이미지 인페인팅은 겉으로 보기에는 “빈 영역을 그럴듯하게 채우는” 단일 태스크처럼 보이지만, 실제로는 생성 모델의 효율 논쟁이 매우 압축적으로 드러나는 영역이다.
FLUX.1-Fill-Dev나 SD3.5 Large-Inpainting 같은 대형 범용 모델은 zero-shot 품질이 강하지만, 10B급 파라미터와 높은 추론 비용을 전제로 한다.
서비스나 엣지 환경에서는 “좋은데 너무 무겁다”는 문제가 바로 병목이 된다.
Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance는 이 흐름에 반대 방향으로 접근한다.
Huazhong University of Science and Technology와 VIVO AI Lab의 저자들은 0.226B 파라미터의 태스크 특화 인페인팅 모델을 만들고, 구조 설계와 지식 증류를 함께 최적화하면 10B급 범용 모델과 견줄 수 있는 품질-속도 절충점을 만들 수 있다고 주장한다.
흥미로운 점은 “작은 모델도 잘한다”는 단순한 압축 주장이 아니라는 데 있다.
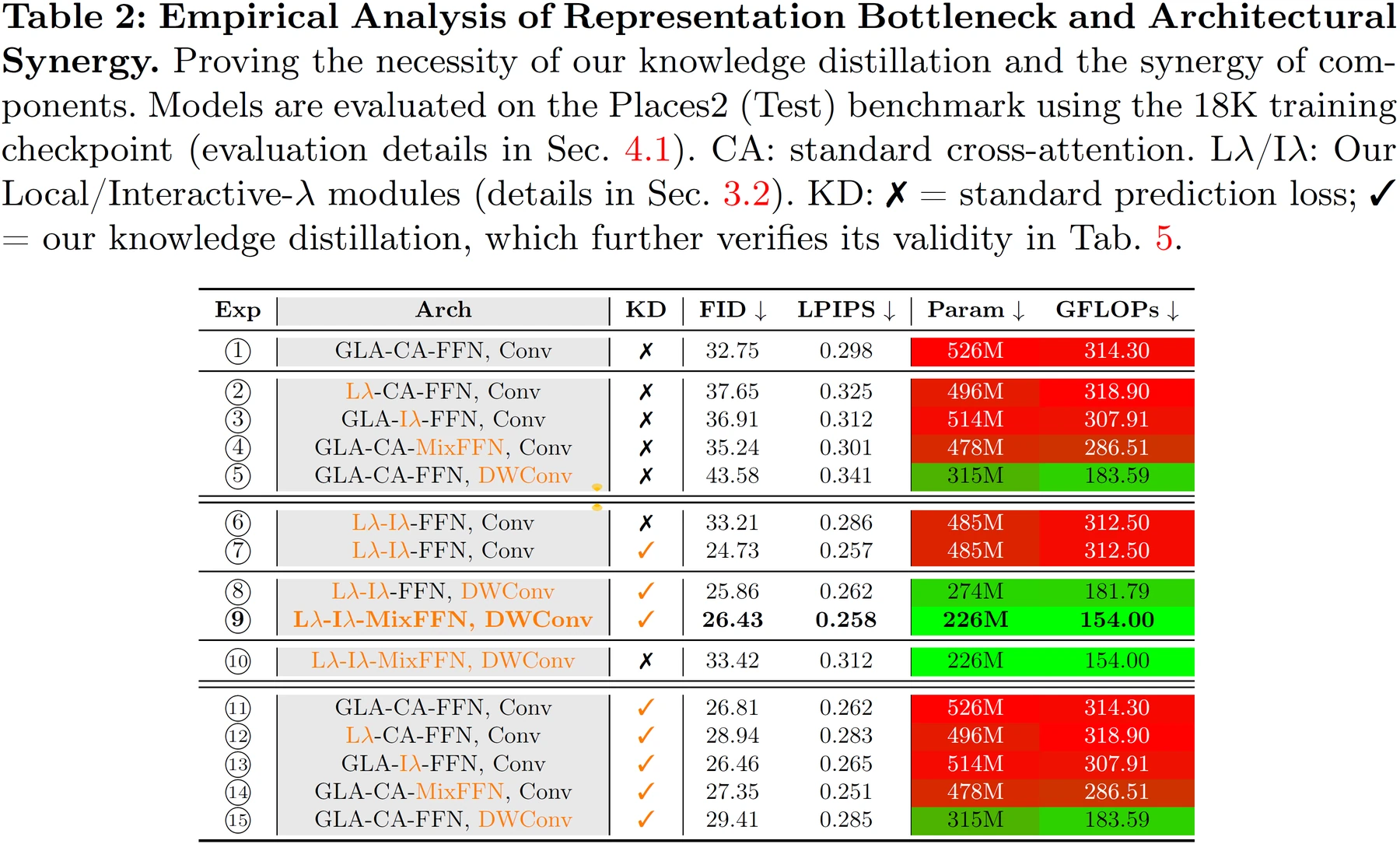
논문은 직접적인 lightweight module 치환만으로는 representation bottleneck이 생긴다고 보고, Local-λ Mix Interaction block과 adaptive multi-granularity distillation을 함께 넣어야 한다고 주장한다.
즉 Moebius의 핵심은 작게 만드는 것이 아니라, 작아진 구조가 어떤 상호작용을 잃지 않게 할 것인가에 있다.
무엇을 해결하려는가
대형 인페인팅 모델의 장점은 범용성이다.
다양한 마스크, 복잡한 장면, 얼굴, 사물 제거를 한 모델로 처리할 수 있다.
하지만 논문이 지적하는 문제는 그 범용성이 곧바로 실무 배포성으로 이어지지 않는다는 점이다.
FLUX.1-Fill-Dev는 약 11.9B 파라미터, SD3.5 Large-Inpainting은 약 8.1B 파라미터 규모로 평가된다. latency와 FLOPs도 작지 않다.
Moebius의 문제 설정은 따라서 다음 질문에 가깝다.
| 질문 | Moebius의 접근 |
|---|---|
| 인페인팅에 10B급 범용 backbone이 꼭 필요한가 | 태스크 특화 specialist로 범위를 좁힌다 |
| 단순 경량화가 왜 실패하는가 | attention·FFN·conv를 따로 줄이면 representation bottleneck이 생긴다고 본다 |
| 작은 student가 teacher의 품질을 어떻게 흡수하는가 | coarse feature, final latent output, latent perceptual loss를 함께 증류한다 |
| 실무적으로 무엇이 달라지는가 | 20 step, 0.52초 수준의 전체 추론 시간으로 비용 구조를 바꾼다 |
이 질문은 최근 vision foundation model 논의에서 중요하다.
모든 이미지 편집 태스크를 초대형 범용 모델에 맡길 수도 있지만, 특정 작업이 충분히 명확하다면 더 작은 specialist가 제품 비용과 지연 시간을 크게 낮출 수 있다.
Moebius는 그 가능성을 인페인팅에서 보여 주려는 시도다.
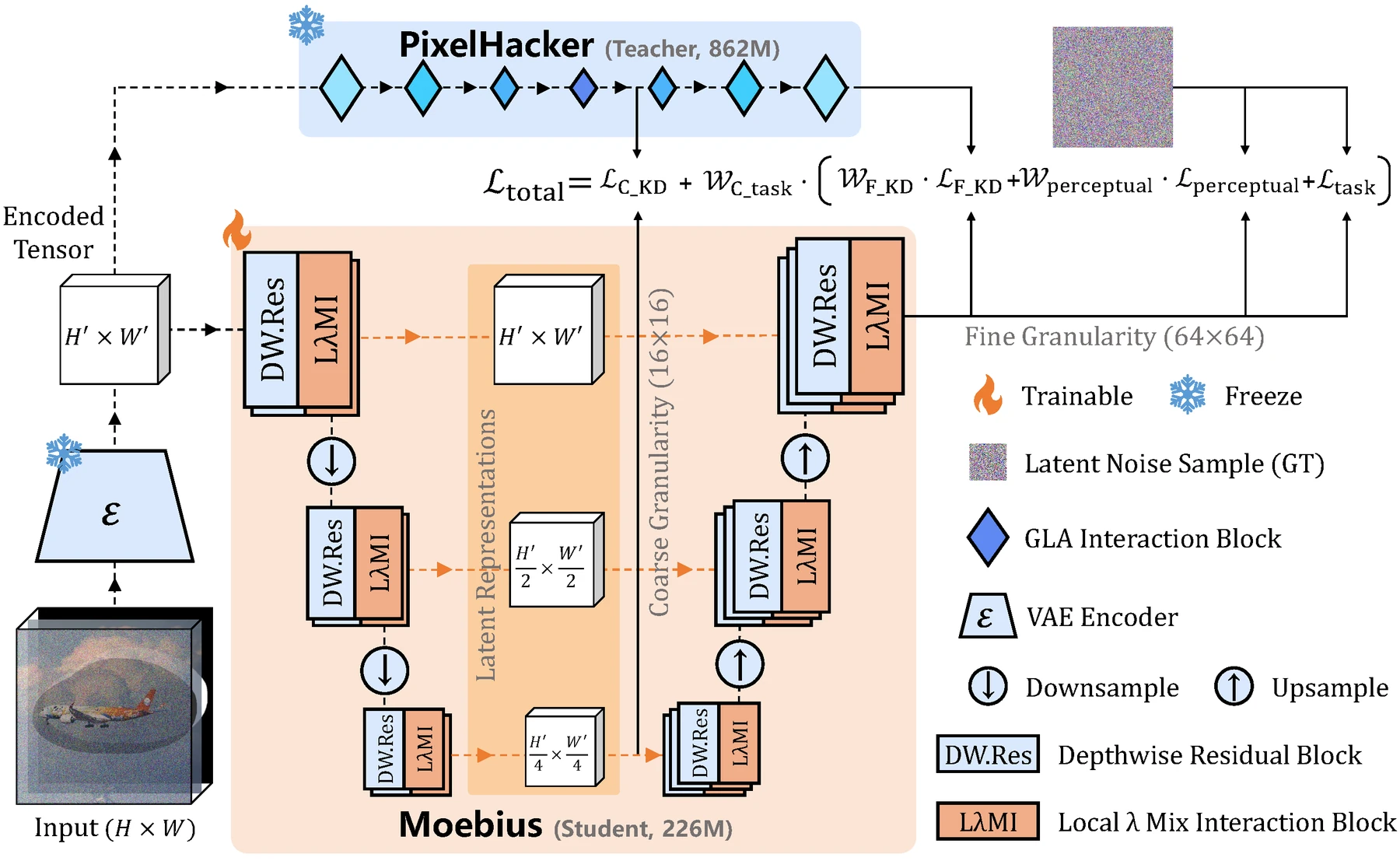
핵심 아이디어 / 구조 / 동작 방식
Moebius는 Latent Diffusion Model 기반의 인페인팅 pipeline을 사용한다.
입력 이미지와 binary mask를 받아 masked image를 만들고, pretrained VAE가 clean latent와 masked latent를 만든다.
여기에 PixelHacker에서 사용한 Latent Categories Guidance, 즉 LCG를 결합해 spatial reference와 semantic prior를 제공한다.
구조 쪽 핵심은 Local-λ Mix Interaction, LλMI block이다.
논문은 Local-λ module이 self-attention에 가까운 local spatial context를 요약하고, Interactive-λ module이 LCG embedding과의 cross-interaction을 담당한다고 설명한다.
두 경우 모두 중요한 점은 공간 문맥이나 전역 semantic prior를 고정 크기의 linear matrix로 요약해, full attention의 계산 부담을 줄인다는 것이다.
이 설계는 Depthwise Convolution과 Mix-FFN을 포함한 lightweight instantiation으로 이어진다.
하지만 논문은 단순히 “GLA로 attention을 바꾸고, FFN을 Mix-FFN으로 바꾸고, convolution을 DWConv로 바꾸면 된다”고 말하지 않는다.
실제 ablation에서 독립적인 치환은 성능을 크게 흔들 수 있고, LλMI·DWConv·Mix-FFN·distillation이 함께 맞물릴 때 압축과 품질의 균형이 나온다는 것이 논문의 주장이다.
학습 쪽에서는 PixelHacker를 teacher로 두고, Moebius를 student로 맞춘다.
증류는 세 층으로 구성된다.
| 증류 층위 | 논문에서의 역할 |
|---|---|
| Coarse-grained distillation | 16×16 수준의 intermediate bottleneck feature를 teacher와 student 사이에서 정렬 |
| Fine-grained distillation + task supervision | 64×64 final latent output에서 teacher prediction과 ground-truth latent noise를 함께 사용 |
| Latent perceptual distillation | pixel-space decoding 없이 E-LatentLPIPS를 latent domain에서 적용 |
여기에 gradient norm 기반 adaptive weighting을 붙인다. coarse/fine/perceptual loss는 scale과 gradient contribution이 다르기 때문에, 정적인 loss weight만 쓰면 수렴과 품질을 동시에 맞추기 어렵다.
Moebius는 주요 parameter set에 대한 gradient norm 비율로 loss weight를 동적으로 조정해, 작은 student가 특정 loss에 끌려가거나 representation을 충분히 쓰지 못하는 문제를 줄이려 한다.
공개된 근거에서 확인되는 점
논문 Table 1의 요지는 꽤 선명하다.
Moebius는 0.226B 파라미터, 0.154 TFLOPs, 26.01ms/step, 20 sampling steps로 평가된다.
총 추론 시간은 0.52초다.
같은 표에서 FLUX.1-Fill-Dev는 11.902B 파라미터, 9.927 TFLOPs, 161.01ms/step, 50 steps, 총 8.05초로 제시된다.
논문이 말하는 “15× faster”는 이 total time 비교에서 나온다.

핵심 비교를 압축하면 다음과 같다.
| 모델 | 파라미터 | TFLOPs | ms/step | steps | total time | 해석 |
|---|---|---|---|---|---|---|
| Moebius | 0.226B | 0.154 | 26.01 | 20 | 0.52s | 가장 작은 specialist |
| PixelHacker | 0.862B | 0.338 | 46.89 | 20 | 0.94s | teacher이자 더 큰 academic baseline |
| SD3.5 Large-Inpainting | 8.057B | 8.657 | 151.02 | 28 | 4.23s | 대형 industrial baseline |
| FLUX.1-Fill-Dev | 11.902B | 9.927 | 161.01 | 50 | 8.05s | 10B급 generalist baseline |
품질 근거는 Places2, CelebA-HQ, FFHQ 같은 자연/인물 장면 benchmark와 user study로 제시된다.
단, 이 부분은 신중하게 읽어야 한다.
Moebius가 모든 숫자에서 일방적으로 1등이라는 뜻은 아니다.
예를 들어 Places2 일부 지표에서는 FLUX.1-Fill-Dev나 PixelHacker가 더 좋은 FID를 보이는 항목도 있다.
FFHQ에서는 PixelHacker가 Moebius보다 FID/LPIPS가 약간 더 좋다.
Moebius의 강점은 절대 성능 단독 1위라기보다, 226M 파라미터와 0.52초 total time으로 그 근처까지 간 효율 곡선에 있다.
반대로 portrait scene에서는 작은 모델의 태스크 특화가 꽤 잘 드러난다.
논문 Table 4에서 Moebius는 CelebA-HQ 512에서 FID 5.39, LPIPS 0.122를 보고하고, FFHQ 256에서 FID 8.15, LPIPS 0.231을 보고한다.
FLUX.1-Fill-Dev의 해당 수치는 CelebA-HQ FID 10.13/LPIPS 0.141, FFHQ FID 11.19/LPIPS 0.268로 제시된다.
인간 평가도 같은 방향이다.
논문은 natural, portrait, real-world set에서 각 scenario당 50개 case를 샘플링하고, 22명의 참가자가 global coherence와 visual fidelity 기준으로 forced-choice 평가를 했다고 설명한다.
평균 preference는 Moebius 31.76%, PixelHacker 32.18%, FLUX.1-Fill-Dev 23.70%, SD3.5 Large-Inpainting 12.36%로 보고된다.
특히 portrait scene에서는 Moebius가 가장 높은 preference를 얻었다고 한다.

공개 릴리스 상태도 확인할 만하다.
GitHub 저장소 hustvl/Moebius에는 training/inference code, config, inference script, requirements가 공개되어 있고, README는 2026년 6월 18일에 training/inference code와 Hugging Face model weights를 공개했다고 적고 있다.
Hugging Face hustvl/Moebius에는 pretrained, ft_places2, ft_celebahq, ft_ffhq checkpoint 파일이 올라와 있다.
다만 GitHub releases와 tags는 확인 시점에 비어 있었고, 사용자는 VAE checkpoint를 PixelHacker 쪽에서 별도로 받아 weight/vae에 배치해야 한다.
라이선스 표기도 표면별로 나뉜다. arXiv 논문 페이지는 CC BY-NC-SA 4.0을 표시하고, GitHub 저장소는 Apache-2.0 LICENSE와 badge를 제공하며, Hugging Face 모델 카드 API는 license: mit를 노출한다.
실제 제품 도입이나 재배포를 검토한다면 코드, weight, 논문 텍스트의 라이선스를 각각 따로 확인하는 편이 안전하다.
실무 관점에서의 해석
Moebius의 실무적 의미는 “작은 모델이 큰 모델을 완전히 대체한다”가 아니다.
더 정확히는 인페인팅처럼 태스크 경계가 비교적 분명한 영역에서, 대형 generalist와 작은 specialist의 비용 곡선이 달라질 수 있다는 사례다.
품질만 보면 PixelHacker나 FLUX가 더 나은 항목이 있고, OOD 자연 장면에서도 FLUX나 PixelHacker가 더 좋은 FID를 보이는 경우가 있다.
하지만 latency, FLOPs, 파라미터를 함께 보면 Moebius가 만드는 선택지는 다르다.
제품 관점에서는 세 가지가 중요하다.
첫째, 실시간/저비용 편집 경로다.
0.52초 total time이 논문 조건에서 재현된다는 전제가 붙지만, 이 숫자는 interactive image editing UX에서 꽤 큰 차이를 만든다.
“한 번 더 지워 보기”, “mask를 바꿔 다시 시도하기” 같은 반복 행동은 모델 품질뿐 아니라 응답 속도에 민감하다.
둘째, specialist deployment의 재평가다.
범용 foundation model 하나로 모든 편집 기능을 처리하는 전략은 단순하지만, 비용이 높다.
Moebius는 특정 태스크에 대해 specialist를 따로 두는 구성이 여전히 경쟁력 있을 수 있음을 보여 준다.
특히 온디바이스, consumer GPU, 서버 비용 절감이 중요한 환경에서는 더 그렇다.
셋째, 압축은 architecture와 distillation의 공동 설계 문제라는 점이다.
단순 pruning, 단순 linear attention, 단순 DWConv 대체만으로는 충분하지 않다.
논문이 설득력 있게 보여 주는 부분은 작은 구조 자체보다, 그 구조가 teacher의 semantic prior와 latent representation을 어떻게 받아들이는지다.
작은 모델 연구에서 “파라미터 수를 줄였다”보다 “어떤 상호작용을 남겼는가”가 더 중요한 질문이 된다.
한계도 분명하다.
Moebius는 인페인팅 specialist이므로, 범용 이미지 생성·편집 전체를 커버하는 모델로 읽으면 안 된다.
또한 공개 benchmark와 qualitative comparison은 논문 저자들이 설계한 평가 범위 안에서의 근거다.
실제 서비스에서는 사용자 mask 분포, 입력 해상도, safety policy, VAE/weight packaging, GPU kernel 호환성, checkpoint license를 다시 확인해야 한다.
그래도 Moebius가 던지는 질문은 좋다.
생성 모델 경쟁이 계속 “더 큰 generalist” 방향으로만 흐를 필요는 없다.
태스크가 충분히 선명하고, 구조와 증류가 같이 설계된다면, 작은 specialist가 더 빠르고 싸게 높은 체감 품질을 낼 수 있다.
인페인팅처럼 반복적이고 latency-sensitive한 기능에서는 이 방향이 단순한 연구 압축보다 훨씬 실용적인 선택지가 될 수 있다.
Sources:
- arXiv abstract: https://arxiv.org/abs/2606.19195
- arXiv HTML: https://arxiv.org/html/2606.19195v1
- Official project page: https://hustvl.github.io/Moebius
- GitHub repository: https://github.com/hustvl/Moebius
- Hugging Face model page: https://huggingface.co/hustvl/Moebius