에이전트 시스템을 오래 쓰다 보면 “모델이 똑똑한가”만큼이나 “반복 업무 절차가 얼마나 잘 보존되는가”가 중요해진다.
도구를 언제 부를지, 실패 로그를 어떻게 읽을지, 출력 형식을 어떻게 맞출지, 어떤 검증을 마지막에 수행할지 같은 절차 지식은 매번 프롬프트로 다시 쓰기에는 길고, 모델 가중치로 흡수하기에는 비용과 접근 제약이 크다.
SkillOpt: Executive Strategy for Self-Evolving Agent Skills는 이 지점을 정면으로 다룬다.
논문의 핵심 주장은 간단하다.
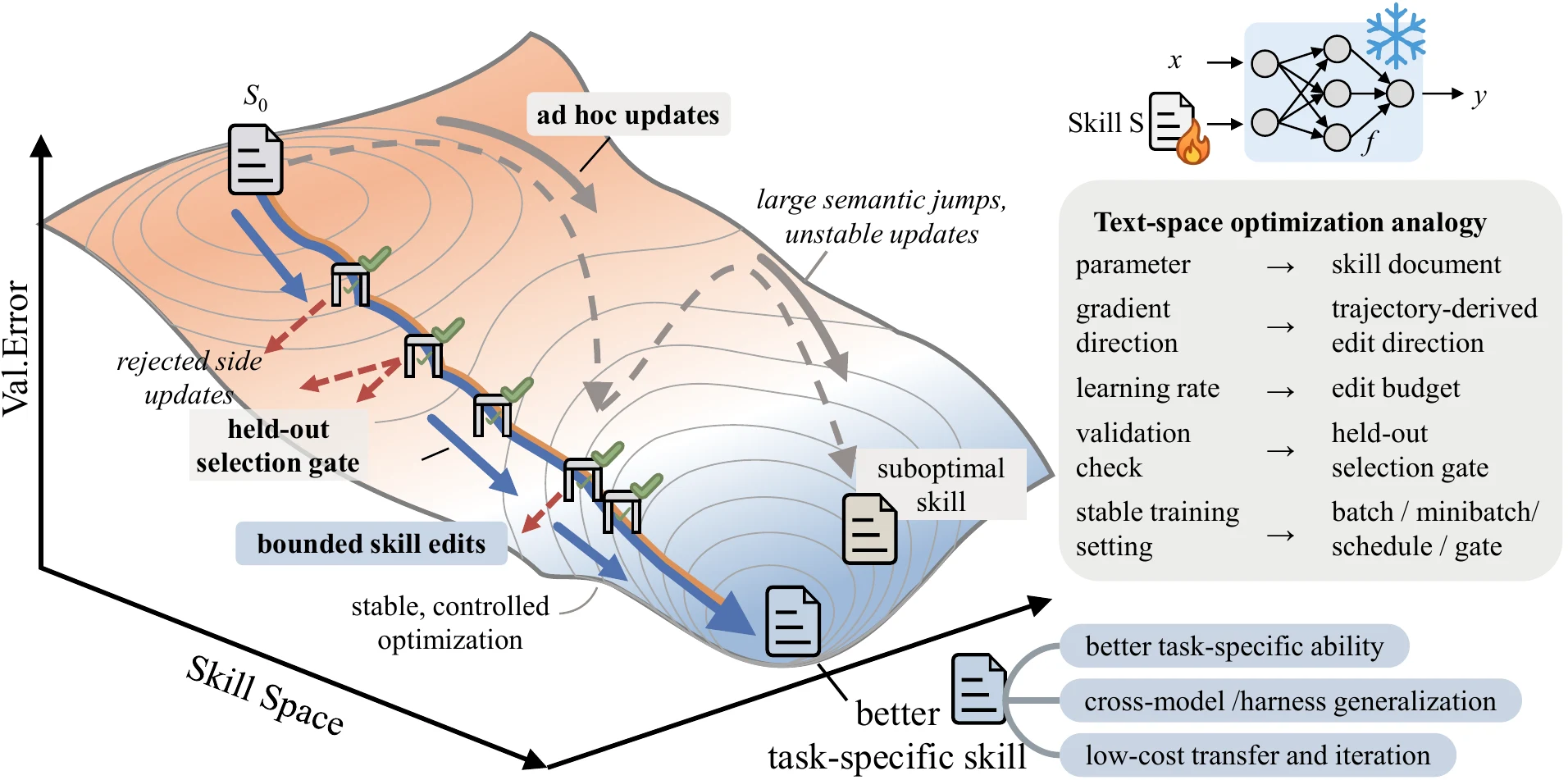
에이전트에게 주입되는 자연어 skill 문서를 수동 프롬프트나 부가 메모가 아니라 학습 가능한 외부 상태로 보자는 것이다.
모델 가중치는 고정하고, 별도의 optimizer model이 실행 궤적과 점수 피드백을 읽어 skill 문서를 조금씩 고친다.
그리고 새 skill은 held-out validation split에서 실제로 좋아질 때만 채택된다.
이 접근은 prompt optimization과 비슷해 보이지만 초점이 조금 다르다.
SkillOpt가 최적화하려는 대상은 단발성 프롬프트가 아니라, 여러 작업과 harness에서 재사용되는 best_skill.md라는 절차 문서다.
즉 “agent가 일을 잘하게 만드는 운영 지식”을 deep learning의 training loop처럼 다루려는 시도다.
무엇을 해결하려는가
현재 agent skill은 보통 세 가지 방식으로 만들어진다.
사람이 직접 쓰거나, LLM에게 한 번에 생성시키거나, 실패 사례를 보고 느슨하게 자기수정한다.
세 방식 모두 빠르게 시작하기에는 좋지만, “정말 나아졌는가”를 반복 가능하게 보장하기 어렵다.
특히 agent가 파일, 도구, 브라우저, verifier, multi-step harness를 다루기 시작하면 skill 문서 하나가 작은 운영 매뉴얼이 된다.
여기에 무제한 self-edit을 허용하면 좋은 절차가 보존되기보다 드리프트가 생길 수 있다.
SkillOpt는 이 문제를 “skill 작성”이 아니라 “skill 학습”으로 재정의한다.
주어진 target model과 harness는 그대로 둔다.
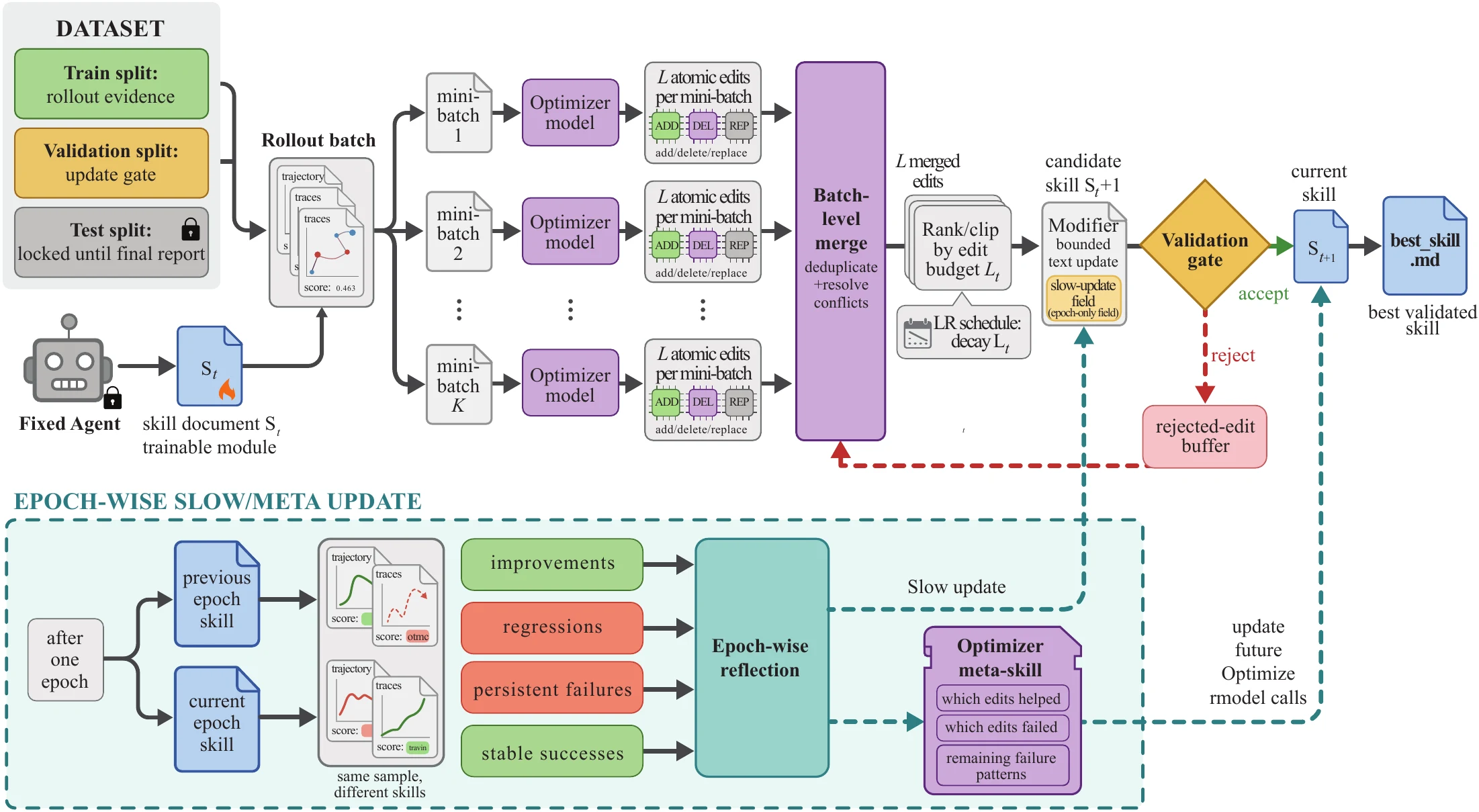
대신 현재 skill로 여러 작업을 실행해 rollout trajectory와 점수를 모으고, optimizer model이 성공/실패 미니배치를 분석해 add/delete/replace 형태의 원자적 편집을 제안한다.
이 편집들은 learning rate처럼 정해진 edit budget 안에서 merge·rank·clip되고, candidate skill은 validation score가 엄격히 개선될 때만 다음 상태로 넘어간다.
이 설계가 중요한 이유는 closed frontier model에도 적용 가능하다는 점이다.
모델 가중치에 접근하지 않아도, agent context에 주입되는 절차 문서를 개선할 수 있다.
반대로 open model을 fine-tune하기 어려운 상황에서도, 배포 시점에는 추가 모델 호출 없이 compact skill artifact만 붙이면 된다.
논문은 이 배포 산출물을 대략 300~2,000 token 규모의 best_skill.md로 설명한다.
핵심 아이디어 / 구조 / 동작 방식
SkillOpt의 loop는 deep learning training을 text space로 옮긴 형태에 가깝다.
논문은 model parameter를 skill document에, forward pass를 rollout에, gradient를 trajectory 기반 reflection에, learning rate를 최대 text edit 수에, validation set을 held-out selection split에 대응시킨다.
이 비유가 단순한 장식은 아니다.
실제 알고리즘도 “작은 step”, “검증”, “rejected update 기억”, “epoch 단위 slow/meta update”를 안정화 장치로 쓴다.
동작 흐름은 다음과 같이 정리할 수 있다.
| 단계 | SkillOpt에서 하는 일 | 딥러닝 비유 |
|---|---|---|
| Rollout | target model이 현재 skill로 train task를 실행하고 trajectory와 score를 남김 | forward pass |
| Reflection | optimizer model이 성공/실패 미니배치를 나눠 반복 오류와 유효 절차를 분석 | gradient 추정 |
| Edit proposal | add/delete/replace 형태의 skill patch를 제안 | parameter update 후보 |
| Edit budget | epoch별 L_t 안에서 edit을 merge, rank, clip |
learning rate / clipping |
| Validation gate | candidate skill을 selection split에서 평가하고 개선될 때만 수락 | validation-based model selection |
| Rejected buffer | 거절된 edit을 negative feedback으로 보관 | 실패한 update의 기억 |
| Slow/meta update | epoch 경계에서 장기 패턴을 optimizer-side memory로 반영 | momentum / optimizer state |
여기서 눈여겨볼 지점은 SkillOpt가 거대한 skill library를 바로 키우지 않는다는 점이다.
논문의 기본 설정은 한 target domain에 대해 하나의 portable skill을 최적화하는 것이다. skill registry나 marketplace보다 한 단계 아래, “하나의 skill 문서를 얼마나 통제 가능하게 개선할 수 있는가”가 연구 질문이다.
또한 optimizer model과 target model이 분리된다. target model은 실제 작업을 수행하는 frozen model이고, optimizer model은 offline training 중에만 trajectory를 읽고 skill edit을 제안한다.
더 강한 optimizer를 쓰더라도 배포 시점 비용이 늘지 않는다는 점은 이 구조의 장점이다.
대신 training phase에서는 rollout computation과 optimizer call 비용이 발생한다.
공개된 근거에서 확인되는 점
arXiv v1은 2026년 5월 22일 제출됐고, 27쪽, 4개 figure, 6개 table로 구성되어 있다.
저자는 Microsoft, Shanghai Jiao Tong University, Tongji University, Fudan University 소속 연구자들이다. arXiv HTML에는 Code: https://aka.ms/SkillOpt가 표시되며, 이 링크는 공식 project page와 microsoft/SkillOpt GitHub 저장소로 이어진다.
논문이 제시하는 실험 범위는 꽤 넓다.
SearchQA, SpreadsheetBench, OfficeQA, DocVQA, LiveMath, ALFWorld 등 6개 benchmark, 7개 target model, direct chat·Codex·Claude Code의 3개 execution harness를 포함한다.
핵심 headline은 SkillOpt가 평가된 52개 model×benchmark×harness cell에서 모두 best 또는 tied-best였다는 것이다.
| 확인 항목 | 논문/프로젝트 페이지 기준 내용 | 해석 |
|---|---|---|
| 최적화 대상 | 자연어 skill document, 최종 산출물 best_skill.md |
모델 가중치가 아니라 agent procedure를 학습 상태로 둠 |
| 업데이트 방식 | add/delete/replace bounded edit + textual learning-rate budget | 프롬프트 전체 재작성보다 drift를 줄이려는 설계 |
| 검증 방식 | held-out selection split에서 좋아질 때만 candidate 수락 | self-revision의 무분별한 퇴화를 막는 gate |
| 평가 범위 | 6 benchmarks, 7 target models, 3 harnesses, 52 cells | 한 harness나 한 모델에만 맞춘 튜닝이라는 설명을 피하려는 실험 구성 |
| 배포 비용 | optimized skill 사용 시 추가 inference-time model call 없음 | offline optimization 비용을 재사용 가능한 문서에 amortize |
가장 눈에 띄는 숫자는 GPT-5.5 설정이다.
논문 초록은 no-skill baseline 대비 SkillOpt가 direct chat에서 평균 +23.5점, Codex agentic loop에서 +24.8점, Claude Code에서 +19.1점을 올렸다고 보고한다.
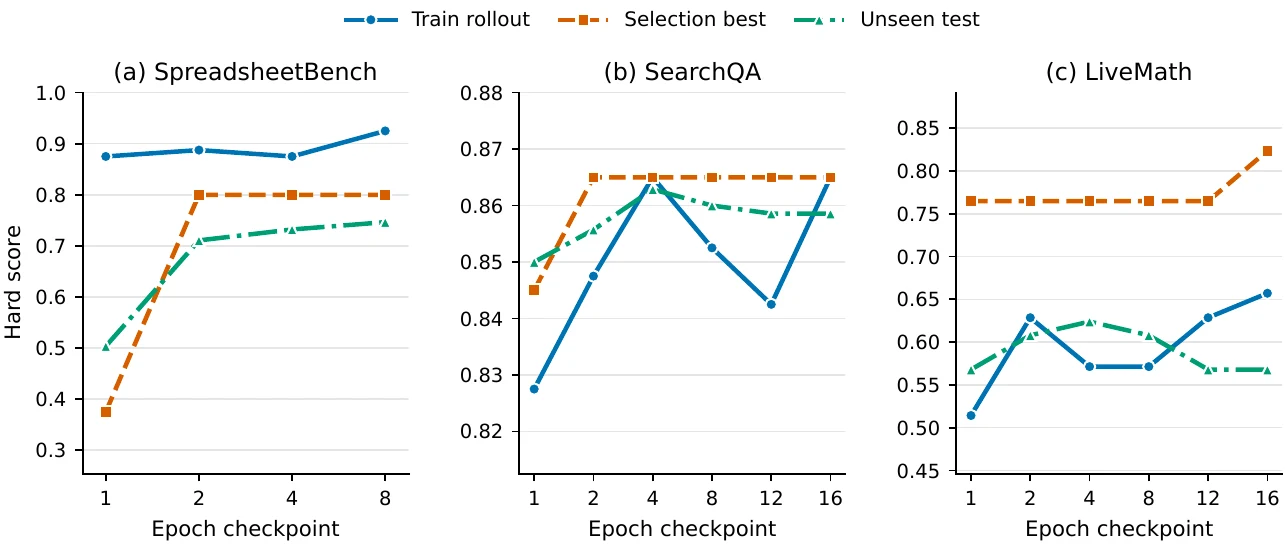
Table 1의 개별 row를 보면 procedural benchmark에서 이득이 특히 크다.
예를 들어 GPT-5.5 direct chat에서 SpreadsheetBench는 +38.9점, OfficeQA는 +39.0점, LiveMath는 +29.3점으로 오른다.
Codex harness에서도 SpreadsheetBench는 +57.5점, LiveMath는 +43.2점으로 크게 움직인다.
Ablation도 이 논문의 메시지를 뒷받침한다.
기본 설정에서 SearchQA, SpreadsheetBench, LiveMath 점수는 각각 87.1, 77.5, 61.3이다. learning-rate control을 제거하면 84.6, 75.7, 57.3으로 내려가고, rejected buffer를 제거하면 85.5, 72.9, 58.9로 내려간다. meta skill과 slow update를 함께 빼면 SpreadsheetBench가 55.0까지 떨어진다.
즉 단순히 LLM에게 “skill을 더 잘 고쳐봐”라고 맡기는 것이 아니라, 작은 text edit, 실패 update 기억, epoch-level memory가 실제 안정화 장치로 작동한다는 주장이다.
Skill artifact의 크기와 edit economy도 실무적으로 흥미롭다.
Table 6 기준 final best_skill.md는 benchmark별로 3791,995 token 정도이고, accepted bounded update 수는 14개다.
SpreadsheetBench는 224 token initial skill에서 1,995 token final skill로 커졌고 4개 edit이 수락됐다.
LiveMath는 154 token에서 379 token으로 늘었고 accepted edit은 1개였다.
즉 SkillOpt의 결과물은 거대한 knowledge base가 아니라, 해당 domain에서 반복적으로 유효했던 절차를 압축한 짧은 운영 문서에 가깝다.
공식 GitHub 저장소 microsoft/SkillOpt도 공개되어 있다.
조회 시점 GitHub API 기준 저장소는 2026년 5월 8일 생성, 5월 25일 push, MIT license metadata, Python 3.10+ requirement, stars 81, forks 3, open issues 1개로 확인된다. root에는 configs/, scripts/, skillopt/, skillopt_webui/, docs/, skillopt-assets/가 있고, README는 SearchQA, ALFWorld, DocVQA, LiveMathematicianBench, SpreadsheetBench, OfficeQA config를 제시한다.
단, releases/latest는 404이고 git ls-remote --tags 결과 tag도 비어 있어, 현재는 versioned package라기보다 초기 연구 코드와 문서화된 실험 framework에 가깝다.
README도 benchmark datasets는 저장소에 포함되지 않으며 split directory를 직접 준비해야 한다고 명시한다.
실무 관점에서의 해석
SkillOpt의 가장 큰 의미는 “agent skill도 학습 pipeline의 대상이 될 수 있다”는 점을 꽤 구체적인 형태로 보여 준다는 데 있다.
지금까지 skill은 사람의 운영 노하우를 markdown으로 적어 두는 방식에 가까웠다.
하지만 실제 agent 운영에서는 어떤 규칙을 넣어야 하는지, 어떤 규칙은 오히려 방해되는지, 실패 사례를 skill에 남겨야 하는지, 아니면 버려야 하는지가 계속 문제 된다.
SkillOpt는 이 질문에 대해 validation-gated edit loop라는 답을 제시한다.
이 관점은 개인용 coding agent나 연구 agent에도 바로 연결된다.
예를 들어 특정 repo에서 테스트를 어떻게 돌리고, 어떤 warning은 무시해도 되고, 어떤 파일은 건드리면 안 되며, 실패 후 어떤 순서로 로그를 봐야 하는지 같은 지식은 매번 사람이 말해 주기보다 skill에 축적되는 편이 낫다.
다만 아무 실행 로그나 skill에 쓰면 agent가 잘못된 습관까지 학습할 수 있다.
SkillOpt식으로 보면 중요한 것은 “기억” 자체가 아니라, 검증된 업데이트만 기억하는 절차다.
조직 환경에서는 더 큰 질문이 생긴다.
최적화된 skill이 정말 domain generalization을 하는지, 특정 benchmark split에만 맞춘 shortcut은 아닌지, 다른 harness나 모델 버전으로 옮겼을 때 negative transfer가 생기지 않는지 계속 확인해야 한다.
논문은 cross-model, cross-harness, cross-benchmark transfer 실험에서 모두 no-skill baseline보다 positive transfer였다고 보고하지만, 동시에 limitations에서 open-ended domain은 reliable feedback signal이 더 어렵다고 인정한다.
따라서 실무 적용의 좋은 출발점은 자동 채점이 가능한 좁은 domain이다. spreadsheet task, document QA, repo-local build/test workflow, 정해진 형식의 report generation처럼 success metric이나 verifier가 비교적 명확한 작업은 SkillOpt류 접근에 잘 맞는다.
반면 전략 문서 작성, 디자인 리뷰, 제품 의사결정처럼 성공 기준이 다차원적이고 주관적인 작업은 human review나 model-based evaluator를 gate에 넣어야 한다.
또 하나의 한계는 SkillOpt가 기본적으로 하나의 portable skill을 최적화한다는 점이다.
매우 이질적인 업무를 하나의 skill에 모두 넣으면 skill 문서가 길어지고 충돌하는 규칙이 생길 수 있다.
장기적으로는 skill library, router, attribution, registry governance가 필요해질 가능성이 크다.
그런 점에서 SkillOpt는 최종 skill ecosystem이라기보다, 그 ecosystem 안에서 개별 skill을 안전하게 개선하기 위한 optimizer primitive로 보는 편이 맞다.
결국 이 논문이 던지는 질문은 단순하다.
에이전트가 경험을 쌓는다면, 그 경험은 어디에 저장되어야 하고 어떤 검증을 거쳐 다음 실행에 영향을 주어야 하는가.
SkillOpt의 답은 “모델 가중치가 아니라 검증된 skill 문서”다.
모든 문제를 해결하는 답은 아니지만, agent memory와 self-improvement를 엔지니어링 가능한 학습 루프로 끌어내리는 데 꽤 좋은 출발점이다.