로컬 LLM 이야기는 오랫동안 Mac Studio나 RTX 데스크톱 같은 “개인용 서버” 이미지에 가까웠다.
하지만 Apple Silicon 세대가 쌓이면서 질문이 조금 바뀌고 있다.
“내 노트북에서 돌릴 수 있는가”를 넘어, 이제는 iPhone에서 충분히 빠르게 돌아가는가가 실제 제품 질문이 된다.
사용자가 항상 들고 다니는 디바이스에서 네트워크 없이, 로그인 없이, 개인 데이터를 밖으로 보내지 않고, 몇 초 안에 답하는 모델이 가능하다면 로컬 AI의 의미는 훨씬 넓어진다.
AI Engineer 채널의 **Running LLMs on your iPhone: 40 tok/s Gemma 4 with MLX — Adrien Grondin, Locally AI**는 그 전환을 짧게 보여 주는 발표다.
Locally AI의 Adrien Grondin은 Gemma 4를 MLX 기반으로 iPhone에서 실행하는 데모를 보여 주고, 개발자가 같은 흐름을 앱에 붙일 때 어떤 조합을 쓰면 되는지 설명한다.
핵심 구성은 단순하다.
Apple의 MLX, Swift 앱용 MLX Swift LM, Hugging Face의 MLX Community weights, 그리고 사용자-facing 앱인 Locally AI다.
내가 보기에는 이 영상의 메시지는 “iPhone에서도 LLM이 돌아간다”보다 조금 더 구체적이다.
온디바이스 LLM 제품의 병목이 모델 자체에서 패키징·양자화·모델 유통·네이티브 앱 통합으로 이동하고 있다는 점이 중요하다.
모델이 공개되는 것만으로는 부족하고, 그 모델이 4-bit/6-bit/8-bit로 변환되어 Hugging Face에 올라오고, Swift 패키지에서 model id만으로 내려받아 실행되고, 사용자는 App Store 앱에서 바로 테스트할 수 있어야 한다.
무엇을 다루는 영상인가
YouTube metadata 기준 영상은 AI Engineer 채널에 2026-04-20 업로드된 약 10분 50초짜리 발표다.
공식 chapter는 없지만, transcript 흐름은 꽤 명확하다.
초반에는 Locally AI와 MLX를 소개하고, 중반에는 MLX Swift LM과 Hugging Face MLX Community에서 모델을 가져오는 흐름을 설명하며, 후반에는 Gemma 4의 40 tok/s 데모와 LM Studio 연결, tool calling 지원 질문으로 이어진다.
이 글은 영상 transcript, 화면에서 추출한 발표 프레임, 그리고 MLX/MLX Swift LM/MLX LM/MLX Community/Locally AI 공개 자료를 함께 기준으로 삼았다.
| 구간 | 발표 내용 | 글에서 보는 포인트 |
|---|---|---|
| 00:14-01:22 | Locally AI 소개, Gemma 4를 iPhone에서 MLX로 실행 | 온디바이스 LLM이 더 이상 연구 데모가 아니라 앱 경험으로 포장됨 |
| 01:22-02:35 | Apple MLX와 MLX Swift LM, iPhone/iPad/Mac 지원 | 개발자 통합면은 Swift package + model download API로 단순화됨 |
| 02:35-03:50 | MLX VLM/audio/video와 Hugging Face MLX Community | 텍스트 모델만이 아니라 Apple Silicon용 MLX 생태계가 커지는 중 |
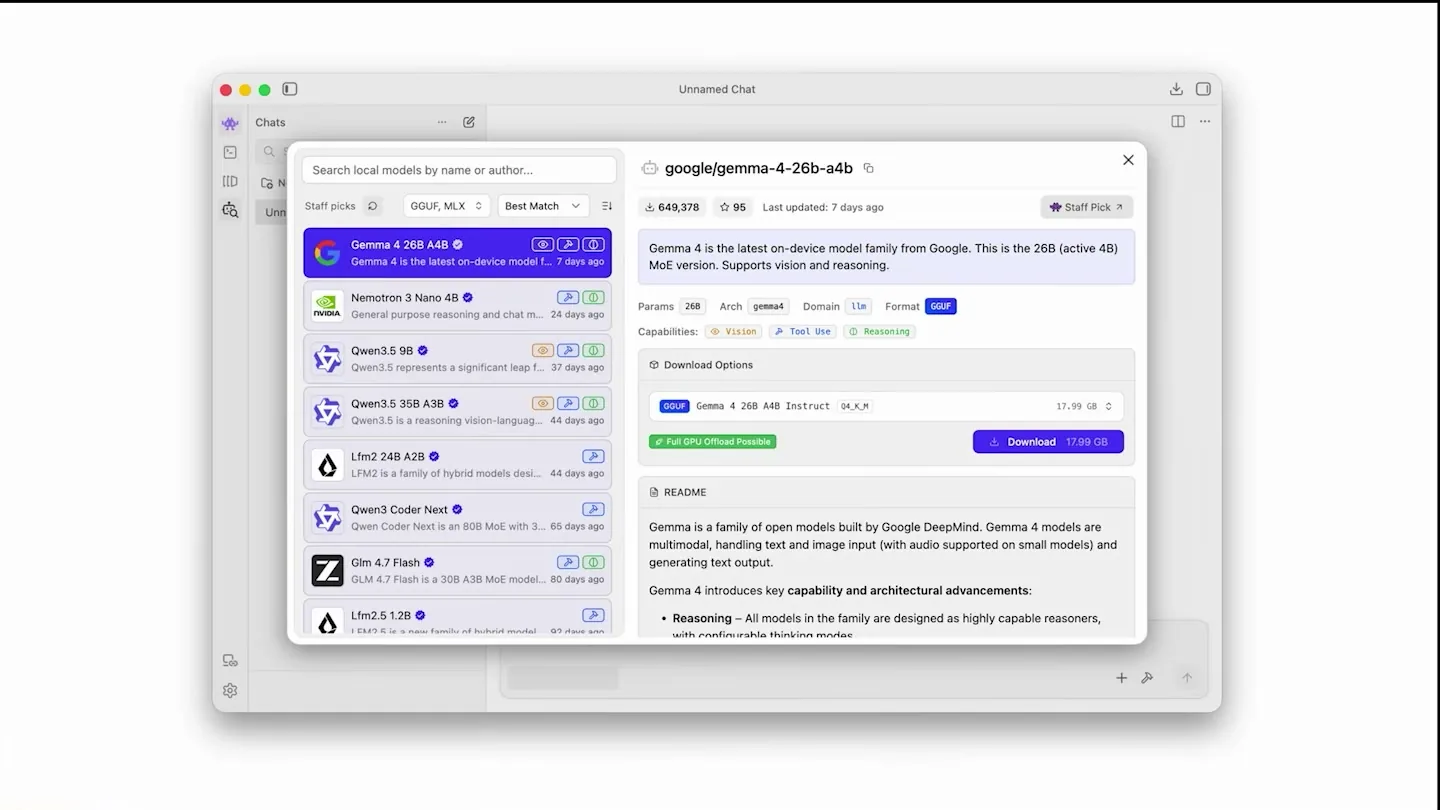
| 03:50-04:40 | Gemma 4 variants와 model id 기반 다운로드 | 모델 유통은 “repo를 직접 변환”보다 pre-converted weights 선택으로 이동 |
| 04:40-05:34 | 4-bit/6-bit/8-bit 양자화 선택 | 모바일에서는 모델 크기와 품질 사이의 제품적 선택이 중요 |
| 05:39-07:18 | iPhone에서 40 tok/s 수준의 offline streaming demo | 로컬 LLM의 사용성 기준은 “돌아간다”가 아니라 체감 응답성 |
| 07:18-08:45 | App Store, Locally의 LM Studio 인수, local server와 response type | 모바일 앱과 데스크톱 로컬 서버가 하나의 로컬 AI 스택으로 연결 |
| 09:02-10:29 | tool calling, repo와 앱의 차이 | 개발자는 MLX Swift LM, 일반 사용자는 Locally app이라는 이중 표면 |
Locally AI는 “로컬 LLM”을 앱 경험으로 바꾼다
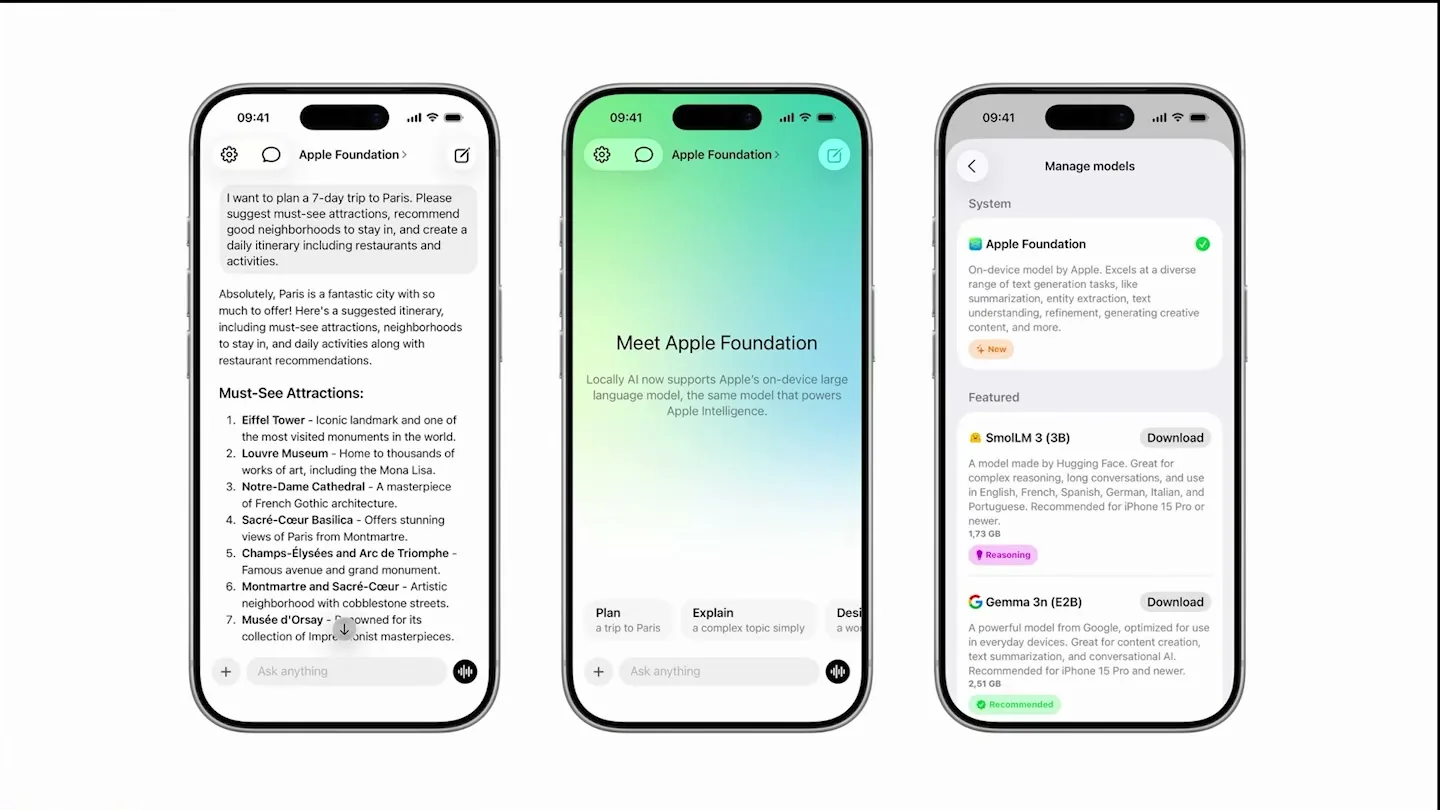
발표는 Locally AI 소개로 시작한다.
Locally AI는 iPhone, iPad, Mac에서 모델을 로컬로 실행하는 네이티브 챗봇 앱이고, 발표자는 Apple Foundation model과 MLX 호환 모델을 함께 다룰 수 있다고 설명한다.
Locally AI 사이트 역시 “offline”, “private and secure”, “Apple Silicon optimized”를 전면에 둔다.
즉 이 앱의 포지셔닝은 단순한 모델 플레이그라운드가 아니라, 사용자가 개인 기기에서 바로 쓸 수 있는 로컬 AI assistant다.
이 지점이 꽤 중요하다.
로컬 LLM을 개발자 도구로만 보면 설치, 모델 변환, quantization, prompt format, tokenizer, UI를 모두 사용자가 알아서 해결해야 한다.
반대로 Locally 같은 앱은 그 복잡도를 앱 내부로 숨긴다.
사용자는 모델을 선택하고 다운로드한 뒤 대화하면 된다.
영상 후반 Q&A에서 발표자가 “일반 사용자는 App Store에서 앱을 받아 쓰면 된다”고 답한 것도 이 차이를 잘 보여 준다.
물론 완전히 마찰이 사라지는 것은 아니다.
발표자는 모델 다운로드가 보통 1GB에서 3GB 정도가 될 수 있고, 이 모델 크기가 현재 가장 큰 barrier라고 말한다.
온디바이스 AI에서 병목은 종종 GPU 서버 비용이 아니라 저장공간, 다운로드 시간, 첫 실행 경험, 발열과 배터리 같은 모바일 제품 변수로 바뀐다.
개발자 표면: MLX Swift LM + Hugging Face model id
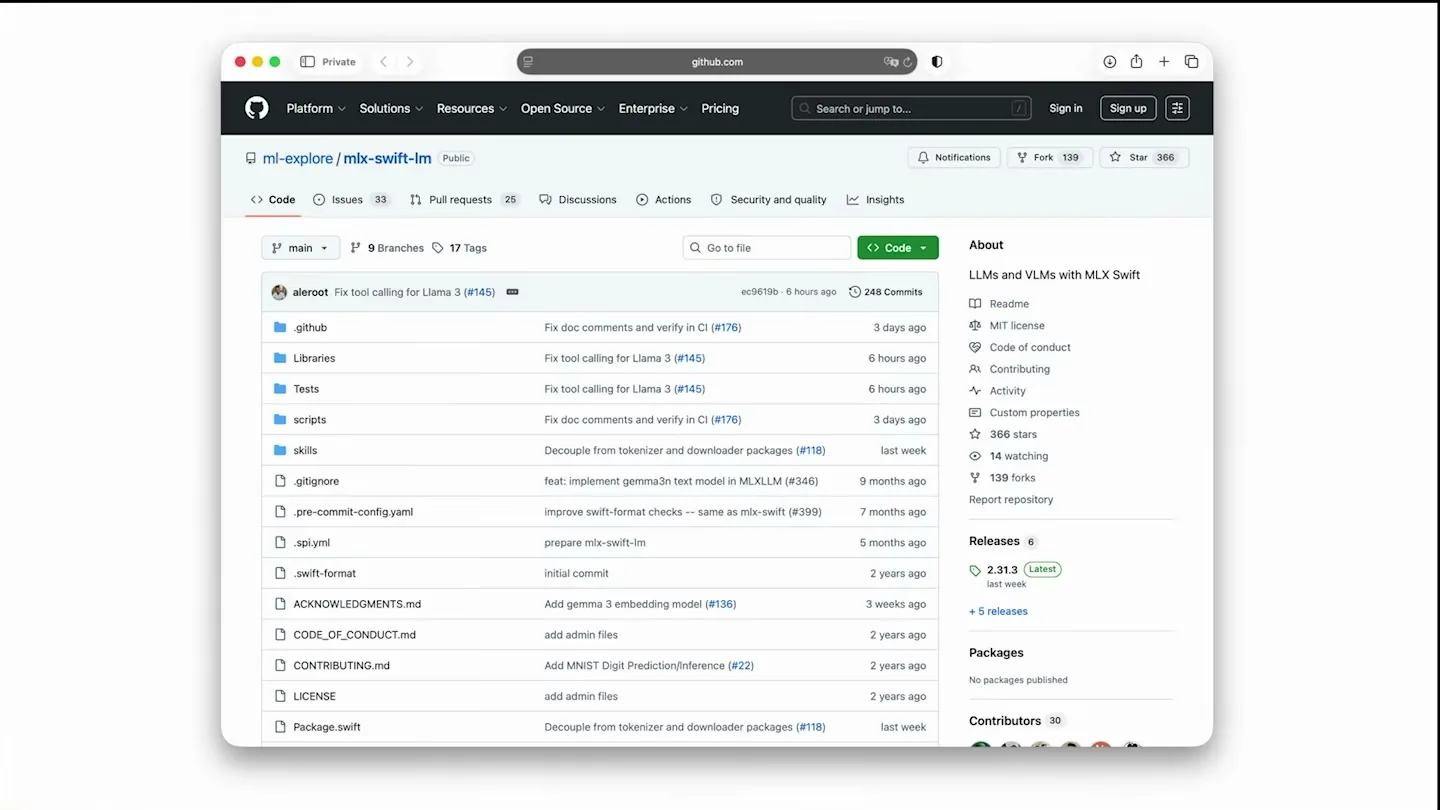
개발자 관점에서 발표의 핵심은 MLX Swift LM이다.
Adrien은 iOS, iPadOS, macOS 앱을 만들고 싶다면 ml-explore/mlx-swift-lm repo를 보면 된다고 설명한다.
이 패키지는 공식 README 기준으로 MLX Swift 위에서 LLM과 VLM을 사용하는 Swift package이며, 앱과 도구를 만들기 위한 모델 로딩·생성 계층을 제공한다.
여기서 사용성의 핵심은 “model id를 넘긴다”는 부분이다.
예전 로컬 모델 통합은 weight format 변환, tokenizer 호환성, chat template, runtime-specific 옵션을 직접 맞춰야 했다.
MLX Swift LM이 Hugging Face download/tokenizer integration을 갖추고, Hugging Face 쪽에 이미 변환된 MLX weight가 있다면, 앱 개발자는 더 높은 수준의 API에서 시작할 수 있다.
발표자는 “10분 안에 iOS 앱에서 모델을 돌릴 수 있다”고 표현한다.
물론 실제 제품에서는 cache 관리, 모델 선택 UI, memory pressure 대응, interruption, background task, streaming UI, safety UX 같은 일이 남는다.
그래도 중요한 것은 first runnable path가 짧아졌다는 점이다.
로컬 LLM이 “연구자가 터미널에서 돌리는 것”에서 “앱 개발자가 Swift package로 붙이는 것”으로 내려오고 있다.
MLX Community는 Apple Silicon용 모델 유통 계층이다
MLX 자체는 Apple Silicon에 최적화된 array framework다. mlx-lm은 Apple silicon에서 LLM text generation과 fine-tuning을 다루는 Python package이고, Hugging Face Hub와의 통합, quantization/upload, LoRA/full fine-tuning 같은 기능을 제공한다.
Swift 앱 쪽에서는 MLX Swift LM이 같은 방향의 product surface가 된다.
하지만 runtime만 있어서는 부족하다.
모바일/로컬 앱이 바로 쓸 수 있는 weights가 필요하다.
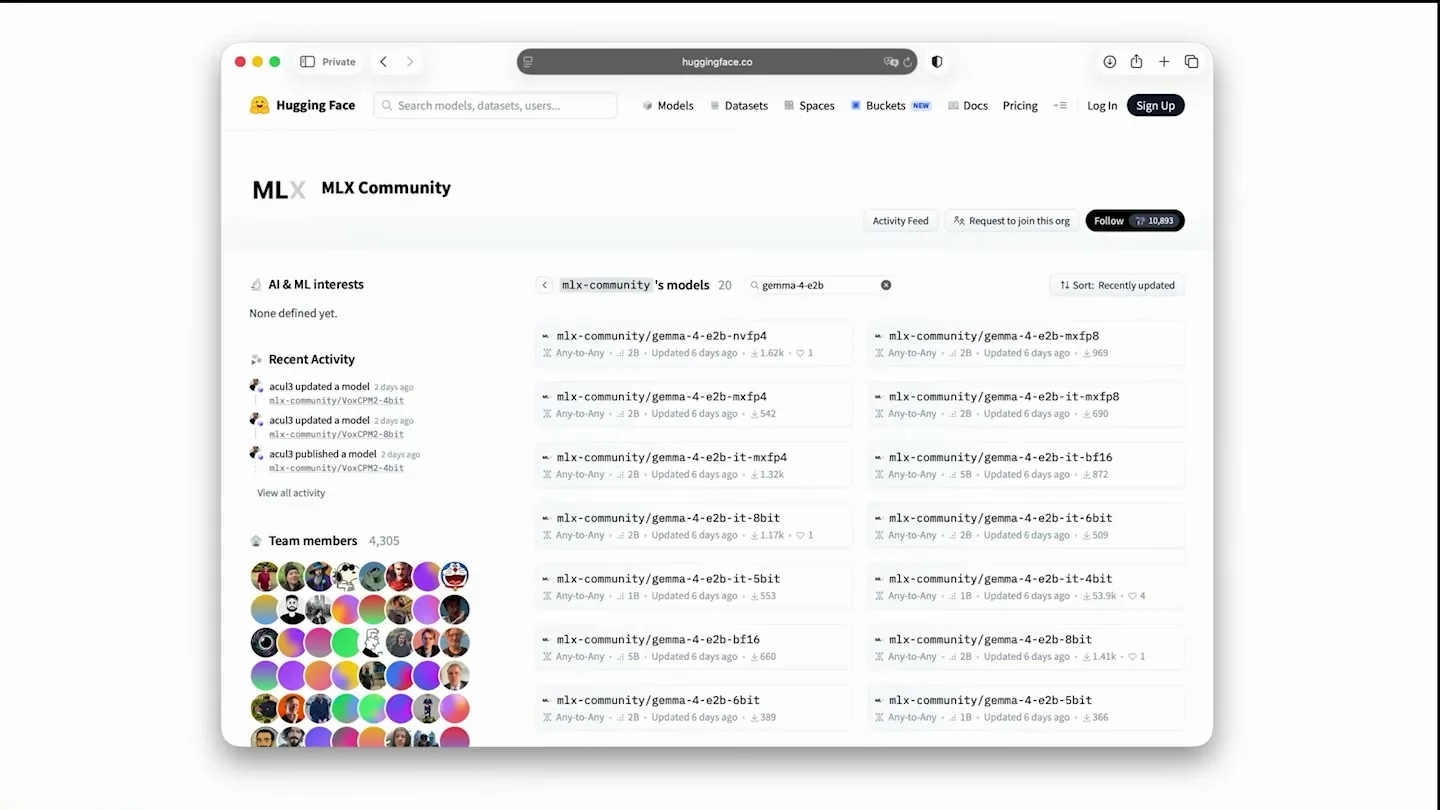
발표자가 추천하는 장소는 Hugging Face의 MLX Community다.
공개 org card 기준 MLX Community는 Apple Silicon에서 돌아가는 MLX model weights를 모아 두고, mlx-lm, mlx-swift-examples, mlx-vlm, mlx-audio와 호환되는 ready-to-use 모델을 제공한다.
이 구조는 온디바이스 AI에서 생각보다 큰 의미가 있다. foundation model release만으로는 iPhone 앱이 바로 좋아지지 않는다.
실제 제품에서는 다음 파이프라인이 필요하다.
| 계층 | 역할 | 온디바이스 제품에서 중요한 이유 |
|---|---|---|
| Base model | Gemma 4, Qwen, SmolLM 같은 open model family | 품질과 모델 크기의 출발점 |
| MLX conversion | Apple Silicon에서 효율적으로 실행 가능한 weight format | iPhone/Mac GPU와 unified memory를 활용하기 위한 전제 |
| Quantization | 4-bit, 6-bit, 8-bit 등 크기/품질 trade-off | 다운로드 크기, RAM, 속도, 품질의 균형을 결정 |
| Distribution | Hugging Face MLX Community 같은 모델 허브 | 앱이 model id 기반으로 쉽게 모델을 가져올 수 있음 |
| Runtime/API | MLX Swift LM, MLX LM, MLX VLM/audio 등 | 앱과 도구가 모델을 호출하는 표준 표면 |
| Product UI | Locally AI, LM Studio 같은 사용자 앱 | 비전문가도 로컬 모델을 실제로 쓰게 만드는 계층 |
즉 이 생태계의 경쟁력은 특정 모델 하나가 아니라, 모델이 나온 뒤 모바일 앱에 도달하기까지의 시간과 마찰에 있다.
발표자가 “새 모델이 나오면 거의 30분 뒤에 quantized weight가 올라온다”는 취지로 말한 부분은 과장이 섞여 있을 수 있어도, 방향성은 분명하다.
커뮤니티 변환과 유통 속도가 로컬 AI 생태계의 체감 속도를 좌우한다.
4-bit, 6-bit, 8-bit: 모바일 LLM의 제품적 선택
영상에서 가장 실용적인 조언은 quantization 범위다.
발표자는 iPhone에서 모델을 실행하려면 full-size weight는 너무 크기 때문에 quantized variant를 골라야 하고, 보통 4-bit에서 8-bit 사이를 추천한다고 말한다.
4-bit 아래로 내려가면 output 품질 영향이 커지기 시작하고, 8-bit는 작은 모델에서 더 안전한 선택지가 된다.

이 조언은 “무조건 4-bit가 좋다”와 다르다.
데모에서는 Gemma 4 같은 비교적 큰 모델을 iPhone에서 돌리려면 aggressive quantization이 필요하지만, 아주 작은 모델은 8-bit로도 충분히 빠를 수 있다.
반대로 3-bit 이하로 가면 모델마다 품질 저하가 체감될 수 있다.
사용자가 기대하는 작업이 simple text processing인지, 긴 질의응답인지, tool calling인지, 한국어 대화인지에 따라 최적점은 달라진다.
흥미로운 점은 발표자가 300M~350M parameter급 작은 모델도 언급한다는 것이다.
이런 모델은 shortcuts 자동화나 간단한 텍스트 처리처럼 latency가 더 중요한 작업에 적합할 수 있다.
앞으로 온디바이스 AI 앱은 하나의 큰 모델을 모든 작업에 쓰기보다, 작업별로 작은 모델과 큰 모델을 섞는 방향으로 갈 가능성이 높다.
40 tok/s 데모가 보여 주는 것
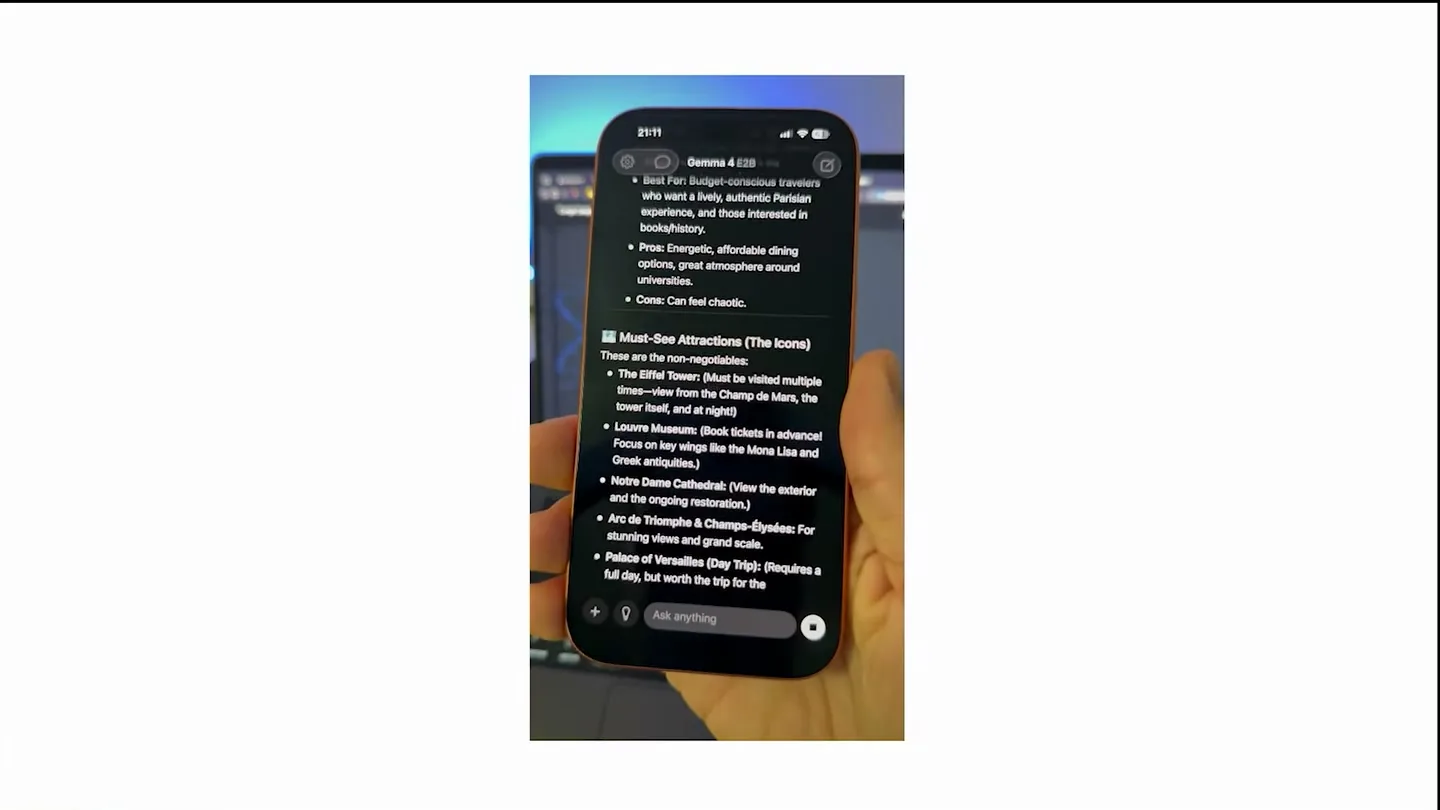
영상의 headline은 iPhone에서 Gemma 4가 40 tok/s 수준으로 streaming된다는 주장이다.
발표자는 최신 iPhone에서 4-bit quantized Gemma 4를 실행하면 약 40 tokens per second가 가능하고, 오래된 iPhone에서도 20 tok/s 정도면 많은 use case에서 충분히 유용하다고 말한다.
여기서 조심해야 할 점도 있다.
영상은 conference demo이며, 재현 가능한 benchmark table이나 기기별 모델별 latency 표를 제공하지는 않는다.
40 tok/s가 어떤 iPhone 세대, 어떤 정확한 Gemma 4 variant, 어떤 prompt 길이, 어떤 thermal 상태에서 측정됐는지는 영상만으로 완전히 독립 검증하기 어렵다.
따라서 이 수치를 제품 의사결정에 쓰려면, 팀의 target device와 target prompt에서 다시 측정해야 한다.
그럼에도 데모의 의미는 충분하다.
사용자가 채팅 앱에서 느끼는 속도는 tokens-per-second 하나만으로 결정되지 않는다.
첫 토큰 지연, streaming UI, 모델 로딩 시간, 메모리 압박, 배터리, 발열, 다운로드 크기가 함께 작동한다.
그런데 20~40 tok/s 범위의 streaming이 가능해지면, 적어도 짧은 질의응답과 로컬 자동화에서는 “클라우드가 아니면 답답하다”는 전제가 약해진다.
Locally와 LM Studio: 모바일 앱과 로컬 서버가 만나는 지점
발표 후반에서 흥미로운 소식은 Locally가 LM Studio에 인수되었다는 언급이다.
LM Studio는 Mac/PC에서 로컬 모델을 다운로드하고 실행하며, local server를 열어 앱이 OpenAI-compatible 형태로 붙을 수 있게 해 주는 도구로 널리 쓰인다.
Adrien은 LM Studio가 Llama.cpp뿐 아니라 MLX engine도 다룰 수 있고, 로컬 서버를 열어 OpenAI response type이나 Anthropic response type 같은 형태로 연결할 수 있다고 설명한다.
이 조합은 꽤 전략적이다.
모바일 앱은 일반 사용자에게 가장 직접적인 표면이고, 데스크톱 local server는 개발자와 power user에게 가장 유연한 표면이다.
둘이 같은 모델 허브, 같은 MLX runtime, 비슷한 response format을 공유하면 로컬 AI는 “앱 하나”가 아니라 생태계가 된다.
특히 agent 앱 관점에서는 response type compatibility가 중요하다.
기존 코드가 OpenAI SDK나 Anthropic-style streaming에 묶여 있다면, 로컬 모델을 테스트하려면 API shape를 맞추는 일이 큰 마찰이 된다.
LM Studio식 local server는 이 마찰을 줄인다.
반대로 iPhone 앱은 사용자가 그런 API shape를 몰라도 바로 모델을 체험하게 해 준다.
Tool calling은 아직 더 중요한 다음 표면이다
Q&A에서 첫 질문은 tool calling 지원 여부였다.
Adrien은 MLX Swift LM이 tool calling을 지원한다고 답하면서, custom structured generation은 아직 별도 패키지들이 얹히는 중이라는 취지로 설명한다.
이 답변은 짧지만 중요하다.
온디바이스 LLM이 단순 챗봇에 머무르면 장점은 privacy와 offline 정도로 제한된다.
하지만 tool calling이 안정적으로 붙으면 상황이 바뀐다.
사용자의 캘린더, 로컬 파일, 앱 shortcut, 사진 라이브러리, 개인 지식 저장소를 네트워크 없이 다루는 작은 agent가 가능해진다.
물론 이 영역에서는 permission, sandbox, prompt injection, tool safety가 더 중요해진다.
클라우드로 데이터를 보내지 않는다고 해서 자동으로 안전한 것은 아니다.
발표가 보여 준 현재 단계는 “로컬 모델이 충분히 빠르게 말한다”에 가깝다.
다음 단계는 “로컬 모델이 디바이스 안의 도구를 안전하게 호출한다”가 될 가능성이 높다.
Apple 플랫폼에서는 이 지점이 특히 크다.
Shortcuts, App Intents, Foundation Models, local files, on-device private context가 모두 같은 생태계 안에 있기 때문이다.
실무적으로 어떻게 읽어야 하나
이 발표를 실무 관점에서 보면, 온디바이스 LLM 프로젝트의 체크리스트가 드러난다.
| 질문 | 확인해야 할 것 |
|---|---|
| 어떤 모델을 쓸 것인가 | Gemma 4, Qwen, SmolLM 등 target task에 맞는 모델 family와 크기 |
| 어떤 weight를 받을 것인가 | MLX Community의 4-bit/6-bit/8-bit 변형, chat template, tokenizer 호환성 |
| 어떤 runtime을 쓸 것인가 | Swift 앱이면 MLX Swift LM, Python/CLI면 mlx-lm, multimodal이면 mlx-vlm/audio 등 |
| target device는 무엇인가 | 최신 iPhone인지, 구형 iPhone인지, iPad/Mac인지에 따라 tok/s와 memory margin이 달라짐 |
| UX 병목은 무엇인가 | 첫 다운로드, 첫 모델 로딩, streaming, battery/thermal, offline 상태 처리 |
| tool use를 할 것인가 | tool calling 지원, structured output, permission boundary, local data safety |
| 클라우드 fallback이 필요한가 | 로컬 모델 실패 시 더 큰 cloud model로 넘길지, 완전 offline을 고수할지 |
가장 피해야 할 오해는 “iPhone에서 40 tok/s가 나오니 모든 cloud inference를 대체할 수 있다”는 식의 과장이다. frontier reasoning, 긴 context, 고품질 coding, 복잡한 tool orchestration은 여전히 큰 모델과 서버 런타임이 유리할 수 있다.
반면 짧은 개인 assistant, 로컬 요약, offline Q&A, app-specific automation, private note processing 같은 workload는 온디바이스 모델이 빠르게 현실적인 선택지가 되고 있다.
내가 보기에 Locally AI와 MLX ecosystem의 핵심 가치는 benchmark leaderboard가 아니라 배포 표면의 밀도다.
MLX로 Apple Silicon을 쓰고, MLX Community로 모델을 받으며, MLX Swift LM으로 앱에 넣고, Locally/LM Studio로 사용자가 바로 만진다.
이 네 단계가 짧아질수록 로컬 AI는 취미용 실험에서 실제 제품 기능으로 내려온다.
정리
이 영상은 화려한 새 모델 발표가 아니다.
오히려 이미 공개된 모델을 어떻게 Apple 기기 안으로 끌고 들어와 제품 경험으로 만들 것인가에 대한 짧은 실전 소개다.
그래서 더 흥미롭다.
로컬 LLM의 승부는 더 이상 “모델 파일이 있다”에서 끝나지 않는다. iPhone에서 돌아갈 만큼 작고 빠른 quantized weight, 개발자가 붙이기 쉬운 Swift runtime, 사용자가 설치할 수 있는 앱, 기존 toolchain과 연결되는 local server가 함께 필요하다.
Gemma 4 40 tok/s 데모는 그 가능성을 보여 주는 하나의 스냅샷이다.
수치 자체는 각 팀이 target device에서 다시 검증해야 하지만, 방향은 분명하다.
Apple Silicon 위의 로컬 AI stack은 점점 더 앱 개발의 일반적인 선택지로 내려오고 있다.
앞으로 중요한 질문은 “로컬 모델이 가능한가”가 아니라, 어떤 작업을 로컬에 두고, 어떤 작업을 클라우드로 넘기며, 그 경계를 사용자에게 어떻게 투명하게 보여 줄 것인가가 될 것이다.