AI 에이전트의 “자가 개선”은 매력적인 표현이지만, 실제 시스템에서는 대부분 프롬프트를 조금 고치거나, 실패 로그를 메모리에 쌓거나, 별도 optimizer가 산출한 패치를 사람이 나중에 반영하는 정도에 머물렀다.
문제는 개선 대상과 개선 과정을 같은 코드 경로 안에 섞어 두면, 무엇이 바뀌었는지 추적하기 어렵고, 실패했을 때 되돌리기도 어렵다는 점이다.
Autogenesis: A Self-Evolving Agent Protocol은 이 문제를 에이전트 프로토콜의 관점에서 다시 잡는다.
논문은 Autogenesis Protocol, AGP를 제안하고, 그 위에 Autogenesis System, AGS라는 자가 진화 멀티 에이전트 런타임을 얹는다.
핵심은 “어떤 구성요소가 진화 가능한가”와 “어떤 연산자가 그것을 어떻게 바꾸는가”를 분리하는 것이다.
이 분리는 단순한 설계 미학이 아니다.
논문이 겨냥하는 것은 MCP나 A2A 같은 기존 프로토콜이 잘 다루는 호출·통신 계층 바깥에 있는 문제다.
장기 실행 에이전트가 프롬프트, 도구, 메모리, 환경, 하위 에이전트를 계속 바꿔 가며 작업하려면, 각 구성요소가 명시적 상태와 버전, 생명주기, 롤백 가능한 업데이트 경로를 가져야 한다.
Autogenesis는 그 레이어를 자가 진화의 표준 인터페이스로 만들려 한다.
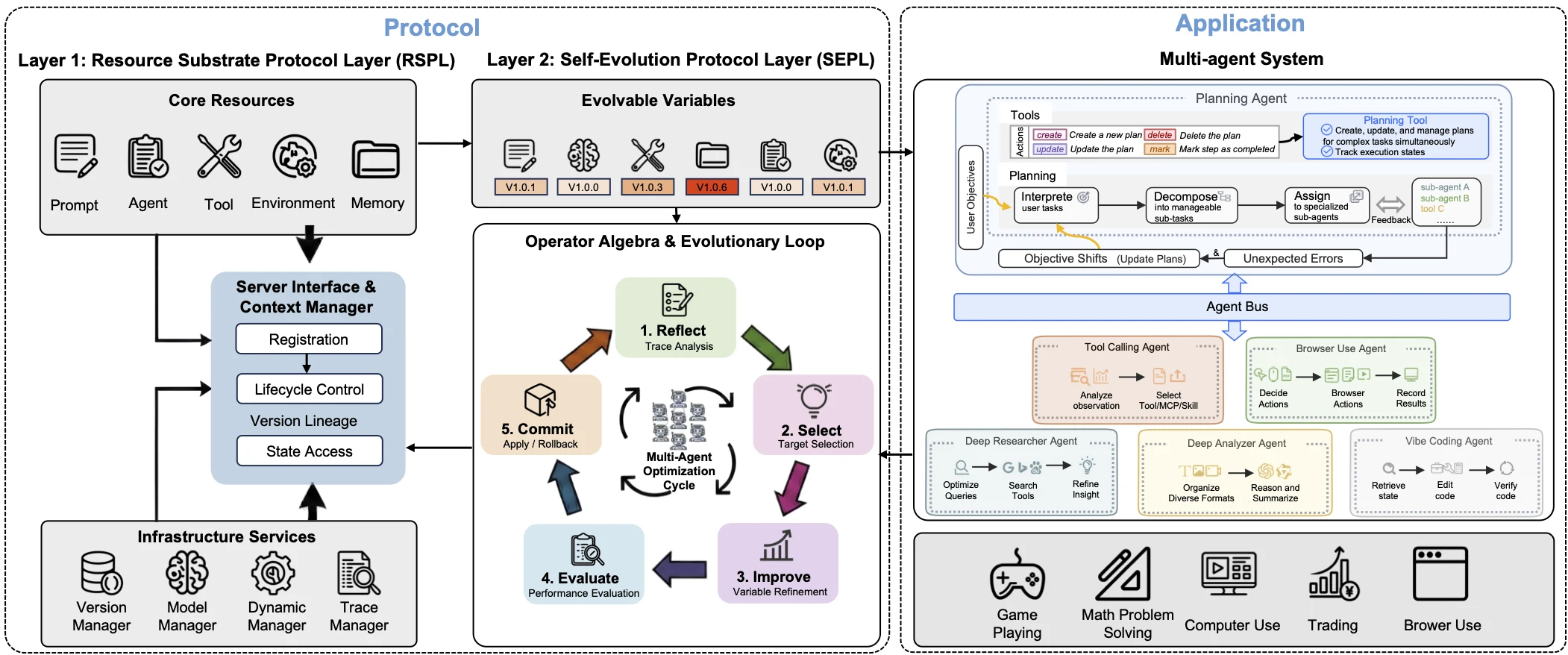
무엇을 해결하려는가
에이전트 시스템은 점점 여러 종류의 리소스를 동시에 다룬다.
시스템 프롬프트, 태스크별 프롬프트, 도구 wrapper, 브라우저나 파일시스템 같은 환경, 장기 메모리, 계획 에이전트와 실행 에이전트가 모두 한 작업 안에 들어온다.
이 구성요소들이 고정되어 있을 때도 운영은 쉽지 않지만, “실행 중 스스로 개선한다”는 목표가 들어오면 더 복잡해진다.
Autogenesis가 보는 첫 번째 병목은 진화 대상의 불명확성이다.
기존 에이전트 프레임워크에서는 프롬프트를 바꿨는지, 도구 설명을 바꿨는지, 에이전트 정책을 바꿨는지, 메모리 상태가 바뀐 것인지가 한 실행 trace 안에서 뒤섞이기 쉽다.
이렇게 되면 성능이 좋아져도 어떤 리소스가 개선을 만든 것인지 알기 어렵고, 나빠졌을 때도 특정 버전으로 되돌리기 어렵다.
두 번째 병목은 업데이트 인터페이스의 부재다.
자가 개선이 안전하려면 업데이트는 즉흥적인 문자열 치환이 아니라, 제안, 평가, 적용, 롤백 가능한 커밋으로 다뤄져야 한다.
특히 프롬프트나 도구 코드처럼 행동을 직접 바꾸는 리소스는, 작은 변경도 장기 작업에서 큰 정책 드리프트로 이어질 수 있다.
세 번째 병목은 프로토콜과 런타임 사이의 간극이다.
논문은 Google A2A를 multi-agent communication 프로토콜, Anthropic MCP를 model-to-tool invocation 프로토콜로 보면서, 둘 다 내부 리소스의 생명주기·버전·상태 변이를 직접 표준화하지는 않는다고 해석한다.
Autogenesis의 목표는 이 빈칸, 즉 에이전트가 자기 구성요소를 바꿔 가며 성장하는 데 필요한 리소스 관리 계층을 채우는 것이다.
핵심 아이디어 / 구조 / 동작 방식
AGP는 두 계층으로 나뉜다.
첫 번째는 Resource Substrate Protocol Layer, RSPL이다.
RSPL은 에이전트 시스템의 구성요소를 프로토콜에 등록된 리소스로 다룬다.
논문이 잡은 최소 공통분모는 다섯 가지다.
| 리소스 유형 | 의미 | 왜 중요한가 |
|---|---|---|
| Prompt | 시스템·태스크 지시문 | 가장 싸고 빠르게 바꿀 수 있는 행동 제어면 |
| Agent | 의사결정 정책 또는 역할 | planning, tool-calling, browser-use 같은 실행 단위 |
| Tool | 로컬 코드, MCP 도구, agent skill 등 | 실제 환경을 바꾸는 actuation layer |
| Environment | 파일시스템, 브라우저, 모바일, 트레이딩 환경 등 | 피드백과 상태 변화를 제공하는 세계 모델 |
| Memory | 세션·장기 상태 | 과거 실행 기록과 개선 근거를 보존하는 계층 |
중요한 점은 RSPL 리소스 자체는 passive하다는 것이다.
리소스가 자기 마음대로 스스로를 수정하지 않는다.
등록, 생명주기 제어, 버전 lineage, state access 같은 작업은 server interface와 context manager를 통해 이뤄진다.
즉 “바뀔 수 있는 것”은 명시적으로 모델링하지만, “어떻게 바꿀 것인가”는 다음 계층으로 넘긴다.
두 번째 계층은 Self-Evolution Protocol Layer, SEPL이다.
SEPL은 자가 진화를 리소스 위의 operator algebra로 본다.
논문은 evolvable variable set이라는 추상화를 도입해 프롬프트, 에이전트, 도구, 환경, 메모리, 그리고 실행 산출물·reasoning trace를 공통의 최적화 대상 공간으로 올린다.
여기에 learnability mask를 붙여 실제로 바꿀 수 있는 부분과 그렇지 않은 부분을 구분한다.
SEPL의 실행 루프는 다음처럼 읽을 수 있다.
| 단계 | 역할 | 운영상 의미 |
|---|---|---|
| Reflect | trace와 실행 결과를 분석 | 실패 원인과 개선 후보를 찾는다 |
| Select | 바꿀 대상 리소스를 고른다 | 모든 것을 한꺼번에 바꾸지 않고 target을 제한한다 |
| Improve | 프롬프트·해법·변수 등을 개선 | reflection, TextGrad, Reinforce++, GRPO 같은 optimizer를 붙일 수 있다 |
| Evaluate | 개선 후보를 성능 기준으로 평가 | 단순 변경이 아니라 근거 있는 후보만 남긴다 |
| Commit | 적용 또는 롤백 | 버전 lineage와 감사 가능성을 유지한다 |
AGS는 이 프로토콜의 구체적 런타임이다.
논문은 planning agent와 여러 sub-agent를 Agent Bus에 first-class participant로 등록하는 구조를 쓴다. planning agent는 직접 하위 작업을 수행하지 않고, plan.md 형태의 계획 산출물을 만들고, 독립 작업은 병렬로, 의존 작업은 순차로 sub-agent에 배정한다. sub-agent는 필요한 prompt와 tool 리소스를 RSPL registry에서 가져와 실행하고, 결과와 trace를 공유 메모리에 남긴다.
한 라운드가 끝나면 planning agent가 결과를 모아 계획을 갱신하고, 필요하면 다시 분해한다.
이 구조에서 “자가 진화”는 한 번의 마법 같은 업데이트가 아니라, 실행 trace를 보고 리소스를 고르고, optimizer로 후보를 만들고, 평가한 뒤, 버전 관리되는 변경으로 커밋하는 반복 루프다.
실무적으로는 에이전트 런타임에 Git-like semantics를 끼워 넣는 접근에 가깝다.
공개된 근거에서 확인되는 점
논문은 AGS를 세 종류의 벤치마크에서 평가한다.
첫째, GPQA-Diamond, AIME24, AIME25 같은 과학·수학 벤치마크에서 Prompt-Evo, Solution-Evo, Prompt-Solution-Joint-Evo를 비교한다.
둘째, GAIA와 HLE 같은 일반 에이전트 벤치마크에서 Agent-Evo를 비교한다.
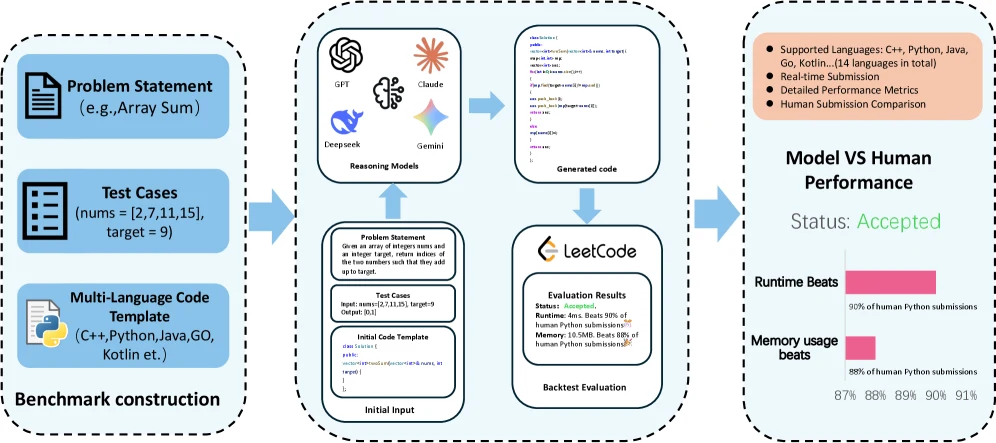
셋째, 자체 구성한 100개 최신 LeetCode 문제 기반 self-evolving code agent benchmark에서 실행 중 Solution-Evo가 실제 코드 품질을 개선하는지 본다.
과학·수학 실험은 자가 진화가 특히 중간 실패 지점이 많은 추론 문제에서 효과를 내는지를 보여 준다.
예를 들어 gpt-4.1은 AIME24에서 vanilla 23.34에서 PS-Joint-Evo 40.00으로 올라가며, 논문은 이를 71.38% 상대 개선으로 보고한다. gpt-4o는 AIME25에서 6.67에서 13.34로 올라가 100% 상대 개선을 보인다.
반대로 grok-4.1-fast처럼 이미 AIME24 96.67에 도달한 모델은 추가 개선 여지가 거의 없어 ceiling effect가 나타난다.
| 모델 / 설정 | Vanilla | 최고 Evo 설정 | 논문이 보고한 상대 개선 |
|---|---|---|---|
| gpt-4o / GPQA | 47.98 | 58.08 | 21.05% |
| gpt-4.1 / AIME24 | 23.34 | 40.00 | 71.38% |
| gpt-4.1 / AIME25 | 20.00 | 33.33 | 66.65% |
| claude-sonnet-4.5 / AIME25 | 73.33 | 90.00 | 22.73% |
| gemini-3-flash-preview / AIME25 | 83.33 | 93.33 | 12.00% |
GAIA 결과도 눈에 띈다.
Validation split 평균은 vanilla 89.70에서 Agent-Evo 93.33으로 올라가고, Test split 평균은 79.07에서 89.04로 올라간다.
특히 Test Level3는 61.22에서 81.63으로 올라가며, 논문은 33.34% 상대 개선으로 정리한다.
이 결과가 의미하는 바는, AGS가 단순 정답 생성이 아니라 planning과 tool-use가 포함된 장기 과제에서도 versioned agent evolution의 이점을 보였다는 주장이다.
코드 벤치마크는 Autogenesis의 메시지를 가장 직관적으로 보여 준다.
논문은 100개 최근 LeetCode 문제를 Python3, C++, Java, Go, Kotlin으로 풀게 하고, 실행 결과와 인간 제출 대비 runtime/memory beat를 함께 본다. backbone은 gemini-3-flash-preview이고, reflection budget은 3 rounds다.
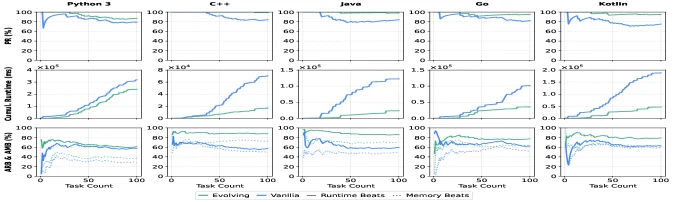
결과는 여러 언어에서 일관되게 개선을 보인다.
Solution-Evo는 Python3 pass count를 79에서 87로, C++를 84에서 99로, Java를 84에서 98로, Go를 82에서 95로, Kotlin을 75에서 95로 끌어올린다.
논문이 보고한 상대 개선은 10.1%에서 26.7% 범위다. runtime도 Python3 7.8%, C++ 46.4%, Java 23.0%, Go 19.8%, Kotlin 28.6% 줄어든다.
다만 memory는 대부분의 compiled language에서 줄지만 Python3와 Kotlin에서는 증가해, 정답률·속도·메모리 사이의 trade-off가 남아 있음을 보여 준다.
| 언어 | Vanilla pass count | Solution-Evo pass count | 상대 개선 | 평균 runtime 변화 |
|---|---|---|---|---|
| Python3 | 79 | 87 | 10.1% | 7.8% 감소 |
| C++ | 84 | 99 | 17.9% | 46.4% 감소 |
| Java | 84 | 98 | 16.7% | 23.0% 감소 |
| Go | 82 | 95 | 15.9% | 19.8% 감소 |
| Kotlin | 75 | 95 | 26.7% | 28.6% 감소 |
공개 구현 표면은 기대와 주의점을 동시에 준다. arXiv abstract와 HTML은 공식 코드 링크로 DVampire/Autogenesis를 제시한다.
GitHub API 기준 저장소는 2026년 4월 8일 생성, 2026년 5월 8일 최근 push, MIT License, Python 중심 코드베이스, stars 43, forks 3, open issues 0으로 확인된다.
루트에는 configs, datasets, docs, examples, libs, scripts, src, tests가 있고, src/optimizer에는 reflection_optimizer.py, textgrad_optimizer.py, reinforce_plus_plus_optimizer.py, grpo_optimizer.py가 들어 있다.
하지만 릴리스 성숙도는 아직 초기 연구 런타임에 가깝다.
GitHub releases/latest는 404이고 tags도 비어 있다.
README는 명시적으로 “codebase is currently undergoing active refactoring and optimization”이라고 쓰며, examples/run_tool_calling_agent.py는 functional이지만 다른 agent들은 progressively stabilized 중이라고 설명한다.
실행 안내도 scripts/INSTALL.md, .env.template, Vault 기반 API key management, 큰 scripts/requirements.txt에 의존한다.
따라서 현재 공개 repo는 논문의 구현 방향을 확인할 수 있는 연구 코드이지만, 곧바로 제품형 SDK처럼 가져다 쓰기에는 정리와 검증이 더 필요해 보인다.
실무 관점에서의 해석
Autogenesis의 가장 흥미로운 지점은 자가 진화를 “더 똑똑한 reflection prompt”가 아니라 리소스 관리 프로토콜로 본다는 데 있다.
많은 에이전트 시스템은 실행 후 reflection을 시키거나, 실패를 메모리에 저장하거나, 다음 프롬프트에 교훈을 붙이는 방식으로 개선을 흉내 낸다.
하지만 그 변화가 어떤 리소스의 어떤 버전에 반영됐는지, 어느 optimizer가 제안했는지, 어떤 평가를 통과했는지, 되돌릴 수 있는지는 별개의 문제다.
AGP/AGS는 이 문제를 정면으로 다룬다.
프롬프트, agent, tool, environment, memory를 같은 registry 안의 리소스로 다루면, 개선 루프는 훨씬 감사 가능해진다.
예를 들어 브라우저 에이전트가 실패했다면, 다음 실행에서는 system prompt만 바꿀지, tool schema를 바꿀지, memory retrieval 정책을 바꿀지, 환경 wrapper를 바꿀지를 명시적으로 분리할 수 있다.
그리고 각 선택은 버전과 lineage를 남긴다.
이 방향은 최근 에이전트 운영에서 점점 중요해지는 두 흐름과 맞닿아 있다.
하나는 MCP나 agent skill처럼 능력을 패키징하고 불러오는 흐름이고, 다른 하나는 실패 로그와 평가 데이터를 이용해 에이전트 절차를 계속 고치는 흐름이다.
Autogenesis는 이 둘 사이에 “능력은 리소스이고, 개선은 리소스에 대한 버전 관리된 operator”라는 중간 추상화를 놓는다.
다만 실무 도입 관점에서는 과장을 경계해야 한다.
논문의 실험은 강한 개선 신호를 보여 주지만, 자가 진화는 항상 추가 inference round, token cost, latency를 동반한다.
코드 벤치마크에서는 judge feedback이 명확하기 때문에 Solution-Evo가 잘 작동하지만, 실제 업무형 에이전트에서는 reward signal이 더 흐릿하다.
잘못 정의된 목표나 noisy evaluator는 행동 드리프트를 만들 수 있고, 롤백 메커니즘만으로 alignment 문제를 해결할 수는 없다.
또 하나의 주의점은 평가 범위다.
논문은 Prompt-Evo, Solution-Evo, Agent-Evo 중심으로 실험을 구성한다.
Environment와 Memory resource evolution도 구현됐다고 언급하지만, 독립 ablation으로 충분히 검증된 것은 아직 아니다.
장기 개인 비서나 운영 자동화 에이전트에서 가장 위험한 변경이 바로 memory와 environment layer라는 점을 생각하면, 이 부분은 앞으로 더 엄격한 평가가 필요하다.
그래도 Autogenesis가 던지는 질문은 매우 실용적이다.
에이전트가 매번 같은 실수를 반복하지 않게 하려면, “실패를 기억한다”만으로는 부족하다.
기억된 실패가 어떤 리소스 업데이트로 바뀌었는지, 그 업데이트가 어떤 평가를 통과했는지, 언제 롤백할 수 있는지까지 시스템이 알아야 한다.
Autogenesis는 이 과정을 프로토콜화하려는 시도다.
한계와 남은 질문
논문 자체도 한계를 분명히 적는다. self-evolution은 추가 inference round를 요구하므로 지연 시간과 토큰 비용이 늘어난다. strict budget에서 효율과 성능의 trade-off를 체계적으로 분석하는 일은 future work로 남아 있다.
또한 misspecified objective나 noisy reward signal이 있을 때 원치 않는 행동 드리프트가 생길 수 있으며, SEPL의 version control과 rollback은 기본 안전장치일 뿐, 더 강한 alignment verification은 아직 열린 문제다.
공개 repo의 상태도 같은 방향으로 읽어야 한다.
MIT 라이선스와 코드 링크가 있고, optimizer와 agent/runtime 파일도 상당히 풍부하지만, 공식 README가 active refactoring을 명시하고 releases/tags가 없는 상태다.
즉 현재 Autogenesis는 “완성된 표준”이라기보다, 자가 진화 에이전트를 어떻게 표준화할 수 있을지 보여 주는 초기 프로토콜·런타임 제안에 가깝다.
그럼에도 방향성은 중요하다.
에이전트의 다음 병목은 단순히 모델이 더 똑똑해지는 것이 아니라, 에이전트가 자기 주변의 프롬프트, 도구, 메모리, 환경, 하위 에이전트를 안전하게 바꾸고 검증하는 방법이다.
Autogenesis는 그 문제를 “자가 개선”이라는 느슨한 말에서 꺼내 버전 관리되는 리소스와 감사 가능한 evolution operator의 문제로 옮긴다.
바로 그 점이 이 논문의 가장 큰 가치다.