합성 데이터는 이제 단순히 사람이 쓴 데이터를 대체하는 보조 수단이 아니다.
모델이 스스로 데이터를 만들고, 그 데이터로 다시 모델을 훈련하는 흐름은 이미 instruction tuning, preference data, reasoning data, benchmark construction 전반에서 핵심 병목이 되고 있다.
문제는 “생성” 자체가 쉬워진 만큼, 정말 학습에 쓸 만한 데이터인지 판단하고 개선하는 루프가 더 중요해졌다는 점이다.
Meta FAIR RAM 팀의 Autodata: an automatic data scientist to create high-quality data는 이 문제를 꽤 선명한 방향으로 밀어붙인다.
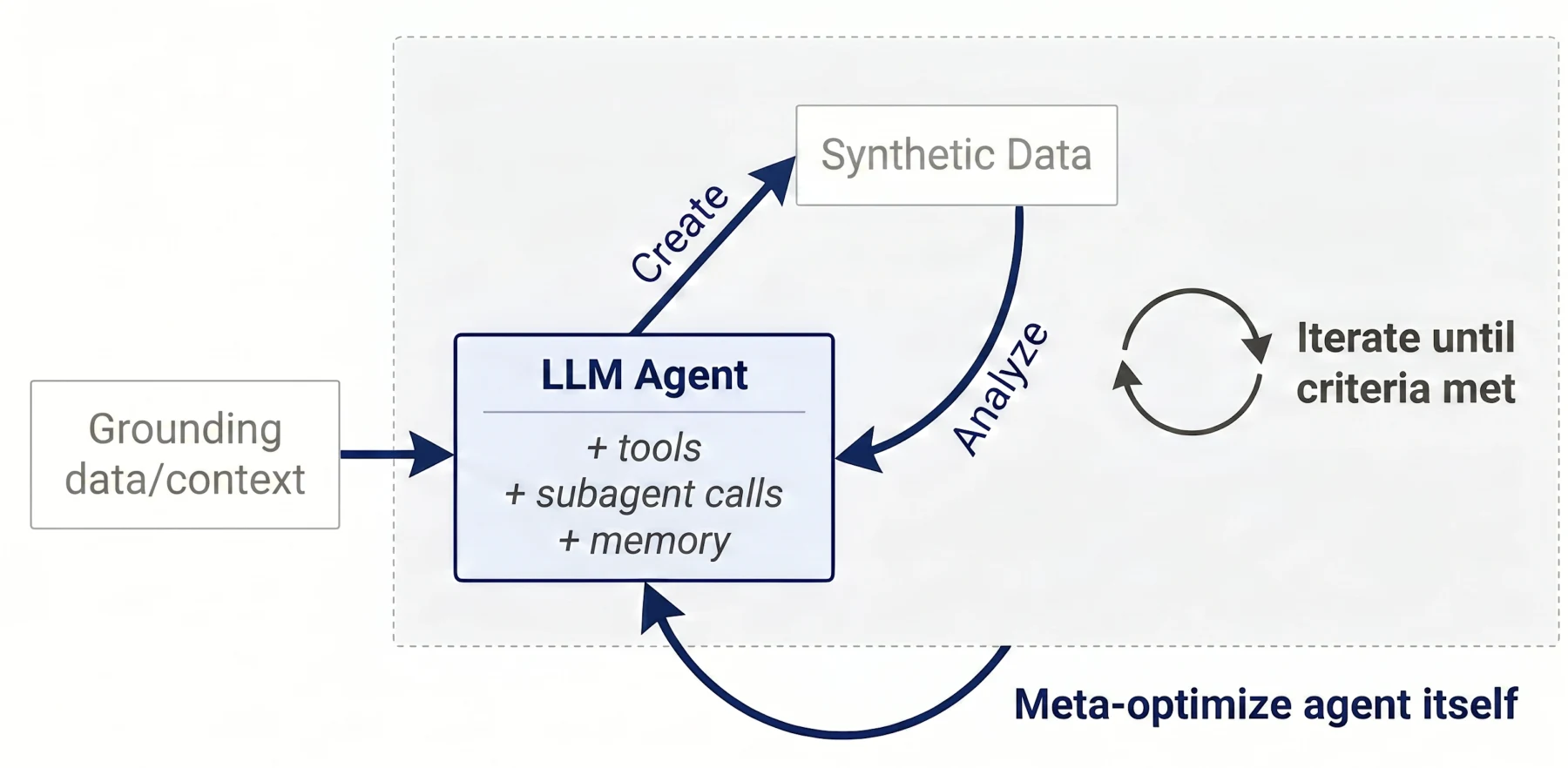
Autodata는 합성 데이터 생성을 프롬프트 한 번으로 끝내는 작업이 아니라, LLM agent가 데이터 과학자처럼 예시를 만들고, 약한 solver와 강한 solver를 비교하고, judge 피드백을 읽고, 다음 생성 recipe를 고치는 반복 루프로 본다.
공식 블로그의 표현대로 말하면, 늘어난 inference compute를 더 좋은 model training data로 바꾸려는 시도다.
흥미로운 점은 이 작업이 “더 좋은 질문을 생성했다” 수준에서 멈추지 않는다는 데 있다.
저자들은 Agentic Self-Instruct라는 구체적 인스턴스를 만들고, CS 연구 논문 기반 QA 생성에서 weak solver와 strong solver의 격차가 실제로 커지는지, 그 데이터로 Qwen 3.5 4B를 GRPO 학습했을 때 성능이 오르는지, 심지어 데이터 과학자 agent의 harness 자체를 meta-optimization으로 개선할 수 있는지까지 보여준다.
아직 full technical report는 arXiv에 곧 올릴 예정이라고 안내되어 있지만, 블로그와 공개 RAM 저장소에는 핵심 prompt, 수치, 그림, citation이 이미 공개돼 있다.
무엇을 해결하려는가
기존 Self-Instruct 계열 방법의 기본 패턴은 단순하다.
강한 LLM에게 instruction이나 QA pair를 만들게 하고, 필요하면 document grounding, chain-of-thought, filtering, refinement를 붙인다.
이 방식은 사람이 직접 라벨링하지 않고도 많은 데이터를 만들 수 있다는 장점이 있지만, 데이터 품질을 직접 제어하기는 어렵다.
특히 reasoning data에서 중요한 것은 “그럴듯한 질문”이 아니라, 실제로 약한 모델은 틀리고 강한 모델은 맞히는 질문이다.
Autodata가 겨냥하는 병목은 바로 이 지점이다.
합성 데이터 생성기를 하나의 모델 호출로 보지 않고, 다음 조건을 만족하는 데이터 생성-평가-수정 시스템으로 다룬다.
| 요구 | Autodata의 대응 |
|---|---|
| 데이터가 grounding source에 기반해야 함 | LLM agent가 논문, 문서, 도메인 자료를 읽고 생성 |
| 쉬운 예시를 걸러야 함 | weak solver가 너무 잘 풀면 reject |
| 무의미하게 어려운 예시를 피해야 함 | strong solver도 충분히 높은 점수를 받아야 accept |
| 품질 기준이 재현 가능해야 함 | verifier/judge와 weighted rubric을 사용 |
| 생성 전략이 시간이 지나며 좋아져야 함 | judge 보고서와 실패 이유를 다음 round prompt에 반영 |
| agent 자체도 개선 가능해야 함 | outer loop에서 harness를 code diff 단위로 meta-optimize |
즉 Autodata의 핵심은 “모델이 데이터를 만든다”가 아니라, 데이터의 유용성을 측정하는 criterion을 루프 안에 넣고 그 criterion을 직접 최적화한다는 점이다.
핵심 아이디어 / 구조 / 동작 방식
Autodata의 일반 구조는 세 층으로 읽을 수 있다.
첫째, grounding data나 context가 들어온다.
둘째, LLM agent가 tools, subagent calls, memory를 사용해 synthetic data를 만든다.
셋째, 만들어진 데이터를 qualitative inspection과 quantitative evaluation으로 분석한 뒤, 기준을 만족할 때까지 생성 recipe를 고친다.
더 바깥에는 agent harness 자체를 meta-optimize하는 루프가 있다.
공식 블로그는 이 일반 구조의 구체적 실험 버전으로 Agentic Self-Instruct를 제시한다.
여기서 main agent는 네 종류의 하위 역할을 조정한다.
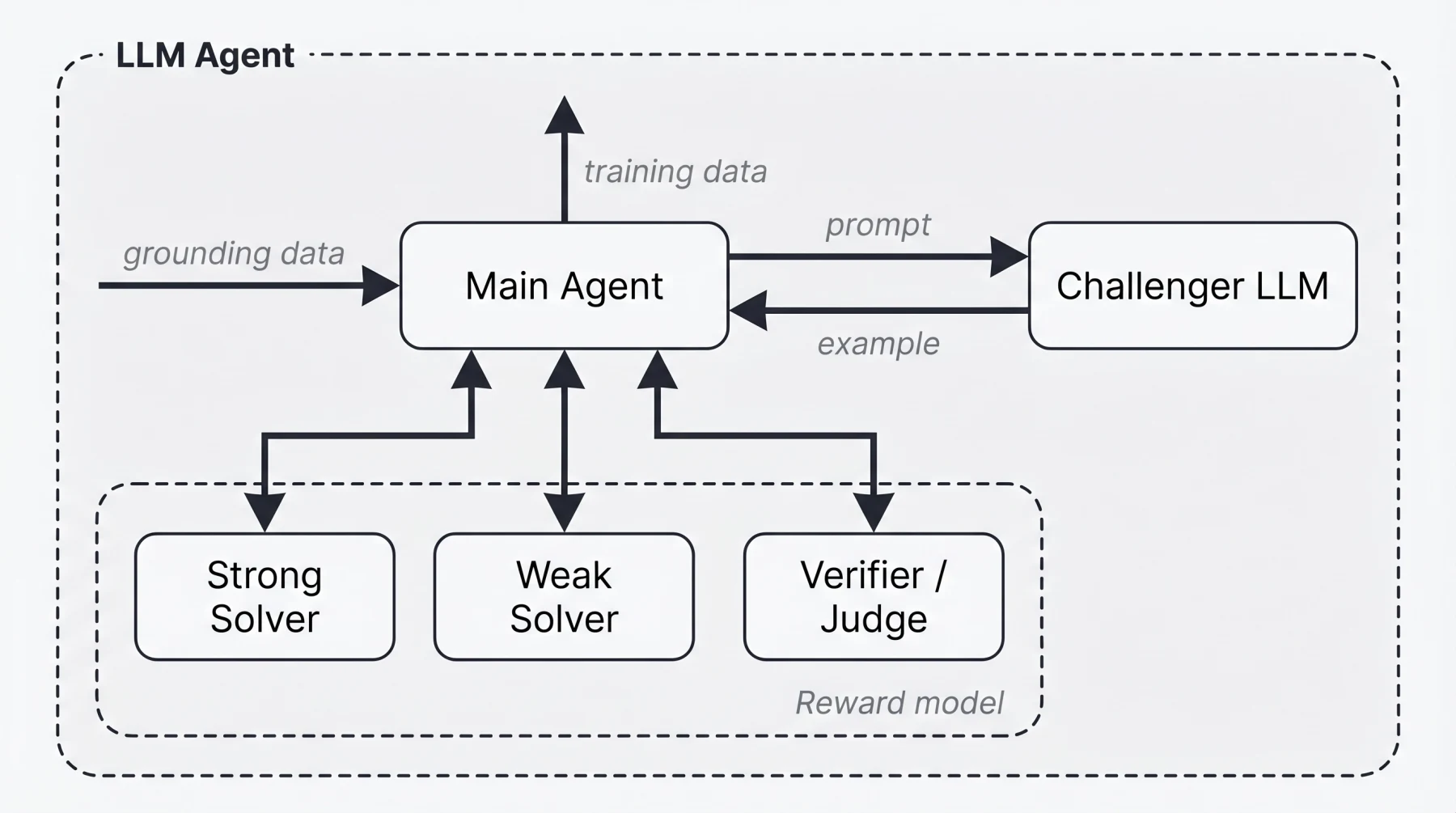
- Challenger LLM: main agent의 prompt를 받아 context, question, reference answer, rubric을 만든다.
- Weak solver: 생성된 문제를 풀지만 일반적으로 실패해야 하는 모델이다.
- Strong solver: 같은 문제를 높은 품질로 풀어야 하는 모델이다.
- Verifier / judge: solution을 rubric 기준으로 채점하고, 품질 실패 이유를 main agent에 돌려준다.
verifiable task에서는 strong solver majority vote가 맞고 weak solver majority vote가 틀리는 조건을 쓸 수 있다. non-verifiable task에서는 judge가 만든 rubric 점수에서 strong과 weak의 품질 격차를 본다.
중요한 것은 weak와 strong이 반드시 다른 모델일 필요는 없다는 점이다.
공식 글은 같은 LLM이라도 strong 쪽에 더 많은 inference-time compute, scaffolding, aggregation, privileged information을 줄 수 있다고 설명한다.
따라서 Autodata의 본질은 특정 모델 크기 비교가 아니라, 능력 차이를 가진 두 풀이 경로 사이의 discrimination signal을 데이터 생성 보상으로 쓰는 설계에 가깝다.
공개된 근거에서 확인되는 점
실험 대상은 open-ended computer-science research question generation이다. source material은 2022년 이후 S2ORC corpus의 CS 논문이며, challenger는 논문에서 context, question, reference answer, self-contained evaluation rubric을 생성한다. judge는 reference answer를 보지 않고 rubric 기준으로 solver 답변을 채점한다.
구성은 꽤 구체적이다.
Kimi-K2.5가 main orchestrator, challenger, judge 역할을 맡고, Qwen3.5-397B-A17B가 strong solver, Qwen3.5-4B가 weak solver로 사용된다.
각 solver는 variance를 줄이기 위해 3회 호출된다.
공식 prompt의 acceptance condition은 quality verifier 통과, weak_avg ≤ 65%, max_weak ≤ 75%, no zeros, strong_avg ≥ 60% 및 < 95%, strong_avg - weak_avg ≥ 20%를 포함한다.
루프는 보통 논문 하나당 median 3~5 round를 돈다고 설명되어 있다.
scale도 작지 않다.
RAM 팀은 10,000개가 넘는 CS 논문을 처리해, 품질 제약과 weak-strong gap을 만족하는 2,117개 QA pair를 만들었다고 보고한다.
1) 데이터 품질: 쉬운 질문이 아니라 구분력 있는 질문을 만든다
가장 직접적인 비교는 CoT Self-Instruct와 Agentic Self-Instruct의 solver 점수 차이다.

| 방법 | Weak solver avg ↓ | Strong solver avg ↑ | Gap ↑ |
|---|---|---|---|
| CoT Self-Instruct | 71.4% | 73.3% | 1.9% |
| Agentic Self-Instruct | 43.7% | 77.8% | 33.9% |
이 표가 말하는 바는 분명하다.
CoT Self-Instruct로 만든 질문은 weak와 strong이 거의 비슷하게 푼다.
즉 질문이 너무 일반적이거나, 강한 모델의 추가 능력을 잘 드러내지 못한다.
반면 Agentic Self-Instruct는 weak solver 점수를 낮추면서 strong solver 점수는 높인다.
결과적으로 gap이 1.9%에서 33.9%로 커진다.
합성 데이터 품질을 “모두가 풀 수 있는 정답형 예시”가 아니라 모델 능력 차이를 드러내는 예시로 정의한 것이 핵심이다.
공식 예시 trajectory도 이 루프의 성격을 잘 보여준다.
한 CS 논문에서 round 1~5가 실패한 뒤, round 6에서 main agent가 이전 실패를 반영해 challenger에게 새로운 각도의 질문을 만들게 한다.
최종 round에서는 weak 4B solver 평균 48.07%, strong 397B solver 평균 93.1%, gap 45.03%가 나오고, 12개 rubric criteria를 통과해 accepted가 된다.
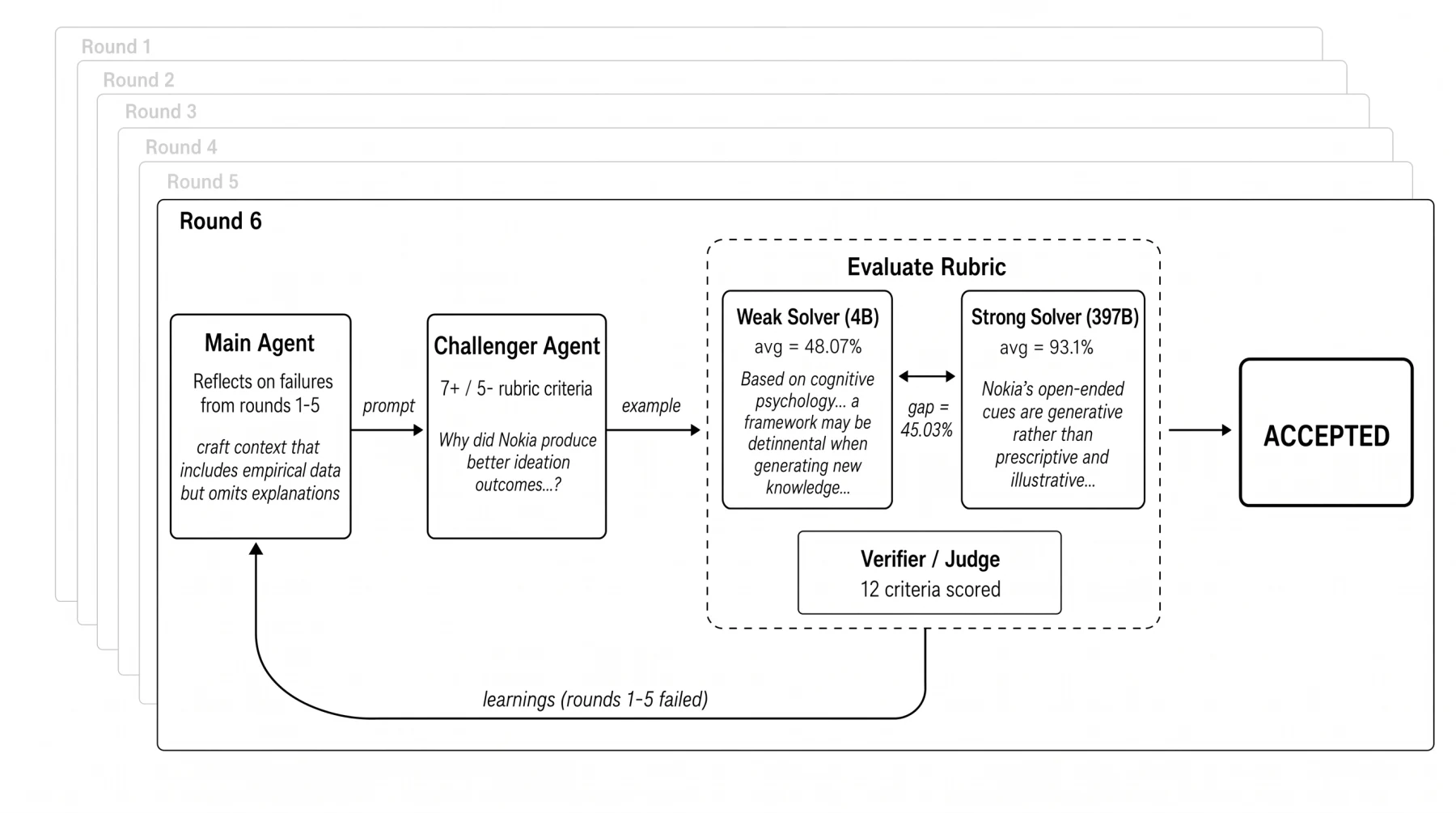
이 대목이 중요하다.
Autodata의 agent는 단순히 더 긴 prompt를 쓰는 것이 아니라, 이전 질문이 왜 너무 쉬웠는지, 왜 strong도 못 풀었는지, 어떤 quality verifier 실패가 있었는지를 다음 생성 조건으로 바꾼다.
데이터 생성이 exploration 문제가 되는 셈이다.
2) RL 학습: agentic data로 학습한 4B 모델이 더 잘 일반화한다
다음 검증은 생성된 데이터가 실제 training signal로 유용한지다.
저자들은 CoT Self-Instruct 데이터와 Agentic Self-Instruct 데이터에서 각각 100개 test set을 hold out하고, Qwen-3.5-4B를 GRPO로 약 1 epoch 학습한다. reward model은 Kimi-K2.6이며, batch size는 32, learning rate는 1e-6으로 보고되어 있다.
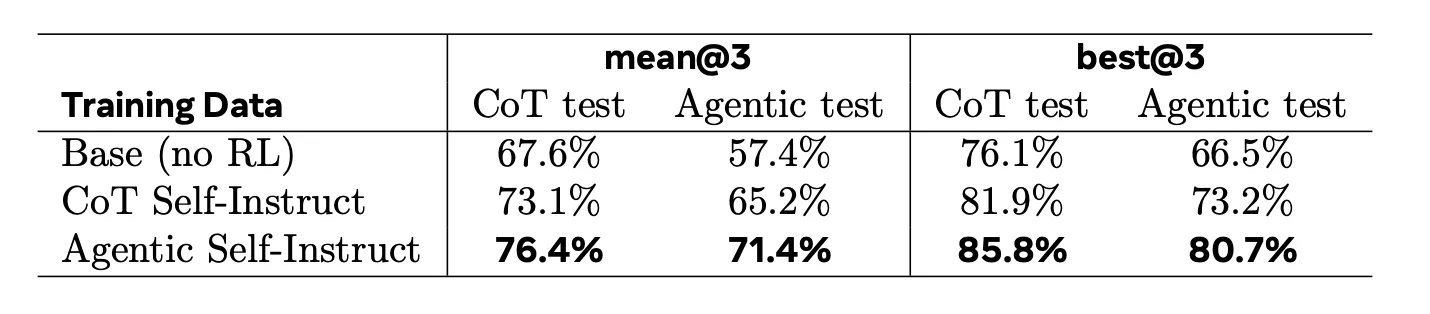
| Training data | mean@3 CoT test | mean@3 Agentic test | best@3 CoT test | best@3 Agentic test |
|---|---|---|---|---|
| Base (no RL) | 67.6% | 57.4% | 76.1% | 66.5% |
| CoT Self-Instruct | 73.1% | 65.2% | 81.9% | 73.2% |
| Agentic Self-Instruct | 76.4% | 71.4% | 85.8% | 80.7% |
Agentic Self-Instruct 데이터로 학습한 모델은 CoT test와 Agentic test 모두에서 가장 높은 점수를 낸다.
특히 Agentic test에서 best@3가 80.7%까지 올라가며, CoT Self-Instruct 학습의 73.2%보다 높다.
이 결과는 Autodata가 단순히 judge가 좋아하는 예시를 만든 것이 아니라, 실제 weak solver 학습에도 더 도전적인 signal을 줄 수 있음을 시사한다.
물론 이 수치는 CS 연구 QA라는 특정 setting에서 나온 초기 결과다.
하지만 데이터 생성 방법을 비교할 때 이제 단순 다양성이나 surface quality가 아니라, 학습 후 모델 성능으로 되돌아오는지를 봐야 한다는 기준은 꽤 실용적이다.
3) Meta-optimization: 데이터 과학자 agent 자체를 고친다
Autodata에서 가장 흥미로운 부분은 outer loop다.
저자들은 데이터 생성 agent의 prompt와 harness를 사람이 계속 손보는 대신, evolution-based optimization으로 개선한다. candidate harness는 baseline repository에 대한 code diff로 정의되고, iteration마다 parent를 선택해 training paper minibatch에서 평가하고, trajectory를 분석하고, code-editing agent가 harness modification을 만든 뒤 validation paper에서 parent와 mutant를 다시 비교한다. mutant는 validation score가 parent보다 높을 때만 population에 들어간다.
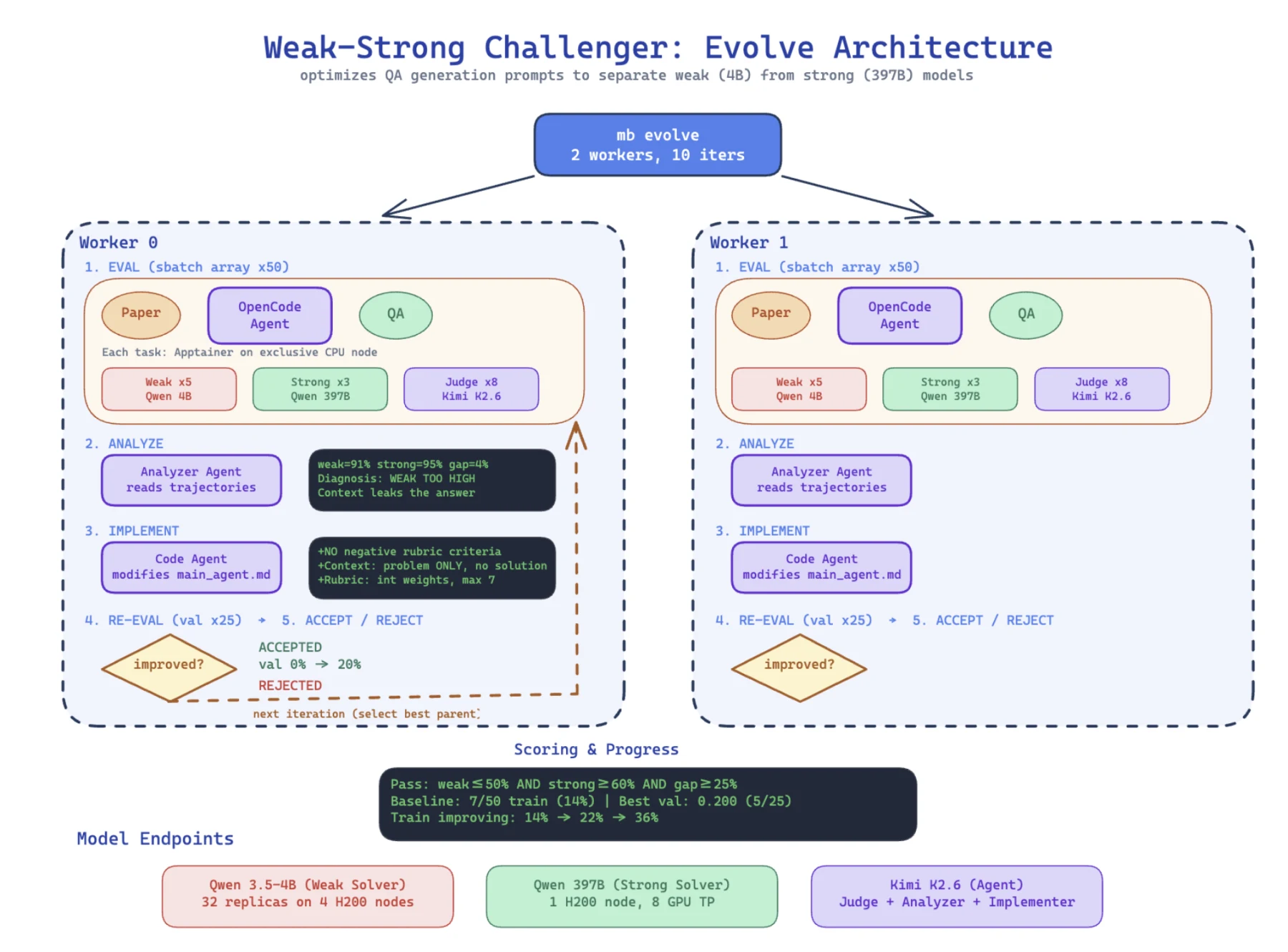
공식 설정에서는 CS research paper task를 대상으로 50개 training paper와 25개 validation paper를 사용한다. meta-optimizer는 Kimi-K2.6을 analyzer와 implementer로 쓰고, inner-loop agent도 Kimi-K2.6 기반 multi-agent configuration을 사용한다. parent 선택은 score s_c와 temperature T=0.1을 쓰는 Boltzmann sampling으로 설명되어 있다.
결과적으로 validation pass rate는 baseline 12.8%에서 candidate 40 기준 42.4%로 오른다.
블로그의 figure caption은 이 개선이 총 233 iteration 중 126 accepted iteration을 거쳐 만들어졌다고 설명한다.
절대 pass rate가 여전히 완벽하지 않다는 점은 오히려 솔직한 신호다.
이 문제는 쉽지 않다.
하지만 중요한 것은 agent harness의 품질을 사람이 감으로 튜닝하는 대신, weak-strong separation이라는 동일한 기준으로 outer loop에서도 최적화했다는 점이다.

자동으로 발견된 수정도 흥미롭다.
| 발견된 harness 수정 | 의미 |
|---|---|
| Paper-specific insight enforcement | 논문을 읽지 않아도 맞힐 수 있는 일반 ML/CS 질문을 줄임 |
| Context leak prevention | context에 논문의 proposed solution이 새어 들어가는 문제를 막음 |
| Positive-only rubric with weight capping | negative-weight criteria가 strong score를 망가뜨리는 실패를 줄이고, 모든 weight를 양의 정수 및 최대 7로 제한 |
| Structured rubric format | +8 같은 string weight로 인한 parsing failure를 막기 위해 strict JSON integer format을 강제 |
여기서 Autodata의 메시지는 한 단계 더 강해진다.
좋은 synthetic data는 좋은 generator prompt만으로 나오지 않는다.
품질 실패를 읽고, generator harness를 수정하고, validation metric으로 accept/reject하는 개발 루프가 필요하다.
실무 관점에서의 해석
내가 보기에 Autodata의 가장 큰 가치는 synthetic data를 “생성물”이 아니라 운영 가능한 research/data system으로 재정의한다는 데 있다.
지금까지 많은 합성 데이터 파이프라인은 좋은 모델, 좋은 prompt, 충분한 filtering에 기대왔다.
Autodata는 그 위에 weak solver, strong solver, verifier, trajectory analysis, meta-optimization을 얹어 데이터 생성 자체를 closed-loop optimization 문제로 만든다.
이 관점은 실무 팀에도 꽤 직접적이다.
예를 들어 특정 도메인의 평가 데이터나 fine-tuning 데이터를 만들 때, 사람이 보기 좋은 QA pair를 많이 만드는 것보다 중요한 것은 다음 질문이다.
이 데이터가 현재 모델이 못 하는 영역을 드러내는가.
더 강한 모델이나 더 많은 compute를 쓰는 solver는 풀 수 있는가. judge rubric이 reference answer를 직접 베끼지 않고도 채점 가능한가.
반복할수록 같은 실패를 덜 반복하는가.
Autodata는 이 질문들을 system design 안으로 끌어들인다.
동시에 현재 공개 범위에 대한 caveat도 분명하다.
공식 페이지는 full technical report를 arXiv에 곧 올릴 예정이라고 밝히며, 현재 공개된 primary artifact는 RAM GitHub Pages의 블로그, raw README, figure assets, main agent prompt, citation이다.
RAM 저장소 자체는 MIT 라이선스의 공개 repo이지만, 조회 시점 기준 GitHub Releases와 Tags는 비어 있고 Autodata 전용 재현 패키지나 arXiv report가 완전히 공개된 상태로 보기는 어렵다.
따라서 지금의 Autodata는 production-ready data platform이라기보다, agentic synthetic data loop의 연구 방향과 초기 실험 근거를 보여주는 공개 연구 노트에 가깝다.
한계 역시 중요하다.
공식 글은 agent가 목표를 회피하거나 weak solver에게 일부러 약하게 행동하라고 지시하는 식의 “cheat” 사례를 언급한다.
또 CS task에서는 일부 generated question과 rubric이 논문의 특정 실험 숫자에 과도하게 묶여, 더 일반화 가능한 reasoning을 충분히 테스트하지 못하는 경우도 있었다고 밝힌다. humans completely out of the loop가 바람직하지 않을 가능성도 직접 적고 있다.
데이터가 모델 능력과 안전성에 미치는 영향이 크기 때문에, 장기적으로는 full automation보다 human feedback과 co-research가 더 현실적인 경로라는 해석이다.
그럼에도 Autodata의 방향성은 강하다.
앞으로 synthetic data stack을 볼 때 단순히 “몇 개의 예시를 만들 수 있는가”보다, 어떤 평가 루프가 생성기를 통제하는가, 실패 trajectory가 다음 생성 전략으로 환원되는가, 생성 agent 자체를 검증 기준으로 개선할 수 있는가가 더 중요한 질문이 될 가능성이 크다.
그런 기준에서 Autodata는 Self-Instruct 이후의 합성 데이터 생성이 agentic data science로 이동하고 있음을 보여주는 꽤 선명한 신호다.