복잡한 수학·코딩·과학 추론에서 self-consistency는 여전히 강력한 기본기다.
같은 문제를 여러 번 풀게 하고, 서로 다른 reasoning trace의 최종 답을 다수결로 모으면 단일 샘플보다 안정적인 답을 얻을 수 있다.
문제는 이 방법이 매우 비싸다는 데 있다.
512개의 trace를 생성하면 대체로 계산량도 512배 가까이 늘고, 그중 상당수는 처음부터 틀린 방향으로 흘러간 저품질 샘플일 수 있다.
Meta AI와 UCSD 연구진의 Deep Think with Confidence(DeepConf) 는 이 병목을 모델 내부 신호로 다루려는 접근이다.
핵심은 LLM을 완전한 블랙박스로 보지 않고, 토큰 생성 시점의 log probability 분포에서 confidence를 계산해 “이 reasoning trace를 끝까지 믿고 가져갈 만한가”를 판단하는 것이다.
단순히 여러 답을 많이 뽑는 것이 아니라, 생성 과정 중 모델이 불안정해지는 구간을 포착해 투표 가중치와 조기 종료 정책으로 연결한다.
흥미로운 점은 이 방법이 별도 학습 없이 test-time policy로 작동한다는 점이다.
논문은 AIME 2024/2025, HMMT 2025, BRUMO25, GPQA-Diamond와 DeepSeek-8B, Qwen3-8B/32B, GPT-OSS-20B/120B 계열에서 평가했고, 프로젝트 페이지와 GitHub 저장소는 vLLM 기반 병렬 추론 프레임워크와 confidence 기반 early stopping 예시를 함께 공개한다.
다만 vLLM upstream PR은 작성 시점 기준 closed / unmerged 상태였으므로, “서빙 프레임워크에 바로 들어간 표준 기능”이라기보다 “vLLM 위에 얹어 실험 가능한 연구 구현”에 가깝게 읽는 편이 안전하다.
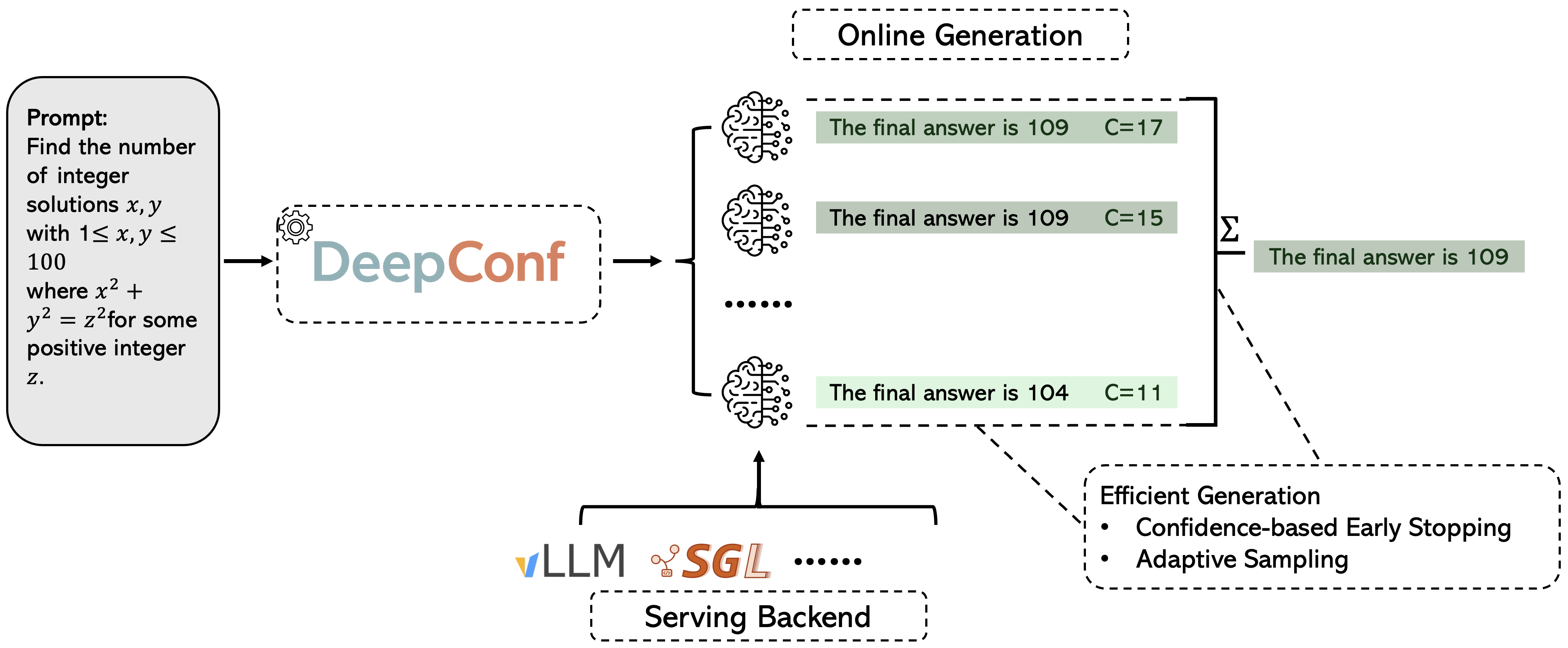
DeepConf 공식 저장소의 프레임워크 그림.
여러 reasoning trace를 생성하되 각 trace의 confidence를 함께 계산하고, confidence-based early stopping과 adaptive sampling으로 최종 답을 고른다.
무엇을 해결하려는가
Self-consistency의 약점은 투표 방식 자체에 있다.
완성도 높은 풀이와 중간에 무너진 풀이가 모두 동일한 한 표로 처리된다.
다수결은 샘플 수가 많을수록 안정될 수 있지만, 저품질 trace가 충분히 많아지면 오히려 틀린 답 쪽으로 투표가 쏠리거나, 정확도 개선 대비 토큰 비용이 급격히 커진다.
논문은 Qwen3-8B로 AIME 2025에서 pass@1 68%를 majority voting 82%까지 끌어올리려면 문제당 511개의 추가 reasoning trace와 약 1억 개의 추가 토큰이 필요하다고 설명한다.
기존의 confidence 활용법은 보통 trace 전체의 평균 confidence를 보는 방식이었다.
하지만 긴 chain-of-thought에서는 전체 평균이 치명적인 한 구간의 오류를 가릴 수 있다.
대부분의 토큰은 자신 있게 생성했더라도, 어떤 중간 단계에서 “wait”, “however”, “think again” 같은 불안정한 전환이 발생하면 최종 답은 틀릴 수 있다.
DeepConf가 겨냥하는 지점은 바로 이 “가장 약한 고리”다.
실무적으로 보면 이 문제는 inference-time compute를 많이 쓰는 모든 제품형 추론 시스템에 걸린다.
수학 문제 benchmark뿐 아니라, 코드 생성 후보를 여러 개 뽑는 agent, 문서 분석에서 여러 hypothesis를 비교하는 RAG pipeline, 검색·계획·검증을 반복하는 orchestration 시스템 모두 “많이 생각하면 좋아지지만, 어디까지 생각할 것인가”라는 비용 경계를 가져야 한다.
DeepConf는 그 경계를 logprob 기반 confidence policy로 잡으려 한다.
핵심 아이디어 / 구조 / 동작 방식
DeepConf의 기본 단위는 토큰 confidence다.
논문은 각 위치에서 상위 k개 후보 토큰의 log probability 평균을 이용해 token confidence를 계산한다.
확률 분포가 특정 후보에 집중되어 있으면 모델이 다음 토큰을 비교적 확신하고 있다고 보고, 여러 후보로 퍼져 있으면 불확실하다고 본다.
이 값 자체는 새로운 supervision이 아니라, 이미 generation 과정에서 얻을 수 있는 내부 확률 신호다.
문제는 토큰 하나의 confidence가 곧 trace 품질을 의미하지 않는다는 점이다.
그래서 DeepConf는 sliding window로 인접 토큰들을 묶어 group confidence를 만든다.
예를 들어 1,024개 또는 2,048개 토큰 윈도우를 이동시키며 구간별 평균 confidence를 계산하면, reasoning 과정 중 어느 구간이 안정적이고 어느 구간이 흔들렸는지 볼 수 있다.
여기서 논문이 특히 강조하는 지표가 Lowest Group Confidence다.
전체 trace의 평균이 아니라, 모든 구간 중 confidence가 가장 낮았던 구간을 trace의 품질 신호로 삼는다.
이는 “논리 사슬은 가장 약한 고리에서 끊어진다”는 직관에 가깝다.
추가로 bottom 10% group confidence, tail confidence, average trace confidence도 비교하지만, 온라인 조기 종료에는 lowest group confidence가 자연스럽게 쓰인다.
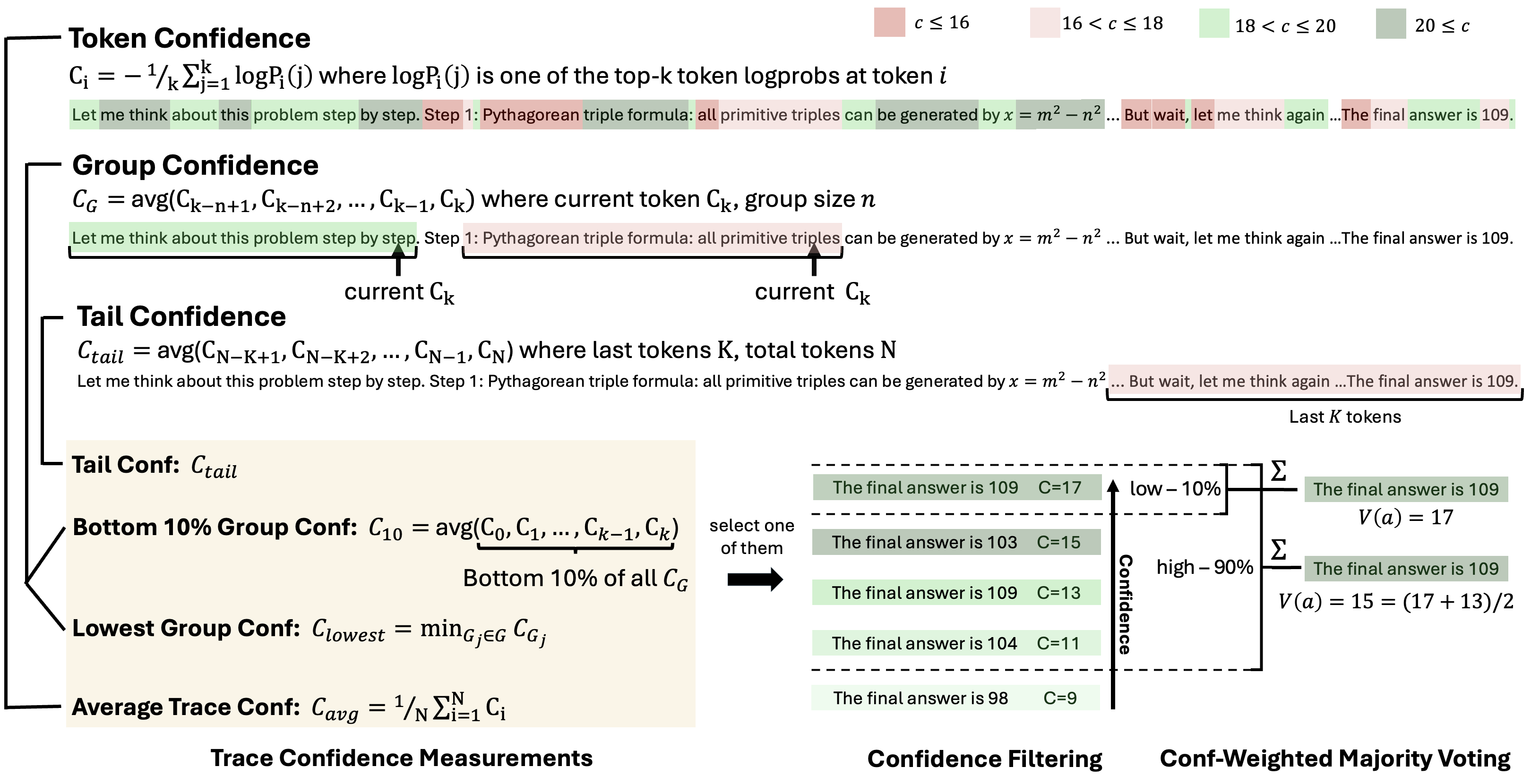
공식 프로젝트 페이지의 confidence 측정 도식.
토큰 단위 confidence를 구간 단위로 묶고, 하위 confidence 구간이나 tail confidence를 이용해 trace를 필터링하거나 가중 투표한다.
DeepConf는 크게 두 모드로 동작한다.
| 모드 | 동작 방식 | 장점 | 한계 |
|---|---|---|---|
| Offline DeepConf | 모든 trace를 끝까지 생성한 뒤 confidence로 가중 투표하거나 상위 trace만 필터링 | 기존 self-consistency 결과를 후처리해 정확도를 높이기 쉬움 | 토큰 생성 비용 자체는 이미 발생함 |
| Online DeepConf | warmup trace로 threshold를 정하고, 새 trace 생성 중 confidence가 threshold 아래로 떨어지면 중단 | 저품질 trace에 쓰는 토큰을 줄일 수 있음 | threshold 추정, logprob 수집, serving stack 수정이 필요함 |
| DeepConf-low | confidence 상위 10% trace만 남기는 공격적 필터링 | 정확도 개선과 토큰 절감이 클 수 있음 | 모델이 틀린 답에 과신하면 성능 하락 가능 |
| DeepConf-high | confidence 상위 90%를 남기는 보수적 필터링 | 정확도 보존에 유리하고 운영 리스크가 낮음 | 토큰 절감 폭은 low보다 작음 |
온라인 방식은 먼저 문제별로 N_init=16개의 완전한 warmup trace를 생성해 threshold를 잡는다.
이후 새 trace를 생성할 때 sliding window confidence가 threshold 아래로 내려가면 해당 trace를 조기에 중단한다.
완성된 trace는 confidence-weighted majority voting에 들어가고, 답 후보의 consensus가 충분히 높아지면 전체 generation도 멈춘다.
즉 “틀릴 가능성이 높은 풀이를 끝까지 쓰지 않고, 이미 합의가 충분하면 더 뽑지 않는다”는 두 종류의 낭비 제거가 함께 들어간다.
공개된 근거에서 확인되는 점
논문에서 가장 눈에 띄는 수치는 AIME 2025 결과다.
GPT-OSS-120B 기준 pass@1은 91.8%, 512개 trace의 일반 majority voting은 97.0%인데, offline DeepConf에서 tail confidence top 10% 필터링을 적용하면 99.9%까지 올라간다.
프로젝트 페이지도 이 결과를 전면에 배치하며 “최대 99.9% accuracy, 최대 84.7% token reduction”을 요약한다.
온라인 평가에서는 토큰 절감이 핵심이다.
GPT-OSS-120B / AIME25 기준 Cons@512는 3.23×10^8 토큰과 97.1% 정확도를 보고하는 반면, DeepConf-low는 0.49×10^8 토큰으로 줄이면서 97.9% 정확도를 기록한다.
이는 논문 표기상 -84.7% 토큰 감소다.
DeepSeek-8B도 AIME25에서 Cons@512 4.01×10^8 토큰, 82.3%에서 DeepConf-low 1.24×10^8 토큰, 86.4%로 이동한다.
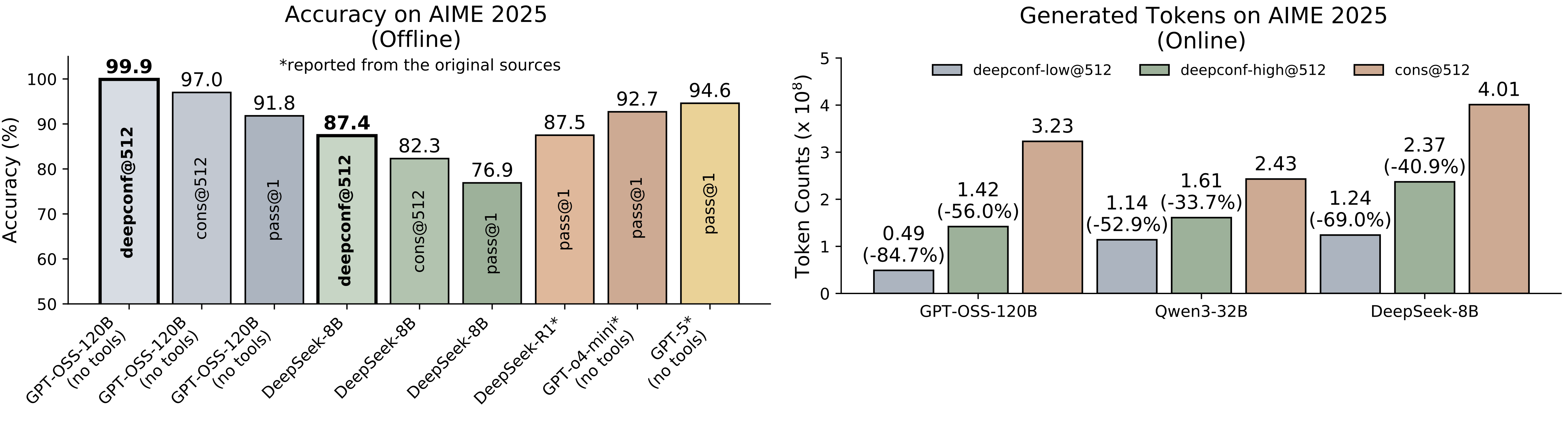
공식 프로젝트 페이지의 대표 결과.
왼쪽은 AIME 2025 offline accuracy, 오른쪽은 online setting에서 생성 토큰 수 감소를 보여준다.
그림 자체는 정보량이 많으므로, 핵심은 “정확도 유지/개선과 토큰 절감이 동시에 관찰된다”는 점이다.
정량 결과를 요약하면 다음과 같다.
| 근거 | 확인되는 내용 | 해석 |
|---|---|---|
| arXiv 논문 | AIME24/25, BRUMO25, HMMT25, GPQA-Diamond에서 64회 반복 평균 실험 | 단일 benchmark cherry-pick보다는 다양한 reasoning task에서 본 패턴 |
| Offline 결과 | GPT-OSS-120B AIME25: Cons@512 97.0% → Tail Conf top 10% 99.9% | 단순 다수결보다 confidence 기반 trace 선별이 강할 수 있음 |
| Online 결과 | GPT-OSS-120B AIME25: 3.23×10^8 token → 0.49×10^8 token, 정확도 97.1% → 97.9% | 저품질 trace 조기 종료가 비용 절감으로 이어짐 |
| vLLM 예시 | logprobs=True, top_logprobs>=2, extra_body["vllm_xargs"]로 early stopping 설정 |
logprob를 노출하는 serving stack에서는 비교적 자연스럽게 붙일 수 있음 |
| GitHub / PyPI | facebookresearch/deepconf, MIT license, PyPI deepconf 0.1.0, GitHub releases/tags는 없음 |
공개 패키지는 있지만 아직 성숙한 버전 릴리스 체계는 약함 |
| vLLM PR #23201 | confidence-based early stopping PR은 closed / unmerged | upstream 표준 기능이라기보다 별도 patch 또는 wrapper로 봐야 함 |
LinkedIn 해설 글에서 흥미로운 부분은 DeepConf를 HyperCLOVAX-SEED-Think-14B에 적용한 작은 자체 실험도 소개한다는 점이다.
작성자는 ChatML의 thinking 단계와 answer 단계에 서로 다른 threshold를 두는 식으로 응용했고, 약 10개 AIME 2025 샘플에서 다수결 정확도 +20.0%p, 평균 생성 토큰 29.6% 감소, 생성 시간 41.6% 단축을 언급한다.
다만 이는 논문 본 실험과 달리 표본 수가 작고 재현 가능한 공개 benchmark table이라기보다는 응용 관찰에 가까우므로, 본 논문 수치와는 분리해서 읽어야 한다.
실무 관점에서의 해석
내가 보기에 DeepConf의 가치는 “confidence가 정답 여부를 완벽하게 예측한다”가 아니라, 추론 런타임이 내부 uncertainty를 비용 정책으로 쓸 수 있다는 점에 있다.
지금까지 test-time scaling은 주로 더 많이 샘플링하고 더 많이 투표하는 방향이었다.
DeepConf는 그 다음 질문을 던진다.
많이 샘플링하되, 어느 trace는 일찍 버리고, 어느 trace에는 더 큰 투표권을 줄 수 있는가?
이 관점은 agent 시스템과도 잘 맞는다.
Agent orchestration에서는 이미 여러 후보 계획, tool call 결과, 검증 루프, self-reflection을 운영한다.
여기에 confidence 기반 필터링이 들어오면 “모든 후보를 끝까지 실행”하는 대신, 불안정한 reasoning branch를 조기에 닫는 정책을 만들 수 있다.
특히 수학·코딩처럼 정답 검증이 부분적으로 가능하거나, 긴 chain-of-thought가 비용의 큰 비중을 차지하는 워크로드에서 실험 가치가 크다.
다만 운영 적용에는 몇 가지 제약이 있다.
첫째, token logprob를 충분히 안정적으로 얻어야 한다.
모든 provider가 같은 방식으로 top logprobs를 제공하지 않으며, hosted API 환경에서는 logprob 접근이나 early stopping hook이 제한될 수 있다.
둘째, confidence는 calibration 문제를 피할 수 없다.
논문도 모델이 틀린 경로에 과신하는 경우를 future work로 언급한다.
공격적인 top 10% 필터링은 성능을 크게 올릴 수 있지만, domain shift가 있으면 오히려 좋은 다양성을 버릴 수도 있다.
셋째, online DeepConf는 serving stack 내부 수정에 더 가깝다.
단순 client-side 후처리로는 이미 토큰이 생성된 뒤라 비용을 줄일 수 없다.
실제 토큰 절감을 얻으려면 generation 도중 confidence를 계산하고 중단할 수 있어야 하며, 이는 vLLM 같은 오픈 서빙 엔진에서는 가능하지만 폐쇄형 API에서는 어렵다.
따라서 실무 적용 순서는 offline filtering으로 품질 신호를 먼저 검증하고, 그 다음 self-hosted serving 경로에서 online early stopping을 실험하는 편이 자연스럽다.
결론적으로 DeepConf는 self-consistency의 “많이 생각하기”를 “선별해서 생각하기”로 바꾸는 방법이다.
모든 trace를 같은 값으로 취급하지 않고, 모델이 스스로 드러내는 불확실성 신호를 사용해 추론 예산을 배분한다.
장기적으로는 test-time scaling이 단순 sample count 경쟁에서 벗어나, confidence, verifier, tool feedback, consensus를 결합한 런타임 정책 경쟁으로 이동할 가능성을 보여주는 사례다.