여러 객체가 들어 있는 이미지에서 “이 영역은 무엇인가”를 각각 물어보는 작업은 생각보다 비싸다.
기존 멀티모달 LLM은 대체로 autoregressive generation을 쓰기 때문에, 영역이 1개면 한 번 설명하고, 4개면 네 번 설명하는 식으로 비용이 늘어난다.
객체 검출이나 segmentation 이후에 각 region을 자세히 설명해야 하는 dense perception 파이프라인에서는 이 순차성이 바로 병목이 된다.
PerceptionDLM: Parallel Region Perception with Multimodal Diffusion Language Models는 이 병목을 diffusion language model 관점에서 다시 푼 논문이다.
핵심 아이디어는 단순하다.
이미지와 여러 region mask를 한 입력으로 넣고, 각 영역의 캡션을 왼쪽에서 오른쪽으로 하나씩 생성하는 대신, 마스크된 텍스트 토큰들을 반복적으로 복원하는 디퓨전 과정 안에서 여러 영역 설명을 동시에 만든다.
저자들은 이를 “parallel region captioning and perception”이라고 부른다.
이 글은 arXiv 논문, 공식 프로젝트 페이지, GitHub 저장소, Hugging Face 모델·데이터 공개 상태를 기준으로 정리했다.
벤치마크 수치는 저자 측 보고값이며, 별도 재현 실험은 하지 않았다.
무엇을 해결하려는가
지역 캡션 모델의 기본 형태는 보통 다음과 같다.
이미지 I와 하나의 영역 R_i를 넣으면 캡션 y_i를 만든다.
여러 영역을 설명하려면 이 과정을 반복한다.
y_i = f(I, R_i)
이 방식은 단순하고 강력하지만, 영역 수가 늘어날수록 latency가 거의 선형으로 증가한다.
논문이 비교 대상으로 드는 DAM, GAR 같은 autoregressive region-specific VLM도 본질적으로 각 region을 순차 처리한다.
반면 PerceptionDLM은 문제를 다음처럼 바꾼다.
{y_i}_{i=1..N} = f(I, {R_i}_{i=1..N})
즉 하나의 이미지와 여러 mask를 동시에 보고, 여러 영역 설명을 하나의 generation problem으로 만든다. diffusion language model은 마스크된 위치들을 병렬적으로 복원할 수 있으므로, 여기서 token-level parallelism뿐 아니라 region caption sequence 자체의 parallelism도 노릴 수 있다.
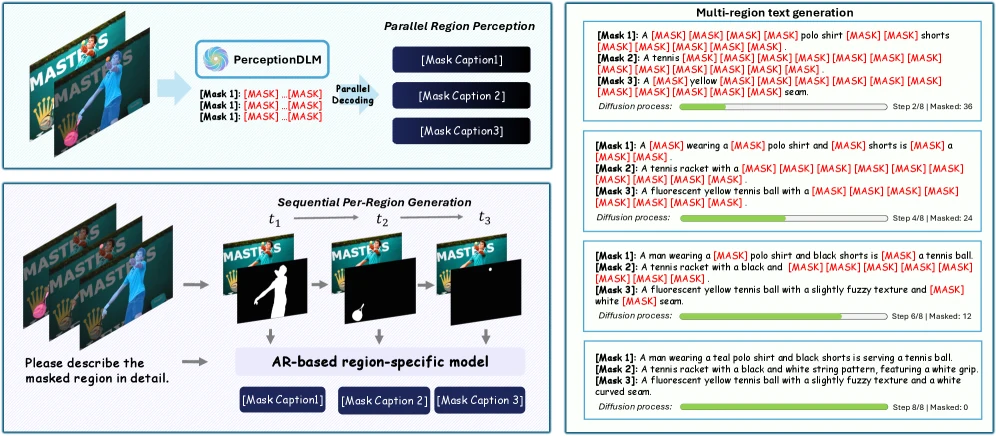
논문 Figure 1의 메시지는 명확하다. autoregressive region captioner는 영역 수가 늘수록 호출 비용이 누적되지만, PerceptionDLM은 여러 region caption을 한 denoising process에 묶는다.
저자 보고 기준으로 constant heavy workload, 즉 이미지당 4개 mask 조건에서 parallelism을 높이면 throughput이 최대 3.44배 개선된다.
핵심 구조: PerceptionDLM-Base 위에 병렬 region head를 얹는다
PerceptionDLM은 처음부터 완전히 새로운 VLM을 학습했다기보다, 먼저 PerceptionDLM-Base라는 diffusion VLM baseline을 만든 뒤 그 위에 parallel region perception 구조를 얹는다.
PerceptionDLM-Base의 주요 구성은 다음과 같다.
| 구성 요소 | 공개 자료 기준 설명 |
|---|---|
| Vision encoder | SigLIP-2 계열 vision tower |
| Connector | GELU를 쓰는 2-layer MLP |
| Language backbone | LLaDA-Instruct-8B diffusion language model |
| 이미지 해상도 처리 | 512×512 tile 기반 dynamic resolution, 필요 시 thumbnail 추가 |
| 학습 방식 | image/prompt token은 유지하고 response token에 diffusion masking 적용 |
기본 VLM만으로 끝나지 않는 이유는 region별 caption을 서로 섞이지 않게 만들어야 하기 때문이다.
여러 영역을 한 프롬프트에 넣으면, 모델은 전체 이미지를 공유해야 하지만 각 region caption의 generation stream은 분리해야 한다.
논문은 이를 위해 세 가지 장치를 결합한다.
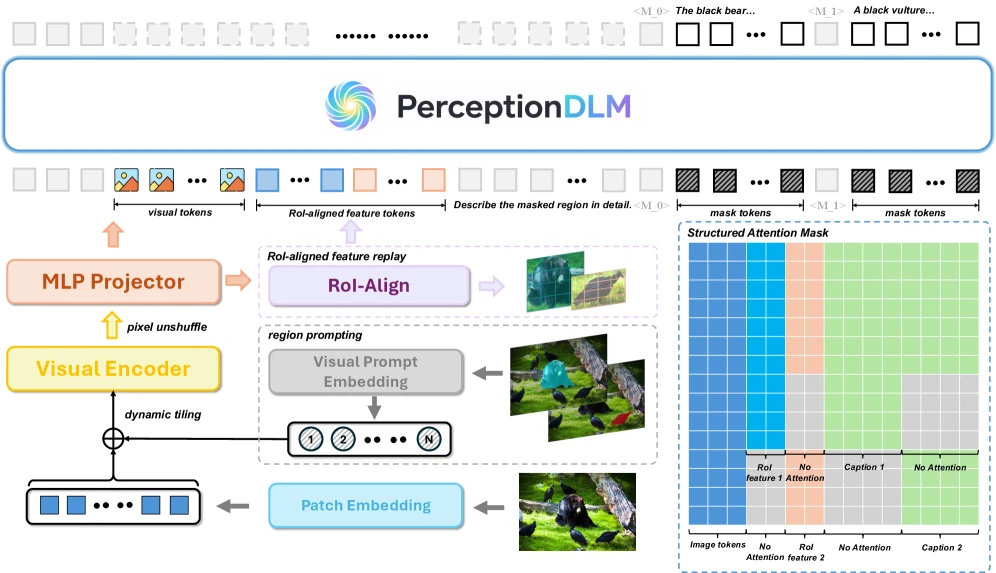
| 장치 | 역할 |
|---|---|
| Region prompting | 여러 mask region을 한 입력 안에 명시적으로 배치한다 |
| RoI-aligned feature replay | 각 region에 대응하는 visual feature를 다시 주입해 작은 영역 정보를 보존한다 |
| Structured attention masking | 영역별 caption stream은 분리하면서 global image context는 공유한다 |
여기서 중요한 부분은 structured attention masking이다.
단순히 캡션들을 이어 붙여 병렬로 디노이징하면, 한 region의 정보가 다른 region caption으로 새어 들어가 cross-region interference가 생길 수 있다.
PerceptionDLM은 각 caption stream이 자기 region 정보에 집중하되, 필요한 이미지 전역 문맥은 공유하도록 attention 구조를 설계한다.
그래서 논문의 주장은 “디퓨전이라서 병렬이다”가 아니라, “병렬 디퓨전이 region-localized captioning에서도 disentangled하게 작동하도록 prompt, RoI feature, attention mask를 같이 설계했다”에 가깝다.
ParaDLC-Bench: 품질과 속도를 같이 보는 벤치마크
저자들은 병렬 region perception을 평가하기 위해 ParaDLC-Bench도 함께 공개했다.
이는 기존 DLC-Bench를 단일 region 평가에서 multi-region localized captioning으로 확장한 벤치마크다.
Hugging Face 데이터셋 카드와 논문 기준 주요 통계는 다음과 같다.
| 항목 | 값 |
|---|---|
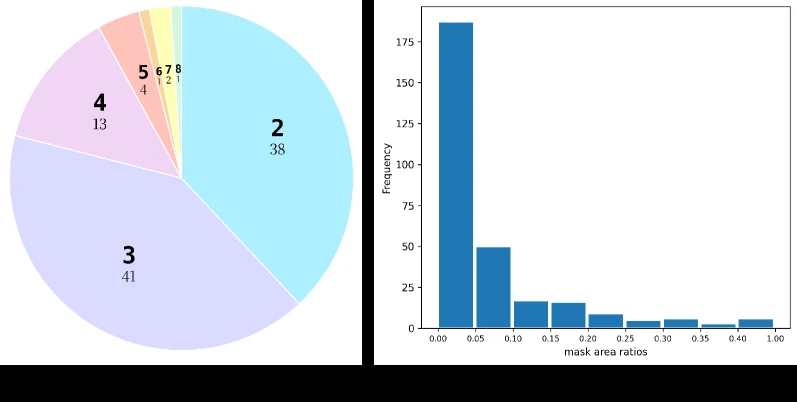
| 이미지 수 | 100 |
| 전체 mask 수 | 299 |
| 수동 검증 질문 수 | 2,345 |
| 이미지당 region 수 | 최소 2개, 대부분 2~4개, 일부 최대 8개 |
| 평균 mask area ratio | 0.07 |
| 원천 데이터 | Objects365 V2 val, DaTaSeg Objects365 instance segmentation |
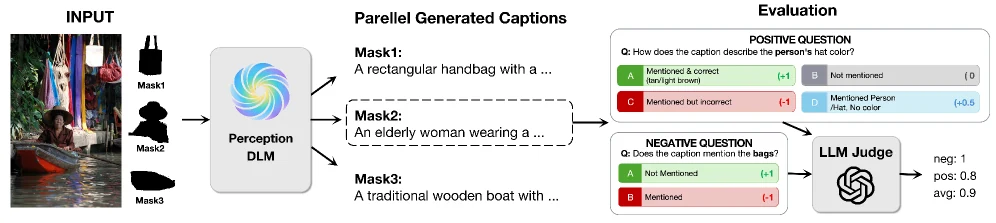
평가 방식도 이 논문에서 중요한 포인트다.
단순히 캡션이 그럴듯한지를 보는 것이 아니라, 각 mask에 대해 positive question과 negative/interference question을 둔다.
Positive question은 실제 속성 설명을 맞히는지 본다.
Negative question은 다른 region에서 빌려온 속성이나 “있을 법하지만 실제로는 없는” 세부 묘사를 hallucination으로 벌점화한다.
병렬 captioning에서 가장 위험한 것이 바로 서로 가까운 객체의 속성이 섞이는 문제이기 때문이다.
공개 수치에서 보이는 위치
논문 Table 2의 ParaDLC-Bench 결과를 보면 PerceptionDLM은 quality만 놓고는 GAR보다 낮지만, latency와 diffusion VLM baseline 대비 위치가 다르다.
| 모델 | 타입 | ParaDLC-Bench Avg | Time |
|---|---|---|---|
| GAR-8B | AR region-specific VLM | 69.5% | 479s |
| DAM-3B | AR region-specific VLM | 69.2% | 326s |
| LLaDA-V-8B | diffusion VLM baseline | 35.2% | 3241s |
| SDAR-VL-8B | diffusion VLM baseline | 31.3% | 945s |
| PerceptionDLM-8B | diffusion, parallel region captioning | 62.4% | 276s |
이 표를 읽을 때 핵심은 PerceptionDLM이 GAR보다 정확도가 높다는 이야기가 아니라, diffusion VLM 계열에서 region captioning 품질을 크게 끌어올리면서 AR region captioner보다 더 빠른 구간을 만든다는 점이다.
논문은 PerceptionDLM-Base가 LLaDA-V보다 15개/16개 multimodal benchmark에서 앞선다고도 보고한다.
즉 병렬 region head만의 이야기가 아니라, 먼저 diffusion VLM baseline 자체를 꽤 강하게 만든 뒤 multi-region task로 확장한 구성이다.
추가 실험에서도 설계 요소의 기여가 분해된다.
같은 training setting에서 region prompting을 제거하면 평균 점수가 거의 무너지고, RoI-aligned feature replay를 빼면 51.3%, full attention으로 바꾸면 47.5%로 내려간다.
저자 보고 기준 full model은 53.7%다.
이는 “여러 region을 한 sequence에 넣고 돌리면 된다”가 아니라, region separation과 feature replay가 실제 성능에 중요하다는 근거로 읽힌다.
질적 예시와 한계
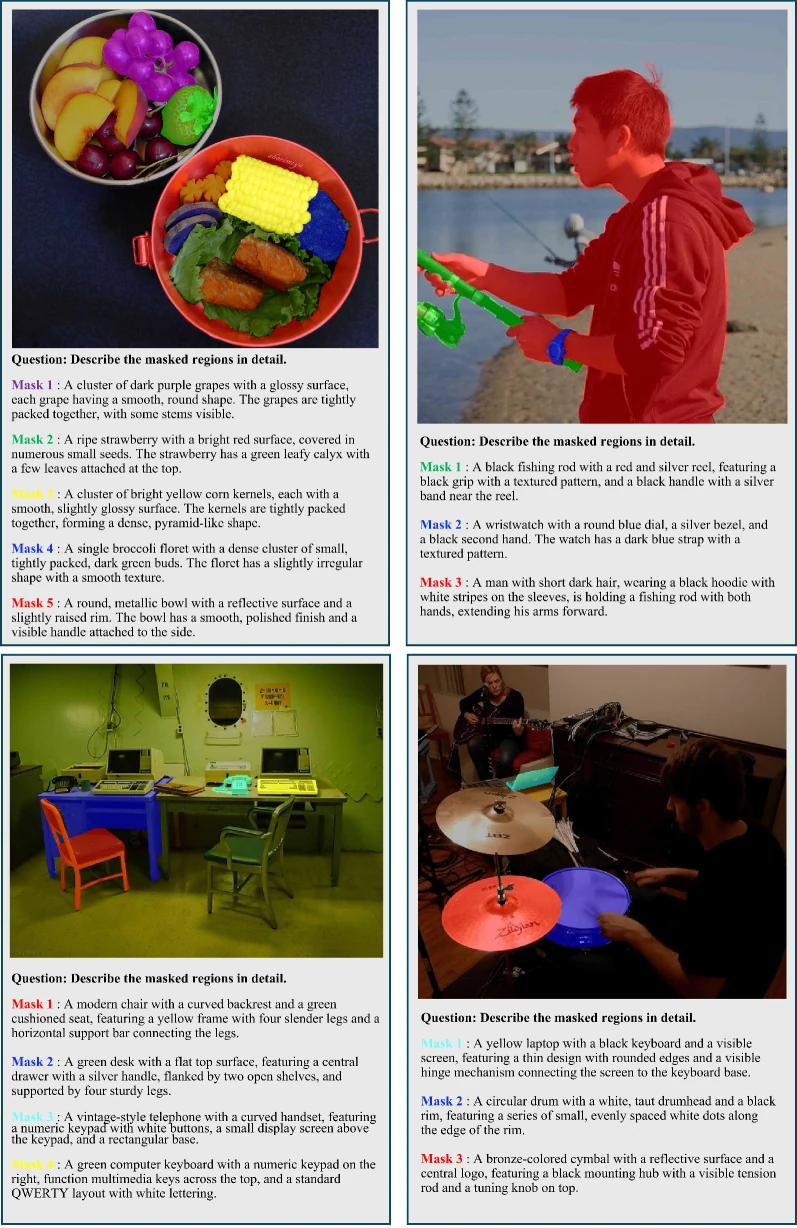
공식 Figure 5와 Figure 6은 PerceptionDLM이 여러 masked region에 대해 동시에 세부 설명을 생성하는 예시를 보여준다.
특히 baseline에서 한 영역의 색상이나 부품이 다른 영역 설명에 섞이는 cross-region interference를 PerceptionDLM이 줄인다는 점을 강조한다.
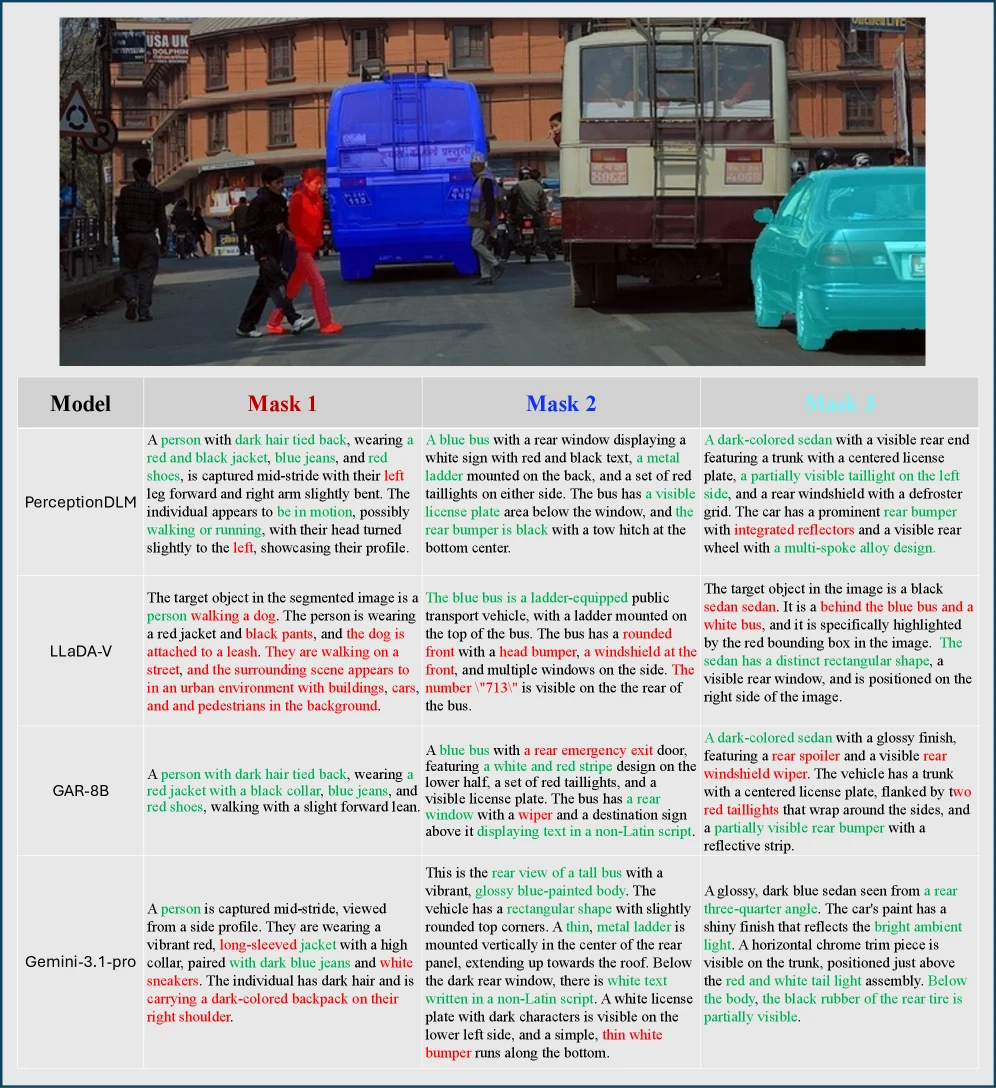
다만 한계도 논문에 명시돼 있다.
실패 사례는 대략 세 갈래다.
| 실패 유형 | 의미 |
|---|---|
| 인접 객체 흡수 | 같은 장면의 가까운 객체 특징이 caption에 섞인다 |
| 작은 저해상도 영역 과잉 특정 | 픽셀상 불명확한 부분을 너무 구체적으로 설명한다 |
| 보이지 않는 세부 묘사 hallucination | 작은 신발 영역에 끈, eyelet, tread 같은 디테일을 만들어낸다 |

이는 region-localized captioning이 단순 VQA보다 더 까다로운 이유이기도 하다.
모델은 이미지 전체 문맥을 알아야 하지만, 답변은 지정된 mask 내부에 엄격히 묶여야 한다.
PerceptionDLM은 구조적으로 이 문제를 완화하지만, 논문 스스로도 작은 region, 인접 region, fine-grained attribute hallucination은 남은 과제로 본다.
공개 상태와 실무적 해석
릴리스 상태는 꽤 좋은 편이다.
공식 GitHub 저장소는 Apache-2.0 라이선스로 공개되어 있고, Hugging Face에는 MSALab/PerceptionDLM-Base, MSALab/PerceptionDLM, MSALab/LLaDA-8B-Instruct-HF, MSALab/PerceptionDLM-Data, MSALab/ParaDLC-Bench가 컬렉션으로 묶여 있다.
README에는 uv sync --extra=dmllm 또는 uv sync --extra=pdmllm으로 환경을 맞추고, demo/infer_dmllm.py, demo/infer_pdmllm.py로 이미지 이해와 parallel region captioning을 실행하는 예시가 있다.
실무 관점에서 이 논문의 의미는 “디퓨전 언어 모델이 텍스트 생성에서 AR을 대체할 수 있는가”보다 조금 더 구체적이다.
PerceptionDLM은 생성 순서 자체가 병목이 되는 perception task, 특히 segmentation 이후 여러 region 설명을 만들어야 하는 구간에서 diffusion decoding의 장점이 더 직접적으로 드러날 수 있음을 보여준다.
일반 챗봇 응답보다 multi-region captioning은 출력들이 상대적으로 독립적이고, 동시에 생성할 명분이 분명하기 때문이다.
반대로 도입을 바로 결정하기에는 확인할 것이 남아 있다.
논문 수치는 저자 측 benchmark와 LLM-as-judge 기반이며, 실제 서비스 이미지 분포에서 small object, occlusion, fine-grained attribute 오류가 얼마나 남는지는 별도 검증이 필요하다.
또한 8B급 VLM을 여러 denoising step으로 돌리는 구조라서, 특정 하드웨어와 batch/workload 조건에서만 speedup이 체감될 수 있다.
그래도 방향성은 선명하다.
PerceptionDLM은 diffusion language model을 “토큰을 빨리 뽑는 다른 LM”으로만 보지 않고, 여러 시각 영역의 설명을 한 번에 정리하는 parallel perception primitive로 사용한다.
이미지 안의 여러 region을 독립적으로, 그러나 같은 장면 문맥 안에서 동시에 설명해야 하는 작업이 늘어난다면, 이런 구조는 AR VLM 뒤에 반복 루프를 붙이는 방식보다 더 자연스러운 운영면을 만들 수 있다.
Sources:
- Hugging Face paper page: https://huggingface.co/papers/2606.19534
- arXiv abstract: https://arxiv.org/abs/2606.19534
- arXiv HTML: https://arxiv.org/html/2606.19534
- arXiv PDF: https://arxiv.org/pdf/2606.19534
- Official project page: https://msalab-pku.github.io/projects/PerceptionDLM/
- GitHub repository: https://github.com/MSALab-PKU/PerceptionDLM
- Hugging Face model zoo: https://huggingface.co/collections/MSALab/perceptiondlm-model-zoo
- ParaDLC-Bench dataset: https://huggingface.co/datasets/MSALab/ParaDLC-Bench