VLM은 이미지 안의 물체를 설명하고 장면의 의미를 추론하는 데는 빠르게 강해졌지만, 실제 3D 세계를 따라가며 공간 관계를 유지하는 문제에서는 여전히 약하다.
카메라가 움직이고, 물체가 여러 프레임에 부분적으로만 보이고, “문에서 등을 돌리고 서 있을 때 카메라는 어느 쪽인가” 같은 질문이 나오면 단일 이미지 caption 능력만으로는 부족하다.
S-Agent: Spatial Tool-Use Elicits Reasoning for Spatial Intelligence는 이 약점을 spatio-temporal evidence accumulation 문제로 다시 정의한다.
핵심은 VLM에게 모든 기하 추론을 내부적으로 맞히라고 시키지 않는 것이다.
VLM은 “무엇을 확인해야 하는가”를 계획하고, 실제 공간 증거는 2D grounding 도구, 3D lifting 도구, spatial expert, 그리고 scene/agent memory가 축적한다.
흥미로운 점은 이 논문이 단순히 새 benchmark 점수를 올리는 데서 멈추지 않는다는 것이다.
S-Agent는 기존 VLM을 감싸는 training-free inference-time framework로도 쓰이고, 그 궤적을 다시 SFT 데이터로 만들어 S-Agent-8B라는 compact spatial agent를 학습시키는 teacher 역할도 한다.
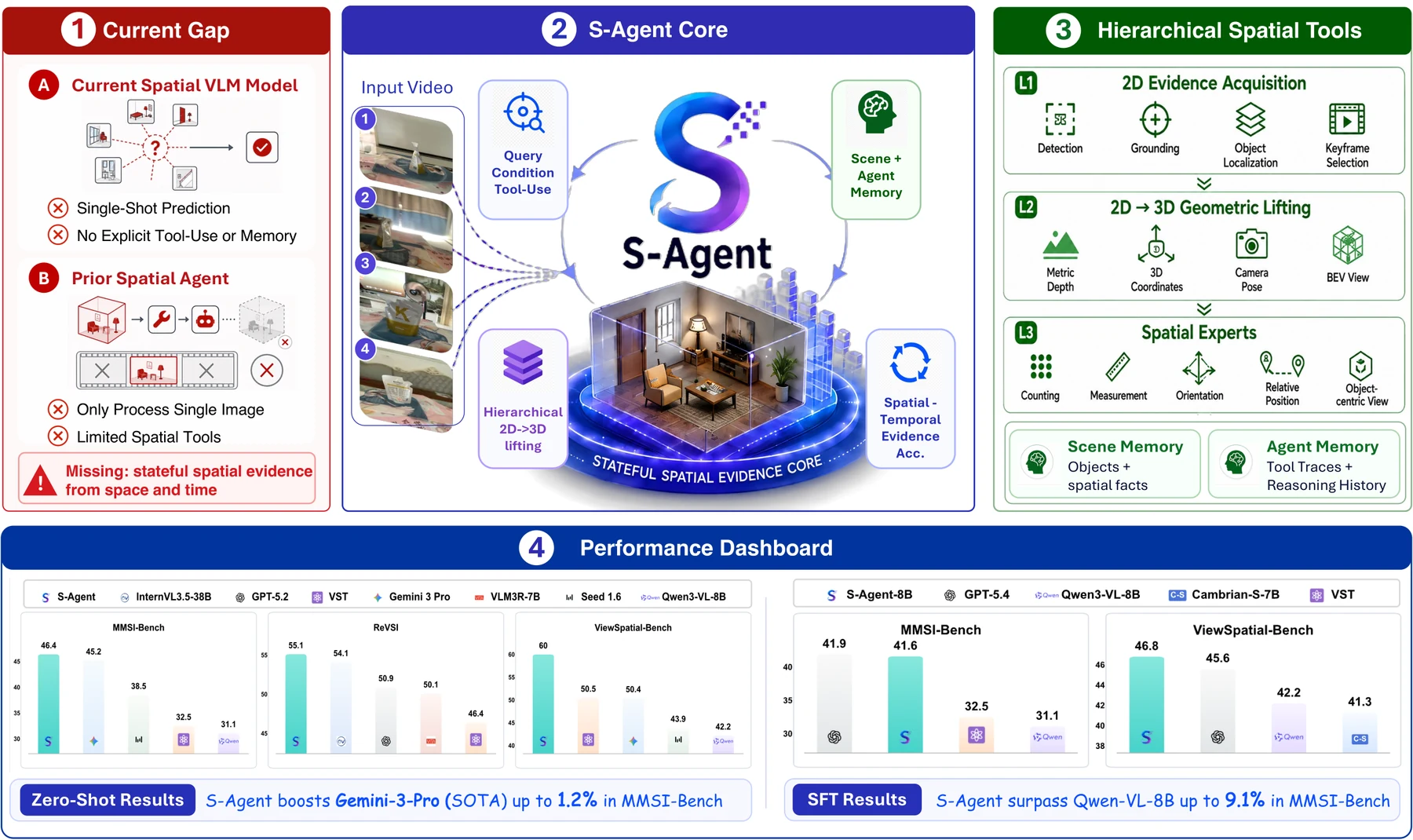
무엇을 해결하려는가
논문의 문제의식은 “VLM이 더 큰 이미지 모델이 되면 3D 공간 추론도 자연스럽게 해결된다”는 가정에 대한 반론에 가깝다.
실제 세계는 숨겨진 3D 상태가 시간에 따라 변하고, 관측은 그중 일부가 2D 프레임으로 투영된 결과다.
한 프레임 안에서 물체를 잘 찾는 것과, 여러 view에 흩어진 같은 물체의 identity·depth·orientation·distance를 유지하는 것은 다른 문제다.
기존 agentic spatial reasoning 연구도 외부 tool을 사용해 이 간극을 줄이려 했다.
논문은 VADAR, SpaceTools, GCA 같은 계열을 언급하면서도, 많은 접근이 여전히 static image나 isolated observation 중심이라고 본다.
S-Agent가 겨냥하는 setting은 더 까다롭다. video나 multi-view image처럼 관측이 계속 들어오고, 한 번 본 object와 관계를 다음 단계에서 다시 써야 하며, spatial answer는 누적된 장면 상태에 의존한다.
그래서 S-Agent의 질문은 “VLM이 답을 아는가”보다 “VLM이 어떤 증거를 더 모아야 하는지 계획할 수 있는가”에 가깝다.
이 framing은 실무적으로도 중요하다.
로봇, AR/VR, 자율주행, egocentric assistant는 정답을 바로 찍기보다, 무엇을 다시 볼지, 어떤 geometry를 계산할지, 이전 관측을 어떻게 유지할지 결정해야 한다.
핵심 구조: planner, tool hierarchy, dual memory
S-Agent의 추론 loop는 두 개의 상태를 유지한다.
하나는 장면의 grounded spatial evidence를 담는 Scene Memory이고, 다른 하나는 도구 호출과 중간 추론 이력을 담는 Agent Memory다.
단계 t에서 VLM planner는 질문, 입력 관측, 두 memory를 보고 evidence request를 만든다.
선택된 tool 또는 expert가 이 요청을 실행하고, 결과 observation이 다시 memory를 갱신한다.
이 구조의 핵심은 역할 분리다.
VLM은 semantic planner로서 “어떤 물체를 찾아야 하는가”, “어떤 관계를 측정해야 하는가”, “추가 증거가 필요한가”를 판단한다.
반면 spatial evidence acquisition은 도구가 담당한다.
논문은 이를 세 단계 hierarchy로 나눈다.
| 단계 | 역할 | 공개 자료에서 확인되는 예시 |
|---|---|---|
| Level 1: 2D evidence | 관련 frame·object·region을 찾고 2D visual cue를 만든다 | vlm_ground, detect (GDINO), depth, keyframe |
| Level 2: 2D-to-3D lifting | 2D cue를 metric coordinate, camera pose, BEV 등 3D-aware evidence로 올린다 | metric_3d (DA3), camera pose, BEV |
| Level 3: spatial experts | count, measure, relative position, orientation 같은 task-specific evidence를 만든다 | measure, count, relpos, vis_orient, obj_view |
여기서 memory는 장식이 아니다.
Scene Memory는 같은 물체가 여러 view에서 반복 등장할 때 identity와 spatial attribute를 유지하고, Agent Memory는 어떤 요청을 했고 어떤 observation을 얻었는지 기록한다.
따라서 다음 tool call은 원점에서 다시 시작하지 않고, 이미 축적한 evidence 위에서 더 필요한 부분만 요청할 수 있다.
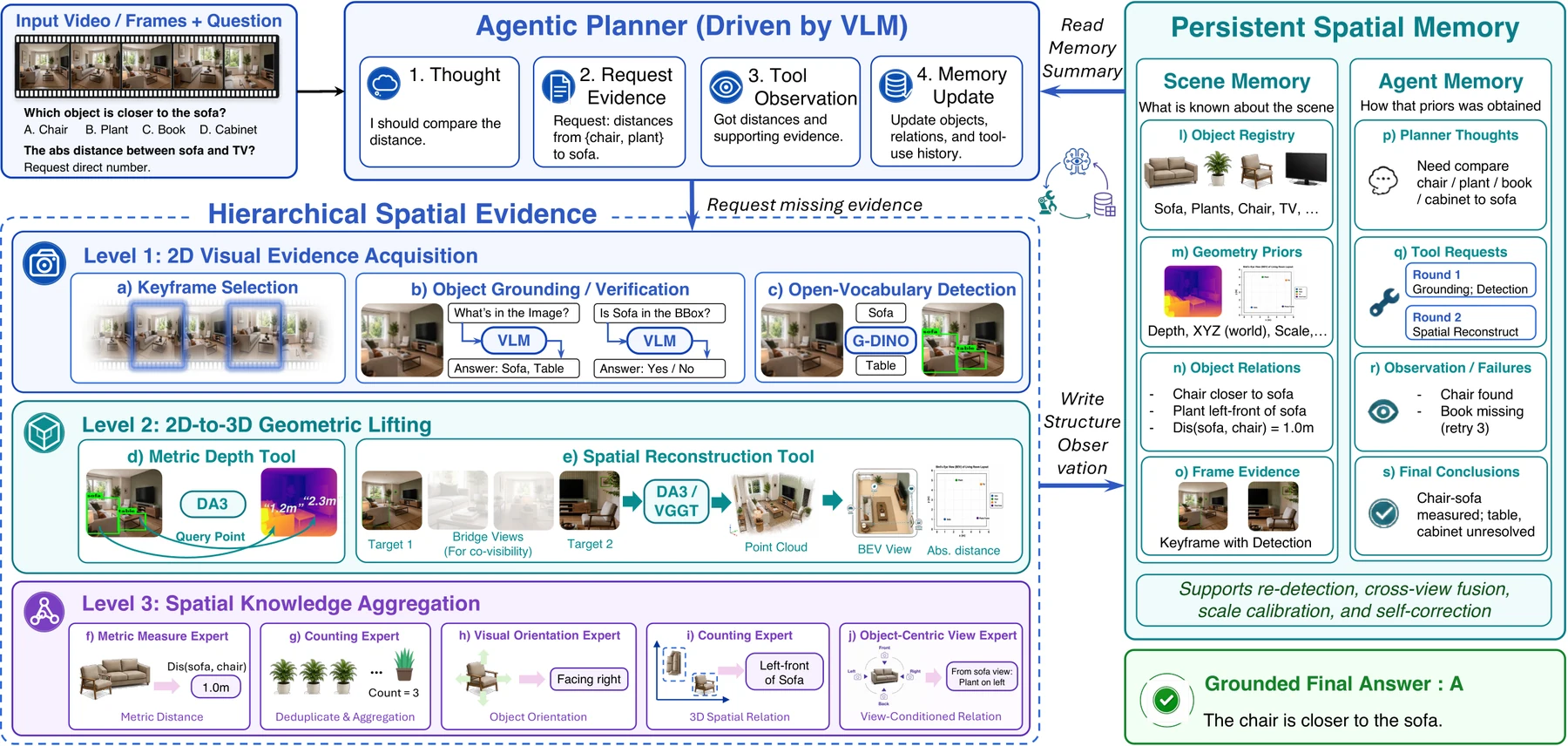
이 설계는 일반적인 tool-use agent와도 조금 다르다.
많은 tool-use workflow는 “질문 → tool call → 답변”처럼 개별 호출이 느슨하게 이어진다.
S-Agent는 tool output을 scene-specific state로 계속 쌓아 두고, 다음 evidence request가 그 상태에 조건화된다.
즉 spatial reasoning을 stateless API 호출이 아니라 stateful perception-reasoning loop로 만든다.
공개된 결과에서 확인되는 점
논문은 S-Agent를 두 가지 방식으로 평가한다.
첫째는 기존 VLM 위에 올리는 training-free zero-shot framework다.
둘째는 S-Agent trajectory로 만든 instruction data를 이용해 작은 spatial agent를 학습시키는 distillation이다.
Zero-shot 결과부터 보면, S-Agent는 MMSI-Bench에서 평균 46.4%를 보고한다.
같은 표에서 Gemini 3 Pro는 45.2%, GPT-5.4는 41.9%다.
논문이 강조하는 “GPT-5.4 대비 +4.5 point”는 이 MMSI 평균 차이다.
ViewSpatial-Bench에서는 S-Agent가 60.0%로, GPT-5.4의 45.6%보다 +14.4 point 높다.
ReVSI에서는 평균 58.8로 Gemini 3 Pro 60.9 다음의 강한 결과를 보인다.
| 평가 | 기준 모델/비교점 | S-Agent에서 보이는 신호 |
|---|---|---|
| MMSI-Bench | GPT-5.4 41.9, Gemini 3 Pro 45.2 | S-Agent 46.4로 closed-source frontier와 비슷하거나 일부 앞선다 |
| ViewSpatial-Bench | GPT-5.4 45.6 | S-Agent 60.0, 특히 person-perspective relative direction에서 큰 폭으로 오른다 |
| ReVSI | Gemini 3 Pro 60.9 | S-Agent 58.8로 video spatial reasoning에서도 상위권이지만 absolute best는 아니다 |
| S-Agent-8B distillation | Qwen3-VL-8B-Instruct MMSI 31.1 | S-Agent-8B는 MMSI 41.6으로 +10.5 point를 보고한다 |
Ablation도 구조적 메시지를 잘 보여 준다.
ViewSpatial에서 GPT-5.4 planner를 썼을 때 VLM-only baseline은 45.6이다.
여기에 Level-1 2D evidence를 넣으면 49.0, Level-2 3D evidence까지 넣으면 49.8, Level-3 expert까지 넣으면 56.7이 된다.
Scene memory와 Agent memory를 모두 켠 full S-Agent는 60.0까지 오른다.
즉 성능 향상은 단순히 “도구 하나를 붙였다”가 아니라, evidence hierarchy와 memory가 함께 작동할 때 커진다는 해석이 가능하다.
Distillation 쪽에서는 S-Agent가 teacher처럼 쓰인다.
논문은 zero-shot S-Agent trajectory에서 S-300K를 만들고, Qwen3-VL-8B-Instruct를 SFT해 S-Agent-8B를 만든다.
공개 표에 따르면 quality-filtered trajectory는 51,596개, turn-level trajectory는 154,590개, nontrivial tool/expert trajectory는 86,205개이며, 최종 SFT sample 수는 292,391개다.
S-Agent-8B는 MMSI 41.6, ViewSpatial 46.8, ReVSI 52.8을 보고한다.
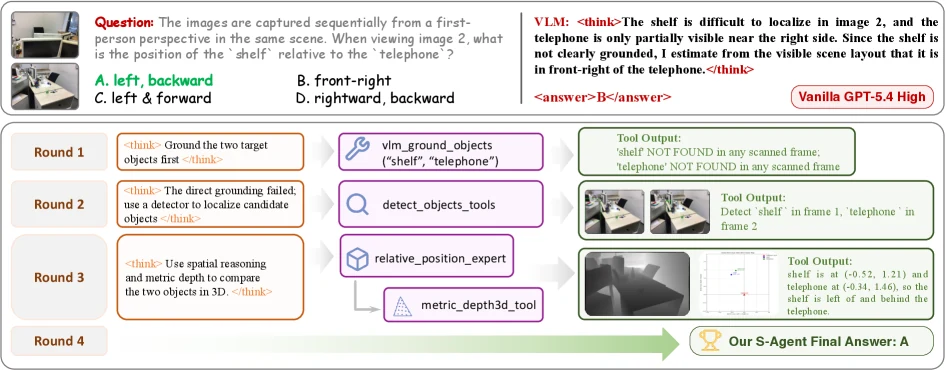
다만 결과 해석에는 caveat가 있다.
VSI-SUPER long-video 비교에서 S-Agent는 VSR duration별 점수에서 강한 편이지만, VSC 쪽은 10분 10.6, 30분 4.2, 60분과 120분 0.0으로 나온다.
즉 S-Agent가 모든 long-video spatial task를 해결했다기보다는, multi-view/video spatial reasoning의 특정 축에서 강한 evidence accumulation 구조를 보여 준다고 읽는 편이 안전하다.
공개 패키지와 릴리스 성숙도
공개 표면은 arXiv/HF Papers, 프로젝트 페이지, GitHub repo로 나뉜다.
논문과 프로젝트 페이지는 비교적 풍부하다.
프로젝트 페이지는 framework figure, trajectory examples, benchmark summaries, paper PDF, arXiv, GitHub 링크를 제공한다. trajectory 예시는 “headphones를 기준으로 문 반대 방향을 바라볼 때 camera가 어느 쪽인가” 같은 문제를 parsing, 2D evidence, 3D lift, orientation, direction resolution 단계로 보여 준다.
반면 실행 가능한 배포는 아직 초기 상태다.
GitHub Ropedia/S-Agent 저장소는 공개되어 있지만, 확인 시점 기준 top-level은 README.md와 assets/ 중심이다.
README badge도 Code-coming soon, Data-coming soon으로 표시한다.
TODO에는 inference/evaluation code, S-Agent trajectories/S-300K data, model checkpoints and usage examples가 모두 추후 공개 항목으로 남아 있다.
| 공개 표면 | 확인한 내용 | 해석 |
|---|---|---|
| HF Papers / arXiv | arXiv:2606.20515, v1, CC BY 4.0, 프로젝트 페이지 링크 | 논문 본문·표·figure의 canonical source |
| Project page | framework, trajectory examples, benchmark summary, paper PDF, GitHub link | 독자가 아이디어와 사례를 보기 가장 좋은 표면 |
GitHub Ropedia/S-Agent |
stars 27, forks 0, open issues 1, default branch main, tags/releases 없음 |
현재는 paper/project asset 중심의 초기 repo |
| README release notes | code/data/checkpoint 모두 coming soon | 논문 결과를 바로 재현할 수 있는 공개 코드 패키지는 아직 아니다 |
| Hugging Face Hub 검색 | arXiv ID 2606.20515로 model/dataset/Space 검색 결과 없음. ropedia-ai에는 DA-Next·Xperience·SpatialBenchmark 계열은 있지만 S-Agent-specific model/dataset은 보이지 않음 |
S-Agent-8B나 S-300K Hub 배포는 확인되지 않았다 |
이 점은 글의 중심 해석을 바꾼다.
S-Agent는 “지금 바로 내려받아 돌릴 수 있는 spatial agent framework”라기보다, 공간 추론을 stateful tool-use loop로 바꾸는 연구 패러다임과 그 실험 결과에 가깝다.
코드·데이터·checkpoint가 공개되면 재현성과 실사용성 평가는 다시 봐야 한다.
실무 관점에서의 해석
내가 보기에 S-Agent의 가장 중요한 메시지는 공간 지능을 모델 크기만으로 해결하려 하지 않는다는 점이다.
3D 세계는 관측이 부분적이고, 시간에 따라 바뀌며, answer에 필요한 evidence가 매번 다르다.
이런 조건에서는 VLM이 모든 geometry를 암묵적으로 상상하기보다, 무엇을 측정하고 어떤 evidence를 기억할지 결정하는 planner가 되는 편이 더 자연스럽다.
이 구조는 로봇이나 AR/VR만이 아니라 일반 에이전트 시스템에도 시사점이 있다.
멀티모달 agent가 화면, 카메라, 문서, 로그를 다룰 때도 비슷한 문제가 생긴다.
단일 screenshot에서 바로 결론을 내리기보다, 관련 region을 찾고, 좌표·상태·이전 관측을 저장하고, 다음 단계에서 재사용해야 한다.
S-Agent의 Scene Memory와 Agent Memory 분리는 그런 시스템 설계에도 적용 가능한 패턴이다.
또 하나는 distillation의 의미다.
Tool-use agent는 호출 비용이 크고 느릴 수 있다.
하지만 S-Agent는 비싼 tool-use trajectory를 teacher로 삼아 compact model에 일부 능력을 이전할 수 있음을 보여 준다.
물론 S-Agent-8B가 모든 설정에서 closed-source system을 이긴다는 뜻은 아니다.
그래도 “도구를 쓰는 큰 agent loop → 궤적 데이터 → 작은 agent 학습”이라는 경로는 멀티모달 agent를 제품화할 때 중요한 compression 전략이 될 수 있다.
한계도 분명하다.
첫째, 현재 공개 repo는 실행 코드와 checkpoint가 아직 coming soon이다.
둘째, 결과는 benchmark별로 강약이 다르며, long-video VSC처럼 여전히 낮은 축도 있다.
셋째, external spatial tool stack은 구성과 품질에 따라 전체 시스템 성능을 크게 좌우할 수 있다.
따라서 S-Agent를 “VLM 공간 추론의 완성형”으로 읽기보다, 공간 추론을 stateless recognition에서 stateful evidence orchestration으로 옮기는 설계 제안으로 읽는 것이 더 정확하다.
그럼에도 이 방향은 꽤 설득력 있다.
앞으로의 spatial/embodied AI가 실제 환경에서 동작하려면, 모델은 더 많은 이미지를 보는 것만이 아니라, 어떤 증거를 쌓고 무엇을 다시 확인하며 어떤 상태를 유지할지 알아야 한다.
S-Agent는 그 질문에 대한 하나의 명확한 답을 제시한다.
공간 추론은 정답을 즉시 맞히는 문제가 아니라, 장면에 대한 증거를 계속 축적하는 agent loop라는 것이다.