긴 비디오 생성에서 어려운 부분은 더 이상 “몇 초짜리 클립이 그럴듯한가”만이 아니다.
사용자가 여러 장면을 순차적으로 지시하고, 모델이 이전 장면의 문맥을 유지하며, 30초·60초 이상으로 늘어난 영상을 낮은 지연으로 만들어야 한다면 병목은 모델 품질과 GPU 시스템이 동시에 얽힌 문제가 된다.
Autoregressive video diffusion은 clean history와 noisy target을 길게 들고 가야 하고, VAE latent 준비, DiT 연산, KV cache, decoding이 모두 길이에 비례해 무거워진다.
NVIDIA의 LongLive-2.0은 이 문제를 “새 비디오 모델 하나”보다 학습부터 추론까지 이어지는 long-video infrastructure로 다룬다.
논문과 프로젝트 페이지 기준으로 LongLive-2.0은 5B급 long video AR diffusion model을 공개하고, 여기에 Balanced sequence parallel training, NVFP4 training, W4A4 NVFP4 inference, NVFP4 KV cache, asynchronous streaming VAE decoding, multi-shot attention sink를 한 묶음으로 결합한다.
흥미로운 점은 릴리스 표면도 비교적 넓다는 것이다. arXiv/Hugging Face Papers에는 논문이 올라와 있고, NVlabs/LongLive GitHub 저장소에는 training·inference code와 NVFP4 관련 kernel 경로가 포함되어 있다.
Hugging Face에는 BF16 5B checkpoint, NVFP4 4-step/2-step checkpoint, toy dataset이 함께 공개되어 있다.
즉 LongLive-2.0은 논문 속 시스템 제안이면서 동시에 실제 배포 경로를 겨냥한 모델·코드·가중치 번들이다.
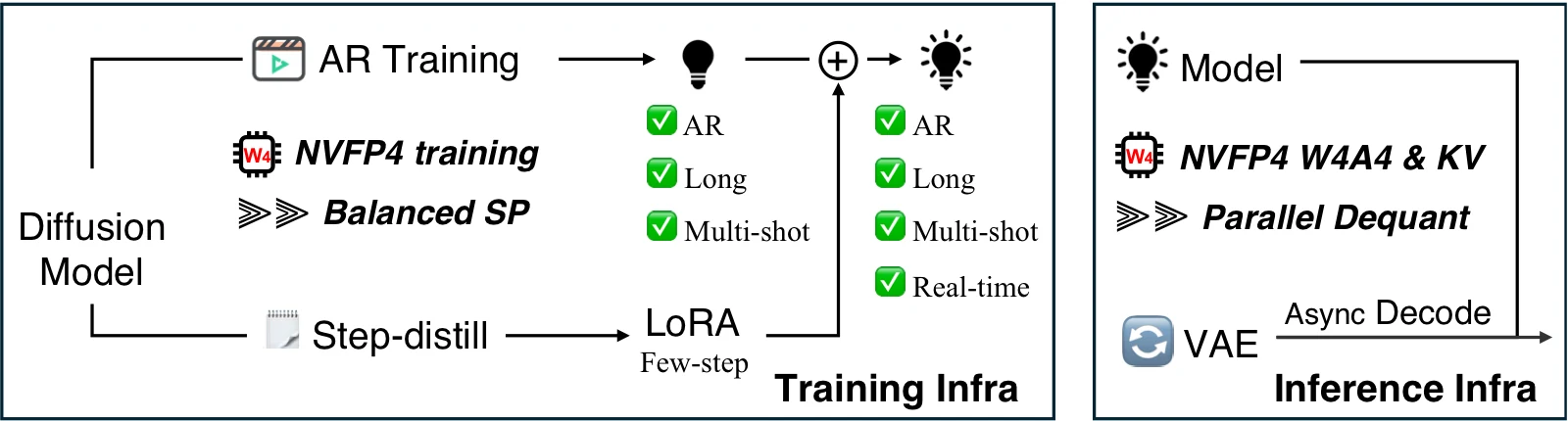
무엇을 해결하려는가
Long video generation의 첫 번째 병목은 학습이다.
긴 영상을 AR 방식으로 학습하려면 과거 clean latent와 현재 noisy target latent를 함께 처리해야 한다.
비디오 길이가 늘어날수록 attention과 GEMM 비용이 커질 뿐 아니라, VAE encoding과 loss-bearing token의 분산도 까다로워진다.
단순히 sequence parallelism을 붙이면 long context는 다룰 수 있지만, clean/history와 noisy/target stream이 GPU마다 불균형하게 나뉘면 loss 계산과 VAE 준비 단계에서 새 병목이 생긴다.
두 번째 병목은 추론이다.
실제 interactive video generation에서는 diffusion model의 raw FPS만 높아서는 충분하지 않다.
KV cache가 길어지고, VAE decoding이 denoising step 사이에서 대기 시간을 만들고, multi-shot prompt에서는 장면 전환마다 identity와 local consistency가 흔들릴 수 있다.
특히 Blackwell 세대의 NVFP4 같은 저정밀 경로를 제대로 활용하려면 post-training quantization만 붙이는 것보다 학습·증류·추론 경로를 같이 맞추는 편이 중요하다.
세 번째 병목은 기존 long-video pipeline의 복잡성이다.
Self-Forcing 계열 방법은 ODE initialization, distribution matching distillation(DMD), long tuning 같은 여러 단계를 거치는 경우가 많다.
LongLive-2.0은 고품질 long-video dataset과 infrastructure가 있으면 base bidirectional diffusion model을 곧바로 long, interactive, multi-shot AR model로 조정할 수 있다고 주장한다.
즉 핵심 메시지는 “더 많은 stage”가 아니라 “더 정렬된 시스템 경로”다.
핵심 아이디어 / 구조 / 동작 방식
LongLive-2.0의 학습 쪽 핵심은 Balanced SP다.
일반적인 sequence parallelism은 clean history token과 noisy target token을 단순히 긴 sequence로 보고 GPU에 나눈다.
하지만 teacher-forcing layout에서는 실제 loss-bearing target token이 특정 구간에 몰릴 수 있고, VAE encoding도 각 rank가 같은 준비 작업을 반복하기 쉽다.
Balanced SP는 clean stream과 noisy stream에서 같은 시간 chunk를 같은 rank가 맡도록 배치한다.
그 결과 attention mask, VAE encoding, loss computation이 temporal chunk ownership을 공유하고, GPU별 work imbalance를 줄인다.
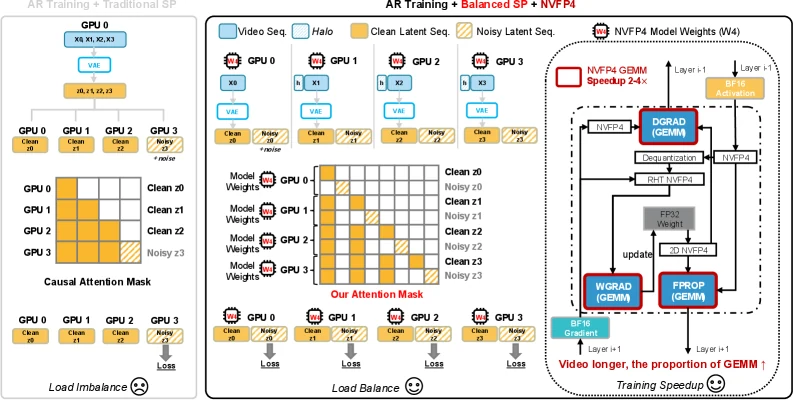
여기에 NVFP4 training이 붙는다.
논문은 video length가 길어질수록 DiT 안의 GEMM 비중이 커지고, NVFP4가 이 연산과 memory footprint를 동시에 줄이는 데 의미가 있다고 설명한다.
DMD 경로에서도 generator, real-score model, fake-score model을 단계적으로 NVFP4로 낮추고, standalone LoRA를 이용해 few-step generation capability를 주입한다.
중요한 점은 이 LoRA가 AR training이 끝나기를 기다리지 않고 별도로 학습될 수 있으며, 여러 AR model에 주입 가능한 형태로 설계된다는 것이다.
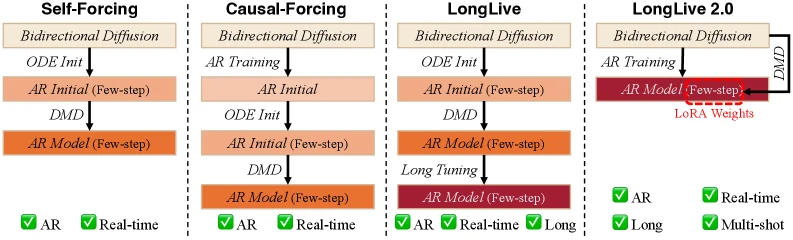
추론 쪽은 세 층으로 구성된다.
첫째, Blackwell GPU에서는 W4A4 NVFP4 inference를 사용한다.
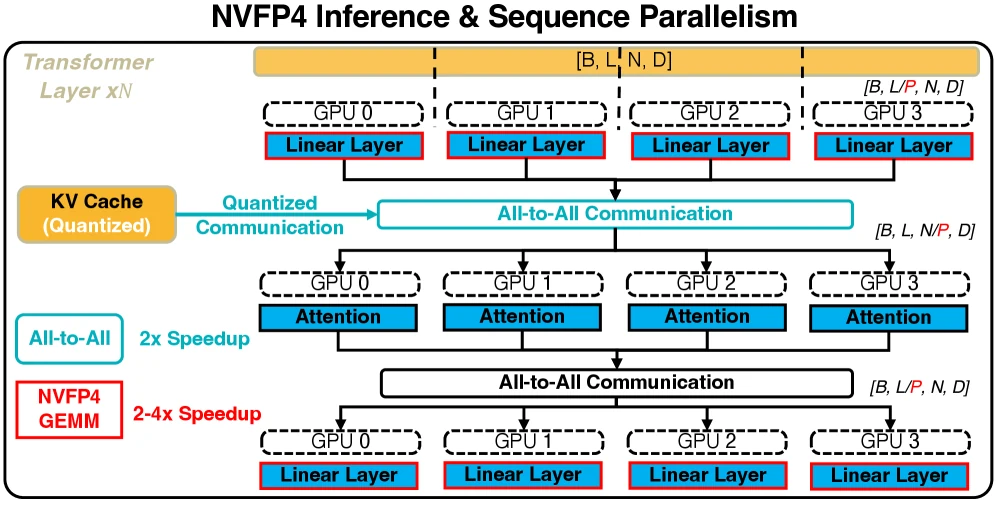
둘째, KV cache도 NVFP4로 저장해 긴 video context에서 memory를 줄이고, parallel dequantization kernel로 복원 비용을 낮춘다.
셋째, asynchronous streaming VAE decoding을 통해 DiT denoising과 VAE decoding 사이의 idle time을 줄인다.
H100처럼 Blackwell이 아닌 GPU에서는 sequence-parallel inference를 사용하고, quantized KV cache가 all-to-all communication overhead를 낮추는 역할을 한다.
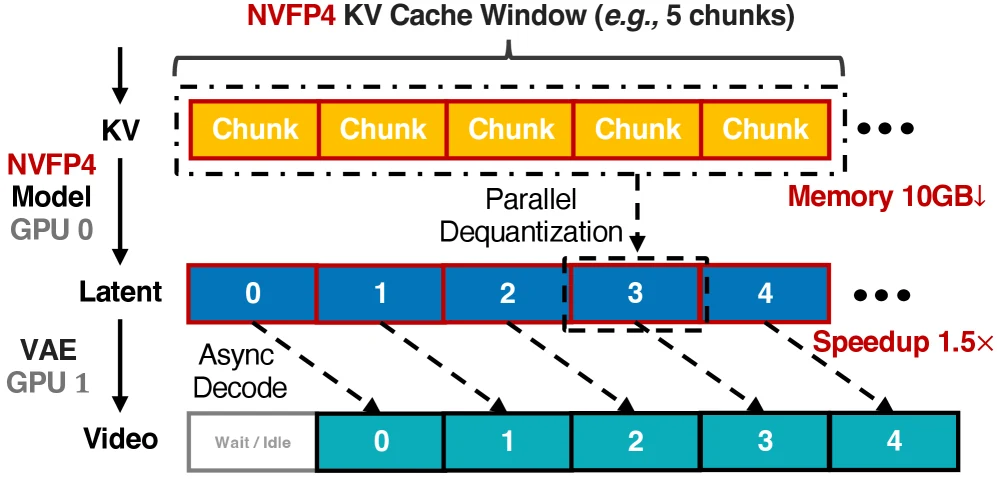
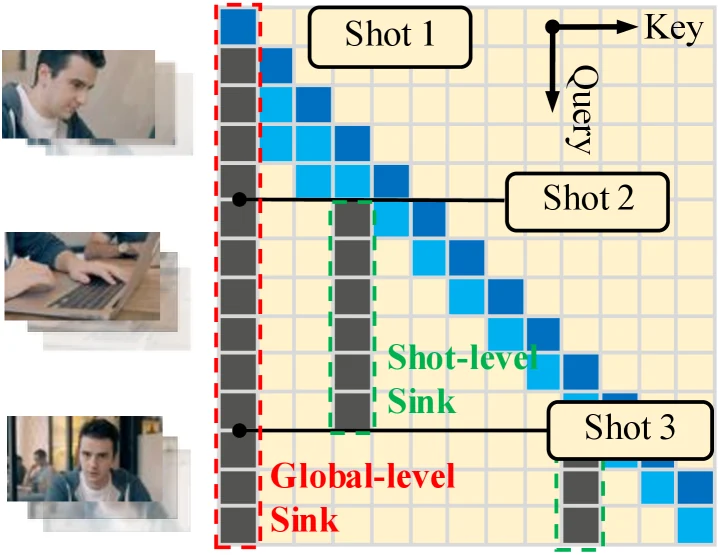
Multi-shot attention sink도 LongLive-2.0의 중요한 설계다.
긴 영상에서는 전체 identity를 보존하는 global-level sink와 장면별 local consistency를 보존하는 shot-level sink가 서로 다른 역할을 한다.
LongLive-2.0은 fixed global sink를 유지하면서, shot boundary마다 shot-level sink를 새로 묶어 scene-level appearance drift를 줄이는 구조를 쓴다.
이는 단순히 더 긴 KV cache를 들고 가는 것이 아니라, 긴 영상 안에서 어떤 기억은 전역으로, 어떤 기억은 장면별로 유지할지 나누는 정책에 가깝다.
| 구성 축 | 공개 자료에서 확인되는 내용 | 실무적 의미 |
|---|---|---|
| Balanced SP | clean/noisy temporal chunk를 같은 rank가 담당 | teacher-forcing layout과 SP 실행을 맞춰 학습 imbalance를 줄임 |
| NVFP4 training | long-video AR training과 DMD 경로에 저정밀 연산 적용 | 긴 sequence에서 커지는 GEMM·memory 비용을 낮춤 |
| Standalone LoRA DMD | AR model과 별도로 few-step LoRA를 학습해 주입 | 4-step/2-step 실시간 경로를 더 유연하게 구성 |
| W4A4 NVFP4 inference | Blackwell에서 model weight·activation을 NVFP4로 실행 | video diffusion의 inference throughput을 hardware path에 맞춤 |
| NVFP4 KV cache | 긴 history cache를 4-bit로 저장하고 병렬 복원 | long context memory와 SP communication overhead 완화 |
| Async VAE decoding | denoising과 VAE decode를 겹침 | diffusion FPS가 아니라 end-to-end latency를 줄이는 데 중요 |
| Multi-shot sink | global sink와 shot-level sink를 분리 | 긴 multi-shot video에서 identity와 장면별 coherence를 동시에 겨냥 |
공개된 근거에서 확인되는 점
학습 효율 표에서 가장 선명한 신호는 64초 길이의 AR training이다.
논문 Table 1 기준 plain BF16은 64초에서 OOM이고, BF16+SP는 64초 iteration time이 1372.9초다.
Balanced SP를 적용하면 1196.5초로 줄고, NVFP4 Balanced SP까지 적용하면 639.5초가 된다.
저자들은 이를 BF16+SP 대비 2.1배 speedup으로 보고한다.
16초와 32초에서도 NVFP4 Balanced SP는 각각 40.1초, 119.3초로 가장 빠르다.
| AR training 설정 | 16초 | 32초 | 64초 | 해석 |
|---|---|---|---|---|
| BF16 without SP | 75.3s | 202.7s | OOM | 짧은 길이에서는 가능하지만 long context에서 메모리 한계 |
| BF16 + SP | 52.2s | 162.7s | 1372.9s | long-video 학습을 가능하게 하지만 workload imbalance가 남음 |
| BF16 Balanced SP | 45.8s | 136.8s | 1196.5s | teacher-forcing chunk layout을 SP와 맞춰 개선 |
| NVFP4 Balanced SP | 40.1s | 119.3s | 639.5s | 64초에서 BF16+SP 대비 2.1배 speedup |
DMD training에서도 memory 절감이 분명하다.
Table 2는 generator, real-score, fake-score model을 모두 BF16으로 둘 때 peak per-GPU memory가 70.5GB라고 보고한다. generator를 NVFP4로 낮추면 63.3GB, generator에 NVFP4+LoRA를 쓰고 real-score를 NVFP4로 낮추면 57.2GB, 마지막으로 fake-score까지 NVFP4+LoRA로 구성하면 49.0GB다.
논문은 이 마지막 구성을 BF16 baseline 대비 0.69배 memory ratio로 정리한다.
추론 쪽은 end-to-end latency를 보는 것이 중요하다.
Table 3 기준 BF16 4-step path는 FPS 24.8, 64초 E2E generation latency 112.9초, total memory 36.4GB다.
NVFP4를 적용하면 FPS는 32.0으로 오르고 memory는 29.7GB로 줄지만, KV cache를 NVFP4로 저장하면 memory가 19.4GB까지 내려간다.
여기에 async decoding을 붙이면 64초 E2E latency가 57.6초로 줄고, 2-step path에서는 FPS 45.7, 64초 latency 36.3초까지 내려간다.
| 추론 설정 | FPS | 16초 E2E | 32초 E2E | 64초 E2E | Total memory |
|---|---|---|---|---|---|
| BF16 4-step | 24.8 | 26.6s | 53.2s | 112.9s | 36.4GB |
| NVFP4 4-step | 32.0 | 22.9s | 46.6s | 96.0s | 29.7GB |
| NVFP4 + KV cache | 29.7 | 23.8s | 48.9s | 99.5s | 19.4GB |
| NVFP4 + KV cache + async decoding | 29.7 | 15.9s | 29.1s | 57.6s | 19.4GB |
| NVFP4 2-step | 45.7 | 11.2s | 19.2s | 36.3s | 19.4GB |
품질은 속도와 함께 읽어야 한다.
GitHub README의 model table과 논문 Table 4 기준 LongLive-2.0 BF16 4-step은 5B, 1280×720, FPS 24.8, VBench total 85.06이다.
NVFP4 4-step은 FPS 29.7, VBench total 84.51로 약간 낮고, NVFP4 2-step은 FPS 45.7, VBench total 83.14다.
즉 LongLive-2.0의 메시지는 “저정밀이 무조건 품질을 그대로 보존한다”가 아니라, 실시간성에 가까운 throughput으로 갈수록 품질 trade-off를 명시적으로 관리한다에 가깝다.
VBench-Long 60초 결과도 비슷하다.
LongLive-2.0 BF16은 Avg.
Rank 3.67, subject consistency 97.48, background consistency 97.00, dynamic degree 60.62로 표시된다.
NVFP4는 Avg.
Rank 3.83, subject consistency 97.62, background consistency 96.97로 identity·background 쪽은 매우 높지만 dynamic degree는 45.88로 낮아진다.
따라서 NVFP4 path는 장기 일관성을 꽤 유지하면서 throughput을 끌어올리지만, 장면의 움직임 다양성까지 항상 같은 수준으로 유지한다고 보기는 어렵다.
공개 패키징도 확인할 만하다.
GitHub API 기준 NVlabs/LongLive는 Apache-2.0 라이선스 저장소이고, 현재 main branch에는 training/inference script, configs/nvfp4, fouroversix, KV dequantization kernel, merged NVFP4 checkpoint helper 등이 포함되어 있다.
다만 inspection 시점에 GitHub releases와 tags는 비어 있었다.
이는 코드가 공개되어 있더라도 stable release artifact라기보다는 빠르게 정리 중인 연구·시스템 repo로 보는 편이 안전하다는 뜻이다.
Hugging Face 쪽은 모델과 라이선스 경계를 분리해서 봐야 한다.
API 기준 Efficient-Large-Model/LongLive-2.0-5B는 model_bf16.pt를 포함하고, NVFP4 4-step/2-step repo는 각각 model_4o6.pt, model_te.pt를 포함한다.
세 모델 repo는 text-to-video, long-video, NVFP4 같은 tag를 달고 있고 gated는 아니지만, license tag는 other이며 card data는 NVIDIA Open Model License를 가리킨다.
즉 코드 repo의 Apache-2.0과 모델 가중치의 NVIDIA Open Model License는 별개의 조건으로 확인해야 한다.
실무 관점에서의 해석
LongLive-2.0의 가장 중요한 의미는 video generation이 점점 모델 아키텍처 단독 경쟁에서 systems co-design 경쟁으로 이동하고 있다는 점이다.
몇 초짜리 sample을 더 예쁘게 만드는 것과, 60초 multi-shot video를 interactive latency에 가깝게 만드는 것은 다른 문제다.
후자는 attention layout, low-precision training, KV-cache storage, VAE scheduling, LoRA distillation, GPU architecture까지 함께 봐야 한다.
LongLive-2.0은 이 묶음을 한 논문과 공개 코드·가중치로 정리한 사례다.
특히 Balanced SP는 long-video training에서 꽤 현실적인 교훈을 준다. parallelism은 단순히 sequence를 나누는 문제가 아니라, 데이터 layout과 loss layout, VAE preprocessing layout까지 맞아야 한다.
GPU 수를 늘려도 각 rank가 받는 token 의미가 다르면 실제 병목은 다른 곳에서 생긴다.
LongLive-2.0의 chunk-aligned layout은 “parallelism strategy는 모델 수식이 아니라 입력 구성과 함께 설계해야 한다”는 메시지를 준다.
Inference 쪽에서도 배울 점이 많다.
많은 모델 발표가 FPS만 내세우지만, LongLive-2.0은 KV cache memory와 VAE decoding idle time을 별도 병목으로 분리한다.
이 접근은 제품 배포에 더 가깝다.
사용자는 diffusion model이 초당 몇 프레임을 계산하는지보다, prompt를 넣은 뒤 실제 16초·32초·64초 결과물이 언제 나오는지를 체감하기 때문이다.
Table 3에서 async decoding이 64초 E2E latency를 크게 낮추는 것도 바로 이 관점에서 중요하다.
다만 이 릴리스를 곧바로 범용 video generation 해결책으로 과대평가하면 안 된다.
NVFP4 path는 Blackwell 계열 GPU와 특수 kernel, FourOverSix 또는 TransformerEngine backend, FlashAttention, KV dequantization extension 같은 실행 조건에 강하게 의존한다.
H100에서는 sequence-parallel inference로 일부 속도 경로를 맞추지만, 최종 숫자는 hardware와 backend configuration에 따라 달라질 수밖에 없다.
또한 NVFP4 2-step path는 매우 빠르지만 VBench total과 dynamic degree가 내려가는 trade-off도 함께 보인다.
라이선스와 release maturity도 실무적으로 중요하다.
코드 저장소는 Apache-2.0이지만 모델 가중치는 NVIDIA Open Model License로 별도 관리된다.
GitHub releases/tags가 아직 비어 있고, 모델 카드의 환경·다운로드 지침도 NVFP4 backend별로 꽤 복잡하다.
따라서 연구 재현이나 내부 실험에는 매력적이지만, 바로 production pipeline에 넣으려는 팀은 사용 조건, checkpoint provenance, backend별 설정, 실제 target GPU에서의 latency를 다시 검증해야 한다.
그럼에도 LongLive-2.0은 긴 비디오 생성 릴리스의 기준선을 잘 보여준다.
앞으로 중요한 질문은 “얼마나 긴 영상을 만들 수 있는가”만이 아니라, “그 길이를 어떤 training layout으로 감당하는가, 어떤 precision으로 학습과 추론을 맞추는가, KV cache와 decoding을 어떻게 scheduling하는가, 그리고 그 결과를 실제 공개 가중치와 코드로 어떻게 배포하는가”가 될 가능성이 크다.
LongLive-2.0은 이 질문들을 하나의 시스템으로 묶었다는 점에서, long video generation을 연구 데모에서 운영 가능한 infrastructure 문제로 끌어내리는 중요한 신호로 읽힌다.