큰 언어 모델은 대체로 더 깊어질수록 좋아진다. layer 수를 늘리면 한 토큰을 예측하기 전에 더 많은 계산 단계를 통과할 수 있고, 직관적으로는 더 복잡한 feature composition이나 multi-hop reasoning도 가능해야 한다.
그런데 실제 LLM은 그 깊이를 그런 식으로 쓰고 있을까.
Do Language Models Use Their Depth Efficiently?는 이 질문을 정면으로 던지는 논문이다.
Róbert Csordás, Christopher D.
Manning, Christopher Potts는 Llama 3.1, Qwen 3, OLMo 2 계열 모델의 residual stream을 여러 방식으로 찔러 보며, 깊이가 성능과 상관은 있지만 현재 stacked Transformer가 깊이를 효율적으로 쓰는지는 의심스럽다고 주장한다.
논문은 arXiv v3 기준으로 NeurIPS 2025 채택 논문이며, 공식 코드도 공개되어 있다.
핵심 결론은 꽤 도발적이다.
모델의 전반부 layer는 정보를 통합하고 다음 layer 계산에 영향을 주지만, 후반부 layer는 새 sub-result를 만들어 미래 token 계산에 넘기기보다 현재 token의 output probability distribution을 조금씩 다듬는 residual sharpening에 가까워 보인다는 것이다.
더 어려운 MATH 문제나 hop 수가 많은 MQuAKE 질문에서도 계산이 더 뒤쪽 layer로 밀려나는 증거를 찾지 못했고, 얕은 Qwen 2.5와 깊은 Qwen 2.5의 layer를 선형 map으로 맞춰 보면 같은 상대적 깊이끼리 가장 잘 대응된다.
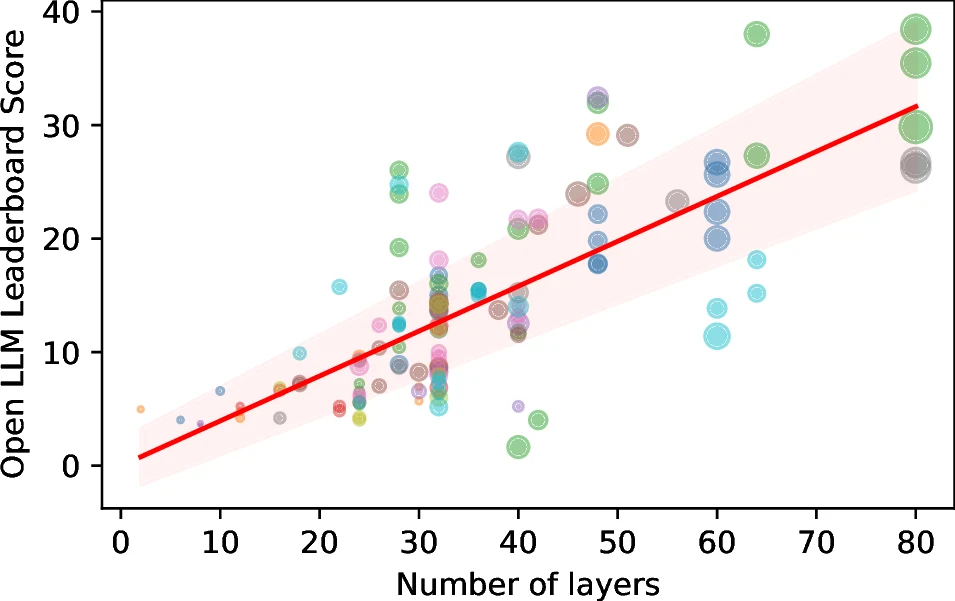
무엇을 해결하려는가
Transformer는 recurrence 없이 layer stack을 한 번 통과한다.
그래서 모델이 한 토큰을 예측할 때 사용할 수 있는 내부 계산 단계 수는 사실상 layer 수로 제한된다.
만약 모델이 더 깊은 계산 그래프를 잘 활용한다면, 깊은 layer에서는 전단계에서 만든 sub-result를 받아 더 높은 차원의 composition을 만들고, 문제 난도가 높을수록 더 뒤쪽 layer까지 의미 있게 쓰는 패턴이 나와야 한다.
하지만 최근 layer skipping, layer pruning, residual stream 분석 연구들은 다른 신호도 보여 왔다.
많은 모델은 일부 layer를 건너뛰거나 바꿔도 생각보다 견고하고, 중간 이후 layer의 probe 개선 폭이 작다는 결과가 반복된다.
이 논문은 그 긴장을 residual stream 중심의 causal intervention으로 더 직접적으로 본다.
저자들이 묻는 질문은 네 가지로 정리할 수 있다.
| 질문 | 논문이 본 측정 방식 | 관찰된 신호 |
|---|---|---|
| 후반부 layer가 residual을 얼마나 바꾸나 | sublayer output norm을 residual norm과 비교 | 중간 지점 이후 상대 기여가 급격히 줄어듦 |
| 어떤 layer가 미래 계산에 영향을 주나 | layer skipping 후 이후 layer contribution과 미래 token prediction 변화 측정 | 후반부 layer는 미래 token 계산에 거의 영향을 주지 않음 |
| 복잡한 문제는 더 깊은 계산을 쓰나 | MATH difficulty, MQuAKE hop 수별 depth score | 난도·hop 증가에 따른 depth 증가 증거를 찾지 못함 |
| 깊은 모델은 새로운 계산을 하나 | Qwen 2.5 1.5B layer에서 14B layer로 선형 map 학습 | 같은 상대적 위치 layer끼리 가장 잘 맞음 |
이 구조가 중요한 이유는 단순한 interpretability 흥미를 넘어서기 때문이다.
만약 후반부 layer의 상당 부분이 새로운 compositional computation이 아니라 분포 미세 조정에 쓰인다면, 더 깊은 Transformer를 계속 쌓는 scaling은 점점 diminishing returns를 낼 수밖에 없다.
반대로 이를 깨려면 architecture, normalization, recurrence, latent thinking, objective 설계를 다시 봐야 한다.
핵심 아이디어 / 구조 / 동작 방식
논문은 pre-layernorm Transformer의 additive residual 구조에서 출발한다.
한 layer의 attention output과 MLP output은 residual stream에 더해진다.
따라서 각 layer가 residual을 얼마나 크게, 어떤 방향으로 바꾸는지 보면 “이 layer가 새 feature를 쓰는가, 기존 feature를 강화하는가, 또는 거의 건드리지 않는가”를 거칠게 추적할 수 있다.
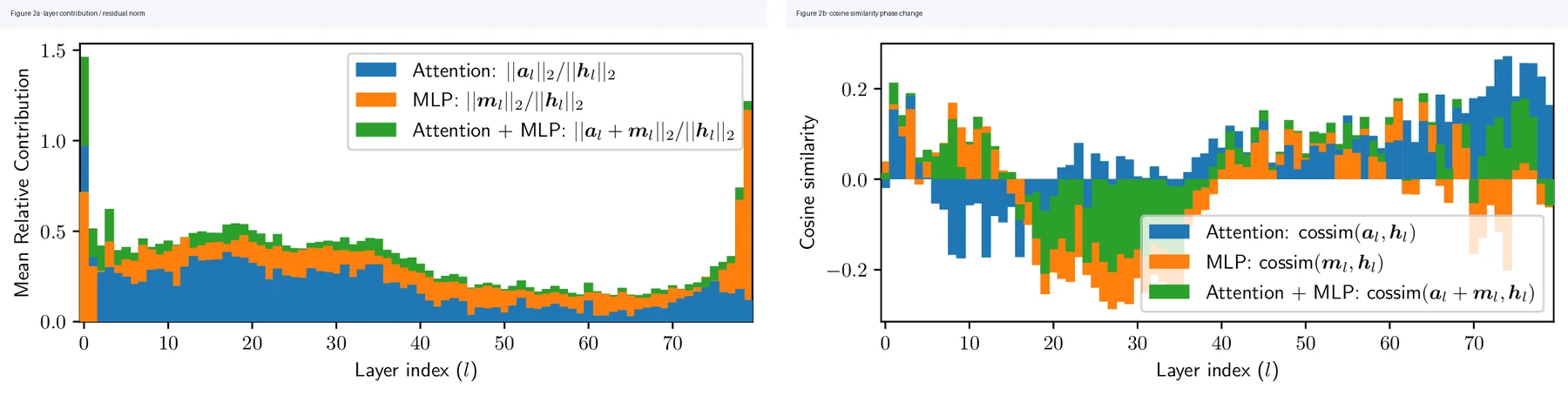
첫 번째 분석은 layer contribution의 norm과 cosine similarity다.
Llama 3.1 70B에서 attention/MLP output을 residual norm으로 나눠 보면 모델 중간 지점 근처에서 기여도가 급격히 떨어진다. cosine similarity도 비슷한 지점에서 phase change를 보인다.
논문은 이 패턴을 “초반에는 feature를 쓰고 지우며 정보를 통합하다가, 중간 이후에는 이미 residual 안에 있는 feature를 강화하는 쪽으로 바뀐다”는 신호로 해석한다.
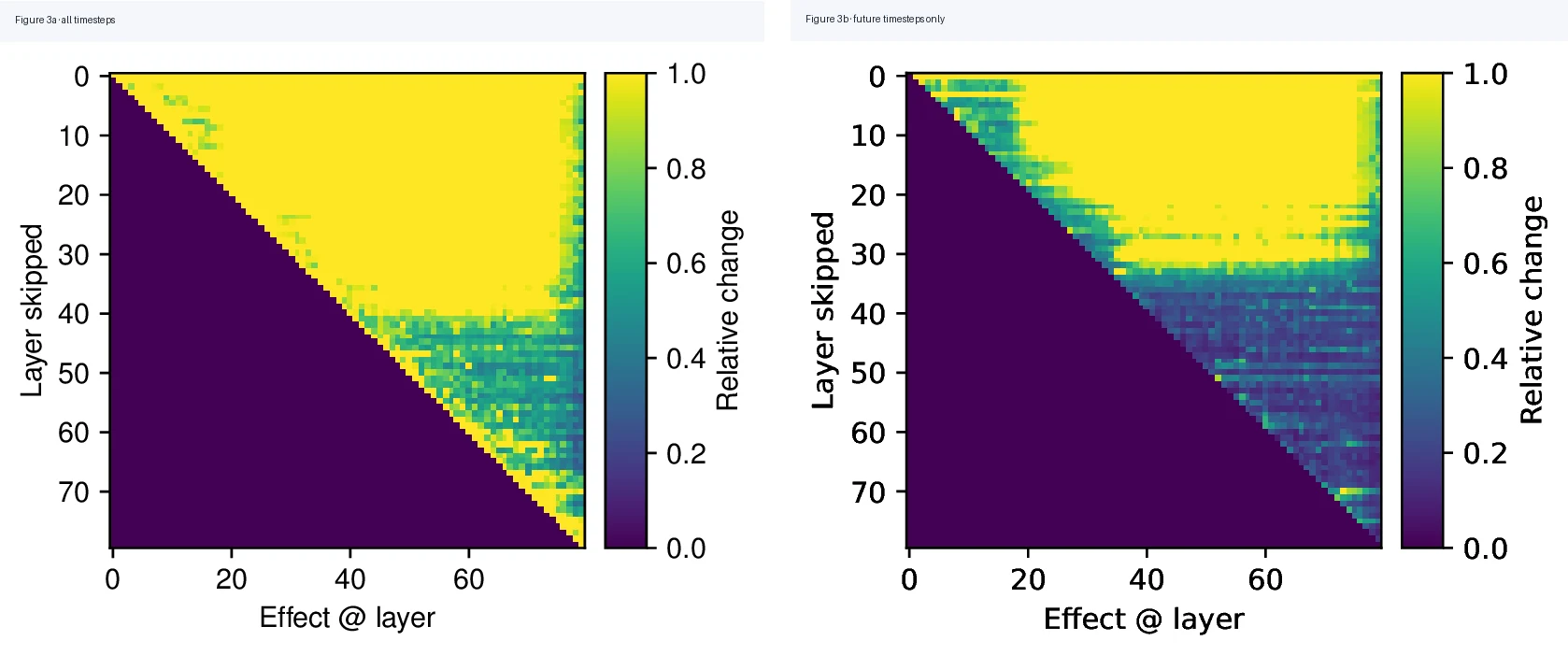
두 번째 분석은 더 인과적이다.
특정 layer s를 건너뛰고, 그 뒤 layer들의 contribution이 얼마나 바뀌는지 측정한다.
전체 timestep을 보면 후반부 layer도 현재 token의 최종 예측에는 중요하다.
하지만 미래 token에 미치는 영향만 분리하면 그림이 달라진다.
후반부 layer를 건너뛰어도 미래 timestep의 이후 계산과 예측은 크게 흔들리지 않는다.
이 차이가 논문의 중심이다.
후반부 layer가 현재 token 예측에는 중요하지만 미래 token 계산에는 중요하지 않다면, 그것은 reusable sub-result를 만들어 다음 token computation에 넘긴다기보다 현재 위치의 logits/probabilities를 다듬는 독립적 계산일 가능성이 높다.
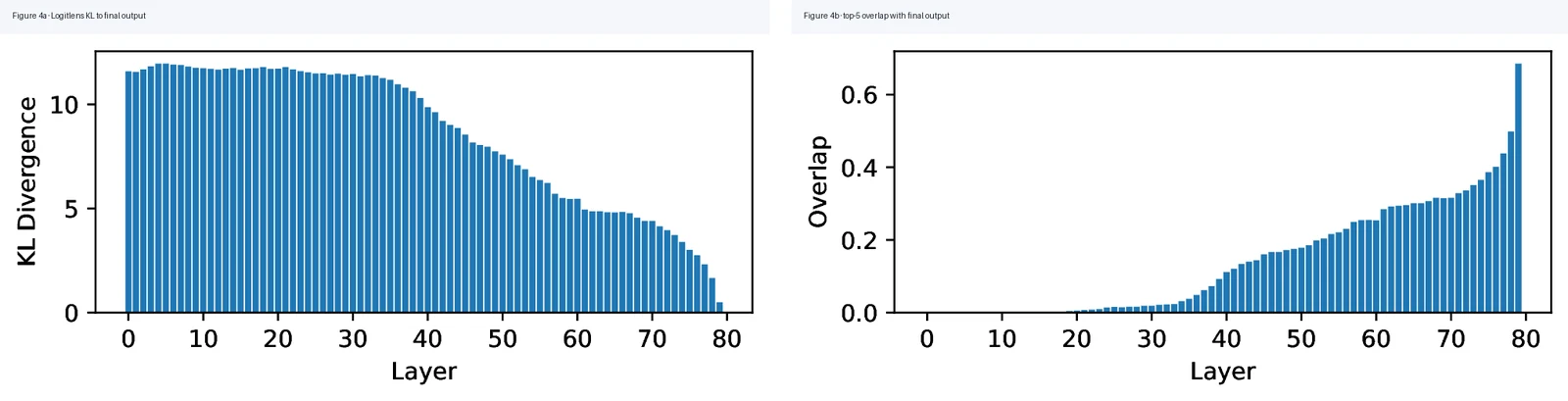
세 번째 증거는 Logitlens다.
각 layer의 residual에 output head를 직접 붙여 최종 예측과 얼마나 가까운지 보면, 네트워크 중간 이후부터 KL divergence가 낮아지고 top-5 token overlap이 급격히 오른다.
즉 중간 이후 layer는 새 계산을 시작한다기보다 이미 최종 답에 가까워진 분포를 점점 최종 분포에 맞추는 단계로 보인다.
공개된 근거에서 확인되는 점
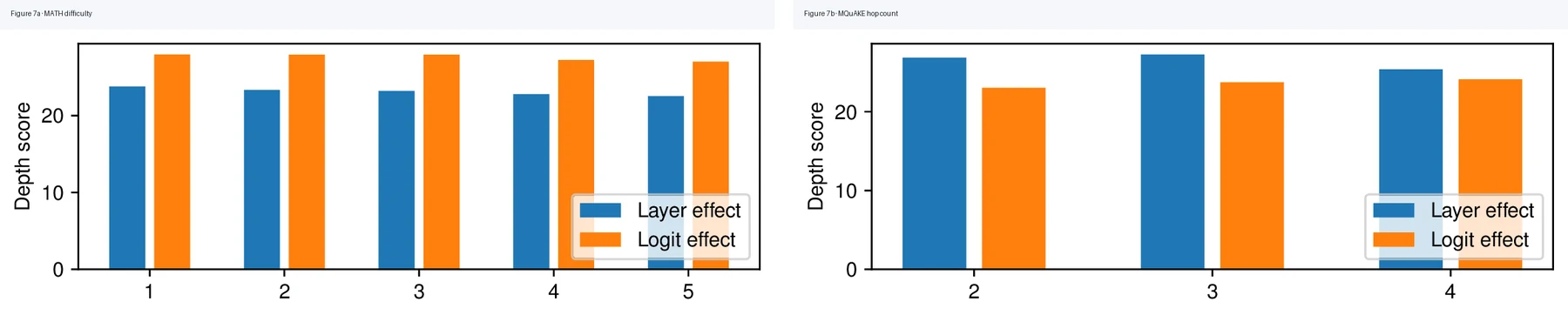
가장 흥미로운 실험은 “어려운 문제일수록 더 깊게 계산하나”다.
논문은 MATH의 difficulty level과 MQuAKE의 hop count를 계산 깊이의 proxy로 보고, 미래 token에 대한 layer influence를 weighted average layer index로 요약한 depth score를 만든다.
만약 모델이 복잡한 문제를 더 깊게 조립한다면 difficulty나 hop 수가 늘수록 depth score도 올라가야 한다.
결과는 그렇지 않다.
Llama 3.1 70B의 main result에서는 MATH difficulty와 MQuAKE hop 증가가 depth score 상승으로 이어지지 않는다. residual erasure와 integrated gradients 예시에서도 arithmetic의 뒤쪽 계산 step이 더 뒤쪽 layer를 쓰는 식의 지연된 composition 패턴은 보이지 않는다.
논문은 “문제가 어려워질수록 깊은 layer를 더 쓰는 adaptive computation의 증거를 찾지 못했다”고 정리한다.
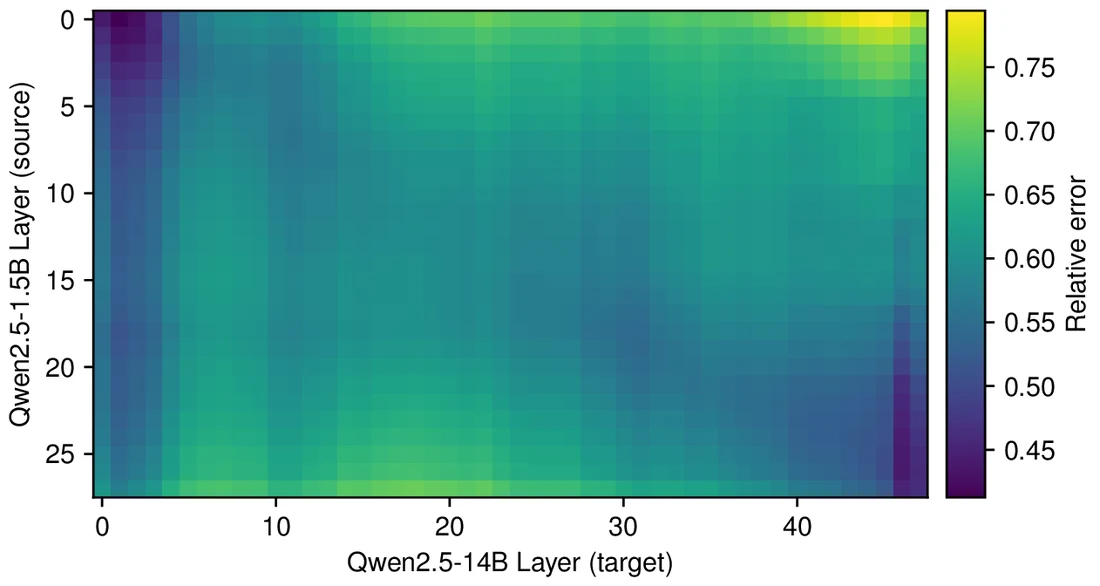
또 하나의 강한 실험은 “깊은 모델이 얕은 모델에 없던 새 계산을 하는가”다.
저자들은 Qwen 2.5 1.5B와 Qwen 2.5 14B를 사용해, 얕은 모델의 각 layer residual에서 깊은 모델의 각 layer residual을 예측하는 선형 map을 모든 layer pair에 대해 학습했다.
만약 깊은 모델의 후반부가 얕은 모델에는 없는 질적으로 새로운 계산을 한다면, 이런 단순한 상대 위치 대응은 약해야 한다.
하지만 heatmap은 대각선 패턴을 보인다.
같은 절대 layer 번호가 아니라 같은 상대적 깊이가 가장 잘 맞는다.
논문은 이를 깊은 모델이 새 종류의 계산을 뒤쪽에 추가한다기보다, 얕은 모델이 하던 계산을 더 많은 layer에 “늘여서” 더 작은 step으로 수행한다는 증거로 해석한다.
다만 논문이 모든 모델이 완전히 같은 방식이라고 주장하는 것은 아니다.
Appendix에서는 Qwen 3, OLMo 2, Llama 3.1 8B/405B, Llama 3.1 70B Instruct까지 확장해 유사한 흐름을 보이면서도 모델별 차이를 기록한다.
예를 들어 Qwen 3 32B와 OLMo 2 32B는 전반부 layer가 서로 즉각적으로 build-on하기보다 residual에 정보를 누적하다가 특정 지점 이후 통합하는 듯한 특이 패턴을 보인다고 설명한다.
그럼에도 “난도가 올라가면 더 깊은 layer를 동적으로 쓴다”는 핵심 신호는 약하다.
MoEUT가 주는 힌트
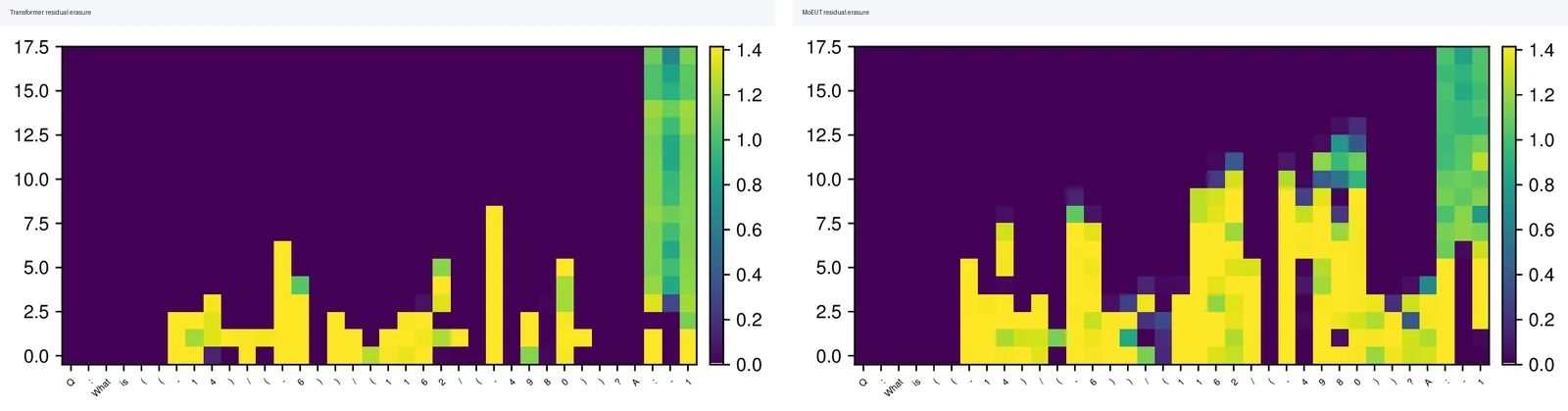
논문의 마지막 실험은 대안 architecture에 대한 작은 힌트다.
저자들은 DeepMind Math arithmetic subset에서 standard Transformer와 MoEUT를 비교한다.
MoEUT는 Universal Transformer 계열처럼 layer sharing을 쓰는 모델이다. residual erasure 예시에서는 MoEUT가 더 많은 depth를 input-dependent하게 쓰는 패턴이 보인다.
특히 question을 modeling하지 않는 설정에서 answer 처리에 더 많은 layer를 쓰는 경향이 나타난다.
이 결과는 아직 exploratory study에 가깝다.
그러나 메시지는 분명하다.
현재 pretrained stacked Transformer의 후반부가 “낭비”처럼 보인다면, 해결책은 단순히 더 쌓는 것이 아니라 recurrence, shared-layer, adaptive computation, objective 설계에서 나올 수 있다.
실무적으로 읽을 포인트
이 논문은 새 모델을 바로 가져다 쓰라는 release가 아니라, 깊은 LLM의 내부 계산 효율을 의심하게 만드는 분석 논문이다.
그래도 모델 설계와 post-training을 보는 관점에는 꽤 실용적인 시사점이 있다.
| 관점 | 이 논문이 던지는 질문 | 실무적 해석 |
|---|---|---|
| scaling | layer 수를 늘리면 성능은 오르지만 왜 diminishing returns가 생기나 | 추가 layer가 새 compositional step이 아니라 distribution matching에 쓰이면 수익률이 낮아질 수 있음 |
| reasoning | CoT가 왜 여전히 강한가 | residual 내부에서 adaptive composition을 못 한다면, token space recurrence가 계산을 외부화하는 역할을 함 |
| latent thinking | residual space에서 더 생각하게 만들면 해결되나 | pretrained Transformer가 fixed-depth circuit을 고수한다면 단순한 latent loop만으로는 부족할 수 있음 |
| pruning / early exit | 후반부 layer를 줄일 수 있나 | 현재 token prediction에는 후반부가 중요하므로 무작정 제거는 위험하지만, 미래 계산 기여가 낮다는 점은 selective optimization의 단서 |
| architecture | 어떤 방향이 유망한가 | recurrence, parameter sharing, adaptive computation, normalization/objective 변경이 연구 포인트 |
특히 Chain-of-Thought에 대한 해석이 좋다.
논문은 CoT가 residual stream 내부의 compositional processing 부족을 input/output token space로 우회하는 방식이라고 본다.
토큰을 하나씩 내보내면 다음 token에서 이전 intermediate result를 다시 입력으로 받아 full recurrence를 만들 수 있다.
대신 계산 상태가 discrete symbol로 제한되고, 훈련 데이터에 명시되지 않은 thinking step을 스스로 늘리는 능력에는 한계가 생긴다.
공개 아티팩트 상태
공식 코드는 GitHub의 RobertCsordas/llm_effective_depth에 있다. repository description도 논문 공식 codebase라고 되어 있고, 라이선스는 MIT다.
구조는 크게 analysis/와 training/ 두 codebase로 나뉜다.
analysis/: NDIF/NNSight 기반 residual analysis, layer skipping, Logitlens, open LLM leaderboard regression 스크립트가 들어 있다. README는NDIF_TOKEN환경변수를 요구하며, local model만 돌릴 경우 빈 문자열로 둘 수 있다고 설명한다.training/: DeepMind Math pretraining/finetuning, Qwen layer mapping, SLURM/W&B 기반 실험 프레임워크가 들어 있다.- 확인 시점 기준 GitHub tags와 releases는 비어 있었다. 즉 pip package처럼 설치해 바로 쓰는 라이브러리라기보다는, 논문 실험을 재현·검토하기 위한 연구 코드에 가깝다.
- Hugging Face model/dataset 검색에서는 arXiv ID나 정확한 제목 기준으로 별도 공식 artifact를 확인하지 못했다.
재현 비용도 가볍지 않다.
논문 Appendix의 hardware section에 따르면 대부분의 main experiment는 NNSight와 NDIF를 사용하지만, Qwen 및 Llama 3.1 70B Instruct 실험은 4×A6000 48GB에서 수행했고, DeepMind Math 학습은 2×A100 80GB로 2일, Llama 3.1 3B full finetuning은 4×H200으로 10시간, Qwen layer-pair linear map 학습은 총 80 GPU-days가 걸렸다고 보고한다.
따라서 이 논문은 “가벼운 로컬 실험 팁”보다는 대형 모델 구조 진단을 위한 분석 프레임으로 보는 편이 맞다.
한계와 내가 보는 의미
논문 스스로도 한계를 명확히 적는다. main case study는 Llama와 Qwen 중심이며, 결과가 모든 model family에 자동으로 일반화된다고 볼 수는 없다.
Qwen layer mapping도 비용 때문에 하나의 model pair에 의존한다.
또한 “복잡한 문제에서 depth가 늘지 않는다”는 관찰이 곧 “모델이 문제를 어떻게 푸는지 완전히 설명했다”는 뜻은 아니다. fixed-depth처럼 보이는 circuit 안에서도 width, superposition, attention pattern, token-level recurrence가 섞여 있을 수 있다.
그럼에도 이 논문이 좋은 이유는 질문이 선명하기 때문이다.
LLM scaling 논의는 종종 parameter 수, token 수, benchmark 점수로 흐르지만, 실제 architecture는 한 토큰마다 정해진 layer budget을 쓰는 계산 그래프다.
이 계산 그래프가 더 깊어졌을 때 새로운 compositional step을 얻는가, 아니면 같은 계산을 더 잘게 쪼개고 마지막에 확률분포를 다듬는가는 다음 세대 architecture를 고르는 데 중요한 질문이다.
개인적으로는 이 논문을 “후반부 layer가 쓸모없다”로 읽기보다, “후반부 layer가 우리가 기대한 종류의 쓸모를 하고 있지 않을 수 있다”로 읽는 게 맞다고 본다.
현재 token의 정확한 distribution을 맞추는 일은 언어 모델링 objective에서는 매우 중요하다.
하지만 장기적으로 수학, 계획, agentic reasoning, world modeling에서 더 많은 depth를 원한다면, 단순히 layer를 더 쌓는 것만으로는 부족할 수 있다.
CoT, latent reasoning, recurrent-depth model, Universal Transformer류, adaptive computation 연구가 다시 중요해지는 이유다.
참고 링크
- Paper: Do Language Models Use Their Depth Efficiently?
- arXiv HTML: 2505.13898v3
- Official code: RobertCsordas/llm_effective_depth