RAG 검색 스택에서 reranker는 품질을 크게 올리지만, 배포 표면은 종종 번거롭다.
어떤 reranker는 CrossEncoder처럼 (query, document) 쌍을 넣으면 바로 relevance score를 주지만, 최근의 LLM 기반 reranker는 CausalLM으로 동작하면서 특정 다음 토큰 logit을 score처럼 읽어야 하는 경우가 있다.
모델 성능은 좋아도 운영 코드는 “텍스트 생성 모델을 로드하고, 마지막 토큰 위치를 맞추고, vocabulary logit 중 특정 열을 꺼내 정렬한다”는 식으로 복잡해진다.
sigridjineth/ctxl-rerank-v2-1b-seq-cls는 이 문제를 아주 좁고 실용적인 방식으로 푼 Hugging Face 모델이다.
새 reranker를 훈련했다기보다, Contextual AI의 ctxl-rerank-v2-instruct-multilingual-1b를 단일 logit SequenceClassification 모델로 변환한 compatibility layer에 가깝다.
모델 카드의 핵심 주장은 간단하다.
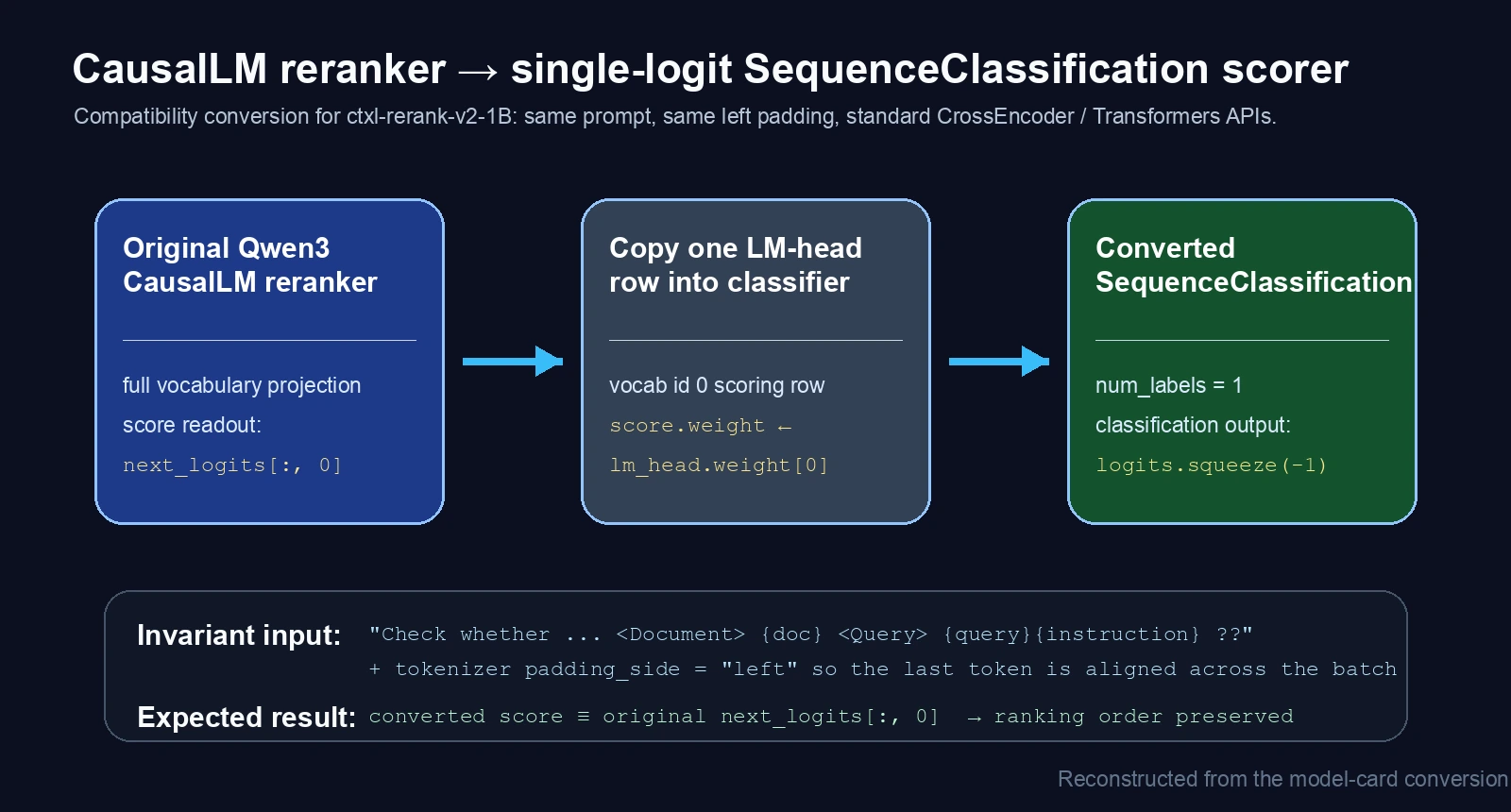
원본 CausalLM reranker가 마지막 토큰에서 next_logits[:, 0]을 relevance score로 쓰고 있다면, LM head의 0번 row를 classification head로 복사해도 같은 hidden state 위에서는 같은 scalar score를 얻을 수 있다는 것이다.
무엇을 해결하려는가
Contextual AI가 공개한 Reranker v2는 instruction-following reranker family다.
공식 블로그는 1B, 2B, 6B 모델과 quantized NVFP4 버전을 공개했다고 설명하고, recency/source/complex instruction 같은 충돌 해결형 retrieval 평가를 강조한다.
즉 단순히 “질문과 문서가 관련 있는가”만이 아니라, “더 최신 문서를 우선하라”, “내부 문서를 시장 분석보다 우선하라” 같은 ranking instruction을 반영하는 쪽에 초점이 있다.
그런데 1B 원본 모델의 Hub metadata를 보면 AutoModelForCausalLM 기반 text-generation 모델이다.
Sentence Transformers CrossEncoder 예시는 제공되지만, 내부적으로는 CausalLM의 마지막 토큰 vocabulary projection에서 score를 읽는 구조다.
이 방식은 정확히 쓰면 문제가 없지만, 일반 AutoModelForSequenceClassification, text-classification pipeline, CrossEncoder wrapper, inference endpoint의 기대 형태와는 다르다.
ctxl-rerank-v2-1b-seq-cls가 해결하는 병목은 바로 이 API friction이다.
검색팀 입장에서는 reranker가 최종적으로 필요한 것은 문서마다 하나의 scalar score다.
원본 모델의 score 정의가 특정 vocab logit이라면, full vocabulary logits 전체를 계산하고 그중 0번만 읽는 대신, 같은 row를 classifier head로 노출하면 된다.
결과적으로 모델은 여전히 Qwen3 backbone을 쓰지만, 로딩 인터페이스는 AutoModelForSequenceClassification이 된다.
핵심 아이디어 / 구조 / 동작 방식
모델 카드가 설명하는 변환은 세 단계로 요약된다.
| 항목 | 원본 ContextualAI 1B | seq-cls 변환 모델 |
|---|---|---|
| Hub 모델 | ContextualAI/ctxl-rerank-v2-instruct-multilingual-1b |
sigridjineth/ctxl-rerank-v2-1b-seq-cls |
| Transformers auto class | AutoModelForCausalLM |
AutoModelForSequenceClassification |
| Architecture | Qwen3ForCausalLM |
Qwen3ForSequenceClassification |
| Score readout | final token의 next_logits[:, 0] |
logits.squeeze(-1) 단일 logit |
| 변환 핵심 | full vocab projection 후 0번 logit 사용 | score.weight ← lm_head.weight[0] |
| 목적 | instruction-following multilingual reranking | 같은 score를 표준 classification/CrossEncoder tooling으로 사용 |
중요한 점은 prompt와 padding 규칙이 그대로 유지되어야 한다는 것이다.
모델 카드의 권장 입력 포맷은 다음과 같다.
Check whether a given document contains information helpful to answer the query.
<Document> {document}
<Query> {query}{optional_instruction} ??
또한 batch scoring에서는 left padding을 써야 한다.
원본 CausalLM score는 “마지막 토큰 위치”에서 읽히므로, padding 방향이 바뀌면 batch 안에서 score를 읽는 위치가 달라질 수 있다.
모델 카드는 tokenizer에 pad token이 없으면 eos_token을 pad token으로 지정하고, padding_side="left"를 맞추라고 안내한다.
from sentence_transformers import CrossEncoder
MODEL_ID = "sigridjineth/ctxl-rerank-v2-1b-seq-cls"
ce = CrossEncoder(MODEL_ID, max_length=8192)
if ce.tokenizer.pad_token is None:
ce.tokenizer.pad_token = ce.tokenizer.eos_token
ce.tokenizer.padding_side = "left"
prompts = [
"Check whether a given document contains information helpful to answer the query.\n"
"<Document> Cats are pets.\n"
"<Query> Which is a domestic animal? ??",
"Check whether a given document contains information helpful to answer the query.\n"
"<Document> The moon is made of cheese.\n"
"<Query> Which is a domestic animal? ??",
]
scores = ce.predict(prompts)
Transformers API로도 같은 의미다.AutoTokenizer와 AutoModelForSequenceClassification를 로드하고, logits의 마지막 dimension을 squeeze하면 문서별 score가 나온다.
높은 score를 더 관련 있는 문서로 보고 내림차순 정렬한다.
공개된 근거에서 확인되는 점
Hub API와 raw config를 확인하면 이 모델의 성격이 꽤 명확하다. sigridjineth/ctxl-rerank-v2-1b-seq-cls는 public, non-gated 모델이고, card metadata는 transformers, text-ranking, reranker, sequence-classification, qwen3, multilingual, 32k 태그와 cc-by-nc-sa-4.0 라이선스를 표시한다.
API의 transformersInfo는 AutoModelForSequenceClassification와 AutoTokenizer를 가리킨다.
| 확인 항목 | 값 / 관찰 | 해석 |
|---|---|---|
| Base model | ContextualAI/ctxl-rerank-v2-instruct-multilingual-1b |
Contextual AI Reranker v2 1B의 변환판 |
| Pipeline tag | text-ranking |
reranking/relevance scoring 용도 |
| Config architecture | Qwen3ForSequenceClassification |
CausalLM이 아니라 classification head로 노출 |
num_labels / label |
1 / SCORE |
문서 쌍마다 단일 scalar score |
| Safetensors parameter count | 1,015,873,024 F32 parameters | 약 1B급 공개 weight |
| Config shape | hidden 2048, 14 layers, 16 attention heads, 8 KV heads | base Qwen3 1B 계열 구조와 일치하는 변환 |
| Context 관련 값 | card는 32K inherited, config max_position_embeddings: 40960 |
긴 후보 문서 reranking을 염두에 둔 base 특성 |
| Hub 상태 | public, non-gated, API 조회 시점 downloads 6 / likes 6 | 널리 쓰인 표준 릴리스라기보다 호환성 변환 artifact |
| License | CC-BY-NC-SA-4.0 | 상업 사용 불가, attribution/share-alike 조건 확인 필요 |
여기서 특히 조심해야 할 점은 “성능이 새로 좋아졌다”는 식으로 해석하면 안 된다는 것이다.
모델 카드의 parity claim은 변환 모델의 score가 원본의 next_logits[:, 0]과 같다는 주장이다.
즉 ranking order를 보존하면서 API surface를 바꾸는 것이 핵심이지, 별도의 benchmark로 원본보다 더 강한 reranker가 되었다는 의미는 아니다.
반대로 이 작고 제한적인 주장이 실무적으로는 꽤 중요하다.
원본 방식에서는 full vocabulary projection을 만든 뒤 0번 logit만 읽는다.
변환 모델은 classification head가 하나의 score만 내므로, 코드에서 custom logits processor나 vocab-column slicing을 덜 다루게 된다.
물론 전체 latency는 backbone forward, sequence length, batching, kernel, dtype에 크게 좌우되므로 “항상 몇 배 빨라진다”고 말할 수는 없다.
하지만 integration cost는 확실히 낮아진다.
공식 Contextual AI Reranker v2의 배경도 함께 봐야 한다.
Contextual AI 블로그는 Reranker v2가 instruction following, QA, multilinguality, product search/recommendation, real-world enterprise use case에서 강한 cost/performance trade-off를 낸다고 설명한다.
특히 instruction-following retrieval benchmark를 위해 recency-based, source-based, complex-instructions dataset을 공개했고, 모델 collection에는 1B/2B/6B와 NVFP4/FP8 variants가 묶여 있다.
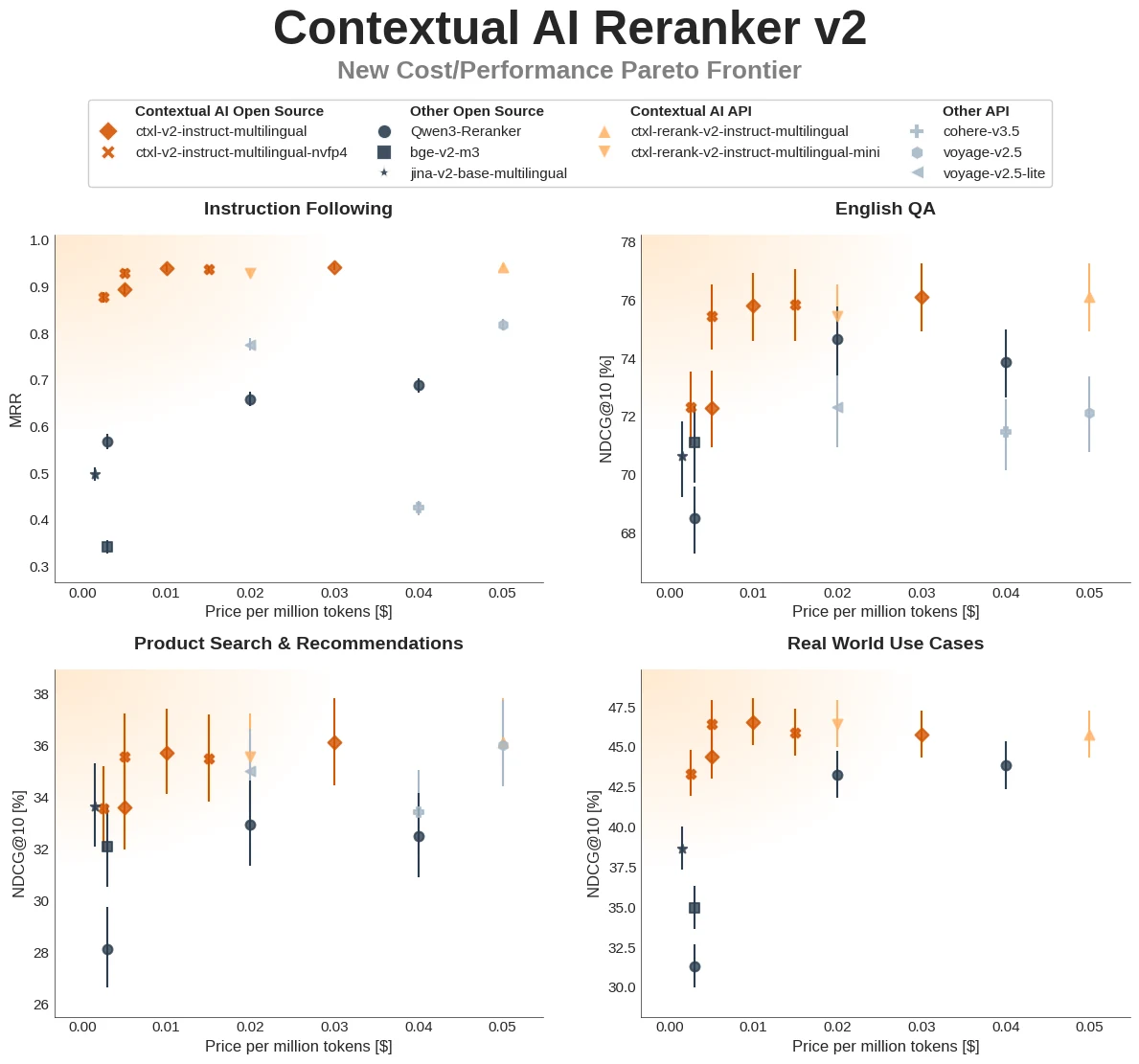
이 이미지와 공식 성능 주장은 원본 Contextual AI Reranker v2 family에 대한 것이다. seq-cls 변환 모델은 그중 1B instruct multilingual 모델의 score readout을 classification interface로 바꾼 파생 모델로 읽는 편이 정확하다.
실무 관점에서의 해석
내가 보기에 이 모델의 가치는 “새로운 reranker SOTA”보다 LLM-style reranker를 기존 retrieval stack에 꽂기 쉽게 만든 packaging에 있다.
많은 RAG 시스템은 이미 Sentence Transformers CrossEncoder, LangChain/LlamaIndex reranker wrapper, 자체 rerank microservice처럼 “입력 쌍 → float score” 인터페이스를 전제로 만들어져 있다.
CausalLM 기반 reranker를 넣으려면 score 위치, padding, dtype, logits slicing을 매번 맞춰야 한다. ctxl-rerank-v2-1b-seq-cls는 그 부분을 모델 artifact 쪽으로 끌어온다.
두 번째 의미는 evaluation 재사용성이다.
같은 prompt template과 left padding을 유지한다면, 원본 1B reranker로 돌리던 offline evaluation set을 AutoModelForSequenceClassification 경로에서도 비교할 수 있다.
점수가 같아야 한다는 것이 모델 카드의 핵심 claim이므로, 도입 전에는 작은 query-document 샘플에서 원본 CausalLM score와 seq-cls score의 ranking parity를 직접 확인하면 된다.
특히 BF16 rounding까지 맞춰야 하는지, max_length를 어디까지 줄일지, 한국어 query/document에서 instruction을 어떻게 쓸지는 별도 검증 대상이다.
세 번째는 라이선스와 배포 리스크다.
모델은 공개되어 있지만 CC-BY-NC-SA-4.0이다.
개인 실험이나 연구 블로그에서는 괜찮아도, 상업 제품에 바로 넣을 수 있는 Apache/MIT 계열 artifact가 아니다.
또한 모델 카드가 말하는 multilingual/32K 특성은 base model에서 상속된 것이며, 실제 운영에서는 후보 수, 문서 길이, GPU 메모리, batching이 비용을 좌우한다.
1B cross-encoder는 embedding retriever처럼 corpus 전체를 훑는 모델이 아니라, top-k 후보를 좁힌 뒤 reranking하는 마지막 계층으로 써야 한다.
도입한다면 나는 다음 순서로 볼 것이다.
| 체크포인트 | 이유 |
|---|---|
| 원본 CausalLM score와 seq-cls score parity를 20~100개 샘플로 확인 | padding/template 실수는 ranking을 바로 흔든다 |
| top-k 후보 수별 latency 측정 | reranker 비용은 후보 수에 거의 선형으로 묶인다 |
| 한국어/영어/혼합 문서에서 instruction template 비교 | multilingual claim은 자체 corpus에서 다시 확인해야 한다 |
| score calibration 금지 | score는 정렬용이지 답변 신뢰도나 사실성 점수가 아니다 |
| 라이선스 검토 | CC-BY-NC-SA-4.0은 상업 배포에 제약이 크다 |
요약하면 ctxl-rerank-v2-1b-seq-cls는 모델 연구보다 배포 접점을 바꾸는 작은 엔지니어링 artifact다.
Contextual AI Reranker v2 1B의 instruction-following reranking 능력을 쓰고 싶지만, CausalLM logits readout을 직접 다루고 싶지 않은 팀에게 의미가 있다.
강한 검색 시스템은 retriever, reranker, generator를 모두 바꾸며 개선되지만, 이런 compatibility conversion은 그중 reranker 계층을 더 평범한 CrossEncoder 인터페이스로 되돌려 준다.
그 평범함이야말로 운영에서는 꽤 큰 장점이다.