LLM 애플리케이션에서 “컨텍스트가 중요하다”는 말은 이제 너무 흔하다.
하지만 실제 기업 환경에서 문제는 context window의 길이만이 아니다.
고객 대화는 Slack에 있고, 정책은 문서 저장소에 있고, 이전 판단은 티켓·CRM·이메일·감사 로그에 흩어져 있다.
벡터 검색은 그중 비슷한 조각을 찾아 줄 수 있지만, 그 조각들이 왜 연결되는지, 과거에 어떤 결정을 내렸는지, 그 결정이 다음 판단에 어떤 선례가 되는지는 별도의 구조가 필요하다.
AI Engineer 채널에 올라온 Stephen Chin의 “Connecting the Dots with Context Graphs” 발표는 이 지점을 정면으로 다룬다.
Neo4j의 관점에서 context graph는 RAG를 버리는 대체재라기보다, RAG가 놓치기 쉬운 관계·선례·추론 흔적을 그래프 위에 남기는 메모리 계층이다.
이 발표의 핵심은 간단하다.
에이전트가 더 정확해지려면 더 많은 텍스트를 한 번에 넣는 것만으로는 부족하다.
무엇이 무엇과 연결되어 있고, 어떤 판단이 어떤 근거로 내려졌으며, 그 판단이 다음 케이스에서 어떻게 재사용되는지를 queryable한 구조로 남겨야 한다.
무엇을 다루는 영상인가
이 영상은 AI Engineer 채널이 2026년 5월 16일 공개한 약 18분 분량의 컨퍼런스 발표다.
발표자는 Neo4j 개발자 관계 팀을 이끄는 Stephen Chin이고, 주제는 context graph, knowledge graph, GraphRAG, agent memory, 그리고 금융 서비스 의사결정 데모다.
공식 YouTube 설명은 환자 emphysema care plan 예시와 금융 서비스 대출 판단 데모를 중심으로, “정보는 양쪽에 있었지만 시스템이 관계를 traversing할 수 있었는지가 결과를 바꿨다”고 요약한다.
공식 챕터는 없지만 transcript 기준 흐름은 명확하다.
문제 제기에서 시작해 knowledge graph와 GraphRAG의 차이를 설명하고, short-term·long-term·reasoning memory를 묶은 Neo4j Agent Memory, 마지막으로 context graph 기반 금융 서비스 데모로 이어진다.
핵심 아이디어: 검색 결과가 아니라 관계와 결정 이력을 저장하기
Stephen Chin은 발표 초반에 의료 예시를 든다.
“Andre Jenkins의 emphysema care plan은 무엇이었나?”
라는 질문에 일반 LLM은 폐 손상을 줄이고 증상을 관리하라는 넓은 의학 상식을 답한다. vector RAG를 붙이면 환자에 대한 일부 정보가 들어오지만, 여전히 respiratory therapy나 deep breathing 같은 비교적 일반적인 권고에 머문다.
차이는 그래프가 들어올 때 생긴다.
환자의 이전 진단, 수술 이력, 흡연 이력처럼 서로 떨어져 있는 사실을 관계로 연결하면 답은 더 구체적이 된다.
발표에서는 medication management, smoking cessation counseling, pulmonary rehabilitation exercise처럼 환자 맥락을 반영한 권고가 나온다.
여기서 중요한 것은 단순히 “더 많은 문서를 검색했다”가 아니라, 검색된 조각 사이의 관계를 따라갔다는 점이다.
이 관점은 최근 agent memory 논의와도 맞닿아 있다.
에이전트는 현재 대화만 기억해서는 부족하다.
장기적으로 축적된 엔티티와 선호, 과거 tool call과 reasoning trace, 이전 결정과 그 결과를 함께 다뤄야 한다.
Chin은 이를 short-term memory, long-term memory, reasoning memory의 세 층으로 나누어 설명한다.

영상 6분대의 메모리 분류.
발표는 에이전트 메모리를 현재 컨텍스트, 장기 지식, 추론 trace의 세 계층으로 나누고 이를 그래프에 연결한다.
Neo4j Agent Memory가 보여주는 구현 방향
발표에서 가장 구체적인 구현물은 Neo4j Agent Memory다.
영상 속 슬라이드는 이 패키지를 short-term, long-term, reasoning memory를 하나의 Neo4j context graph로 묶는 API로 제시한다. short-term memory는 conversation과 message를 다루고, long-term memory는 entity·preference·fact를 지식 그래프화하며, reasoning memory는 context graph for explainability & learning으로 tool call과 reasoning step을 저장한다.
공식 저장소 설명도 같은 방향이다. neo4j-labs/agent-memory는 “graph-native memory system for AI agents and context graphs”라고 자신을 설명한다.
README 기준 short-term memory는 conversations/messages, long-term memory는 entities/preferences/facts, reasoning memory는 reasoning traces/tool usage를 담당한다.
2026년 5월 23일 조회 기준 GitHub 저장소는 Apache-2.0 라이선스, Python 주 언어, 257 stars, 63 forks를 보였고, PyPI neo4j-agent-memory의 최신 버전은 0.4.0으로 확인된다.
TypeScript 쪽 npm 패키지 @neo4j-labs/agent-memory는 latest가 0.3.0이다.
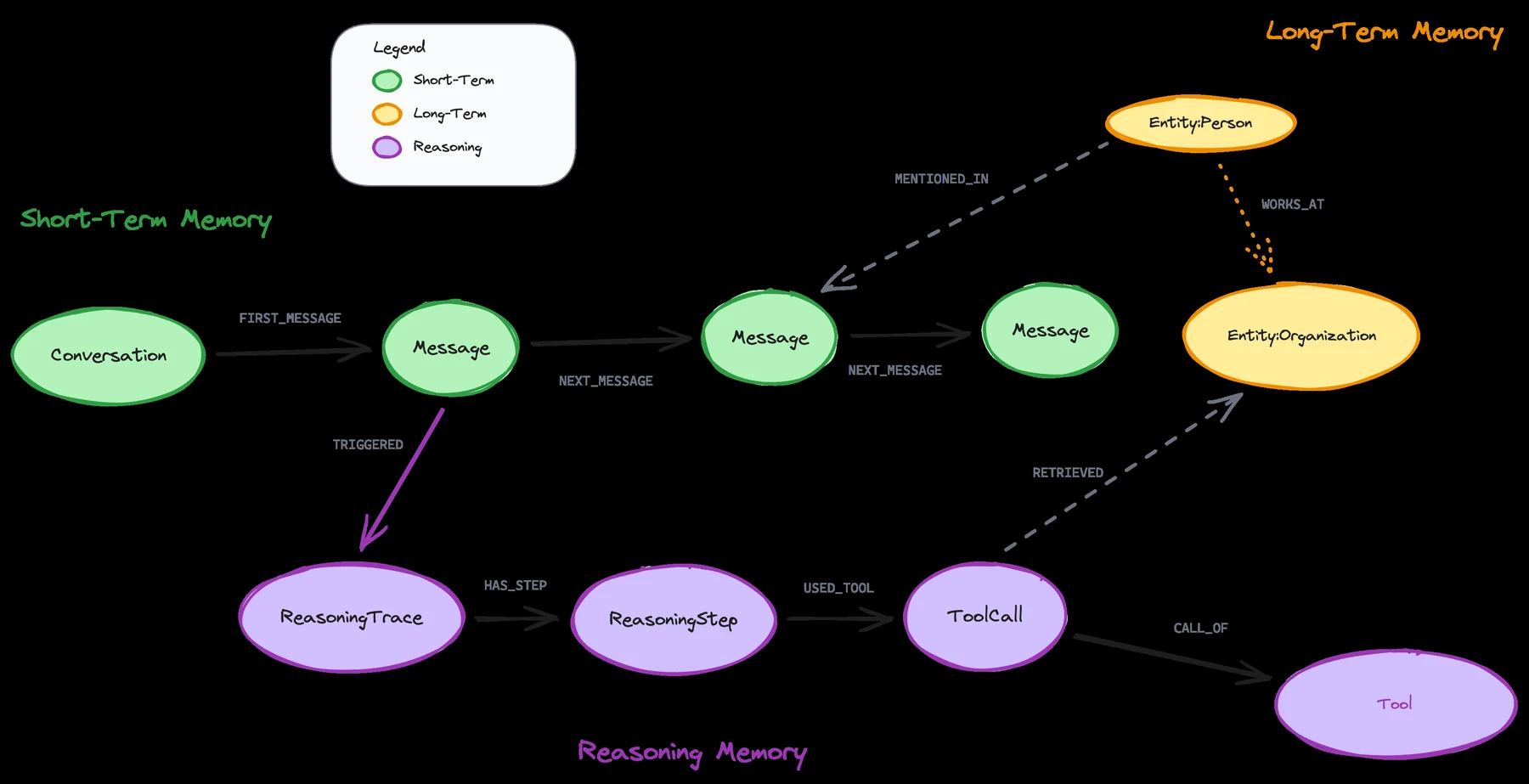
neo4j-labs/agent-memory 저장소의 공식 데이터 모델 이미지.
대화와 메시지, 엔티티, reasoning trace, tool call이 별도 로그가 아니라 하나의 관계 그래프로 연결된다.
영상의 API 슬라이드는 이 구조를 더 실무적으로 보여준다. add_message, search_messages, add_entity, search_entities, record_step, record_tool_call, get_similar_traces 같은 기능이 하나의 memory API 아래 묶인다.
즉 context graph는 단순히 “그래프 DB에 문서를 넣는 것”이 아니라, 에이전트 런타임이 발생시키는 상태와 판단을 장기적으로 재사용 가능한 형태로 기록하는 인터페이스에 가깝다.
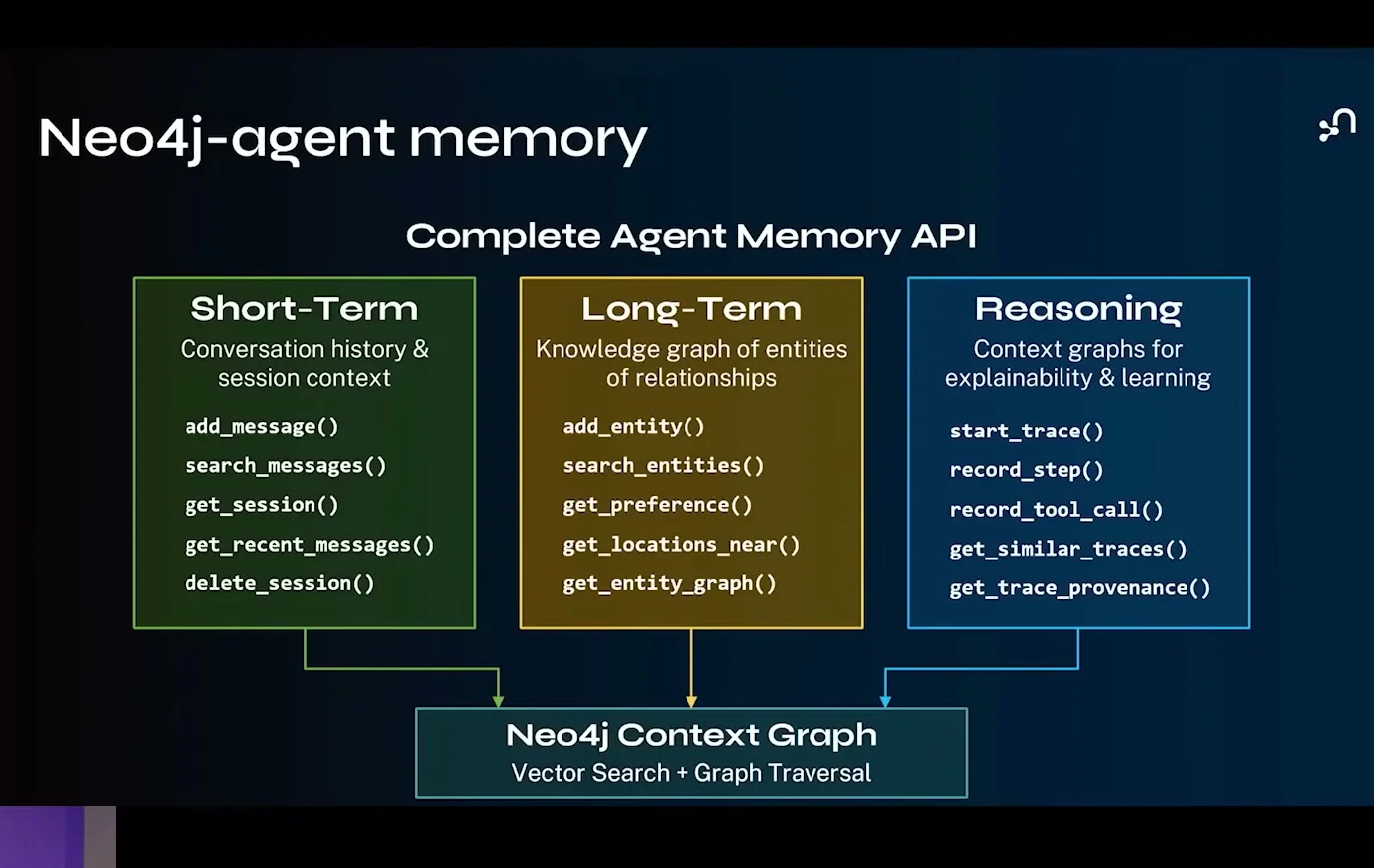
영상 9분대의 Neo4j Agent Memory API 슬라이드.
발표자는 short-term, long-term, reasoning memory가 Neo4j Context Graph 위에서 vector search와 graph traversal을 함께 쓰는 형태로 연결된다고 설명한다.
Context graph는 audit log보다 “왜”를 더 많이 담으려 한다
발표의 좋은 대조는 traditional audit log와 context graph 비교다.
전통적인 감사 로그는 보통 “어떤 action이 언제 일어났는가”를 남긴다.
예를 들어 “Transaction rejected at 14:32” 같은 기록은 나중에 검색할 수 있지만, 그 판단에 영향을 준 정책, 관련된 고객 이력, 이전 선례, 담당자의 reasoning은 별도 시스템에 흩어져 있다.
Chin이 말하는 context graph는 이 빈틈을 메우려 한다.
단순 action log가 아니라 decision trace, causal chain, entity, relationship, event를 함께 저장하고, “왜 그 판단이 내려졌는가”를 다음 의사결정에서 다시 질의할 수 있게 한다는 것이다.
이 지점에서 context graph는 observability 로그와도 다르고, 일반적인 vector index와도 다르다.
목표는 실행 흔적을 모으는 데 그치지 않고 선례를 재사용 가능한 지식으로 바꾸는 것이다.

영상 11분대의 비교 슬라이드. context graph는 단절된 기록이 아니라 decision trace와 causal relationship을 함께 저장해 “왜”를 검색 가능하게 만들겠다는 방향을 잡는다.
이건 규제 산업에서 특히 중요하다.
금융, 의료, 보험, 공공 부문에서는 답이 맞는지만큼이나 “왜 그런 판단을 했는가”가 중요하다.
에이전트가 고객에게 어떤 권고를 했거나, 내부 직원의 승인·거절 판단을 보조했다면, 나중에 그 근거를 설명할 수 있어야 한다.
단순 prompt log나 vector hit list는 이 요구를 온전히 만족시키기 어렵다.
Context graph based retrieval의 구조
발표의 retrieval 아키텍처는 세 단계로 읽을 수 있다.
첫째, search query가 context graph memory retrieval tools로 들어간다.
둘째, 이 도구는 Neo4j 안의 knowledge graph, vector, graph data science 계층을 함께 사용해 관련 정보를 꺼낸다.
셋째, agent loop가 그 정보를 이용해 답을 만들고, 결과와 reasoning trace를 다시 contextual memory로 밀어 넣는다.
이 구조에서 vector search는 사라지지 않는다.
오히려 그래프 안으로 들어간다. embedding은 시작점을 찾는 데 유용하고, graph traversal은 그 시작점에서 관계를 따라가며 더 넓은 맥락을 만든다.
Graph Data Science 알고리즘은 community나 similarity 같은 구조적 신호를 줄 수 있다.
결국 context graph는 “vector vs graph”의 선택지가 아니라, vector retrieval을 관계 기반 memory update loop 안에 넣는 설계로 보는 편이 맞다.
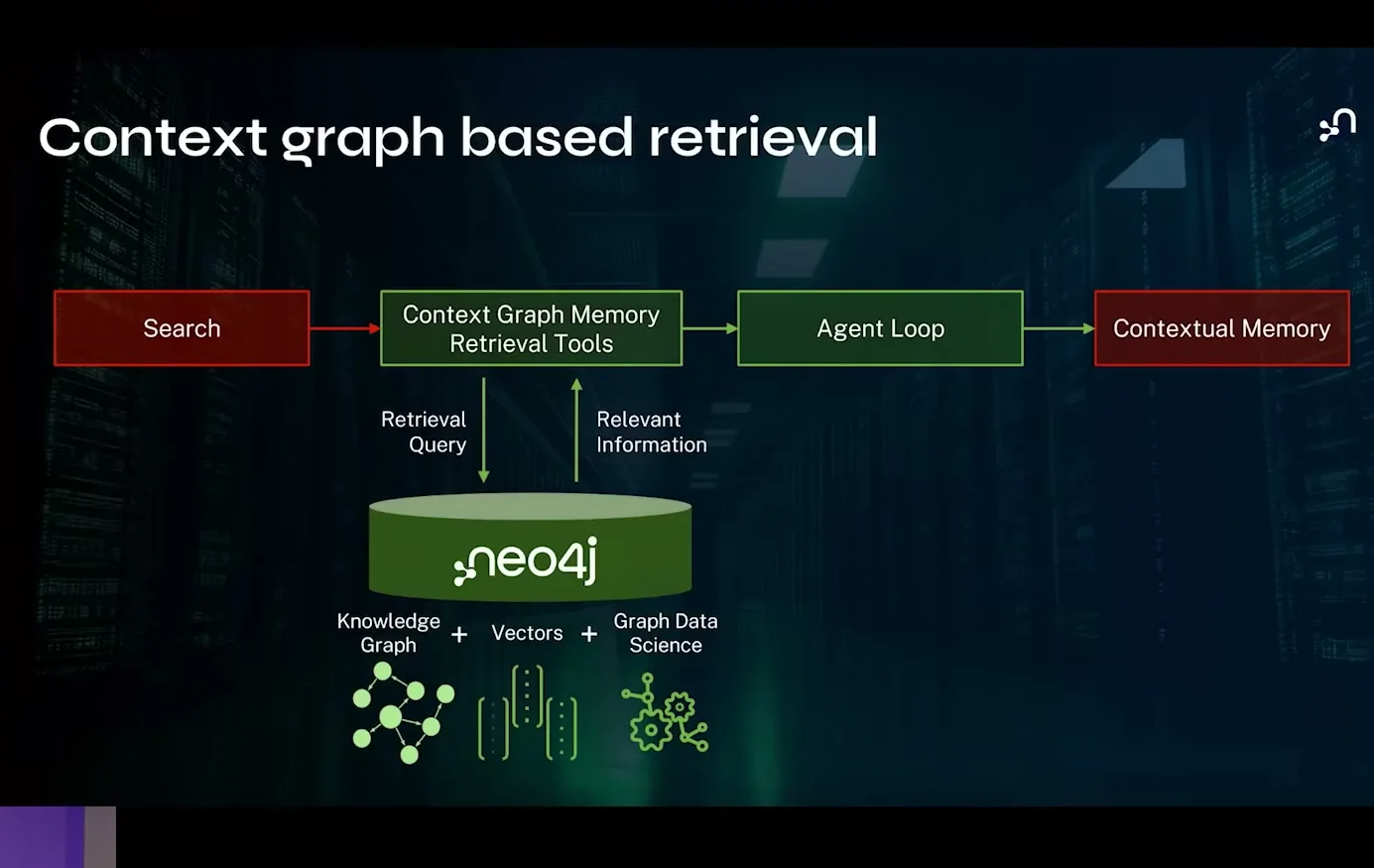
영상 12분대의 retrieval 구조.
검색은 graph memory retrieval tool을 지나고, Neo4j의 knowledge graph·vector·graph data science 계층이 agent loop와 contextual memory 사이를 연결한다.
이 관점은 에이전트 시스템의 평가 방식도 바꾼다.
모델이 한 번 좋은 답을 냈는지만 보지 않고, 그 답이 어떤 trace를 남겼는지, 다음 비슷한 케이스에서 그 trace가 도움이 되는지, 사람이 검토할 수 있는 형태로 관계와 근거가 남는지를 봐야 한다. context graph가 흥미로운 이유는 바로 이 반복 학습과 감사 가능성의 접점에 있다.
금융 서비스 데모가 보여주는 사용 장면
발표 후반의 데모는 금융 서비스 의사결정 보조 UI다.
Chin은 support ticket system, CRM/Salesforce, internal business data system을 연결하고, 10개 MCP tool을 붙였다고 설명한다.
여기에 OpenAI embedding을 만들고 Neo4j context graph에 domain graph와 reasoning graph를 채운 뒤, Next.js 기반 프런트엔드로 노출한다.
사용자는 Jessica Norris에게 credit line increase를 승인할지 묻는다.
시스템은 그래프와 Cypher query를 통해 Jessica의 계좌 이력, 관련 margin trade, 이전 거절 기록, fraud risk pattern을 끌어온다.
발표에서 AI는 대출을 승인하지 말라는 권고를 내리고, 그 이유와 위험 요인, 과거 결정의 영향을 함께 제시한다.
이 데모의 포인트는 모델이 “거절”이라고 말한 사실 자체가 아니다.
더 중요한 것은 사용자가 그 판단의 근거가 되는 graph traversal과 관련 정보를 볼 수 있다는 점이다.
실무의 human-in-the-loop 환경에서는 이것이 결정적이다.
사람이 최종 결정을 내려야 할 때 필요한 것은 그럴듯한 문장 하나가 아니라, 어떤 근거를 보고 그런 권고가 나왔는지 추적 가능한 구조다.
공식 companion repo인 neo4j-labs/create-context-graph도 비슷한 방향을 제품화한다.
이 저장소는 domain-specific context graph application을 몇 분 안에 scaffold하는 CLI라고 설명하며, FastAPI backend, agent framework, Next.js/Chakra UI frontend, graph visualization, document browser, decision trace viewer를 묶는다.
2026년 5월 23일 조회 기준 Apache-2.0 라이선스, 602 stars, 81 forks를 보였고, 공식 문서는 “AI agents with graph memory, scaffolded in seconds”라고 요약한다.
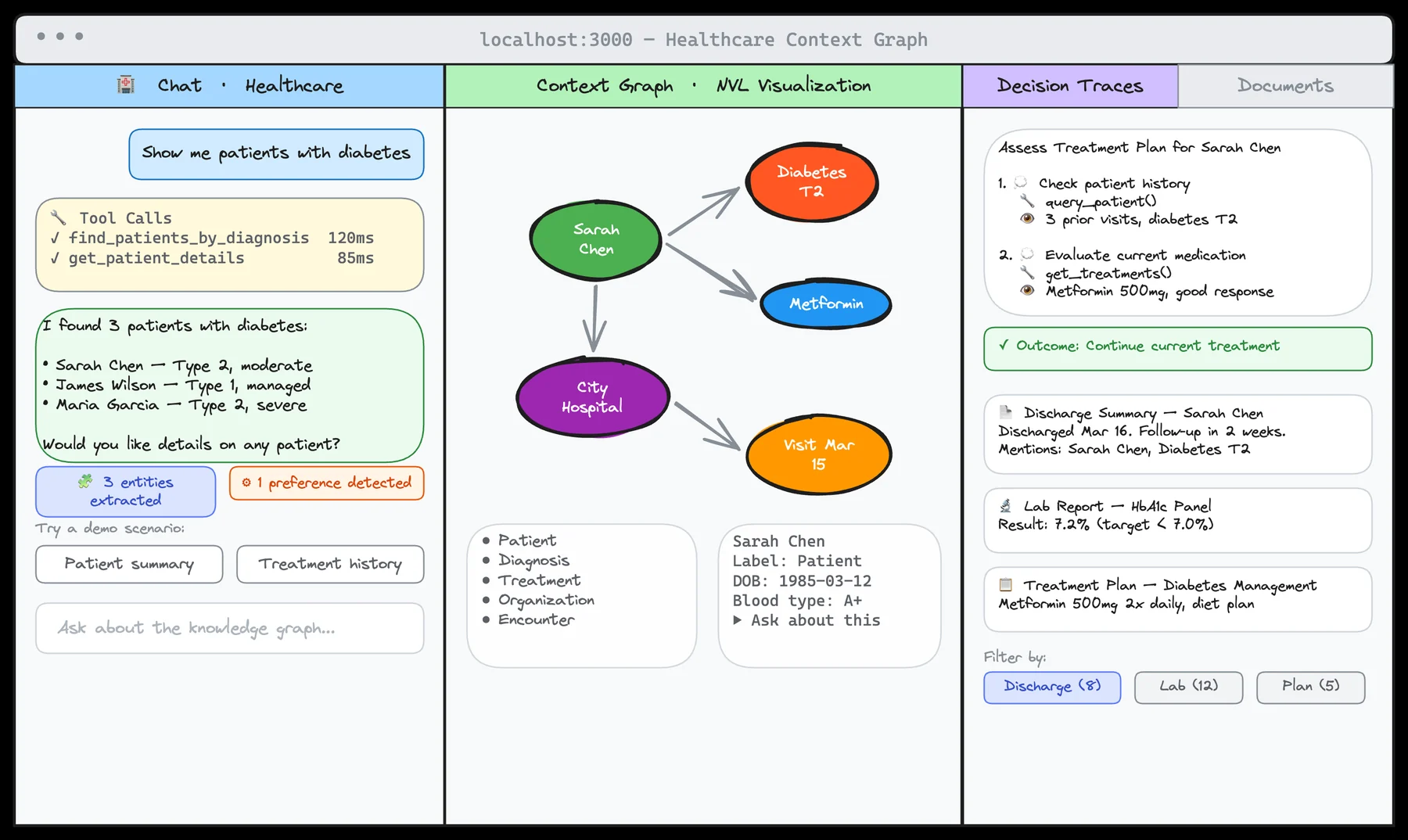
neo4j-labs/create-context-graph 저장소의 공식 앱 예시.
영상 속 금융 데모와 도메인은 다르지만, chat·context graph visualization·decision trace·document panel을 하나의 사용자 경험으로 묶는 방향은 같다.
타임라인으로 보는 핵심 구간
| 시간 | 화면 / 주제 | 핵심 내용 |
|---|---|---|
| 00:14–02:28 | 문제 제기와 “Matrix” 비유 | 기업 지식이 Slack, 고객 thread, enterprise system에 흩어져 있고, 에이전트가 비즈니스 결정을 내리려면 관계를 잇는 컨텍스트가 필요하다고 설명한다. |
| 02:33–03:15 | Gartner hype cycle, Foundation Capital 언급 | context graph가 agentic AI 논의에서 별도 키워드로 떠오르고 있으며, knowledge graph를 활용해 silo를 연결해야 한다고 주장한다. |
| 03:18–04:35 | Knowledge graph 기본 구조 | node, relationship, property, embedding을 함께 사용해 LLM의 언어·추론 능력과 graph의 관계·맥락 표현력을 결합한다고 설명한다. |
| 04:37–06:17 | LLM direct vs vector RAG vs graph-grounded retrieval | emphysema care plan 예시로, 비슷한 문서 조각만 찾는 것과 환자 이력 관계를 traversing하는 것의 차이를 보여준다. |
| 06:19–09:53 | Short-term, long-term, reasoning memory | 에이전트의 현재 상태, 장기 엔티티 지식, tool call과 decision trace를 함께 저장해야 한다고 설명하고 Neo4j Agent Memory를 소개한다. |
| 09:57–11:29 | Lenny podcast memory demo | podcast처럼 조밀한 콘텐츠에서 장소·주제·관계를 그래프로 뽑아 전체 맥락을 질의하는 예시를 보여준다. |
| 11:31–12:58 | Context graph 정의와 retrieval architecture | traditional audit log와 달리 decision trace와 causal chain을 저장하고, retrieval tool과 agent loop를 통해 contextual memory를 갱신하는 구조를 제시한다. |
| 13:00–15:59 | 금융 서비스 데모 | support ticket, CRM, 내부 데이터, MCP tool을 연결한 credit decision demo에서 이전 거절, margin trade, fraud pattern을 근거로 권고를 만든다. |
| 16:10–17:18 | 학습 자료와 마무리 | GraphAcademy의 Knowledge Graph / GraphRAG 학습 경로와 Neo4j 리소스를 안내하며, 이어질 세션이 context graph의 agentic use case를 더 다룬다고 예고한다. |
공개 자료에서 확인되는 점
발표는 컨퍼런스 데모 성격이 강하지만, 연결되는 공개 자료는 꽤 구체적이다.
특히 Neo4j Agent Memory와 Create Context Graph는 단순 슬라이드 용어가 아니라 공개 저장소와 패키지 표면을 가진 프로젝트다.
| 항목 | 확인한 내용 | 해석 |
|---|---|---|
| YouTube 영상 | Connecting the Dots with Context Graphs — Stephen Chin, Neo4j, AI Engineer 채널, 2026-05-16 공개 |
발표 자체는 제품 데모와 개념 설명이 섞인 conference talk다. |
neo4j-labs/agent-memory |
Apache-2.0, Python, 257 stars, 63 forks, PyPI neo4j-agent-memory 0.4.0 |
agent memory를 short-term, long-term, reasoning memory로 나누고 Neo4j-backed graph memory로 구현하려는 Labs 프로젝트다. |
@neo4j-labs/agent-memory |
npm latest 0.3.0 | TypeScript client 표면도 있으나 PyPI와 버전이 다르므로 언어별 maturity를 분리해서 봐야 한다. |
neo4j-labs/create-context-graph |
Apache-2.0, Python, 602 stars, 81 forks | domain-specific context graph app을 scaffold하는 CLI로, NAMS 또는 self-hosted Neo4j, FastAPI, Next.js UI를 묶는다. |
GraphAcademy dev.neo4j.com/ga-rag |
graphacademy.neo4j.com/knowledge-graph-rag/로 연결 |
Neo4j는 context graph를 GraphRAG와 knowledge graph 교육 흐름 안에 배치하고 있다. |
여기서 조심할 점도 있다.
GitHub stars와 package version은 adoption의 간접 신호일 뿐, production reliability를 보장하지 않는다.
또한 Neo4j Labs 프로젝트는 보통 실험적 성격을 가진다.
실제 도입에서는 schema design, 데이터 품질, 권한 모델, retention policy, audit requirement를 별도로 검증해야 한다.
실무 관점에서의 해석
이 발표를 “Neo4j가 그래프 DB를 팔기 위해 RAG를 재해석했다” 정도로만 읽으면 아쉽다.
더 중요한 메시지는 에이전트 시스템의 병목이 검색 품질에서 의사결정 메모리 품질로 이동하고 있다는 점이다.
초기 RAG는 문서 조각을 잘 찾는 데 초점을 맞췄다.
하지만 agentic workflow가 길어질수록 질문은 달라진다.
이 사용자의 이전 요청은 무엇이었나?
지난번에 어떤 tool을 호출했고 어떤 결과가 나왔나?
비슷한 케이스에서 어떤 결정을 내렸고, 왜 그렇게 판단했나?
그 판단은 이후 성공했나, 실패했나?
이런 질문은 단순 vector similarity보다 관계와 시간, 인과, 선례를 요구한다.
Context graph는 이 질문에 대한 한 가지 실용적인 답이다.
모든 것을 거대한 prompt에 넣는 대신, entity와 event, message와 tool call, decision trace와 outcome을 그래프 구조로 남긴다.
그러면 에이전트는 다음 task에서 “비슷한 텍스트”뿐 아니라 “관련된 사람·조직·정책·과거 판단”을 따라갈 수 있다.
다만 이 접근은 공짜가 아니다.
그래프가 유용하려면 도메인 모델이 필요하고, 데이터 통합이 필요하며, 어떤 관계를 저장할지 결정해야 한다. reasoning trace에는 민감한 정보가 들어갈 수 있으므로 access control과 redaction도 중요하다.
또 LLM이 Cypher를 생성하거나 graph traversal 결과를 요약할 때 생기는 오류는 별도 검증이 필요하다. context graph는 magic memory가 아니라, 잘 설계해야 하는 운영 인프라다.
내가 보기에 실무 팀이 여기서 얻을 수 있는 체크리스트는 네 가지다.
- RAG 결과를 답변으로 끝내지 말고 trace로 남기는가. 어떤 문서와 관계가 답에 쓰였는지 다음 케이스에서 재사용할 수 있어야 한다.
- 메모리를 current context, long-term knowledge, reasoning trace로 나누어 관리하는가. 한 덩어리 로그로 저장하면 검색은 쉬워도 의사결정 재사용은 어렵다.
- 사람이 판단 근거를 검토할 수 있는가. 금융·의료·내부 정책처럼 책임이 큰 영역에서는 graph visualization, source link, previous decision provenance가 필요하다.
- 권한과 보존 정책이 memory layer에 반영되는가. 에이전트가 기억을 잘하는 것만큼, 잊어야 할 것을 잊고 보여주면 안 되는 것을 숨기는 것도 중요하다.
정리
Connecting the Dots with Context Graphs는 짧은 발표지만, agent memory의 방향을 잘 보여준다.
더 큰 context window나 더 강한 retriever만으로는 기업형 에이전트의 신뢰성을 설명하기 어렵다.
장기 실행 에이전트에는 현재 대화, 장기 지식, reasoning trace, 과거 decision outcome을 연결하는 별도의 memory substrate가 필요하다.
Neo4j가 제시하는 context graph는 그 substrate를 knowledge graph와 GraphRAG 쪽에서 구현하려는 시도다.
아직은 데모와 Labs 프로젝트의 성격이 강하고, 실제 도입에는 데이터 모델링과 거버넌스 비용이 따른다.
그럼에도 방향은 분명하다.
앞으로 좋은 agent system은 답변을 생성하는 것만이 아니라, 왜 그런 답을 만들었는지와 그 경험을 다음 판단에 어떻게 남길지를 설계하는 시스템이 될 가능성이 크다.