Transformer는 보통 한 토큰을 예측할 때 정해진 깊이의 feed-forward 계산을 한 번 통과한다.
반대로 chain-of-thought나 agentic reasoning은 더 많은 계산을 쓰지만, 그 계산은 대부분 토큰으로 외부화된다.
최근 latent reasoning, looped transformer, recurrent-depth model 계열의 질문은 여기서 출발한다.
모델이 답을 내기 전 내부 표현을 여러 번 정제하게 만들 수 있다면, token-level thinking보다 더 싸고 안정적인 추론 계산을 만들 수 있을까.
Solve the Loop: Attractor Models for Language and Reasoning는 이 질문에 꽤 직접적인 답을 낸다.
Jacob Fein-Ashley와 Paria Rashidinejad는 looped language model의 recurrent block을 정해진 횟수만큼 펼치는 대신, 출력 임베딩 공간의 고정점 fixed point을 푸는 문제로 바꾼다.
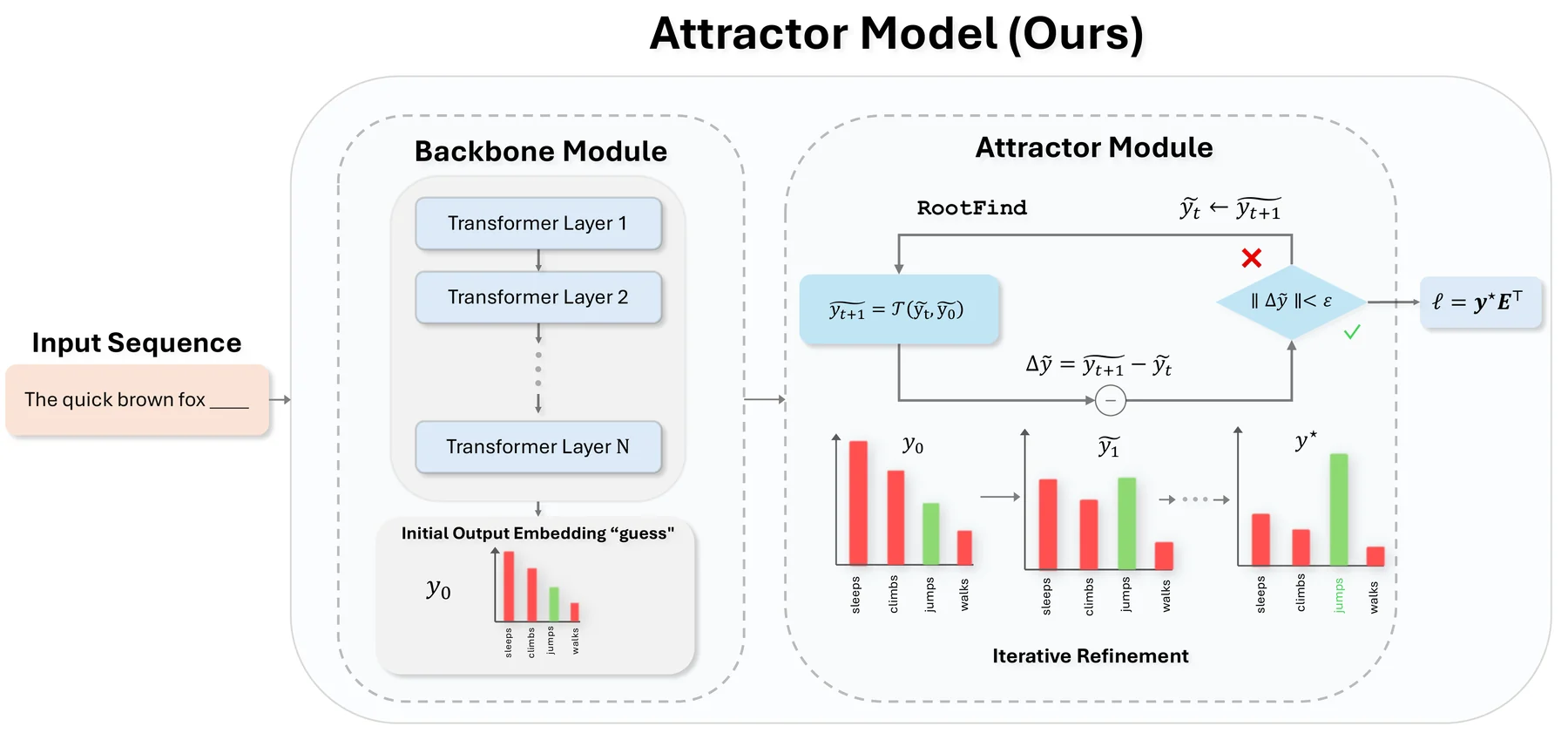
이름처럼 Attractor Model은 backbone이 먼저 그럴듯한 출력 임베딩 초안을 만들고, 작은 attractor module이 그 초안을 equilibrium 근처로 끌어당긴 뒤, tied unembedding으로 next-token distribution을 만든다.
흥미로운 지점은 “더 많이 반복한다”가 아니라 “반복을 학습 중에는 쓰되, inference에서는 거의 필요 없게 만든다”는 결과다.
논문은 이를 equilibrium internalization이라고 부른다.
학습 과정에서 backbone의 초기 제안 y0가 점점 fixed point y*에 가까워져, solver가 훈련의 teacher처럼 작동하지만 배포 시에는 T=0 또는 T=1만으로도 수렴한 품질에 가까운 예측을 낸다는 주장이다.
무엇을 해결하려는가
Looped transformer 계열의 장점은 명확하다.
같은 block을 여러 번 적용하면 파라미터 수를 크게 늘리지 않고도 effective depth를 늘릴 수 있고, 알고리즘적 절차나 latent refinement를 표현할 가능성이 생긴다.
Parcae, Ouro, Huggin, recurrent-depth Transformer, tiny recursive model 같은 흐름은 모두 이 방향을 본다.
하지만 기존 looped model에는 세 가지 병목이 있다.
첫째, 학습 시 recurrence를 몇 번 펼칠지 정해야 한다.
둘째, backpropagation through depth 때문에 반복 횟수에 따라 activation memory가 선형으로 커진다.
셋째, 학습에서 본 loop count와 inference에서 쓰는 loop count가 달라지면 품질이 흔들릴 수 있다.
반복 계산이 reasoning에 좋다는 직관은 있어도, 실제 대규모 LM 학습에서는 안정성, 메모리, sequential compute가 발목을 잡는다.
Attractor Model의 문제 정의는 이 병목을 “반복 횟수를 잘 고르는 문제”가 아니라 “수렴할 상태를 직접 정의하는 문제”로 바꾸는 것이다.
만약 recurrent trajectory가 결국 어떤 fixed point로 수렴한다면, 굳이 T번 펼친 마지막 상태를 목표로 삼을 필요가 없다.
모델의 출력은 고정점 방정식의 해이고, 반복 횟수는 architecture가 아니라 solver의 예산과 tolerance가 된다.
핵심 아이디어 / 구조 / 동작 방식
Attractor Model은 크게 두 모듈로 읽으면 된다.
첫 번째는 일반 causal Transformer에 가까운 backbone module이다.
이 모듈은 입력 토큰 임베딩을 받아 출력 임베딩 공간의 초기 제안 y0를 만든다.
중요한 점은 이 초기 상태가 zero나 noise가 아니라, 이미 next-token prediction에 의미 있는 표현이라는 것이다.
두 번째는 weight-tied attractor module이다.
이 모듈은 현재 상태 yt와 backbone proposal y0를 함께 받아 다음 상태 yt+1를 만든다.
논문은 y0를 첫 상태로만 쓰지 않고 매 refinement step마다 계속 주입하는 additive proposal injection이 가장 잘 작동한다고 보고한다.
그 결과 refinement map은 입력과 무관한 고정점으로 붕괴하지 않고, backbone이 낸 구체적 proposal에 붙어서 수렴한다.
수식으로는 A(ỹ, ỹ0) = T_a(ỹ, ỹ0) - ỹ = 0을 푸는 문제다.
Forward pass에서는 Anderson acceleration 기반 root finder로 approximate equilibrium y*를 찾고, backward pass에서는 fixed-point solver를 끝까지 저장하지 않고 implicit differentiation을 사용한다.
언어 모델링 실험에서는 full implicit solve 대신 one-step approximation u ≈ v를 써서 품질 손실을 작게 유지하면서 메모리와 step time을 줄인다.
| 구조 | 출력이 만들어지는 방식 | 학습/추론에서 생기는 병목 | Attractor 논문의 해석 |
|---|---|---|---|
| 표준 Transformer | 정해진 layer stack을 한 번 통과 | 계산량은 안정적이지만 token별 내부 정제 여지가 제한됨 | feed-forward baseline |
| Looped LM / Parcae | 공유 block을 정해진 횟수만큼 반복한 뒤 decode | 반복 수가 학습 그래프와 메모리에 직접 묶임 | finite unroll baseline |
| Attractor Model | backbone proposal에서 시작해 fixed point를 solver로 찾은 뒤 decode | solver compute는 남지만 training memory는 반복 깊이에 덜 묶임 | recurrence를 equilibrium 문제로 재정의 |
논문이 기존 DEQ와 구분되는 지점도 여기다.
일반 Deep Equilibrium Model은 hidden state equilibrium을 zero 같은 비정보적 초기값에서 찾고 별도 head로 decode한다.
Attractor Model은 fixed point를 tied output-embedding space에 놓고, backbone이 만든 의미 있는 proposal에서 warm-start한다.
이 위치와 초기화가 언어 모델 스케일에서 안정성과 수렴 속도를 가르는 핵심 ablation으로 나온다.
공개된 근거에서 확인되는 점
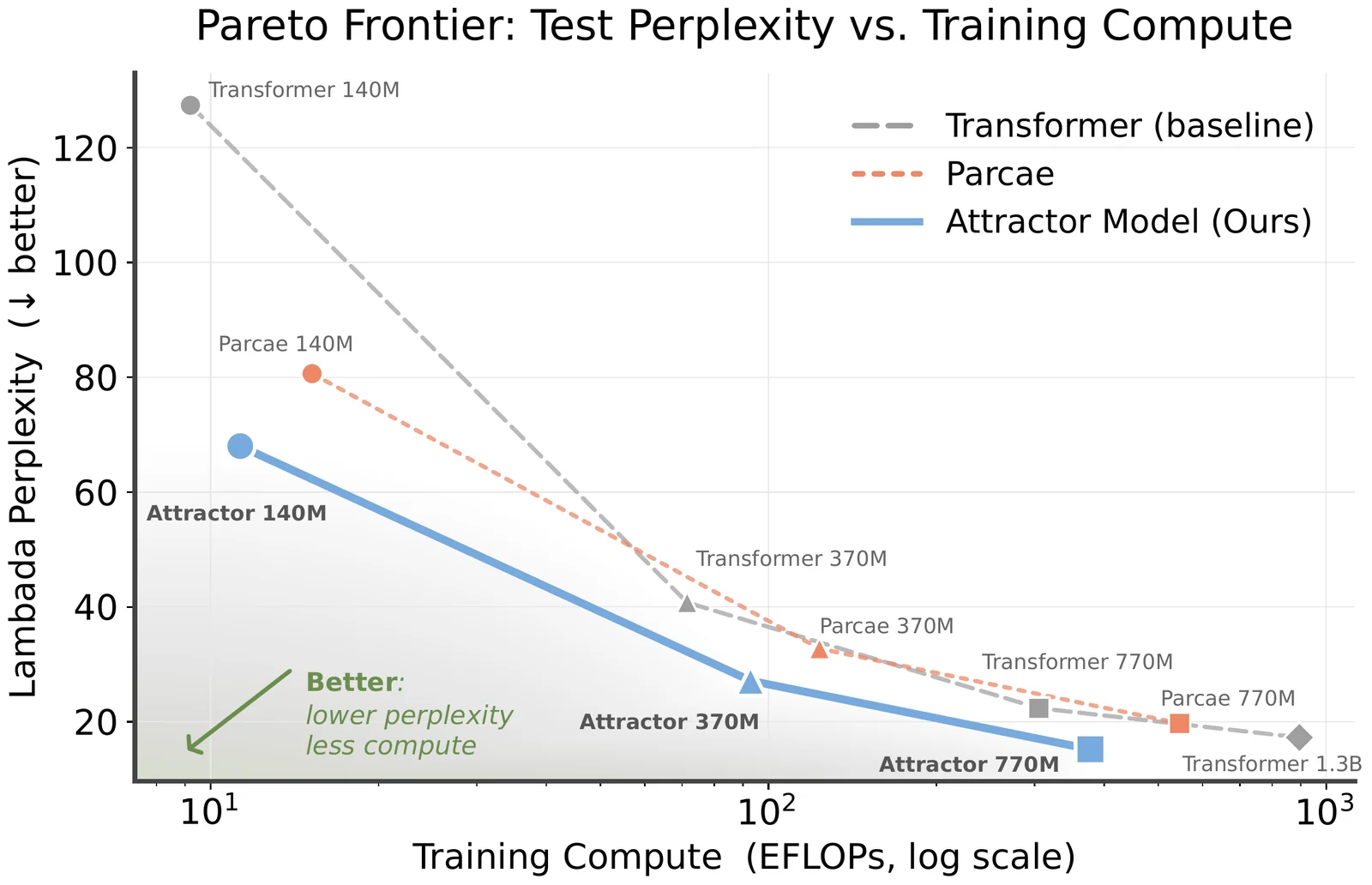
대규모 언어 모델링 실험은 140M, 370M, 770M 크기에서 Transformer, Parcae, Attractor를 비교한다.
논문은 FineWeb-Edu 기반 nanochat recipe를 따르고, validation perplexity, LAMBADA perplexity, CORE/CORE-Extended accuracy를 보고한다.
가장 강한 headline은 770M Attractor가 parameter-matched Transformer와 Parcae보다 낮은 perplexity와 높은 CORE accuracy를 보이고, 1.3B Transformer와도 비슷하거나 일부 더 나은 영역에 들어간다는 점이다.
| 크기 | 모델 | Validation PPL ↓ | LAMBADA PPL ↓ | CORE ↑ | CORE-Ext. ↑ |
|---|---|---|---|---|---|
| 140M | Transformer | 21.48 | 127.39 | 13.00±0.15 | 8.80±0.21 |
| 140M | Parcae | 19.06 | 80.64 | 14.04±0.20 | 9.67±0.28 |
| 140M | Attractor | 18.30 | 68.02 | 14.59±0.11 | 10.03±0.05 |
| 370M | Transformer | 15.79 | 40.77 | 17.46±0.03 | 11.71±0.22 |
| 370M | Parcae | 14.49 | 32.74 | 20.00±0.06 | 12.75±0.31 |
| 370M | Attractor | 14.03 | 27.14 | 20.24±0.09 | 12.64±0.33 |
| 770M | Transformer | 13.08 | 22.37 | 22.42±0.20 | 14.20±0.63 |
| 770M | Parcae | 12.49 | 19.71 | 25.07±0.33 | 15.19±0.43 |
| 770M | Attractor | 12.09 | 15.21 | 26.83±0.29 | 15.42±0.51 |
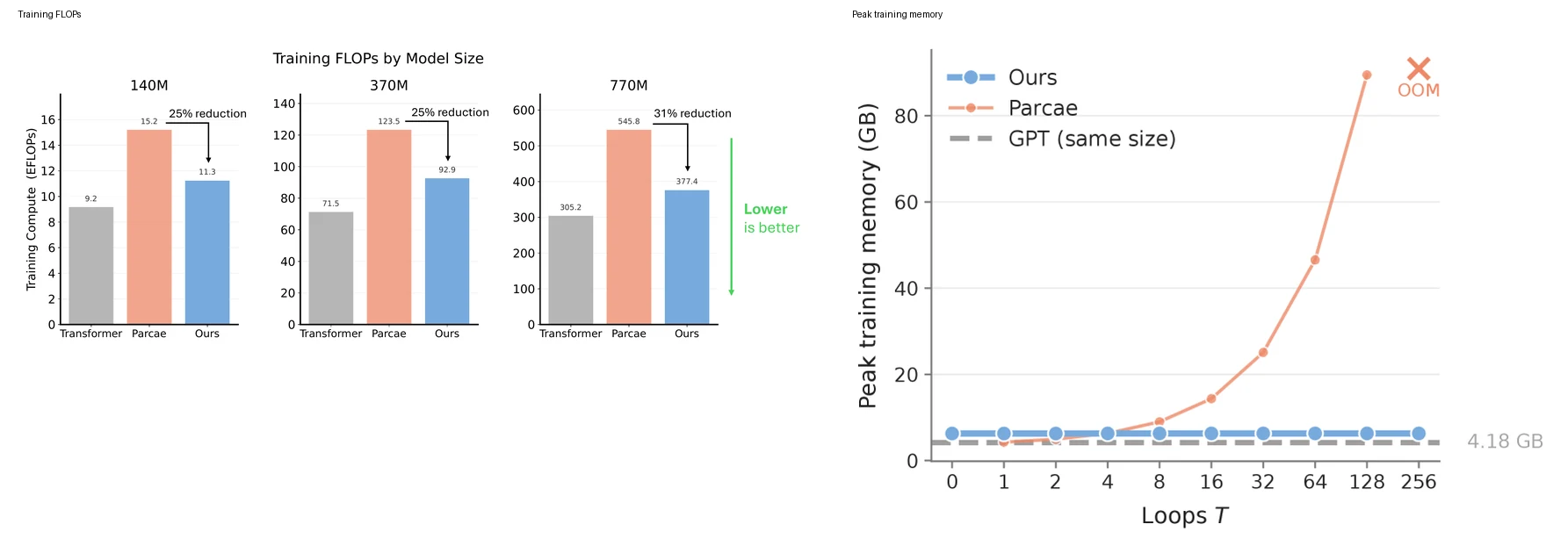
효율성 쪽에서는 두 레이어가 분리된다.
FLOPs 관점에서 Attractor는 solver가 Tmax까지 매번 가지 않고 residual tolerance 아래로 일찍 수렴하기 때문에, Parcae 대비 25-31% 낮은 training FLOPs를 보고한다.
메모리 관점에서는 implicit backward가 반복 중간 activation을 모두 저장하지 않으므로, recurrent depth가 커져도 peak memory가 거의 일정하게 유지된다.
논문 Figure 5는 Parcae가 loop 수가 늘수록 memory가 증가하다가 OOM에 도달하는 반면, Attractor는 GPT same-size 근처의 낮은 메모리 선을 유지한다고 보여준다.
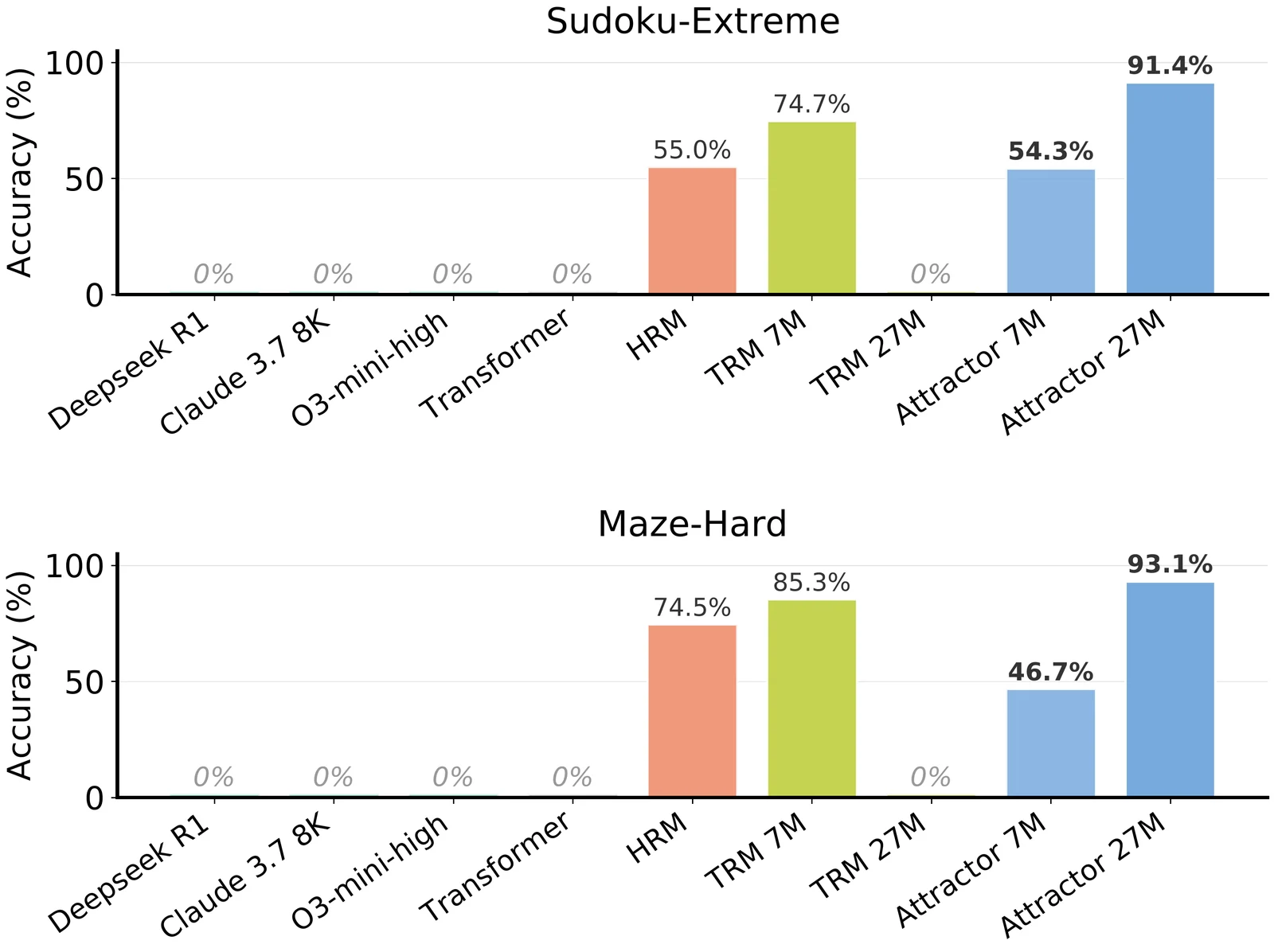
두 번째 실험 축은 작은 reasoning model이다.
Sudoku-Extreme과 Maze-Hard에서 약 1,000개 training example만 사용하고, autoregressive chain-of-thought 없이 전체 grid를 한 번에 예측한다.
이 설정에서는 frontier LLM과 standard Transformer가 0%로 실패하고, TRM은 7M에서 강하지만 27M으로 키우면 붕괴한다.
Attractor는 반대로 7M에서는 약하지만 27M으로 키웠을 때 Sudoku-Extreme 91.4%, Maze-Hard 93.1%를 보고한다.
| 방법 | 파라미터 | Sudoku-Extreme ↑ | Maze-Hard ↑ |
|---|---|---|---|
| DeepSeek R1 | 671B | 0.0% | 0.0% |
| Claude 3.7 | 미공개 | 0.0% | 0.0% |
| o3-mini-high | 미공개 | 0.0% | 0.0% |
| Transformer | 27M | 0.0% | 0.0% |
| HRM | 27M | 55.0% | 74.5% |
| TRM | 7M | 74.7% | 85.3% |
| TRM | 27M | 0.0% | 0.0% |
| Attractor | 7M | 54.3% | 46.7% |
| Attractor | 27M | 91.4% | 93.1% |
여기서도 핵심은 점수 자체보다 scaling behavior다.
논문은 tiny recursive reasoner에서 보인 “less is more” 현상, 즉 모델을 키우면 오히려 붕괴하는 현상을 Attractor의 fixed-point objective가 완화한다고 해석한다.
다만 이 비교는 매우 특수한 grid reasoning setting이고, frontier LLM의 0%도 같은 direct full-output protocol 아래의 결과로 읽어야 한다.
일반적인 대화형 추론 능력 비교로 확장해서 읽으면 과장이다.
equilibrium internalization: 학습 중 반복을 backbone이 흡수한다
논문에서 가장 재사용 가치가 큰 개념은 equilibrium internalization이다.
Attractor Model은 원래 inference에서도 solver로 y*를 찾아야 하는 구조처럼 보인다.
그런데 학습이 진행되면서 backbone proposal y0가 fixed point에 가까워지고, solver가 필요한 반복 수가 줄어든다.
Figure 6은 Attractor의 solver iteration이 훈련 초반에는 높다가 빠르게 최소 반복 수 근처로 내려와 안정화되는 반면, DEQ baseline은 시간이 갈수록 반복 수가 늘어나는 패턴을 보여준다.
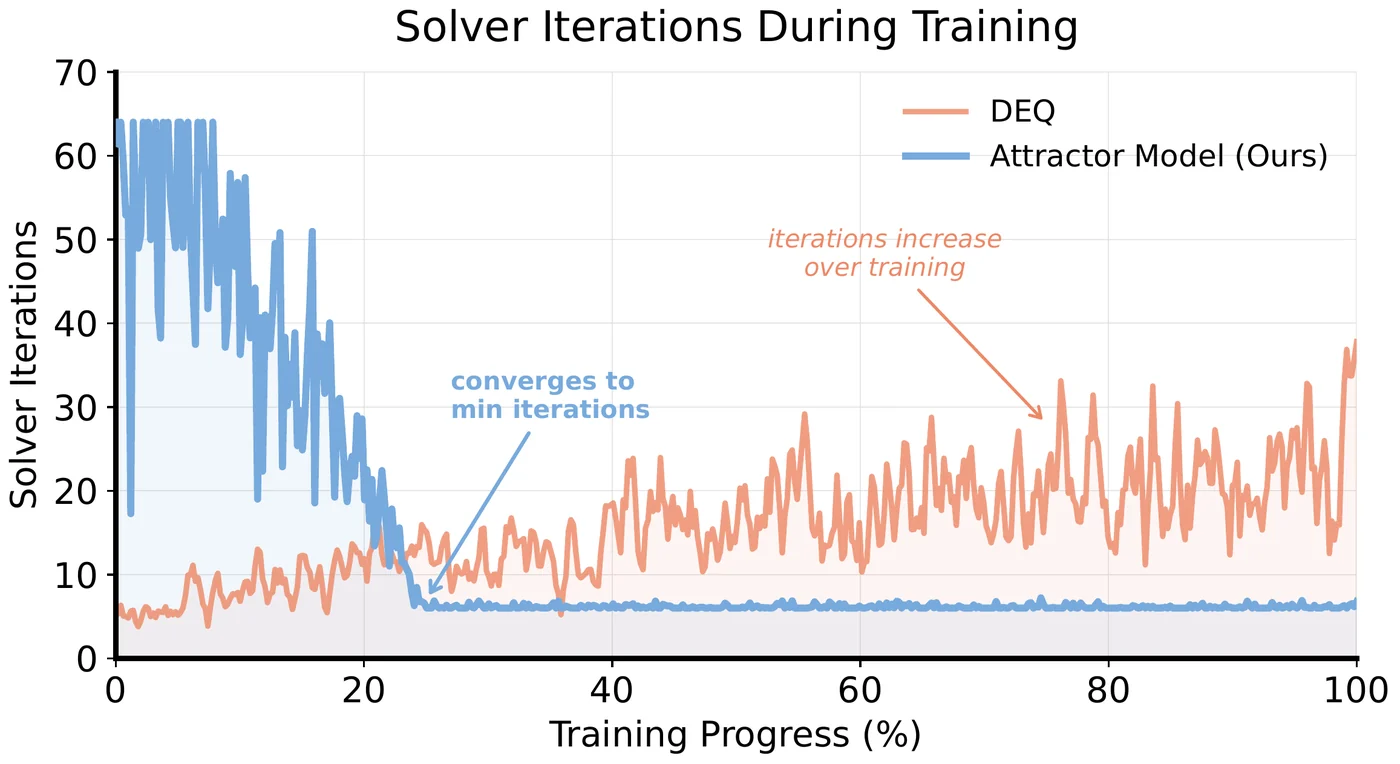
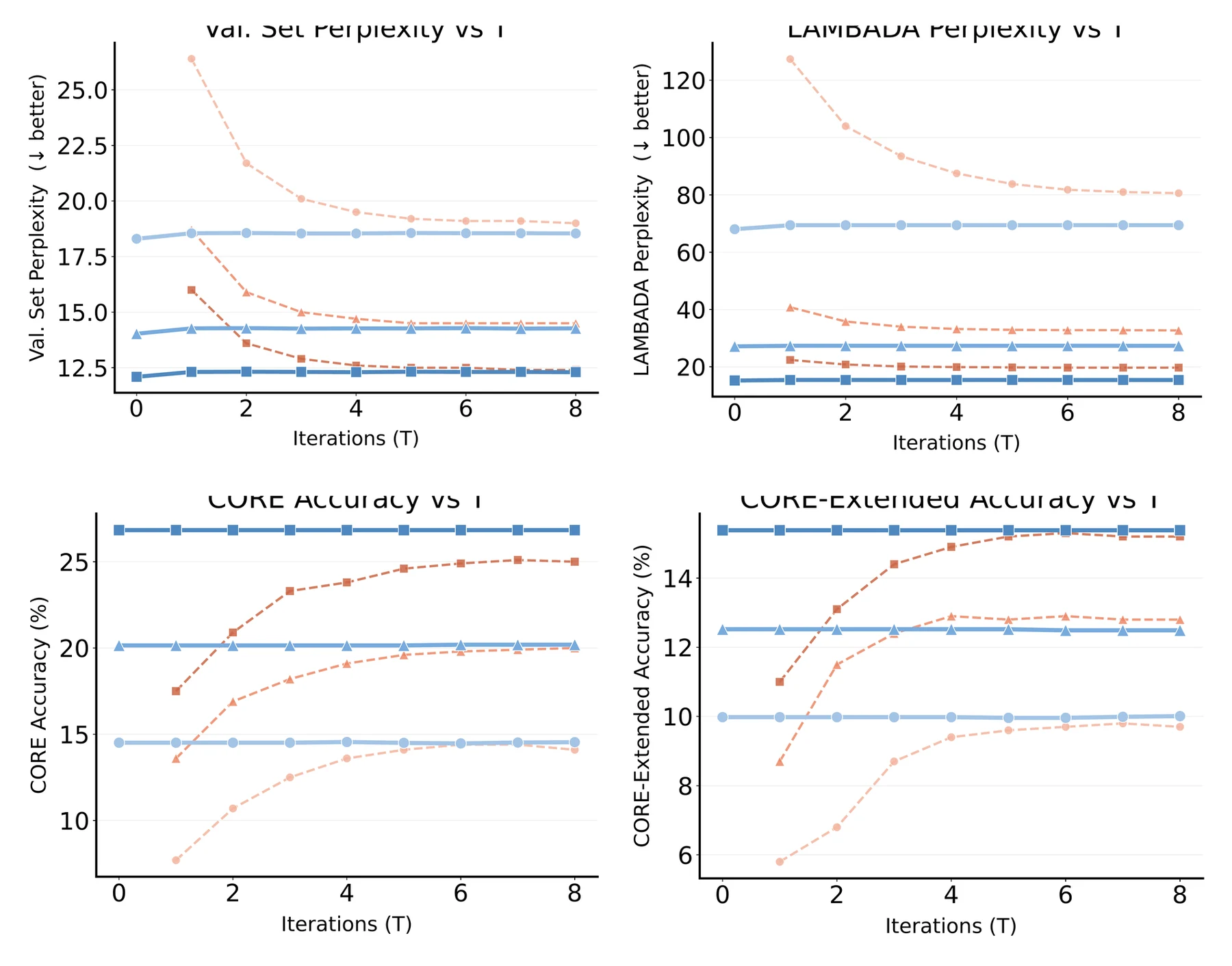
Figure 7은 이 해석을 inference 쪽에서 다시 확인한다.
Parcae는 test-time iteration T를 늘릴수록 validation PPL, LAMBADA PPL, CORE accuracy가 좋아지다가 T≈8 근처에서 plateau에 도달한다.
반면 Attractor는 모든 크기에서 T=1에 거의 peak를 찍고, 770M에서는 T=0, 즉 backbone proposal을 바로 decode해도 거의 수렴한 품질에 가깝다.
이 현상은 실무적으로 꽤 중요하다.
반복 구조를 넣은 모델은 보통 inference latency가 걱정된다.
하지만 Attractor 논문이 맞다면 fixed-point solver는 배포 시 매 토큰마다 깊게 도는 비용이라기보다, 학습 중 backbone을 더 좋은 출력 임베딩으로 유도하는 implicit teacher에 가깝게 작동할 수 있다.
즉 recurrence가 추론 시간 계산 budget이 아니라 학습 과정의 shaping mechanism으로 변한다.
Ablation도 이 방향을 뒷받침한다.
60.3M 모델에서 DEQ hidden equilibrium은 validation PPL 42.18, tied unembedding DEQ는 38.74, output embedding equilibrium과 backbone proposal initialization을 쓰는 Attractor는 34.05까지 내려간다.
Proposal injection 역시 initial-only 방식은 convergence가 12.4%에 그치고 PPL 51.92로 나쁘지만, additive injection은 PPL 34.05, 평균 8.4 iterations, 99.7% convergence를 기록한다.
Full IFT backward는 PPL 33.91로 조금 더 좋지만, one-step approximation은 PPL 34.05를 유지하면서 train memory와 step time을 기준점 1.0×로 줄인다.
공개 구현과 릴리스 표면
이 논문은 paper-only 주장에 머물지는 않는다. arXiv v1에는 project page와 GitHub code 링크가 있고, 공식 repository jacobfa/Attractor에는 README, MIT LICENSE, pyproject.toml, attractor/, launch_configs/, eval_configs/, experiments/, runs/, scripts/가 포함되어 있다.
README 기준 설치는 pip install -e .이고, attractor.create_model("attractor-small-140m") 또는 AttractorConfig.from_name("attractor-large-770m") 형태의 quick start를 제공한다.
Hugging Face에는 jacobfa1/attractor-140m, jacobfa1/attractor-370m, jacobfa1/attractor-770m 세 checkpoint가 올라와 있다.
2026-05-22 API 확인 기준 세 모델은 gated/private가 아니고, MIT license tag와 text-generation pipeline tag를 갖는다.
각 repo의 sibling file은 .gitattributes, README.md, config.json, model.pt 정도로 단순하다.
즉 “모델이 공개되어 있다”는 점은 분명하지만, Transformers 표준 safetensors/model card 생태계처럼 바로 범용 loader에 얹는 패키징은 아직 아니다.
릴리스 성숙도는 초기 연구 코드에 가깝다.
GitHub API 기준 repository는 2026-05-11 생성, 2026-05-20 push, MIT license, Python repository이며, 2026-05-22 확인 시점 stars 17, forks 3, open issues 0, tags 0개다.
또한 pyproject.toml의 package name이 아직 parcae로 남아 있고 README도 Parcae와 TinyRecursiveModels 위에 구축되었다고 밝힌다.
이 점은 부정적이라기보다, 이 release를 “완성된 범용 LM framework”가 아니라 Parcae 계열 연구 인프라를 확장한 reproducibility-oriented 연구 코드로 읽어야 한다는 신호다.
| 공개 표면 | 확인된 내용 | 읽는 법 |
|---|---|---|
| arXiv / project page | 논문, figure, code, HF model 링크 제공 | 방법과 실험 claim의 1차 근거 |
GitHub jacobfa/Attractor |
MIT, Python code, training/eval config, scripts, no tags | runnable research artifact에 가까움 |
| Hugging Face checkpoints | 140M/370M/770M model.pt, config.json, MIT, ungated |
checkpoint는 공개됐지만 packaging은 아직 최소형 |
| reasoning experiments | Sudoku/Maze용 experiment path와 training command 제공 | 일반 LM serving보다 실험 재현 쪽에 가까움 |
실무 관점에서의 해석
Attractor Models의 실무적 의미는 “새로운 reasoning model이 나왔다”보다 조금 더 구조적이다.
최근 LLM 연구는 test-time compute를 늘리는 방향과 training-time shaping을 강화하는 방향이 함께 움직인다.
Attractor는 그 중간에 있다.
겉으로는 recurrent inference architecture처럼 보이지만, 논문이 강조하는 효과는 학습 중 fixed-point target이 backbone을 더 좋은 초기 prediction으로 끌어당겨 inference 반복을 줄인다는 점이다.
이 아이디어가 큰 모델로 확장된다면, latent reasoning의 비용 모델이 달라질 수 있다.
지금은 더 깊은 thinking을 하려면 더 긴 CoT token, 더 많은 sampling, 더 복잡한 verifier를 붙이는 방식이 흔하다.
Attractor식 접근은 “생각을 길게 출력한다”가 아니라 “출력 임베딩이 안정된 attractor에 가깝도록 학습한다”는 방향이다.
특히 memory가 반복 깊이에 덜 묶인다면, recurrent-depth 계열이 대형 LM pretraining의 실제 선택지로 들어올 여지가 생긴다.
다만 아직은 조심해서 읽어야 한다.
첫째, 실험 규모는 770M까지이고, frontier-scale pretraining에서 같은 안정성이 유지되는지는 미지수다.
둘째, fixed-point solver가 완전히 공짜는 아니다.
논문은 internalization 때문에 inference iteration이 거의 필요 없다고 보지만, 이 현상이 task, scale, tokenizer, data mixture가 바뀌어도 유지되는지 확인해야 한다.
셋째, Sudoku-Extreme과 Maze-Hard 결과는 매우 흥미롭지만, direct grid prediction protocol의 특수성이 크다. agentic reasoning, theorem proving, coding benchmark로 바로 일반화할 수는 없다.
그럼에도 이 논문은 looped LM 연구에서 중요한 전환점을 제안한다.
반복을 “몇 번 돌릴 것인가”로 설계하지 않고, “어떤 equilibrium을 학습할 것인가”로 설계한다.
그리고 그 equilibrium이 inference-time cost가 아니라 training-time curriculum처럼 작동할 수 있음을 실험적으로 보인다.
이 관점이 맞다면, 다음 질문은 자연스럽다.
Attractor head를 더 큰 base model의 post-training에 붙였을 때도 backbone이 fixed-point teacher를 internalize할까.
그리고 이 internalization은 reasoning RL, tool-use agent, long-context memory 같은 더 복잡한 setting에서도 유지될까.