AI 코딩 도구가 새 프로젝트와 작은 수정에서는 빠르게 빛나지만, 오래된 production codebase에서는 오히려 팀을 느리게 만들 수 있다는 이야기는 이제 낯설지 않다. 코드가 더 많이 나오지만, 그중 상당 부분이 지난주에 만든 AI slop을 다시 고치는 churn이 되기도 한다. “모델이 더 좋아지면 해결되겠지”라고 넘기기에는, 이미 현업 팀들은 오늘의 모델로도 복잡한 문제를 맡기고 싶어 한다.
AI Engineer 채널의 **No Vibes Allowed: Solving Hard Problems in Complex Codebases – Dex Horthy, HumanLayer**는 이 간극을 정면으로 다룬다. Dex Horthy는 HumanLayer에서 복잡한 코드베이스의 AI 코딩 에이전트 워크플로우를 다루고, 2025년 4월 12 Factor Agents 글로 context engineering이라는 표현을 널리 퍼뜨린 인물로 소개된다. 이 발표에서 그는 “vibe coding”의 반대편에 있는 실천을 제안한다. 즉 모델에게 더 긴 작업을 던지는 것이 아니라, context를 의도적으로 압축하고, spec과 plan을 팀의 source of truth로 만들고, 사람이 thinking을 아웃소싱하지 않는 방식이다.
내가 보기에는 이 발표의 핵심은 “AI 코딩은 되는가 안 되는가”가 아니다. 더 정확한 질문은 복잡한 코드베이스에서 agent가 사용할 context supply chain을 어떻게 설계할 것인가다. codebase, 이슈, 테스트, 과거 의사결정, 리뷰 기준, 구현 계획을 어떤 단위로 넣고 빼고 압축할지 정하지 않으면, 더 좋은 모델을 붙여도 금방 dumb zone으로 들어간다.
무엇을 다루는 영상인가
YouTube metadata 기준 영상은 AI Engineer 채널에 2025-12-02 업로드된 약 20분 31초짜리 컨퍼런스 발표다. 공식 chapter가 제공되어 있고, 설명란은 Stanford/Yegor의 개발자 생산성 분석, 300k LOC Rust codebase, Claude Code, frequent intentional compaction, research-plan-implement workflow를 핵심 배경으로 제시한다.
이 글은 영상 transcript, 공식 chapters, 화면에서 추출한 슬라이드 프레임, 그리고 HumanLayer의 companion 글 **Getting AI to Work in Complex Codebases**와 12 Factor Agents 자료를 함께 기준으로 삼았다.
| 구간 | 발표 내용 | 글에서 보는 포인트 |
|---|---|---|
| 00:00-01:40 | AI 코딩 도구가 complex/brownfield codebase에서 rework와 churn을 늘릴 수 있다는 문제 제기 | 생산성의 병목은 코드 생성량이 아니라 재작업과 품질 유지 |
| 01:40-02:53 | context engineering의 목표와 Claude Code에 대한 경험 변화 | 오늘의 모델도 context를 잘 주면 더 멀리 갈 수 있음 |
| 02:53-04:38 | naive loop, intentional compaction, 무엇을 compact하는가 | 대화가 길어질수록 좋아지는 것이 아니라 context 품질이 중요 |
| 04:38-07:26 | context window, dumb zone, sub-agent와 compaction | 40-60% 근처의 context 운영 discipline |
| 07:26-09:37 | frequent intentional compaction과 research-plan-implement | 작업 단계를 context 단위로 분리하는 workflow |
| 09:37-12:14 | 복잡한 문제의 한계, semantic diffusion, context engineering 재정의 | agent 용어의 혼란과 context engineering의 범위 정리 |
| 12:14-15:03 | onboarding docs, progressive disclosure, on-demand compressed context | “항상 최신 internal docs”보다 필요 시 압축되는 맥락 |
| 15:03-17:38 | mental alignment, plan에 code snippet 포함, reliability/readability tradeoff | 리뷰의 중심을 코드 전체가 아니라 의도와 계획으로 이동 |
| 17:38-20:31 | thinking을 아웃소싱하지 말 것, RPI라는 약어의 함정, 조직 변화 | 도구보다 반복 훈련과 문화적 채택이 어렵다 |
문제는 “AI가 코드를 더 쓰는가”가 아니다
발표의 출발점은 불편한 데이터다. 설명란과 companion 글은 AI 도구가 더 많은 코드를 만들지만 그 상당 부분이 rework와 churn으로 돌아올 수 있다는 Stanford/Yegor 발표를 배경으로 삼는다. 영상의 첫 슬라이드도 같은 문제를 보여 준다. 새 프로젝트나 작은 변경에는 AI 코딩 도구가 잘 맞지만, 오래된 Java, Rust, Go, C++ 코드베이스처럼 맥락이 두껍고 암묵지가 많은 환경에서는 결과가 쉽게 slop factory가 된다.
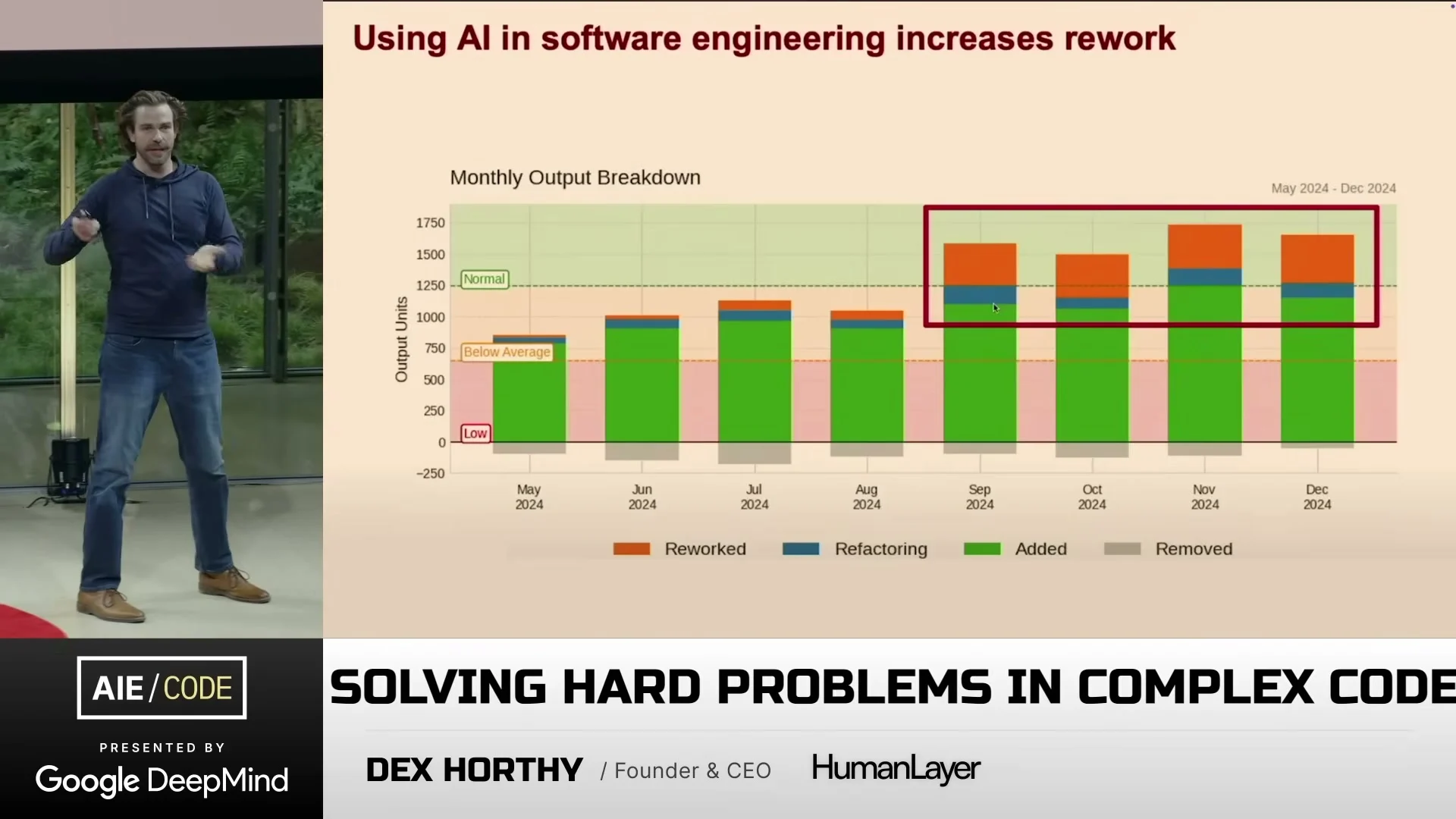
이 프레이밍이 중요한 이유는 해결책의 방향을 바꾸기 때문이다. 문제가 “모델이 아직 충분히 똑똑하지 않다”라면 기다리는 수밖에 없다. 하지만 문제가 “모델이 보는 context가 엉망이다”라면 오늘 당장 바꿀 수 있는 설계 영역이 생긴다. 어떤 파일을 읽히는가, 어떤 테스트 결과를 유지하는가, 대화가 길어질 때 무엇을 compact하는가, plan을 얼마나 구체적으로 쓰는가가 모두 성능 변수가 된다.
Dex는 여기서 “context engineering”을 단순히 prompt를 잘 쓰는 일이 아니라, 개발 workflow 전체를 context window 중심으로 재설계하는 일로 확장한다. 이는 LLM 앱 개발에서 흔히 말하는 RAG나 시스템 프롬프트 튜닝보다 훨씬 운영적인 의미다.
Context window는 오래 쓸수록 좋아지는 저장소가 아니다
발표 중반의 핵심 명제는 LLM이 stateless라는 사실이다. 모델은 이전 실행의 내부 상태를 유지하지 않는다. 매번 더 좋은 tokens를 넣어야 더 좋은 tokens가 나온다. 그래서 coding agent의 context window는 “길게 쌓을수록 현명해지는 작업 기억”이라기보다, 계속 정리하지 않으면 성능을 갉아먹는 작업 공간에 가깝다.

여기서 등장하는 표현이 “dumb zone”이다. Claude Code를 예로 들면 168k token 정도의 context window가 있지만, 그 전체를 다 채우는 것이 목표가 아니다. 발표에서는 대략 40% 선부터 task에 따라 diminishing returns가 나타나고, 60%를 넘으면 compaction이 일어나며, 이후에는 도구 사용과 reasoning 품질이 불안정해질 수 있다고 설명한다. 숫자는 모델과 환경마다 다르지만, 핵심은 분명하다. context utilization은 관리 대상이지 많이 쓸수록 좋은 점수가 아니다.
이를 software engineering 관점으로 바꾸면, coding agent 운영은 memory management 문제이기도 하다. 사람이 IDE에서 쓸모없는 탭을 닫고, 로그를 정리하고, 이슈 설명을 업데이트하듯이, agent에게 들어가는 맥락도 계속 가공되어야 한다.
Intentional compaction: “대화 요약”이 아니라 실패 지점을 보존하는 일
대부분의 사용자는 대화가 길어지면 자연스럽게 요약을 시도한다. 하지만 발표가 말하는 intentional compaction은 단순 요약이 아니다. 지금까지 무엇을 시도했고, 무엇이 실패했고, 현재 어떤 approach를 검증 중이며, 어떤 파일과 테스트가 관련되는지를 다음 단계에서 쓸 수 있게 재구성하는 일이다.
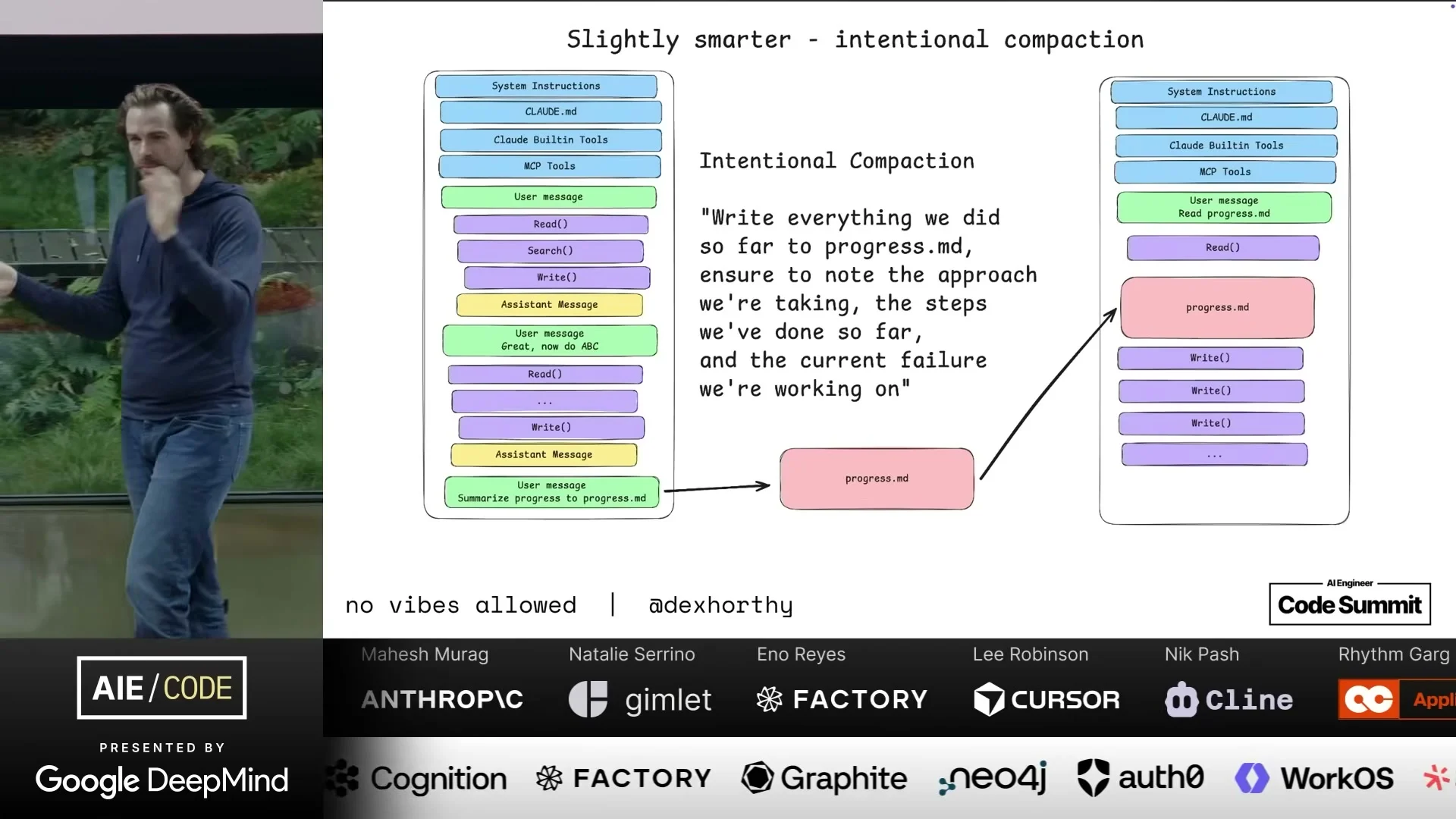
compaction의 대상은 다양하다. 찾아본 파일, 이해한 code flow, 실제 편집 내용, test/build output, JSON tool response, 실패한 시도와 현재 working hypothesis가 모두 포함된다. 중요한 것은 이 정보를 다 남기는 것이 아니라, 다음 agent loop가 바로 이어 받을 수 있는 형태로 남기는 것이다.
이 관점에서 “잘 요약해 줘”는 너무 약한 명령이다. 좋은 compaction은 무엇을 버릴지와 무엇을 보존할지를 정한다. 특히 실패 경로를 버리면 agent는 같은 실수를 반복한다. 반대로 불필요한 로그와 장황한 대화를 다 넣으면 dumb zone으로 간다. context engineering은 이 tradeoff를 다루는 기술이다.
Frequent intentional compaction과 RPI workflow
Dex가 제안하는 실전 패턴은 frequent intentional compaction이다. 한 번의 거대한 Claude Code 세션 안에서 모든 것을 해결하려 하지 않고, research, plan, implement 같은 단계로 context를 나누며 의도적으로 압축한다. 발표에서는 사람들이 이 흐름을 RPI라고 부르기 시작했지만, 그는 약어 자체보다 “context를 작게 유지하며 단계별로 고품질 토큰을 넣는 것”이 중요하다고 강조한다.

이 workflow는 다음처럼 해석할 수 있다.
| 단계 | Agent에게 맡기는 일 | 사람이 확인해야 하는 것 |
|---|---|---|
| Research | 관련 파일, 기존 패턴, 실패 가능성, 테스트 표면 조사 | agent가 문제 공간을 제대로 이해했는가 |
| Plan | 변경 파일, 라인, 코드 snippet, 테스트 단계로 구현 계획 작성 | 계획이 팀의 의도와 mental model에 맞는가 |
| Implement | plan에 따라 작은 단위로 코드 수정과 테스트 실행 | 계획에서 벗어난 변경이나 품질 저하가 없는가 |
| Compact | 다음 단계가 필요한 경우 실패/성공/의사결정을 압축 | 다음 context window에 무엇을 남길 것인가 |
핵심은 plan이 사람을 배제하는 문서가 아니라, 사람이 leverage를 얻는 인터페이스라는 점이다. 계획이 너무 짧으면 실행 신뢰도가 떨어지고, 너무 길면 사람이 읽지 않는다. 좋은 plan은 intent를 압축하면서도 실행 가능성을 충분히 높이는 중간 지점을 찾아야 한다.
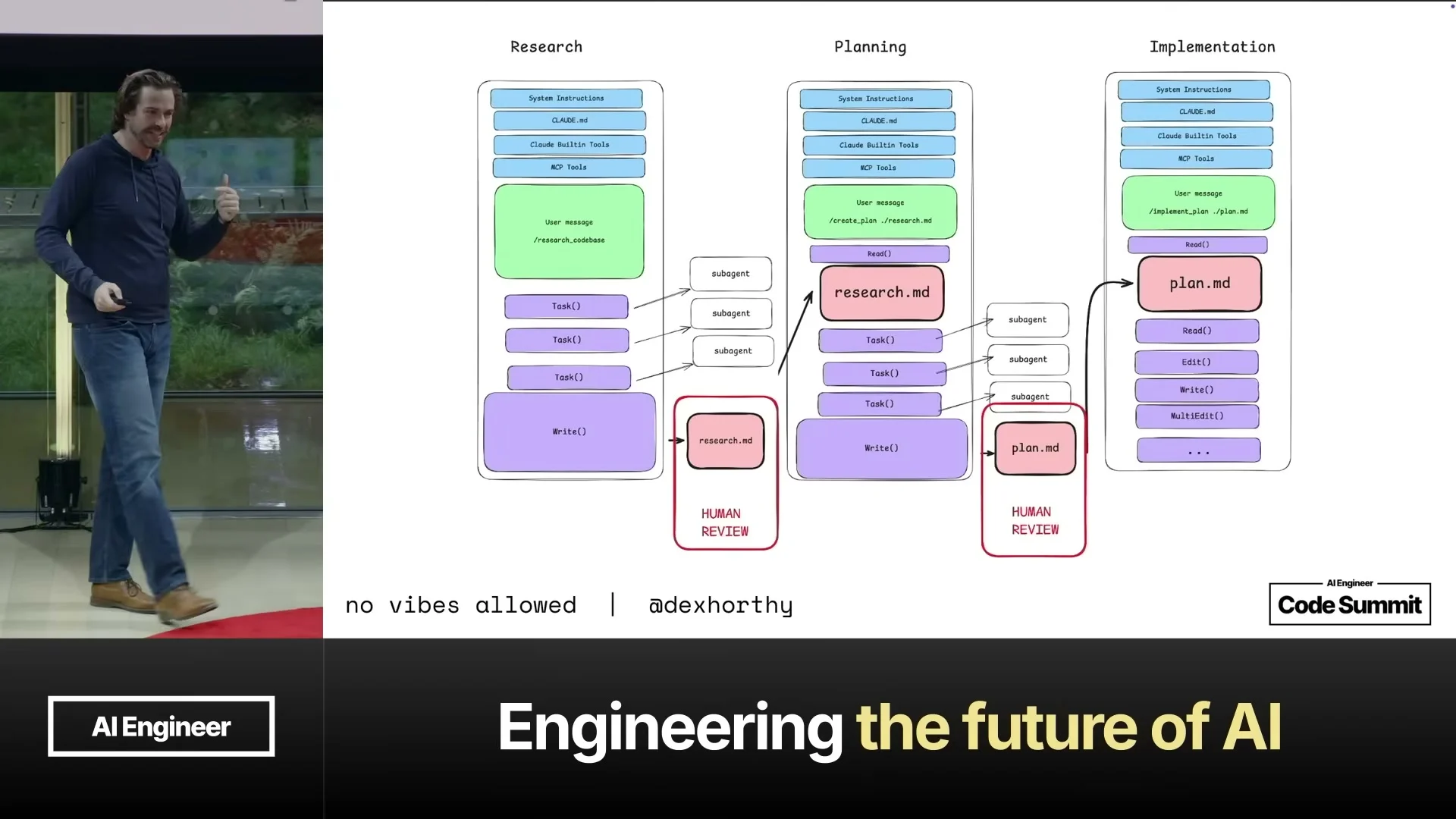
Internal docs는 빨리 거짓말을 한다
발표 후반의 좋은 지점은 “문서를 더 많이 쓰자”에서 멈추지 않는다는 것이다. Dex는 onboarding 정보를 모든 repo에 넣는 접근을 설명한 뒤, internal docs가 시간이 지나면 얼마나 쉽게 거짓말을 하는지 지적한다. 실제 코드베이스는 계속 변하고, 팀은 바쁘고, 문서 업데이트는 항상 뒤로 밀린다.
그래서 더 선호하는 방식은 on-demand compressed context다. 예를 들어 SCM provider와 Jira integration 관련 기능을 만들고 있다면, 그 순간 필요한 코드 경로와 팀 지식을 agent가 조사하고 압축해 작업 context로 가져오는 방식이다. 모든 것을 항상 최신 문서로 유지하려 하기보다, 작업 시점에 필요한 맥락을 재구성한다.

이 관점은 최근 agent skills, repo-local memory, codebase map, semantic search, MCP 기반 tool access와도 연결된다. 다만 Dex의 강조점은 “도구가 알아서 해 준다”가 아니다. 필요한 순간에 필요한 context를 만들 수 있도록 codebase와 workflow를 설계하자는 쪽에 가깝다.
코드 리뷰의 중심이 “모든 diff 읽기”에서 “mental alignment”로 이동한다
가장 실무적인 대목은 code review에 대한 해석이다. AI가 1000줄, 2000줄짜리 변경을 자주 만들면, 사람이 모든 줄을 같은 깊이로 읽는 방식은 금방 지속 불가능해진다. 그렇다고 리뷰를 포기할 수는 없다. Dex는 code review의 hierarchy에서 가장 아래에 mental alignment를 둔다. 팀이 codebase가 어떻게 변하고 왜 변하는지 같은 그림을 공유하는 것이 바닥이라는 뜻이다.
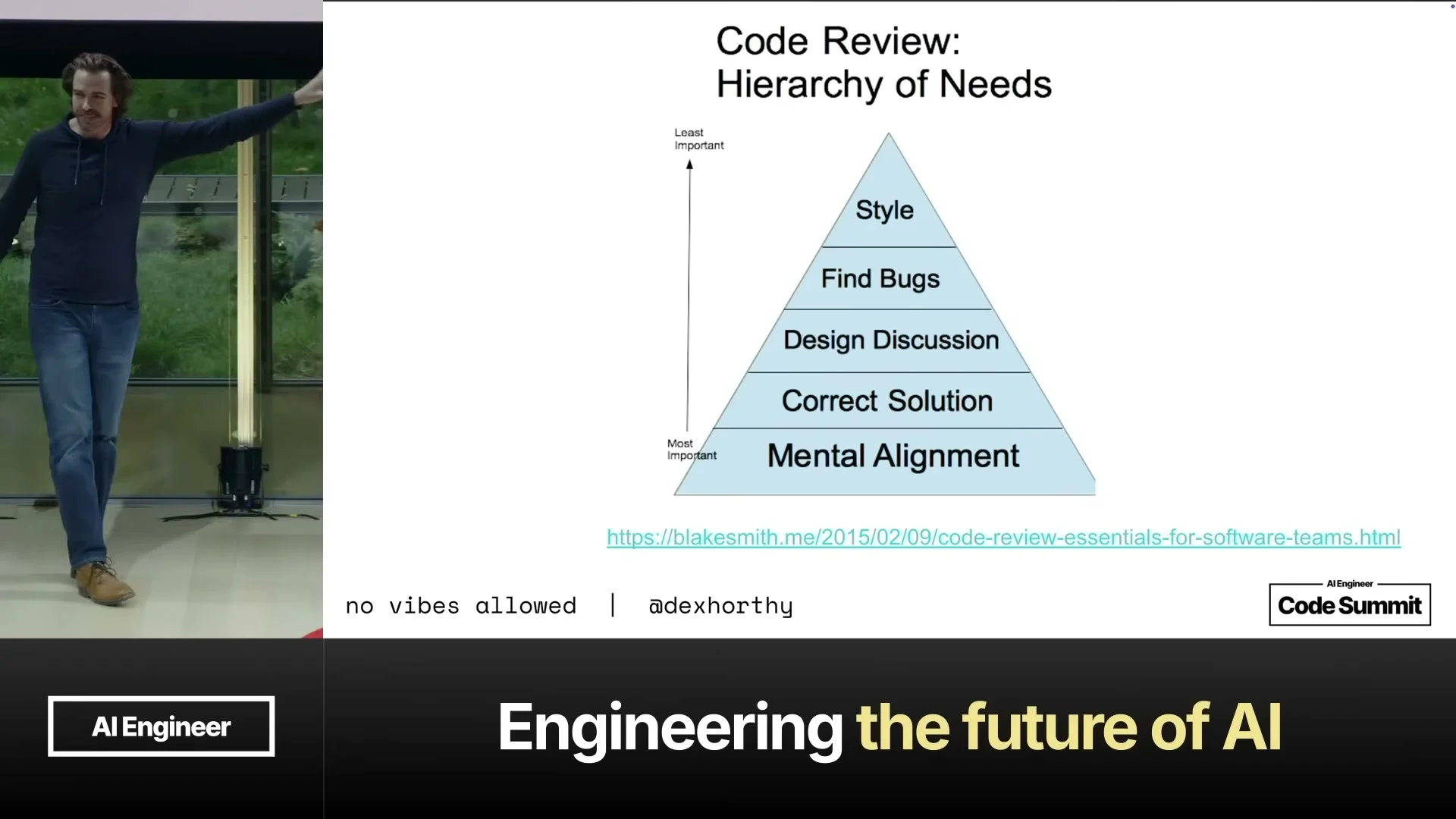
이때 plan과 spec이 중요해진다. Companion 글도 Sean Grove의 “Specs are the new code” 관점을 언급한다. 최종 코드만 커밋하고 prompts와 의사결정 과정을 버리면, 팀은 왜 그런 코드가 나왔는지 추적하기 어렵다. 반대로 spec과 plan이 source of truth가 되면, 리뷰어는 전체 diff를 무작정 읽기보다 “의도, 경계, 테스트, 리스크”를 중심으로 검토할 수 있다.
물론 이것은 코드 리뷰를 없애자는 말이 아니다. 오히려 리뷰 대상이 바뀐다는 뜻이다. 테스트는 여전히 중요하고, 중요한 구현 세부는 여전히 봐야 한다. 하지만 AI 코딩이 늘어날수록 사람의 가장 큰 leverage는 모든 줄을 수작업으로 읽는 데서 나오지 않는다. 계획의 품질, 테스트 표면, 변경 의도, 실패 시 복구 가능성을 보는 데서 나온다.
“Don’t outsource the thinking”이 결론이다
발표 제목은 “No Vibes Allowed”지만, 실제 결론은 더 차분하다. Dex는 RPI나 context engineering을 또 하나의 silver bullet prompt로 팔지 않는다. 오히려 “Don’t outsource the thinking”이라고 말한다. 많은 markdown 파일을 뿜어내 사용자를 안심시키는 도구를 경계하고, 때로는 전체 research-plan-implement가 과하다고 말한다.

이 말은 AI 코딩 도구를 덜 쓰자는 뜻이 아니다. 오히려 제대로 쓰려면 사람이 더 명확하게 생각해야 한다는 뜻이다. 어떤 문제는 full RPI가 필요하고, 어떤 문제는 짧은 plan만 있으면 된다. 어떤 변경은 agent에게 맡겨도 되지만, 어떤 변경은 architecture decision을 먼저 사람이 정리해야 한다. context engineering은 이 경계를 판단하는 기술까지 포함한다.
영상과 companion source에서 확인되는 점
공개 자료에서 확인되는 주요 사실은 다음과 같다.
| 확인 지점 | 공개 자료에서 보이는 내용 | 해석 |
|---|---|---|
| YouTube metadata | No Vibes Allowed, Dex Horthy, HumanLayer, AI Engineer, 2025-12-02 업로드, 약 20분 31초 |
HumanLayer의 advanced context engineering 관점을 짧은 컨퍼런스 발표로 정리 |
| 공식 chapters | intro, context engineering, dumb zone, context management, semantic diffusion, mental alignment, RPI 등 15개 구간 | 영상 자체가 context engineering 실무 패턴을 단계적으로 설명 |
| 영상 설명란 | 300k LOC Rust codebase, 일주일치 작업을 하루에 처리, expert review 통과, frequent intentional compaction 언급 | 정량 benchmark라기보다 HumanLayer 팀의 workflow 경험담으로 읽어야 함 |
| companion 글 | Getting AI to Work in Complex Codebases는 같은 문제의식과 research-plan-implement workflow를 더 길게 설명 |
영상의 짧은 슬라이드를 보완하는 1차 텍스트 자료 |
| 12 Factor Agents | production-grade LLM/agent software를 위한 원칙 모음 | Dex의 context engineering 논의가 단발성 팁이 아니라 agent 시스템 설계 철학과 연결 |
주의할 점도 있다. 영상과 companion 글의 성과 사례는 흥미롭지만, 독립 재현 가능한 benchmark라기보다 특정 팀과 코드베이스에서 얻은 workflow 경험에 가깝다. “Claude Code가 300k LOC Rust codebase를 처리했다”는 말은 가능성의 신호이지, 모든 brownfield codebase에서 같은 효과가 난다는 보장은 아니다. 실제 조직에서는 테스트 품질, reviewer 역량, codebase 구조, CI 속도, domain knowledge 접근성에 따라 결과가 크게 달라질 것이다.
실무 관점에서의 해석
이 발표가 좋은 이유는 AI 코딩을 “프롬프트 잘 쓰기”보다 높은 수준에서 다루기 때문이다. 복잡한 코드베이스에서 중요한 것은 한 번의 prompt가 아니라, agent가 문제를 이해하고, 계획하고, 실행하고, 실패를 압축해 다음 단계로 넘기는 전체 공급망이다. 이 공급망을 설계하지 않으면 모델이 만든 코드는 많아져도 팀의 mental alignment는 약해질 수 있다.
특히 팀 리더에게 주는 메시지가 크다. AI 코딩 도구 도입은 개인 생산성 실험에서 끝나지 않는다. spec이 어디에 남는지, plan을 누가 읽는지, PR 리뷰가 어떤 기준을 보는지, agent가 실패한 정보를 어디에 압축하는지, stale internal docs를 어떻게 피하는지 같은 운영 규칙이 필요하다. 이 규칙이 없으면 팀은 “AI를 쓰고 있다”는 사실만 공유하고, 실제 작업 방식은 각자 다르게 흩어진다.
또 하나의 시사점은 context engineering이 skill과 memory의 중간 영역이라는 점이다. 모든 것을 영구 메모리에 넣는 것도 아니고, 매번 처음부터 설명하는 것도 아니다. 반복되는 절차는 skill로, 특정 작업의 조사 결과는 plan으로, 현재 실행 상태는 compacted context로 남긴다. 이 구분이 명확해질수록 agent는 더 안정적으로 긴 작업을 수행할 수 있다.
결론: No vibes는 더 많은 형식이 아니라 더 좋은 압축이다
“vibe coding”의 문제는 AI를 쓴다는 사실 자체가 아니다. 문제는 의도, 근거, 실패 경로, 테스트 계획, 팀의 mental model을 저장하지 않은 채 최종 코드만 남기는 방식이다. Dex의 발표가 말하는 no vibes는 감을 버리자는 말이 아니라, 감으로 흘러가는 정보를 spec, plan, compacted context, review 기준으로 바꾸자는 말에 가깝다.
따라서 이 영상의 실천적 결론은 단순하다. 복잡한 코드베이스에서 AI 코딩을 진지하게 쓰려면, agent에게 더 큰 일을 시키기 전에 context window를 어떻게 먹일지부터 설계해야 한다. 좋은 파일 검색, 정확한 테스트 출력, 실패한 시도의 보존, 짧고 구체적인 plan, 단계 사이의 intentional compaction, 그리고 사람이 thinking을 놓지 않는 리뷰 문화가 필요하다.
결국 AI 코딩의 다음 병목은 모델 API가 아니라 팀의 작업 기억이다. 그 작업 기억을 무작정 길게 쌓는 대신, 필요한 순간에 필요한 형태로 압축해 공급하는 팀이 더 멀리 갈 것이다.