요즘 LLM을 배우는 가장 빠른 길은 완성된 API나 transformers 예제를 바로 실행하는 것이다.
실무에서는 그 접근이 자연스럽다.
하지만 그렇게 시작하면 모델이 실제로 무엇을 최적화하고, gradient가 어디로 흐르며, tokenizer와 training loop가 어떤 가정을 숨기는지 놓치기 쉽다.
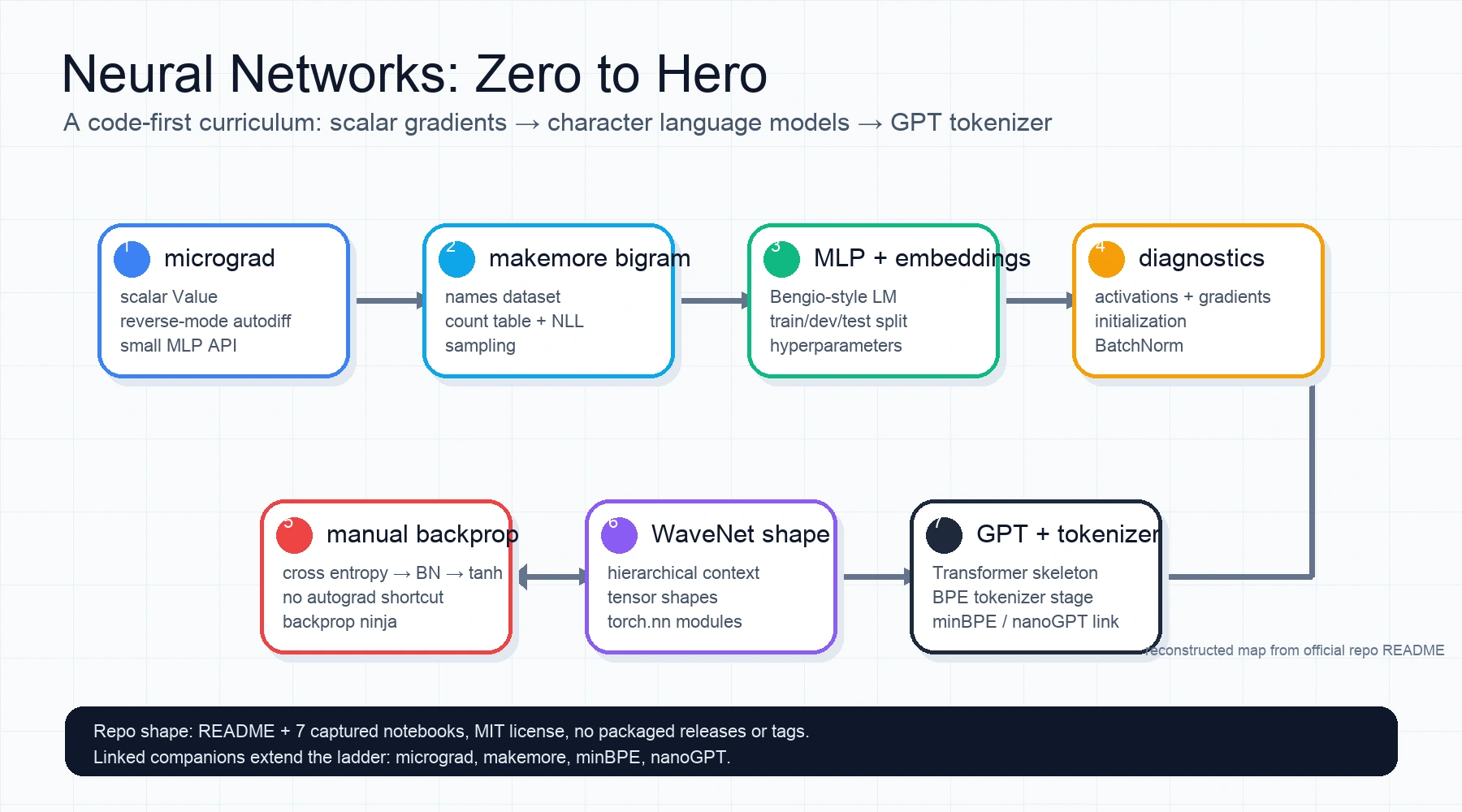
Andrej Karpathy의 karpathy/nn-zero-to-hero는 이 흐름을 일부러 거꾸로 되감는다.
이 저장소는 범용 딥러닝 라이브러리도, 최신 LLM 학습 프레임워크도 아니다.
README가 설명하듯 가장 기초적인 신경망과 역전파에서 시작해, character-level language model, BatchNorm, manual backprop, WaveNet식 계층 구조, GPT/tokenizer로 이어지는 YouTube 강의와 Jupyter notebook 아카이브에 가깝다.
이 저장소의 가치는 “새로운 모델을 배포한다”가 아니라, 현대 LLM이 서 있는 기초 부품을 코드로 다시 분해한다는 데 있다.
신경망을 loss.backward() 한 줄로 소비하기 전에, scalar 값 하나가 계산 그래프 안에서 어떻게 미분되고, 문자 하나가 다음 문자를 예측하는 확률 모델로 어떻게 바뀌며, activation과 gradient 통계가 왜 학습 안정성을 좌우하는지 직접 확인하게 만든다.
무엇을 해결하려는가
nn-zero-to-hero가 겨냥하는 문제는 성능 벤치마크가 아니라 추상화의 과속이다.
PyTorch, JAX, Hugging Face, LLM API는 모두 훌륭한 추상화지만, 너무 빨리 올라타면 학습이 실패했을 때 무엇을 봐야 하는지 알기 어렵다. loss가 내려가지 않을 때 optimizer 문제인지, initialization 문제인지, tensor shape 문제인지, data split 문제인지, softmax가 너무 자신 있게 틀리는 문제인지 감이 잘 오지 않는다.
Karpathy식 접근은 이 병목을 “작게 만들어서 끝까지 보기”로 푼다.
Lecture 1의 micrograd는 scalar Value와 reverse-mode autodiff를 손으로 구현한다.
Lecture 2 이후의 makemore는 이름 데이터셋을 character-level autoregressive language model로 바꾼다.
여기서 bigram count table, negative log likelihood, embedding table, MLP, train/dev/test split, BatchNorm, manual backprop, WaveNet식 context aggregation이 차례로 등장한다.
중요한 점은 이 repo가 “장난감 예제니까 덜 중요하다”가 아니라는 것이다.
오히려 장난감 크기이기 때문에 gradient, activation, sampling, tokenization, tensor shape 같은 핵심 개념이 숨지 않는다.
대규모 LLM 학습에서는 같은 문제가 분산 시스템, 데이터 파이프라인, mixed precision, checkpointing, serving stack 안에 묻힌다. nn-zero-to-hero는 그 전에 신경망을 디버깅 가능한 작은 시스템으로 보는 눈을 만든다.
핵심 아이디어 / 구조 / 동작 방식
저장소 구조는 매우 작다.
GitHub API 기준 기본 branch는 master이고, top-level에는 README.md, LICENSE, lectures/가 있다. lectures/ 아래에는 micrograd 강의용 notebook 2개와 makemore 강의용 notebook 5개가 들어 있다.
README는 8개 lecture를 나열하지만, 후반 GPT와 tokenizer 강의는 이 repo 안의 notebook만으로 완결되기보다 영상 설명란, minBPE, Colab, 별도 companion repo를 따라가야 하는 형태다.
| 구간 | repo 안에서 보이는 산출물 | 교육적으로 중요한 포인트 |
|---|---|---|
| Lecture 1: micrograd | lectures/micrograd/* notebook 2개, linked karpathy/micrograd |
scalar 계산 그래프, reverse-mode autodiff, 작은 MLP API |
| Lecture 2: makemore bigram | makemore_part1_bigrams.ipynb |
문자 bigram count, sampling, NLL, PyTorch tensor 감각 |
| Lecture 3: makemore MLP | makemore_part2_mlp.ipynb |
embedding table, MLP language model, train/dev/test split |
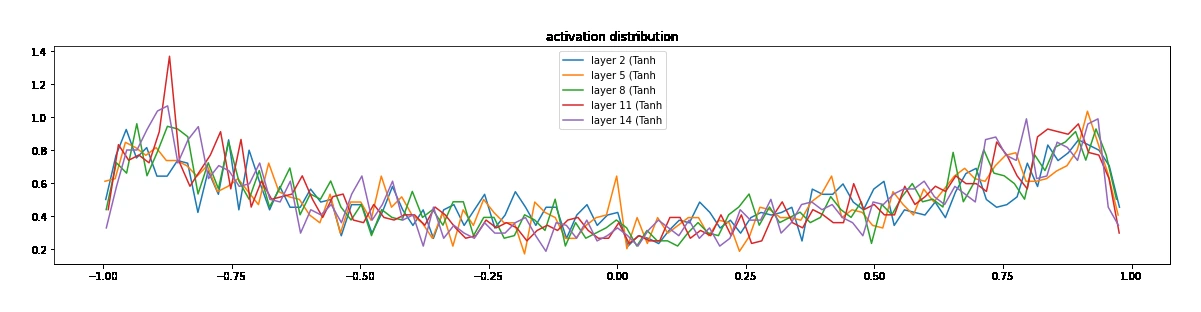
| Lecture 4: activations & BatchNorm | makemore_part3_bn.ipynb |
initialization, activation/gradient distribution, BatchNorm |
| Lecture 5: manual backprop | makemore_part4_backprop.ipynb |
loss.backward() 없이 cross entropy부터 embedding까지 직접 역전파 |
| Lecture 6: WaveNet shape | makemore_part5_cnn1.ipynb |
계층적 context aggregation, tensor shape 추적, torch.nn 감각 |
| Lecture 7~8: GPT / tokenizer | README의 YouTube·minBPE·Colab 링크 | Transformer와 BPE tokenizer를 별도 축으로 확장 |
micrograd 구간의 핵심은 Value 객체다.
숫자 하나가 연산을 거칠 때 부모 노드와 local gradient를 보존하고, 마지막 출력에서 backward()를 호출하면 그래프를 거꾸로 순회하며 gradient를 채운다. linked karpathy/micrograd repo는 이 아이디어를 “약 100줄짜리 autograd engine과 약 50줄짜리 neural net library”로 설명한다.
실제 생산용 자동미분과 비교하면 극단적으로 단순하지만, 역전파가 마술이 아니라 DAG 위의 chain rule이라는 사실을 보여주기에는 충분하다.

makemore 구간은 같은 철학을 언어 모델로 옮긴다.
이름 목록을 받아 문자 단위로 다음 문자를 예측하고, 처음에는 bigram lookup table로 시작한다.
이때 모델은 거대한 Transformer가 아니라 단순한 count matrix다.
하지만 이미 여기서 training objective, sampling, smoothing, negative log likelihood라는 언어모델링의 기본 구조가 모두 등장한다.

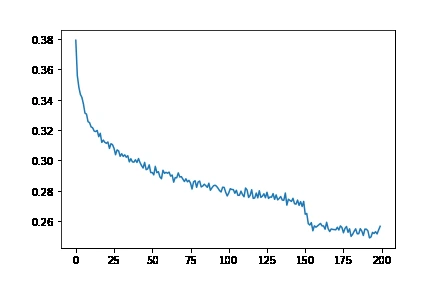
그다음 강의들은 “모델을 더 크게 만든다”보다 “모델이 왜 잘 안 배우는지 해부한다”에 가깝다.
MLP 강의에서는 embedding table과 hidden layer를 붙이고, BatchNorm 강의에서는 activation distribution과 gradient distribution을 직접 시각화한다. manual backprop 강의는 PyTorch autograd를 일부러 끄고 cross entropy, tanh, BatchNorm, embedding table을 손으로 미분한다.
이 흐름은 modern LLM stack을 바로 복제하지는 않지만, 큰 모델에서도 여전히 필요한 학습 디버깅 감각을 만든다.
WaveNet 파트도 같은 맥락에서 봐야 한다.
이 notebook은 최신 음성 생성 시스템을 재현하려는 것이 아니라, context를 한 번에 납작하게 넣는 MLP에서 벗어나 계층적으로 묶는 사고방식을 보여준다. tensor shape를 계속 추적하고, torch.nn 모듈을 직접 구성하며, loss가 어떻게 변하는지 확인한다.
이렇게 보면 GPT 강의로 넘어가는 다리는 “갑자기 Transformer가 등장한다”가 아니라, 문자 예측 문제를 더 깊고 구조적인 sequence model로 밀어 올리는 과정이 된다.
공개된 근거에서 확인되는 점
GitHub API로 확인한 현재 저장소 신호는 꽤 명확하다. karpathy/nn-zero-to-hero는 2022년 9월 생성된 공개 repo이고, 조회 시점 기준 약 22.4k stars와 3.2k forks를 갖고 있다.
주 언어는 Jupyter Notebook으로 잡히며, license는 MIT다. /releases/latest는 404이고 /tags도 비어 있어, 이 repo는 versioned package라기보다 강의 자료 아카이브로 보는 편이 맞다.
YouTube metadata 기준 README에 연결된 8개 lecture의 총 길이는 약 14.6시간이다.
Lecture 1 micrograd는 약 2시간 26분, Lecture 7 GPT는 약 1시간 56분, Lecture 8 tokenizer는 약 2시간 14분이다.
이 길이는 이 자료가 짧은 블로그 튜토리얼이 아니라, 실제로 코드를 함께 치며 개념을 압축해 가는 course에 가깝다는 신호다.
notebook 내부도 README의 설명과 잘 맞는다. micrograd notebook에는 Value class, Graphviz 기반 draw_dot, PyTorch와의 gradient 비교가 보인다. makemore notebook들은 torch, torch.nn.functional, cross_entropy, embedding table, train/dev/test split, BatchNorm, manual backprop, WaveNet/CNN식 shape 조작을 순차적으로 포함한다.
즉 repo는 “강의 제목만 모아 둔 index”가 아니라, 영상에서 만든 중간 산출물을 실제 notebook으로 보존하고 있다.
다만 release maturity를 과장하면 안 된다.
이 repo는 pip install nn-zero-to-hero 같은 소비를 기대하는 패키지가 아니고, model checkpoint나 benchmark artifact를 배포하지도 않는다.
README의 표현처럼 “This may grow into something more respectable”라는 교육용 진행형 프로젝트에 가깝다.
Lecture 7 GPT와 Lecture 8 tokenizer는 repo 내부 notebook보다 영상 설명란, karpathy/minbpe, Colab, 그리고 broader Karpathy ecosystem을 따라가야 한다.
| 확인 항목 | 관찰된 사실 | 해석 |
|---|---|---|
| 저장소 성격 | README + lectures/ notebook archive |
실행 라이브러리보다 course companion repo |
| 공개 산출물 | micrograd notebook 2개, makemore notebook 5개 | 기초 autograd와 character-level LM에 가장 강한 내부 자료 |
| license | MIT | 교육용 재사용·수정에 우호적 |
| releases/tags | latest release 404, tags 비어 있음 | 버전 관리된 패키지 release로 보기는 어려움 |
| linked companion | micrograd, makemore, minBPE, Colab, YouTube lectures | repo 하나보다 Karpathy식 “작은 구현들의 학습 경로”로 읽는 편이 정확함 |
실무 관점에서의 해석
실무 팀에서 nn-zero-to-hero를 읽는 가장 좋은 방법은 onboarding 자료다.
특히 LLM 제품이나 에이전트 시스템을 만드는 팀이라면, 대부분의 엔지니어가 모델을 API·SDK·프레임워크 단위로 먼저 접한다.
그 자체는 나쁘지 않지만, 디버깅과 연구 해석 단계에서는 “loss가 의미하는 것”, “gradient가 어디서 사라지는지”, “tokenizer가 문제를 어떻게 바꾸는지”, “sampling은 왜 품질을 바꾸는지”를 다시 내려가서 봐야 한다.
이 repo는 그 내려가는 길을 매우 잘 설계한다. micrograd는 자동미분을 black box에서 DAG로 바꾸고, makemore는 언어모델을 거대한 LLM에서 문자 예측 문제로 축소한다.
BatchNorm과 manual backprop은 학습 안정성을 숫자와 그래프로 읽게 한다.
WaveNet/GPT/tokenizer 구간은 sequence modeling이 단일 architecture 이름이 아니라, context를 어떻게 표현하고 다음 token 분포를 어떻게 만들 것인가의 연속 문제라는 점을 보여준다.
한계도 분명하다.
이 자료만으로 modern LLM training system을 이해했다고 말할 수는 없다. data mixture 설계, distributed training, optimizer scaling, mixed precision, checkpoint sharding, tokenizer vocabulary engineering, instruction tuning, RL/post-training, evaluation harness, inference serving은 거의 다루지 않는다.
또한 repo 자체가 오래된 lecture archive 성격이라 최신 nanochat·frontier model training practice와 직접 동기화되어 있다고 보기는 어렵다.
그래도 nn-zero-to-hero는 지금도 의미가 있다.
LLM 시대의 병목은 단순히 “최신 논문을 더 많이 아는 것”이 아니라, 너무 많은 추상화가 쌓인 시스템을 필요할 때 다시 분해할 수 있는 능력이다.
이 repo는 그 능력을 기르는 가장 좋은 공개 자료 중 하나다.
신경망을 결과물로 소비하기 전에, 계산 과정으로 다시 보는 훈련이라는 점에서 이름 그대로 zero to hero의 역할을 한다.