에이전트 스킬 생태계가 커질수록 문제는 “스킬을 많이 모으는 것”에서 “어떤 스킬을 언제 노출하고, 실행 후 어떤 경험을 믿고 축적할 것인가”로 이동한다. SKILL.md는 코드, 절차, 참고 문서, 검증 루틴을 한 디렉터리에 묶는 좋은 단위지만, 공개 저장소 전체로 확장하면 중복·품질 편차·환경 의존성·검증 불가능성이 동시에 따라온다. 잘못 고른 스킬은 도움이 아니라 context pollution이 되고, 우연히 성공한 궤적을 그대로 저장하면 다음 작업의 실패 원인이 된다.
SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution는 이 병목을 정면으로 다룬다. Hugging Face Papers에 올라온 arXiv 2605.18401과 공식 GitHub 저장소, 프로젝트 페이지를 종합하면 SkillsVote의 핵심은 단순한 스킬 검색기가 아니라 스킬 라이브러리의 수명주기 거버넌스 레이어다. 수집된 스킬을 프로파일링하고, 작업 전에 관련 스킬만 추천하며, 작업 후에는 실행 궤적을 하위 작업 단위로 분해해 실제로 도움이 된 지식만 보수적으로 라이브러리에 반영한다.
이 논문이 흥미로운 이유는 최근 에이전트 시스템의 중요한 질문을 모델 학습이 아니라 외부 지식 운영 문제로 바꿔 놓기 때문이다. 모델을 업데이트하지 않아도, 어떤 스킬을 노출하고 어떤 경험을 보존할지 제대로 통제하면 frozen agent의 성능을 끌어올릴 수 있다는 주장이다.
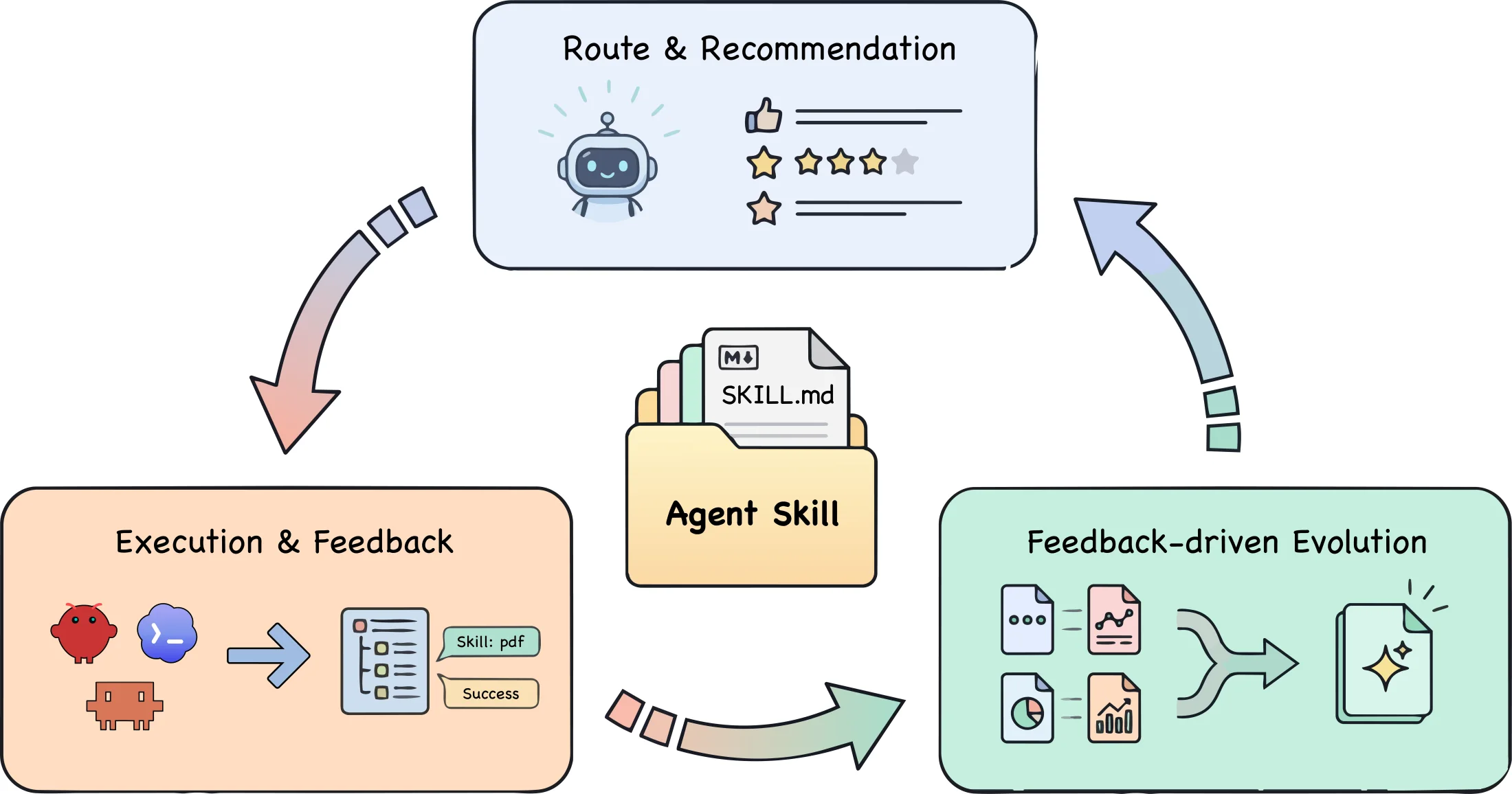
무엇을 해결하려는가
오늘의 에이전트 스킬 논의는 보통 두 축으로 나뉜다. 하나는 좋은 SKILL.md를 어떻게 작성할 것인가이고, 다른 하나는 많은 스킬 중 필요한 것을 어떻게 찾을 것인가다. SkillsVote는 여기에 세 번째 축을 추가한다. 실행 후 얻은 경험을 어떤 기준으로 스킬 라이브러리에 반영할 것인가다.
논문은 공개 스킬 생태계를 이미 marketplace scale에 도달한 대상으로 본다. 공식 README는 GitHub에서 1.68M개 이상의 SKILL.md 파일을 발견했고, 그중 790K개 이상이 Anthropic skill validator 기준 format-valid라고 설명한다. 이 정도 규모에서는 수작업 큐레이션이나 단순 popularity ranking만으로는 부족하다. 스킬 이름과 설명만으로는 실행 환경 요구사항, 의존성, 검증 가능성, 실제 절차 품질을 판단하기 어렵기 때문이다.
더 근본적인 문제는 경험 축적의 오염이다. 장기 작업을 수행한 에이전트는 풍부한 궤적을 남긴다. 하지만 그 궤적에는 스킬이 실제로 기여한 부분, 에이전트가 독립적으로 탐색한 부분, 환경 문제 때문에 실패한 부분, 평가 신호가 애매한 부분이 뒤섞여 있다. 이 전체를 “교훈”으로 저장하면 라이브러리는 빠르게 커지지만 품질은 떨어진다. SkillsVote는 바로 이 지점에서 노출 제어, 책임 귀속, 보수적 진화를 결합한다.
핵심 아이디어 / 구조 / 동작 방식
SkillsVote의 전체 구조는 네 단계로 읽을 수 있다.
| 단계 | 역할 | 중요한 설계 포인트 |
|---|---|---|
| 수집·프로파일링 | 공개 또는 사내 SKILL.md 라이브러리를 수집하고 환경 요구사항·품질·검증 가능성을 분석 |
스킬을 단순 텍스트 chunk가 아니라 디렉터리 단위 실행 패키지로 취급 |
| 작업 전 추천 | 별도 추천 에이전트가 라이브러리를 검색해 관련 스킬과 짧은 사용 가이드를 solver agent에 노출 | 전체 라이브러리를 context에 넣지 않고 task-conditioned exposure control 수행 |
| 실행 후 귀속 | 궤적을 하위 작업 단위로 분해하고 성공·실패 원인을 스킬, 독립 탐색, 환경, 평가 신호에 귀속 | task-level summary보다 세밀하고 step-level trace보다 재사용 가능한 granularity 사용 |
| 통제된 진화 | 성공했고 재사용 가능한 탐색만 기존 스킬 수정 또는 신규 스킬 생성으로 라우팅 | 실패·불확실·환경 의존 증거는 직접적인 라이브러리 업데이트에서 제외 |
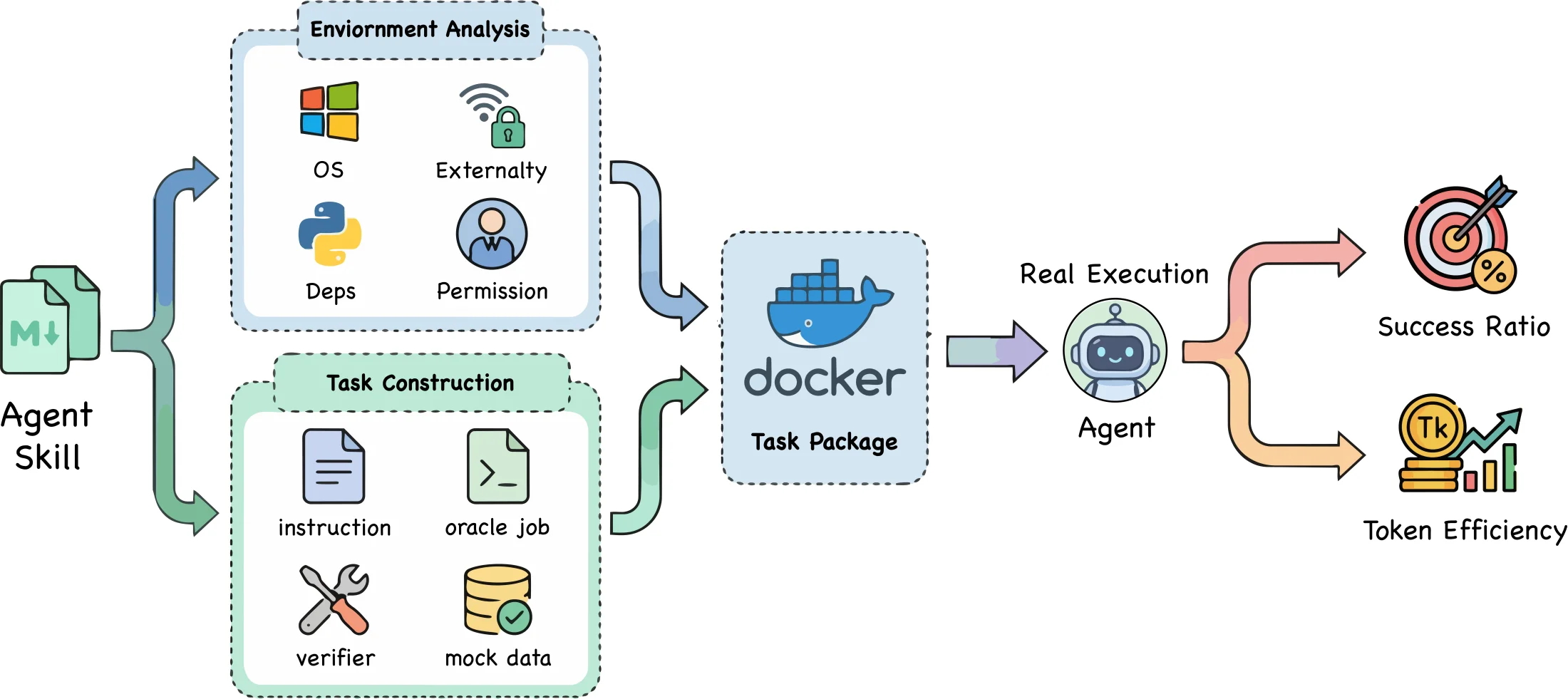
첫 단계는 open-source skill corpus를 실행 준비 관점에서 프로파일링하는 것이다. 논문은 운영체제 가정, 쓰기 권한, sudo, 네트워크, API key, CLI 도구, MCP 서버, 환경 변수 같은 runtime requirement를 본다. 동시에 스킬이 일관되고 완결된 실행 단위인지, 성공 조건이 낮은 모호성으로 정의되는지, 재현 가능한 sandbox task로 만들 수 있는지도 평가한다. 즉 “스킬이 있다”와 “에이전트가 안전하게 써도 된다”를 분리한다.
두 번째는 agentic library search다. 기존 progressive disclosure 방식은 짧은 metadata를 먼저 보여 주고 필요할 때 전체 스킬을 읽게 한다. SkillsVote는 여기서 한 걸음 더 나아가, solver agent가 작업을 시작하기 전에 별도 추천 단계가 로컬 스킬 라이브러리를 검색하고 후보 SKILL.md와 관련 리소스를 선택적으로 읽는다. 결과물은 “이 작업에 노출할 스킬 목록”과 “어떻게 써야 하는지”에 대한 압축 가이드다. 전체 라이브러리를 그냥 던지는 것보다 negative transfer를 줄이려는 설계다.
세 번째가 논문의 핵심인 하위 작업 단위 귀속이다. SkillsVote는 전체 task success만 보지 않고, 궤적을 semantically complete subtask로 나눈다. 각 subtask는 하나의 독립 목표, 하나의 주요 평가 신호, 최대 하나의 관련 스킬 context를 가진다. 이 단위에서 시스템은 성공 여부와 책임 원인을 함께 기록한다. 예를 들어 success_skill_used_with_extra_exploration은 기존 스킬을 실제로 사용했지만 추가 탐색을 통해 성공한 경우이고, success_no_skill_seen은 스킬 없이 독립 탐색으로 성공한 경우다. 반대로 환경 문제나 스킬 자체 문제로 실패한 경우는 진화의 직접 근거가 아니라 진단 신호로 남는다.
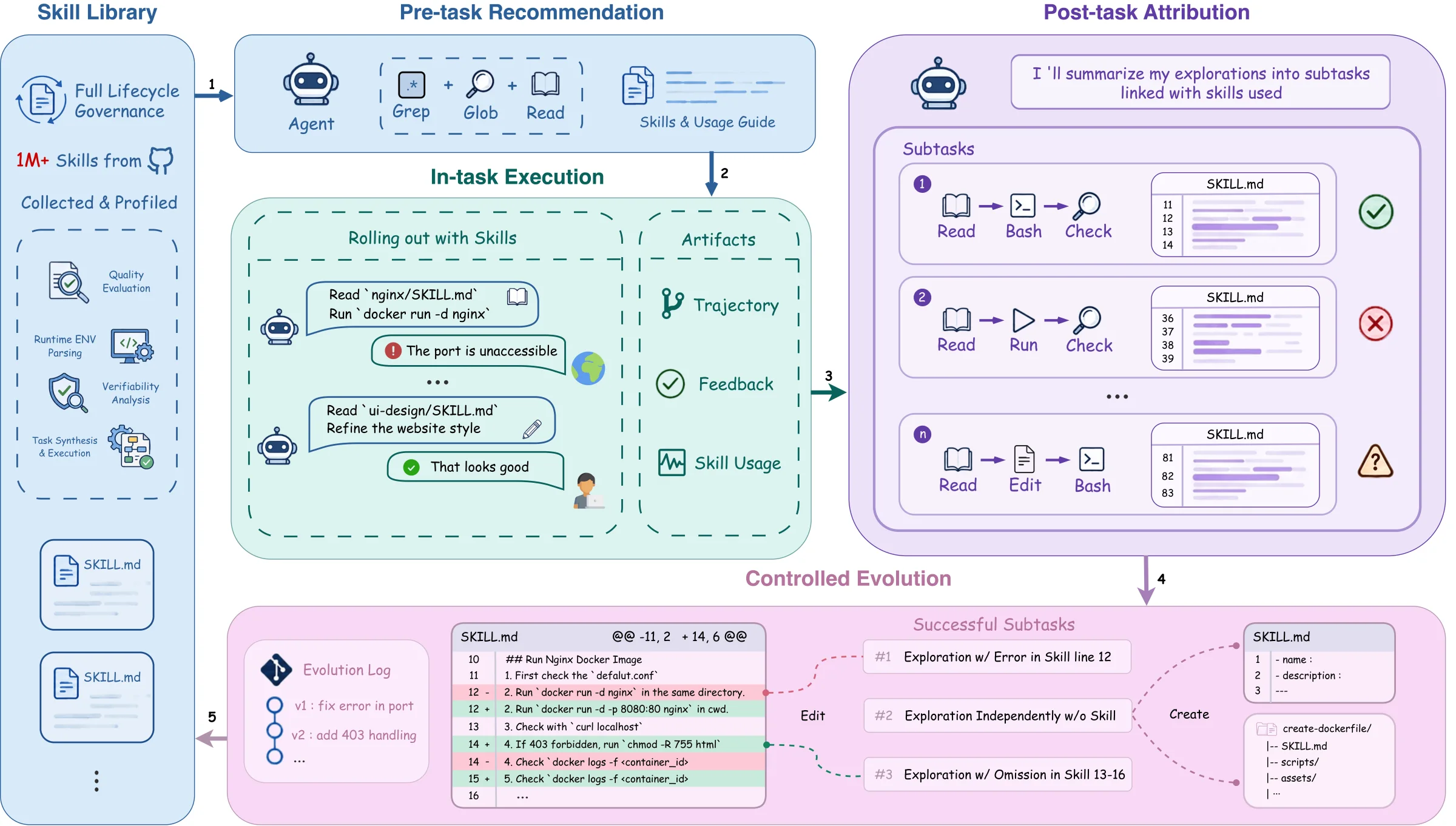
마지막 단계는 evidence-gated update construction이다. SkillsVote는 성공한 모든 경험을 저장하지 않는다. 성공했고, 재사용 가능한 exploration이 있으며, 특정 스킬 경계에 귀속될 수 있을 때만 업데이트 후보가 된다. 같은 절차나 precondition을 지지하는 증거는 먼저 aggregation되고, 기존 스킬을 보강할지, 새로운 독립 스킬을 만들지, 아니면 skip할지 결정된다. 따라서 SkillsVote의 진화는 append-only trace archive가 아니라 보수적인 skill maintenance workflow에 가깝다.
공개된 근거에서 확인되는 점
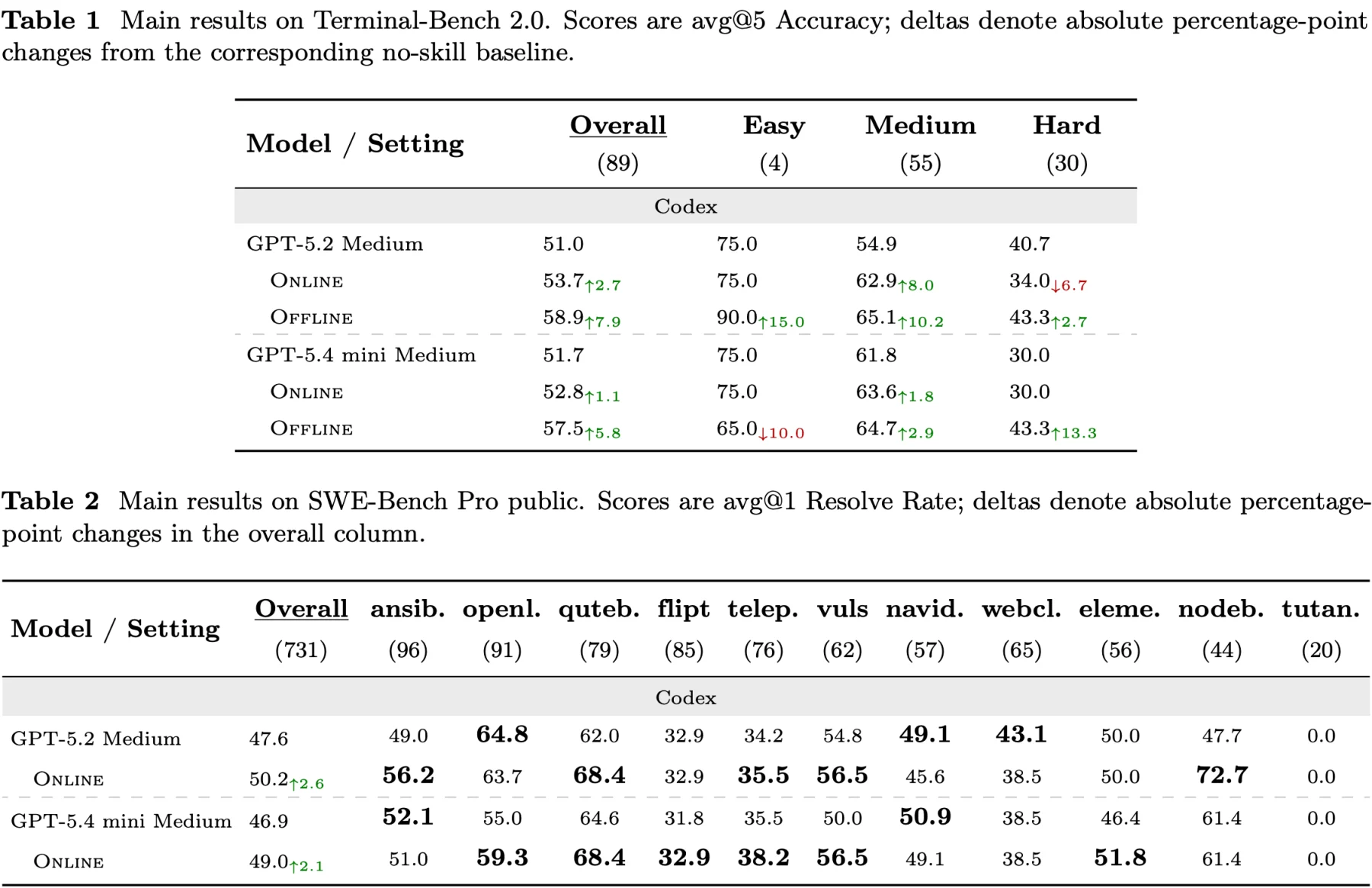
평가는 Terminal-Bench 2.0, Terminal-Bench Pro, SWE-Bench Pro public을 중심으로 구성된다. 논문 설정에 따르면 Terminal-Bench 2.0은 89개 terminal task, SWE-Bench Pro public은 11개 공개 저장소의 731개 long-horizon software-engineering task다. Terminal-Bench Pro에서는 48개 공개 software-engineering/system-administration task를 offline evolution 데이터로 사용했고, 2개의 환경 불안정 task는 제외했다.
공식 결과에서 가장 강한 신호는 offline evolution이다. Terminal-Bench Pro의 과거 궤적으로 만든 frozen skill library를 Terminal-Bench 2.0에 전이했을 때, GPT-5.2 Medium은 51.0에서 58.9로 올라 +7.9 percentage points, GPT-5.4 mini Medium은 51.7에서 57.5로 올라 +5.8 points를 기록한다. online evolution은 더 작지만 여전히 양의 효과를 보인다. 빈 라이브러리에서 순차 작업 흐름으로 축적할 때 Terminal-Bench 2.0에서는 GPT-5.2가 +2.7, GPT-5.4 mini가 +1.1 points 개선된다.
SWE-Bench Pro에서도 비슷한 패턴이 관찰된다. online evolution 기준 GPT-5.2 Medium은 47.6에서 50.2로 올라 +2.6 points, GPT-5.4 mini Medium은 46.9에서 49.0으로 올라 +2.1 points를 기록한다. 논문은 이 개선이 repository와 difficulty별로 균일하지 않다고 설명한다. 이는 스킬이 잘 맞는 작업에서는 큰 도움을 주지만, 약하게 관련된 스킬이 노출되면 오히려 해가 될 수 있다는 해석과 맞물린다.
| 벤치마크 / 설정 | 베이스라인 | SkillsVote 설정 | 변화 |
|---|---|---|---|
| Terminal-Bench 2.0, GPT-5.2, offline | 51.0 | 58.9 | +7.9 pp |
| Terminal-Bench 2.0, GPT-5.4 mini, offline | 51.7 | 57.5 | +5.8 pp |
| Terminal-Bench 2.0, GPT-5.2, online | 51.0 | 53.7 | +2.7 pp |
| Terminal-Bench 2.0, GPT-5.4 mini, online | 51.7 | 52.8 | +1.1 pp |
| SWE-Bench Pro public, GPT-5.2, online | 47.6 | 50.2 | +2.6 pp |
| SWE-Bench Pro public, GPT-5.4 mini, online | 46.9 | 49.0 | +2.1 pp |
추천 단계의 역할도 중요하다. 논문 분석은 스킬 노출이 중립적이지 않다고 말한다. 온라인 초기 라이브러리를 추천 없이 직접 노출하면 negative task-level delta가 커질 수 있고, 추천을 붙이면 sparse하거나 약하게 관련된 스킬을 solver context에서 걸러내는 noise filter 역할을 한다. offline으로 축적된 라이브러리에서도 추천은 positive contribution을 키우고 loss를 줄이는 방향으로 작동한다. 다시 말해 evolution은 재사용 가능한 지식을 만들고, recommendation은 그 지식이 현재 작업에 노출될지 결정한다.
또 하나의 근거는 verifiable task construction이다. SkillsVote는 프로파일링 단계에서 검증 가능한 스킬에 대해 instruction, oracle job, verifier, mock data, Docker task package를 구성하고 실제 agent-model combination으로 실행한다. 이 구조는 스킬 문서를 단순히 임베딩 검색 대상으로만 보지 않고, 실행 결과와 검증 신호가 붙은 artifact로 다루려는 의도를 보여준다.
공개 릴리스 표면도 꽤 구체적이다. GitHub 저장소 MemTensor/skills-vote는 MIT License로 공개되어 있고, README 기준 hosted skills-vote와 local/private library용 skills-vote-local 두 통합 경로를 제공한다. hosted 경로는 SKILLS_VOTE_API_KEY가 필요하고, local 경로는 로컬 SKILL.md 라이브러리에서 agentic search 또는 vector search로 추천할 수 있게 설계되어 있다. 다만 README roadmap 기준 local attribution과 local skill library evolution은 아직 미완료 항목으로 남아 있다. 즉 현재 공개물은 논문 실험 코드와 추천 통합은 상당 부분 열려 있지만, 전체 lifecycle을 로컬에서 완전히 닫는 제품형 릴리스는 아직 진행 중으로 보는 편이 맞다.
| 공개 표면 | 확인되는 내용 | 해석 |
|---|---|---|
| arXiv / HF Papers | lifecycle governance, recommendation, attribution, controlled evolution 제안 | 연구 중심의 메인 근거 |
| 프로젝트 페이지 | “SkillsVote — The Skills Engine for AI Agents” 포지셔닝 | Codex, Claude Code, Cursor 등 에이전트 런타임에 붙는 스킬 엔진으로 제시 |
| GitHub 저장소 | MIT License, benchmark scripts/configs, integration skills, examples, docs 공개 | 재현과 통합을 위한 research artifact bundle 성격 |
| README roadmap | hosted skill, local recommendation integration은 공개; local attribution/evolution은 계획 항목 | 추천기는 바로 실험 가능하지만 full local governance loop는 아직 성숙 중 |
| 릴리스 신호 | 조회 시점 기준 releases와 tags는 비어 있음 | 초기 연구 릴리스에 가까우며 versioned product release로 보기는 이르다 |
실무 관점에서의 해석
내가 보기에 SkillsVote의 가장 중요한 메시지는 스킬 생태계의 경쟁력이 “얼마나 많은 스킬을 보유했는가”가 아니라 스킬 노출과 보존을 얼마나 잘 통제하는가로 이동한다는 점이다. 에이전트 런타임 입장에서 스킬은 context budget을 쓰는 외부 기억이다. 따라서 틀린 스킬, 너무 일반적인 스킬, 현재 작업과 약하게 관련된 스킬은 단순히 무용한 것이 아니라 actively harmful할 수 있다.
이 관점은 기업 내부 에이전트 운영에도 직접적이다. 팀이 반복 업무를 SKILL.md로 쌓기 시작하면 처음에는 생산성이 올라가지만, 곧 중복 스킬, 오래된 명령, 환경별 예외, 권한이 필요한 절차, 검증 불가능한 팁이 섞인다. 그때 필요한 것은 더 큰 context window가 아니라 skill registry 운영 규칙이다. 어떤 스킬이 어떤 환경에서 실행 가능한지, 어떤 스킬을 어떤 작업에 노출할지, 작업 후 어떤 교훈만 반영할지를 정하는 정책이 필요하다. SkillsVote는 이 운영 문제를 실험 가능한 프레임워크로 만든다.
특히 하위 작업 단위 attribution은 꽤 실용적인 아이디어다. 실제 에이전트 작업은 하나의 success/fail label로 설명되지 않는다. 어떤 단계는 스킬 덕분에 빨라졌고, 어떤 단계는 모델이 새로 탐색했으며, 어떤 단계는 환경 문제 때문에 우회했을 수 있다. 이 차이를 구분하지 못하면 좋은 경험과 나쁜 경험이 같은 라이브러리로 흘러 들어간다. SkillsVote가 successful + reusable + attributable evidence만 업데이트 후보로 삼는 이유가 여기에 있다.
동시에 한계도 분명하다. 첫째, 결과 개선은 의미 있지만 평균적으로는 몇 percentage points 규모이며, task와 repository별 분산이 크다. 스킬 시스템은 만능 성능 부스터가 아니라 잘 맞는 작업에서 heavy-tailed gain을 만드는 도구에 가깝다. 둘째, attribution 자체도 LLM과 실행 로그 해석에 의존하므로, 잘못된 귀속이 생기면 보수적 설계에도 불구하고 library pollution 위험이 남는다. 셋째, 공개 저장소의 roadmap을 보면 local recommendation은 열려 있지만 local attribution/evolution까지 완전히 제품화된 단계는 아니다.
그럼에도 방향성은 매우 중요하다. 최근 agent skills 흐름은 “스킬 파일을 작성하자”에서 “스킬을 검색하자”로 이동했고, SkillsVote는 다음 단계를 제시한다. 즉 스킬을 운영하자는 것이다. 대규모 에이전트 시스템에서 성능은 모델, 도구, 메모리의 합이 아니라, 이 셋 사이의 노출·귀속·보존 정책에 의해 결정될 가능성이 크다. SkillsVote는 그 정책 계층을 실험적으로 분해한 사례로 볼 수 있다.
결론적으로 SkillsVote는 단순한 스킬 마켓플레이스나 검색 엔진이 아니다. 더 정확히는 에이전트가 경험을 외부 지식으로 축적할 때 필요한 lifecycle governance system이다. 지금은 초기 연구 릴리스의 성격이 강하지만, 스킬 레지스트리를 실제 운영 자산으로 만들려는 팀이라면 이 논문이 제시하는 “추천 → 실행 → 귀속 → 보수적 진화” 루프를 꽤 진지하게 볼 필요가 있다.