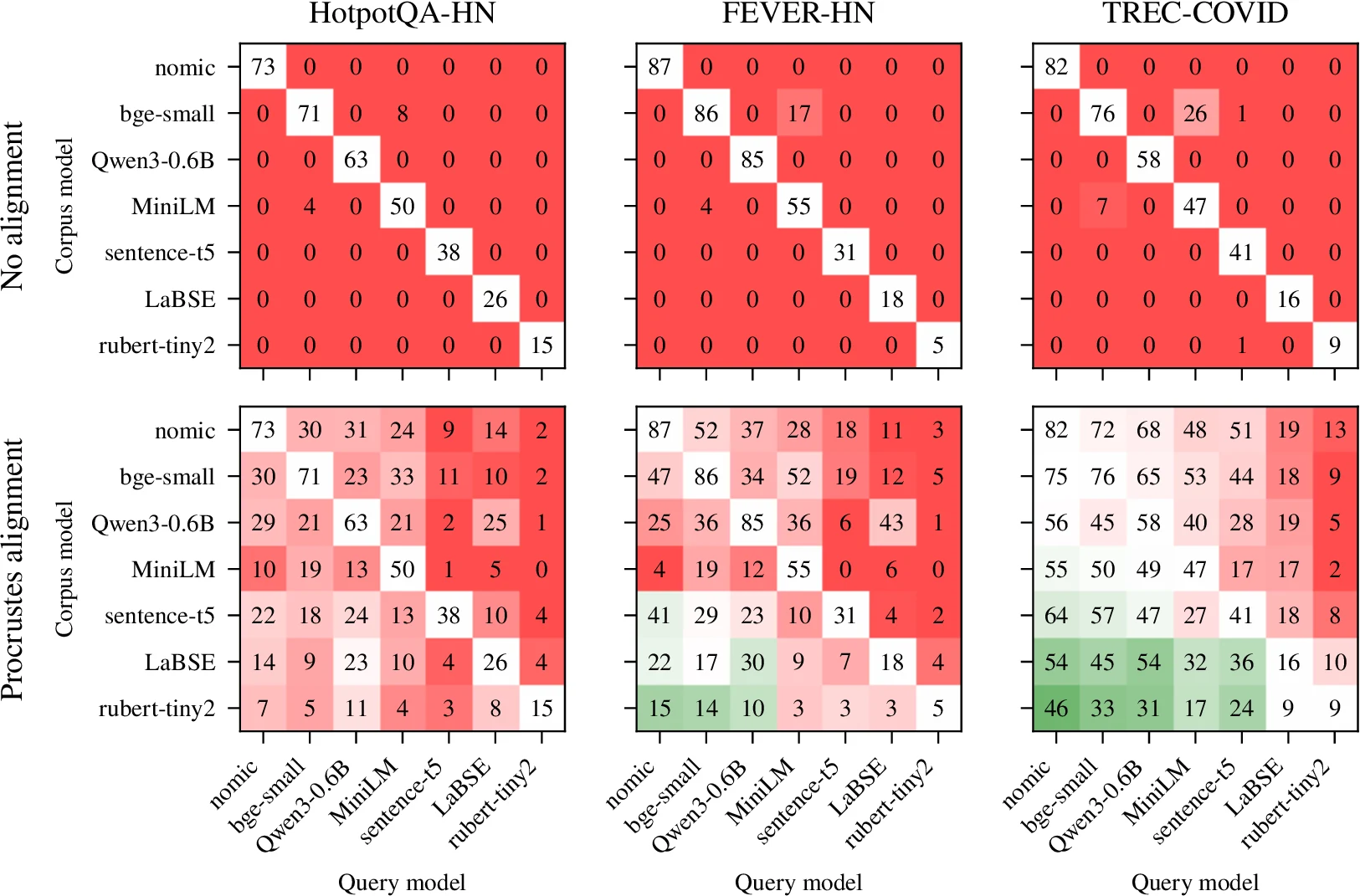
두 번째 실험은 text retrieval partial upgrade다.
HotpotQA-HN, FEVER-HN, TREC-COVID 세 retrieval task에서 7개 공개 text embedding 모델을 조합한다.
문서 embedding은 기존 corpus model로 고정하고, query embedding만 다른 모델로 바꾼다고 보면 된다.
논문 Figure 4의 결과는 꽤 직관적이다.
정렬 없이 서로 다른 모델의 query/document embedding을 곱하면 cross-model retrieval은 거의 실패한다.
하지만 query embedding을 Procrustes로 document model space에 맞추면 retrieval이 다시 가능해지고, 일부 task에서는 더 강한 query encoder로 바꾸는 것이 문서 embedding을 그대로 둔 상태에서도 큰 성능 개선을 만든다.
| 실험 축 | 설정 | 확인되는 메시지 |
|---|---|---|
| 모델 재학습 | MovieLens-25M, 4개 rolling partition | 새 embedding 버전을 reference version에 맞추면 downstream 호환성이 크게 회복된다 |
| Text retrieval | 7개 text embedding 모델 × 3개 MMTEB retrieval task | raw cross-model dot product는 실패하지만, Procrustes 후에는 query encoder upgrade가 가능해진다 |
| Sample complexity | alignment matrix 학습 샘플 수 변화 | 논문 설정에서는 약 10,000개 paired text sample 이후 성능 이득이 대체로 포화된다 |
| Mixed-modality search | CLIP/SigLIP 계열 4개 모델 × MixBench 4개 subset | modality gap을 centering만으로 다루는 것보다 alignment+centering 조합이 전반적으로 강하다 |
Orthogonal constraint의 효과도 따로 비교한다. unconstrained linear alignment는 Frobenius alignment error만 보면 더 유리할 수 있다.
하지만 Figure 5에서 Procrustes는 특히 더 강한 query model로 업그레이드하는 현실적인 방향에서 linear alignment보다 일관되게 좋은 retrieval 성능을 보인다.
논문의 해석은 명확하다.
원래 source model의 geometry를 보존하는 것이 강한 모델이 가진 정보를 잃지 않는 데 중요할 수 있다.
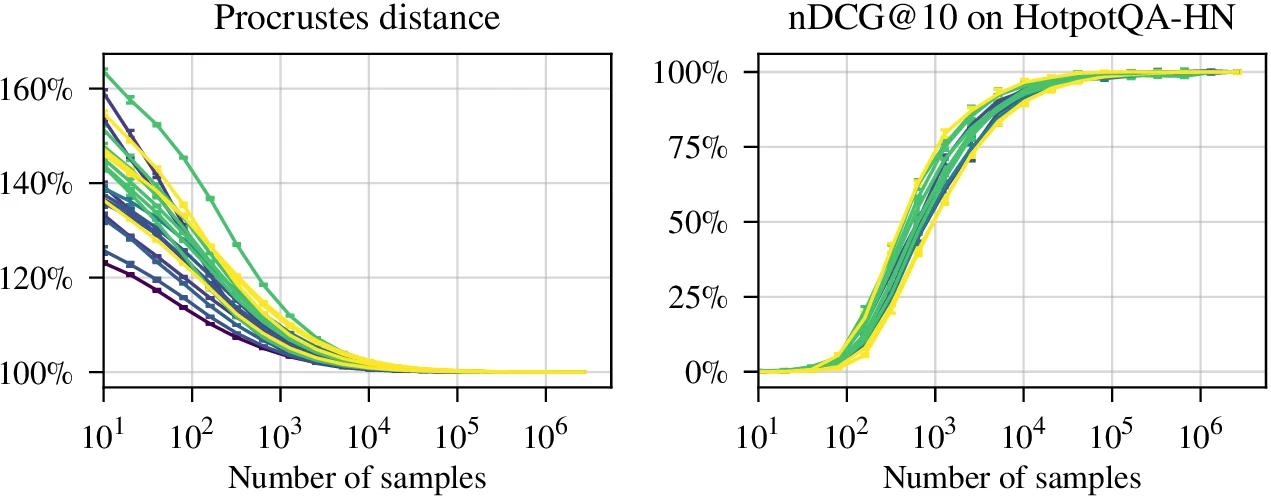
샘플 수 관점에서도 신호가 있다. alignment matrix를 학습하려면 같은 text를 두 모델로 embedding한 paired sample이 필요하다.
논문은 HotpotQA와 FEVER 분석에서 모델 쌍별 성능이 대략 10,000개 샘플 이후 포화되는 양상을 보인다.
이는 대규모 contrastive retraining보다 훨씬 낮은 운영 장벽으로 읽을 수 있다.
물론 이 숫자는 실험 모델과 데이터셋 기준이므로, 도메인별 corpus에서는 별도 검증이 필요하다.
세 번째 실험은 MixBench mixed-modality search다.
CLIP, OpenCLIP, SigLIP 같은 모델은 text와 image를 같은 embedding space에 놓도록 훈련되지만, 실제로는 modality gap이 남는다.
논문은 baseline, orthogonal alignment, centering, alignment+centering 네 가지를 비교한다.
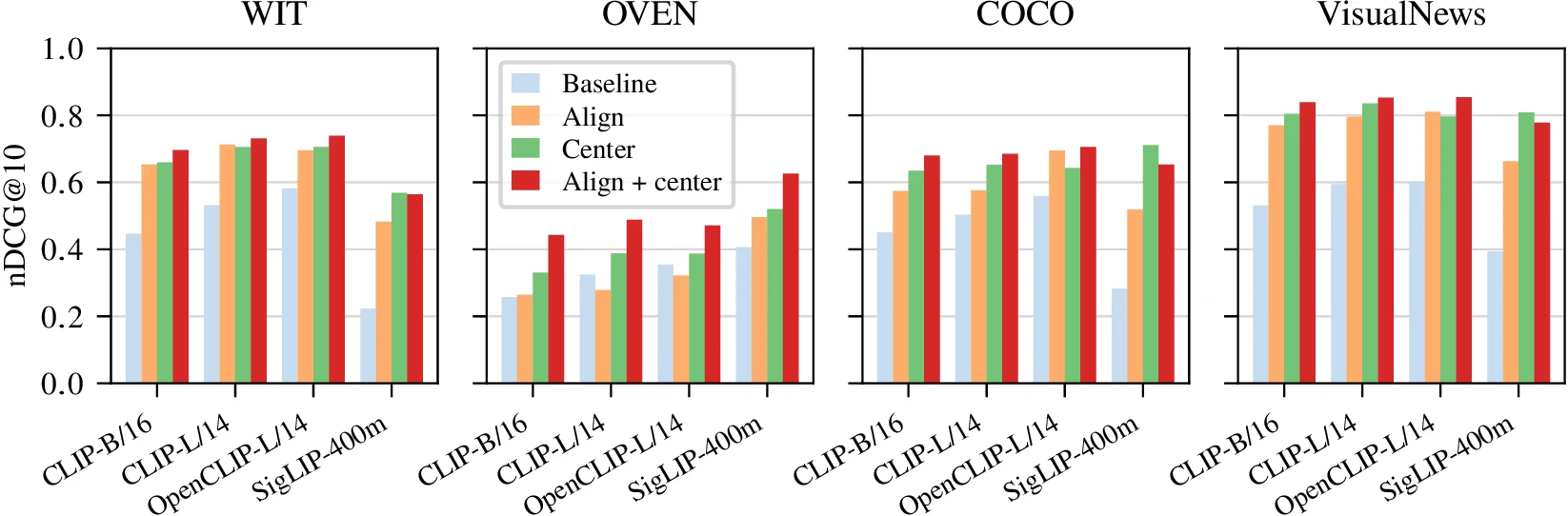
결과적으로 alignment만 해도 대부분의 subset에서 baseline보다 좋아지고, alignment 후 centering을 결합한 설정이 전체적으로 가장 강하다.
기존 연구가 centering과 renormalization을 통해 MixBench 성능을 높였다는 점을 고려하면, 이 논문은 “centering은 좋은 휴리스틱이지만 explicit alignment는 별도의 추가 이득을 준다”는 메시지를 보탠다.
실무 관점에서의 해석
이 논문의 가장 큰 가치는 Procrustes를 새로운 trick으로 제안했다는 데 있지 않다.
오히려 이미 알려진 선형대수 도구를 embedding infrastructure의 호환성 레이어로 다시 위치시킨 데 있다.
RAG와 vector search 운영에서는 모델 교체가 항상 부담이다.
새 embedding 모델이 MTEB에서 더 좋더라도, 기존 index를 버리고 새로 만들려면 비용, 다운타임, A/B 테스트, 품질 회귀 리스크가 생긴다.
Procrustes alignment는 이 부담을 “전체 재색인”이 아니라 “paired sample로 후처리 변환을 추정할 수 있는가”라는 더 작은 문제로 바꾼다.
특히 query/document 경로가 분리되는 검색 시스템에서 의미가 크다.
문서 embedding은 오래된 모델로 이미 저장되어 있고 query encoder만 바꿀 수 있다면, alignment는 partial upgrade의 현실적인 우회로가 된다.
모든 경우에 성능이 좋아지는 것은 아니지만, raw cross-model embedding이 거의 작동하지 않는 상황과 비교하면 실험적 이득은 분명하다.
다만 caveat도 분명하다.
첫째, paired sample이 필요하다.
같은 객체를 두 모델로 모두 embedding할 수 있어야 Q*를 추정할 수 있다.
원문 document가 사라졌거나 privacy 이유로 재인코딩이 불가능한 경우에는 query 쪽 sample만으로는 충분하지 않을 수 있다.
둘째, 두 embedding space가 유사도 구조를 어느 정도 공유해야 한다.
이론도 pairwise dot product preservation을 가정한다.
전혀 다른 task로 학습된 모델이나, domain이 크게 다른 모델 사이에서는 직교 변환 하나가 충분하지 않을 수 있다.
셋째, 이 논문은 arXiv v1 preprint이고, 별도 공식 code repository나 checkpoint release는 확인되지 않았다.
따라서 당장 가져다 쓰는 라이브러리라기보다, alignment layer를 자체 retrieval pipeline에서 검증해 볼 수 있게 만드는 이론·실험 근거로 보는 편이 정확하다.
그럼에도 방향성은 실용적이다. embedding 모델 경쟁이 계속되면, 좋은 모델을 고르는 문제만큼이나 “이미 깔린 vector infrastructure와 어떻게 호환시킬 것인가”가 중요해진다.
Procrustes alignment는 그 질문에 대한 작고 계산 가능한 답이다.
모델 자체를 다시 훈련하지 않고, 공간을 회전시켜 서로 만나게 만든다.
검색·추천·멀티모달 파이프라인이 여러 embedding 모델을 동시에 쓰는 구조로 갈수록, 이런 compatibility-first 관점은 점점 더 중요해질 가능성이 높다.