RAG와 semantic search를 실제 제품으로 만들면, 가장 먼저 부딪히는 병목은 “모든 문서 벡터와 query 벡터를 매번 비교할 수는 없다”는 점이다.
문서가 수천 개일 때는 brute-force scan도 충분하지만, 수백만·수십억 벡터로 커지면 검색 latency와 비용이 곧 제품의 한계가 된다.
Victoria Slocum의 HNSW 설명 포스트는 이 문제를 좋은 비유로 압축한다. **Hierarchical Navigable Small World(HNSW)**는 위쪽 layer에서 비행기처럼 멀리 점프하고, 중간 layer에서 기차처럼 지역을 좁힌 뒤, 가장 아래 layer에서 자전거처럼 근처를 촘촘히 찾는 구조다.
그래서 HNSW는 단순한 “빠른 인덱스 옵션”이 아니라, 벡터 DB가 recall, latency, memory를 교환하는 핵심 제어면에 가깝다.
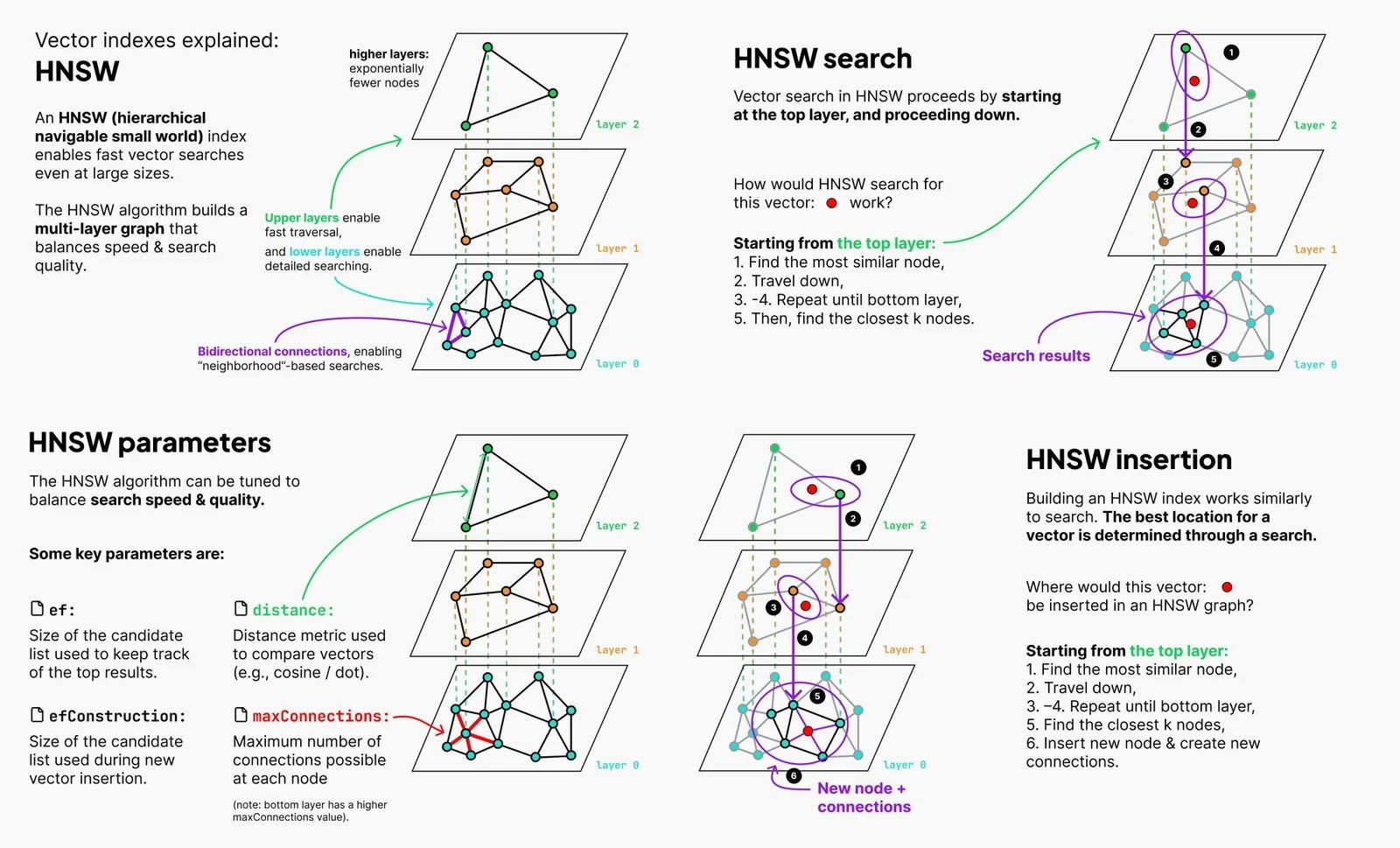
Victoria Slocum의 공개 포스트에 첨부된 HNSW 설명 이미지.
핵심은 상위 layer의 long-range connection으로 불필요한 벡터 scoring을 건너뛰고, 하위 layer에서 local search를 강화한다는 점이다.
무엇을 해결하려는가
Nearest neighbor search의 가장 정직한 방식은 query와 모든 stored vector의 거리를 계산한 뒤 가까운 순서로 정렬하는 것이다.
이 방식은 정확하지만 데이터 개수 N에 대해 선형으로 비싸다. embedding 차원이 높고, top-k query가 많고, metadata filter까지 붙으면 brute-force는 빠르게 운영 병목이 된다.
Approximate nearest neighbor(ANN)는 이 정확도를 조금 양보하고 큰 속도 이득을 얻는 접근이다.
HNSW의 특징은 이 ANN 문제를 계층적 proximity graph로 푼다는 데 있다.
저장된 벡터를 노드로 보고, 가까운 벡터끼리 edge를 연결한 뒤, query가 들어오면 그래프 위를 탐색해서 가까운 후보를 찾는다.
여기서 중요한 점은 “대충 찾는다”가 아니다.
HNSW는 recall을 낮게 고정하는 알고리즘이 아니라, M, efConstruction, efSearch 같은 파라미터로 얼마나 넓게 탐색할지를 조절하는 구조다.
그래서 같은 HNSW라도 설정에 따라 빠르지만 거친 검색이 될 수도 있고, 느리지만 brute-force에 가까운 recall을 내는 검색이 될 수도 있다.
핵심 아이디어 / 구조 / 동작 방식
HNSW의 원 논문인 Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs는 이 구조를 “fully graph-based” ANN index로 제안한다.
별도의 coarse quantizer나 tree를 먼저 두지 않고, 여러 layer의 proximity graph 자체가 coarse-to-fine navigation 역할을 한다.
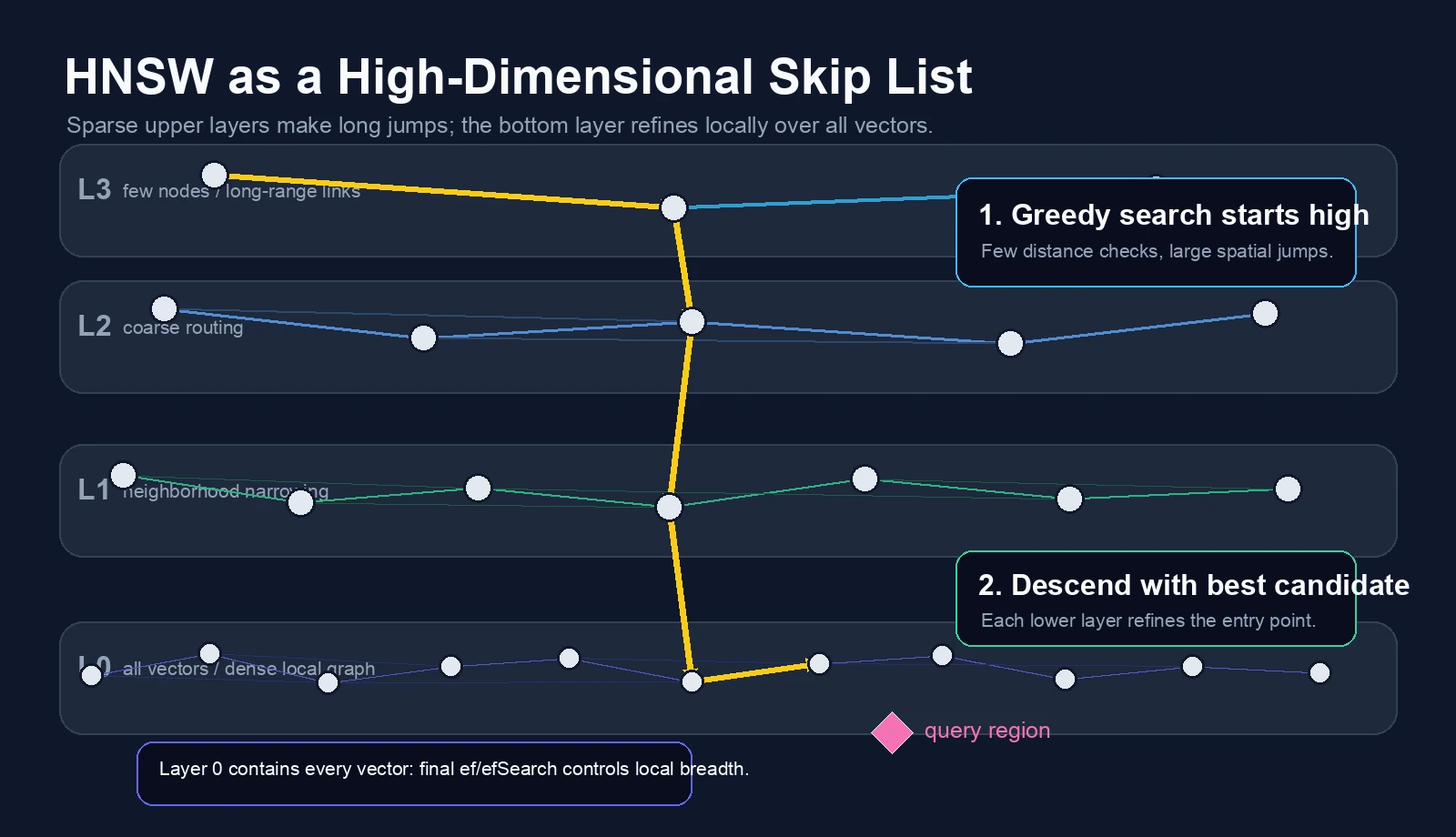
구조는 skip list와 비슷하다.
모든 벡터는 가장 아래 layer 0에 들어간다.
일부 벡터는 확률적으로 더 높은 layer에도 올라간다.
원 논문은 각 element가 포함될 최대 layer를 지수적으로 감소하는 확률 분포로 선택한다고 설명한다.
결과적으로 상위 layer에는 적은 수의 노드와 긴 edge가 생기고, 아래로 내려갈수록 더 많은 노드와 짧은 local edge가 생긴다.
HNSW layer 구조를 재구성한 개념도.
실제 구현은 데이터 분포와 파라미터에 따라 달라지지만, 검색은 대체로 sparse upper layer에서 시작해 layer 0의 dense graph로 내려오며 후보를 정교화한다.
검색 과정은 두 단계로 나눠 생각할 수 있다.
첫째, 상위 layer에서는 greedy routing을 한다.
현재 노드의 이웃 중 query에 더 가까운 노드가 있으면 그쪽으로 이동한다.
상위 layer는 노드 수가 적기 때문에 많은 벡터를 scoring하지 않고도 query가 있을 법한 지역으로 빠르게 이동할 수 있다.
둘째, 아래 layer로 내려오면서 같은 탐색을 반복한다.
이전 layer에서 찾은 좋은 후보가 다음 layer의 entry point가 된다.
마지막 layer 0에서는 더 촘촘한 그래프를 대상으로 후보 집합을 넓게 유지하면서 top-k에 가까운 결과를 찾는다.
이때 검색 폭을 조절하는 대표 파라미터가 efSearch 또는 제품별 ef/hnsw_ef다.
공개된 근거에서 확인되는 점
LinkedIn 포스트의 “고차원 skip list” 비유는 원 논문의 구조와 잘 맞는다.
논문은 HNSW가 Navigable Small World graph를 계층화해 link의 거리 scale을 분리하고, 상위 layer에서 시작해 내려오는 방식으로 NSW 대비 성능을 높인다고 설명한다.
또한 neighbor-selection heuristic이 clustered data와 high-recall 영역에서 성능을 개선한다고 보고한다.
실제 벡터 DB 문서에서도 HNSW는 기본값에 가깝게 자리 잡고 있다.
Weaviate 문서는 hnsw를 대부분의 use case에 권장되는 기본 vector index로 설명하고, Qdrant 문서도 HNSW를 정확도와 속도가 좋은 대표 ANN 알고리즘으로 다룬다.
다만 제품마다 파라미터 이름과 기본값은 다르다.
LinkedIn 포스트의 maxConnections 기본값 32는 Weaviate 설정과 잘 맞지만, 모든 HNSW 구현의 보편 기본값으로 읽으면 안 된다.
| 개념 | Weaviate 문서 기준 | Qdrant 문서 기준 | 실무적 의미 |
|---|---|---|---|
| Graph connectivity | maxConnections, 기본 32, layer 0은 2 * maxConnections 가능 |
m, 기본 16 |
값을 키우면 recall과 graph navigability가 좋아질 수 있지만 memory와 build/search 비용이 증가한다 |
| Build breadth | efConstruction, 기본 128 |
ef_construct, 기본 100 |
index 생성 시 더 많은 후보를 보며 좋은 edge를 만들지만, import/build 시간이 늘어난다 |
| Search breadth | ef, 기본 -1은 dynamic ef |
hnsw_ef, 기본은 ef_construct와 동일 |
query 때 후보를 더 넓게 보면 recall은 좋아지고 latency는 늘어난다 |
| Distance metric | distance, 기본 cosine |
collection vector distance로 설정 | cosine, dot, euclidean 선택이 embedding 학습 방식과 맞아야 한다 |
| Small-data fallback | flatSearchCutoff 등 |
full_scan_threshold |
작은 후보 집합이나 강한 filter에서는 HNSW보다 flat scan이 나을 수 있다 |
이 표에서 가장 중요한 줄은 ef다.M이나 maxConnections는 graph의 골격을 바꾸므로 보통 index build와 memory 계획에 영향을 준다.
반면 efSearch 계열은 query-time knob로 쓰기 쉽다. production에서는 P95 latency를 보며 ef를 올려 recall을 회복하거나, 반대로 latency budget에 맞춰 낮추는 식의 조정이 자주 일어난다.
또 하나의 현실적인 포인트는 filter다.
벡터 검색은 보통 “가까운 벡터”만 찾지 않는다. tenant, 권한, 날짜, 카테고리 같은 payload filter와 함께 작동해야 한다.
Qdrant 문서는 payload index를 HNSW index 생성 전에 만들어야 filter-aware graph edge의 이점을 제대로 얻을 수 있다고 설명한다.
즉 HNSW 튜닝은 vector-only benchmark만의 문제가 아니라, metadata schema와 query planner까지 포함한 데이터 인프라 설계 문제다.
실무 관점에서의 해석
HNSW가 널리 쓰이는 이유는 명확하다. exact scan보다 훨씬 적은 distance computation으로 높은 recall을 얻을 수 있고, ef 같은 query-time knob로 latency와 recall을 비교적 직관적으로 조절할 수 있다.
RAG 시스템에서는 이 특성이 특히 중요하다. first-stage retriever가 너무 느리면 뒤의 reranker나 LLM이 아무리 좋아도 제품 latency를 맞출 수 없고, 너무 거칠면 좋은 문서가 후보에 들어오지 않아 downstream 단계가 복구할 수 없다.
하지만 HNSW는 공짜가 아니다.
첫째, memory를 많이 쓴다.
벡터 자체뿐 아니라 graph edge를 저장해야 하고, connectivity를 높이면 edge 수가 늘어난다.
둘째, build와 update가 비용을 가진다. efConstruction을 높이면 좋은 graph를 만들 가능성은 커지지만 ingest가 느려진다.
셋째, deletion, compaction, quantization, filter-aware search 같은 운영 세부 사항은 제품 구현마다 차이가 크다.
그래서 HNSW를 쓸 때는 “HNSW를 켰는가”보다 아래 질문이 더 중요하다.
| 질문 | 확인할 지표 | 이유 |
|---|---|---|
| 이 corpus에서 recall은 충분한가 | held-out query의 recall@k, nDCG, answer success rate | 공개 benchmark보다 내 데이터 분포가 더 중요하다 |
| latency budget에 맞는가 | P50/P95/P99 latency와 candidate count | ef를 높이면 recall은 좋아지지만 tail latency가 커질 수 있다 |
| memory가 감당 가능한가 | vector bytes + graph edge bytes + cache/GC overhead | M/maxConnections 증가는 RAM 비용으로 돌아온다 |
| filter와 함께 빠른가 | filtered query latency, unindexed filter 비율 | metadata filter가 HNSW 경로를 망가뜨릴 수 있다 |
| reranker와 조합했는가 | retriever recall vs reranker precision | HNSW는 후보 생성기이고, 최종 relevance 판단은 별도 계층일 수 있다 |
내가 보기에 HNSW의 가장 좋은 mental model은 “벡터 DB의 마법”이 아니라 거리 계산 예산을 어디에 쓸지 정하는 그래프 구조다.
상위 layer는 멀리 점프하면서 search space를 줄이고, 아래 layer는 local neighborhood에 예산을 집중한다.
이 예산 배분을 M, efConstruction, efSearch, distance metric, filter index가 함께 결정한다.
따라서 HNSW를 도입할 때의 올바른 결론은 “기본값이면 충분하다”도 아니고 “모든 값을 크게 올리자”도 아니다.
좋은 시작점은 기본값으로 index를 만들고, 실제 query set으로 recall과 latency를 측정한 뒤, 검색 폭은 ef로, graph 품질은 efConstruction과 M으로, memory 압박은 quantization이나 sharding 전략으로 나눠 조정하는 것이다.
HNSW는 billion-scale에서도 빠른 이유가 있지만, 그 빠름은 결국 측정과 튜닝을 통해 제품의 품질-비용 곡선 위에 올려야 의미가 있다.