코딩 에이전트 논의는 자주 “모델이 코드를 얼마나 잘 쓰는가”로 시작한다.
하지만 **Code as Agent Harness: Toward Executable, Verifiable, and Stateful Agent Systems**는 질문을 한 단계 위로 올린다.
코드는 더 이상 에이전트가 마지막에 뱉는 산출물만이 아니라, 에이전트가 추론하고, 행동하고, 환경을 모델링하고, 검증을 받는 운영 기판이라는 것이다.
이 논문은 새로운 단일 모델이나 벤치마크를 제안하는 글이라기보다, 최근 agentic AI 시스템에서 흩어져 있던 설계 패턴을 “code as harness”라는 축으로 재정렬한 survey다.
LLM 주변의 tool, sandbox, memory, validator, permission boundary, execution loop, feedback channel이 어떻게 코드 중심의 하네스로 묶이는지 정리한다.
한 줄로 줄이면 이렇다.
좋은 코딩 에이전트는 단순히 코드를 생성하는 모델이 아니라, 코드를 통해 세계를 실행 가능하고 검증 가능하며 상태를 유지하는 시스템이다.
무엇을 해결하려는가
기존 LLM 코드 연구는 보통 “문제 설명을 주면 정답 코드를 생성하는가”에 가까웠다.
HumanEval, competitive programming, repository-level issue fixing 같은 평가도 대부분 최종 산출물이 통과하는지에 초점을 둔다.
그런데 실제 에이전트 시스템에서는 코드가 최종 산출물에 머물지 않는다.
에이전트는 코드를 써서 중간 계산을 외부화하고, API 호출을 실행하고, 파일 시스템과 shell을 조작하고, 로그와 테스트 결과를 다시 읽고, 실패를 바탕으로 계획을 고친다.
GUI 에이전트라면 DOM이나 accessibility tree를 코드형 상태로 다루고, 로봇/embodied agent라면 simulator나 skill library를 통해 세계와 연결된다.
이때 중요한 병목은 “모델이 한 번에 정답을 냈는가”가 아니다.
더 중요한 질문은 다음과 같다.
| 질문 | 왜 중요한가 |
|---|---|
| 에이전트가 어떤 파일과 상태를 볼 수 있는가 | context와 retrieval이 바뀌면 같은 모델도 다른 행동을 한다 |
| 어떤 tool과 permission boundary를 받는가 | 위험한 action은 모델 지시문이 아니라 하네스에서 막아야 한다 |
| 실패를 어떤 verifier가 판정하는가 | 테스트가 약하면 에이전트는 틀린 성공 신호를 최적화한다 |
| 여러 에이전트가 같은 코드 상태를 어떻게 공유하는가 | planner, coder, tester, reviewer가 서로 다른 snapshot을 보면 coordination이 깨진다 |
| 로그와 trajectory가 재현 가능한가 | 장기 실행 agent의 실패는 최종 결과만 봐서는 디버깅하기 어렵다 |
논문의 문제의식은 여기에 있다.
에이전트 성능은 base model 하나로 설명되지 않는다.
어떤 하네스가 모델을 감싸고 있는지, 그 하네스가 얼마나 실행 가능하고 관찰 가능하고 검증 가능한지가 시스템 품질을 결정한다.
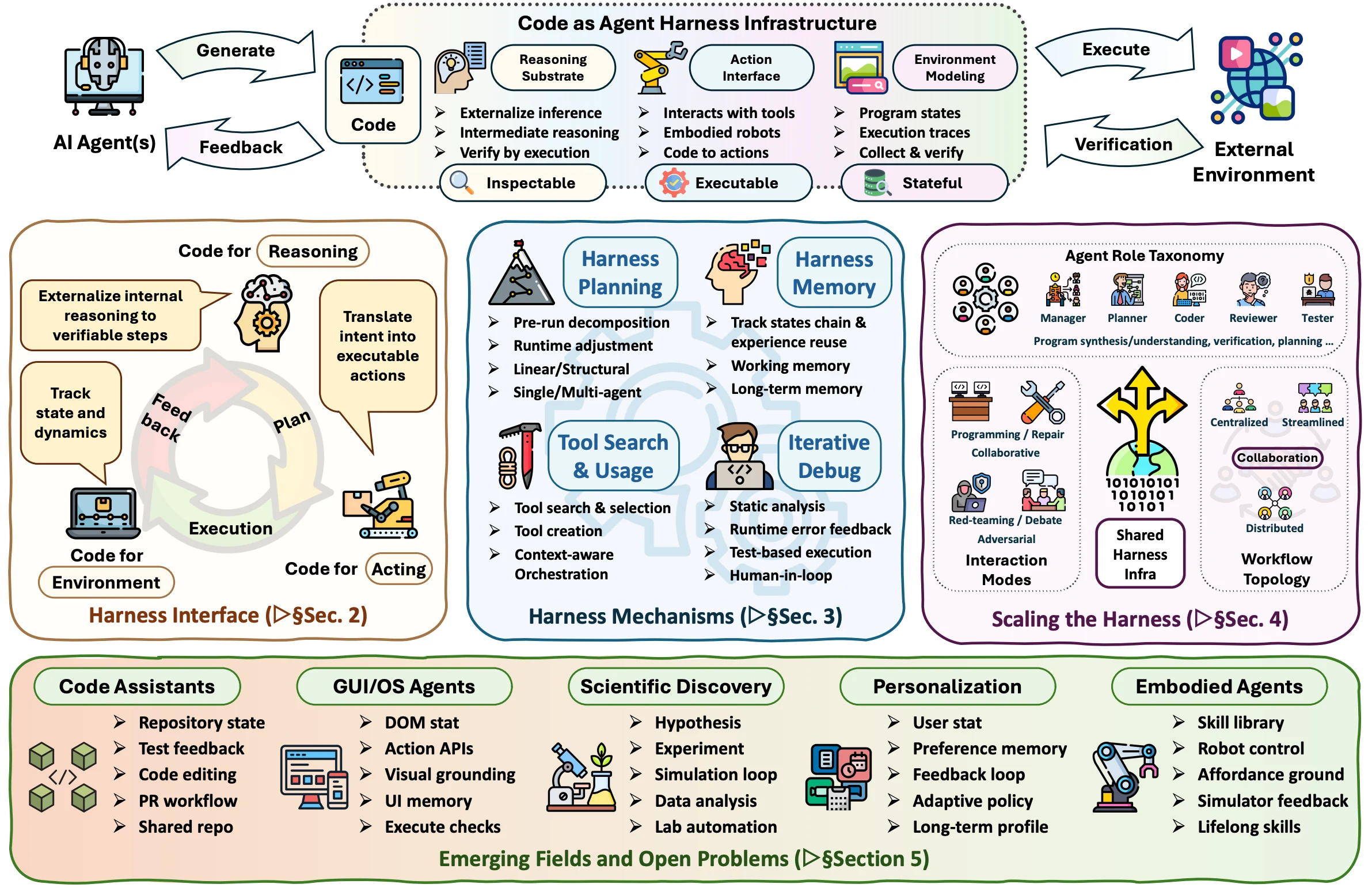
핵심 아이디어: code는 interface, mechanism, shared substrate다
논문은 code-as-harness를 세 층으로 정리한다.
| 층 | 논문에서의 역할 | 실무적으로 읽는 법 |
|---|---|---|
| Harness Interface | code가 reasoning, acting, environment modeling의 연결 매체가 됨 | 모델 출력이 말이 아니라 실행 가능한 중간 상태와 action으로 바뀌는 지점 |
| Harness Mechanisms | planning, memory, tool use, Plan–Execute–Verify loop, adaptive optimization | 에이전트가 긴 작업을 수행하며 실패를 관찰하고 상태를 유지하는 runtime 설계 |
| Scaling the Harness | multi-agent role specialization, shared code-centric substrate, feedback synchronization | planner·coder·tester·reviewer 같은 여러 에이전트가 같은 코드 상태를 기준으로 협업하는 방식 |
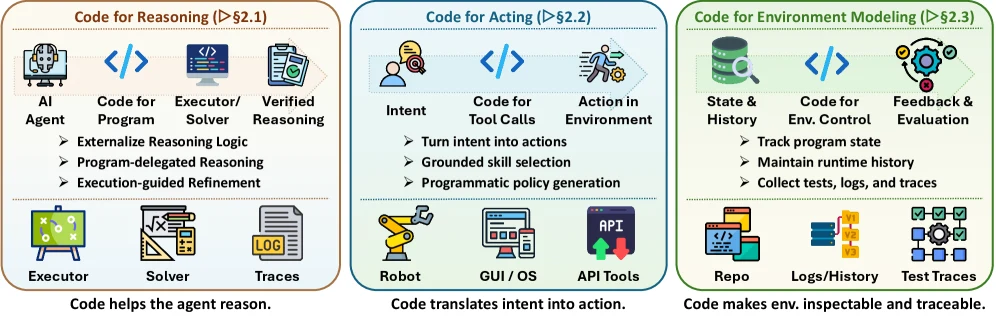
첫 번째 층인 Harness Interface에서 code는 세 가지 일을 한다.
추론에서는 내부 chain을 프로그램이나 solver 호출로 외부화한다.
행동에서는 자연어 intent를 tool call, API action, robot skill, GUI operation으로 번역한다.
환경 모델링에서는 프로그램 상태, 실행 trace, repository history, test result를 저장하고 다시 검증할 수 있게 만든다.
두 번째 층인 Harness Mechanisms는 더 실무적인 시스템 설계에 가깝다.
계획은 long-horizon task를 작은 단계와 dependency graph로 나누고, memory/context engineering은 repository evidence와 작업 상태를 오래 유지하며, tool use는 function call과 environment interaction을 제어한다.
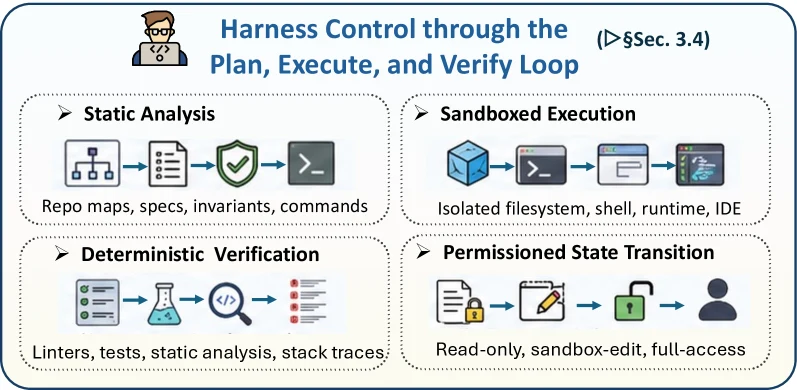
여기에 Plan–Execute–Verify 루프가 붙으면, 에이전트의 행동은 “모델이 말한 것”이 아니라 “계획하고, sandbox에서 실행하고, deterministic sensor와 human gate로 검증하는 상태 전이”가 된다.
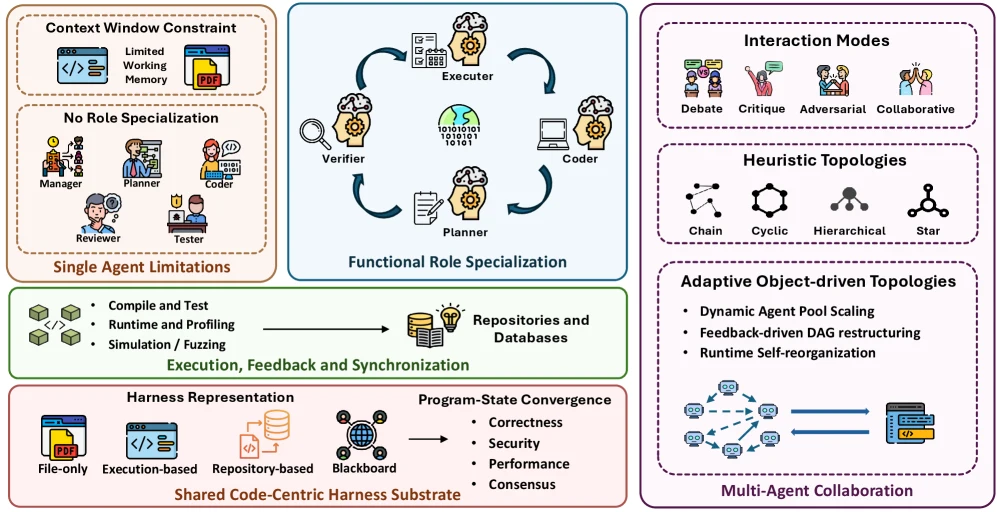
세 번째 층인 Scaling the Harness는 multi-agent 시스템의 문제다.
단일 에이전트는 context window, 역할 전문성, 자기검증 한계에 부딪힌다.
그래서 planner, coder, verifier, reviewer, tester 같은 역할을 나누고, chain/cyclic/hierarchical/star topology나 adaptive topology를 쓴다.
하지만 단순히 에이전트를 여러 개 띄운다고 문제가 해결되지는 않는다.
여러 에이전트가 같은 코드베이스를 보더라도, 서로 다른 snapshot, 오래된 memory, 충돌하는 plan, 누락된 test assumption을 들고 있으면 협업은 쉽게 깨진다.
논문이 강조하는 shared code-centric harness substrate는 바로 이 지점이다.
협업의 중심은 채팅 로그가 아니라, 실행되고 검증되고 merge될 수 있는 shared program state여야 한다.
공개된 근거에서 확인되는 점
arXiv metadata 기준 이 논문은 2026년 5월 18일 제출된 cs.CL, cs.AI 분야 survey이며, 제목은 **Code as Agent Harness**다.
HTML 버전은 Figure 1부터 Figure 12까지 taxonomy, interface, planning, memory, tool use, PEV loop, adaptive harness optimization, multi-agent scaling, application domains를 시각적으로 정리한다.
공식 companion repository와 project page도 함께 공개되어 있다.
저장소 이름은 **YennNing/Awesome-Code-as-Agent-Harness-Papers**이고, README는 이 저장소가 논문을 보조하는 paper list라고 설명한다.
즉 이 저장소는 runnable agent framework라기보다, 논문 taxonomy에 맞춰 대표 연구들을 계속 모으는 curated reading map에 가깝다.
새로 확인되는 project page는 paper, arXiv, GitHub 링크와 함께 “3 connected layers”, “6+ application areas”, “102 PDF pages”, “450+ cited work”라는 survey scope를 전면에 둔다.
2026년 6월 25일 현재 확인 가능한 공개 표면은 다음과 같다.
| 항목 | 확인되는 내용 | 해석 |
|---|---|---|
| 논문 | arXiv:2605.18747, Code as Agent Harness |
모델/벤치마크 논문보다 survey와 taxonomy 논문에 가까움 |
| 공식 HTML | arXiv HTML에 전체 section, figure, table이 공개됨 | 글의 구조와 시각 자료를 직접 확인 가능 |
| Project page | code-as-harness.github.io/code-as-harness-webpage/에서 abstract, three-layer taxonomy, application areas, open problems, citation을 제공 |
단순 PDF 링크보다 논문의 읽는 순서를 더 명확히 보여주는 공식 landing page |
| Companion repo | Awesome-Code-as-Agent-Harness-Papers README와 figs/가 taxonomy별 paper map과 overview 이미지를 제공 |
구현체가 아니라 관련 논문을 taxonomy별로 모으는 resource |
| Repo 상태 | GitHub API 기준 stars 482, forks 38, open issues 5, 기본 브랜치 main, 2026-05-07 생성·2026-05-20 최종 push, releases/tags 없음, root에는 README.md, CONTRIBUTING.md, TODO.md, MISSING_URLS.md, LICENSE, figs/가 있음 |
빠르게 관심을 받고 있지만 installable package나 실행 프레임워크라기보다 paper-facing resource bundle에 가까움 |
| 라이선스 | GitHub API와 checked-in LICENSE 기준 MIT |
companion list와 figure asset의 재사용 조건은 비교적 명확함 |
| 정리 중인 항목 | TODO.md에는 venue/arXiv ID 정정, bare-year row 재스캔, 누락 citation key 같은 cleanup 항목이 남아 있음 |
curated map은 고정된 artifact가 아니라 계속 보정되는 survey companion으로 읽어야 함 |
논문 자체의 기여도 숫자 개선보다는 개념 정리에 있다.
“우리가 어떤 benchmark에서 몇 % 올렸다”가 아니라, 최근 agentic AI에서 code가 맡는 역할을 세 층으로 정리하고, 그 위에 open problem을 세우는 방식이다.
그래서 이 글을 읽을 때도 성능표보다 taxonomy와 문제 정의를 보는 편이 맞다.
실무 관점에서의 해석
이 논문의 가장 큰 가치는 “코드 생성”과 “에이전트 운영”을 분리해서 보지 말라고 말하는 데 있다.
코딩 에이전트가 코드를 작성한다는 말은 반만 맞다.
실제로는 코드가 에이전트에게 memory이고, action surface이고, environment model이고, verification target이며, 때로는 여러 에이전트가 협업하는 shared state다.
이 관점은 agent harness engineering과도 바로 이어진다.
좋은 에이전트 시스템은 모델 endpoint를 하나 고르는 것으로 끝나지 않는다.
어떤 파일을 읽게 할지, 어떤 command를 허용할지, test failure를 어떻게 요약할지, permission tier를 어떻게 나눌지, 사람이 승인해야 하는 state transition은 무엇인지, 여러 에이전트의 변경을 어떻게 merge할지를 모두 설계해야 한다.
특히 논문이 제시하는 Plan–Execute–Verify 관점은 실무적으로 유용하다.
에이전트에게 “수정해”라고 시키는 대신, 다음 네 단계를 명시적으로 분리해야 한다.
| 단계 | 하네스가 책임져야 하는 것 |
|---|---|
| Plan | 변경 목표, 영향 범위, 검증 기준을 외부화한다 |
| Execute | sandbox, filesystem, shell, runtime, IDE 같은 실행 경계를 제한한다 |
| Verify | test, lint, static analysis, trace, human review로 결과를 판정한다 |
| Transition | read-only, sandbox edit, full access처럼 permissioned state transition을 관리한다 |
여기서 중요한 것은 verifier가 완벽하지 않다는 점이다.
테스트가 약하면 agent는 green test를 진실로 착각한다.
GUI checker가 중간의 위험한 action을 못 보면 “완료”로 기록될 수 있다. scientific agent가 잘못된 실험 가정을 코드에 넣어도 script가 돌아가면 성공처럼 보일 수 있다.
논문이 open problem에서 말하는 semantic verification과 oracle adequacy는 바로 이 문제를 겨냥한다.
Multi-agent 쪽에서도 비슷하다.
역할을 나누는 것 자체는 쉽다. planner, coder, reviewer, tester라는 이름을 붙인 agent를 여러 개 띄우면 된다.
어려운 것은 이들이 같은 상태를 보고 있는지, 누가 어떤 assumption을 읽고 썼는지, 충돌이 file diff가 아니라 plan·memory·permission·user requirement 수준에서 감지되는지다.
논문이 transactional shared program state를 open problem으로 둔 이유가 여기에 있다.
이 논문이 던지는 좋은 질문들
논문 후반의 open problem은 실제 agent runtime을 만드는 팀에게 체크리스트처럼 읽힌다.
| Open problem | 논문이 던지는 질문 | 실무적 의미 |
|---|---|---|
| Harness-level evaluation | 최종 task success와 harness 품질을 어떻게 분리해 측정할 것인가 | 모델 벤치마크만으로 agent runtime을 평가하면 안 됨 |
| Semantic verification | 실행이 성공했다는 신호가 실제 요구사항 충족을 보장하는가 | test coverage, security scanner, human review의 scope를 명시해야 함 |
| Self-evolving harness | 하네스가 스스로 바뀔 때 regression을 어떻게 막을 것인가 | prompt/tool/context 최적화도 검증과 rollback이 필요함 |
| Transactional shared state | 여러 agent와 사람이 같은 program state를 어떻게 안전하게 수정할 것인가 | file merge를 넘어 assumption, permission, memory conflict까지 다뤄야 함 |
| Human-in-the-loop safety | 어떤 action은 반드시 사람 승인 gate를 지나야 하는가 | deployment, credential, user data, financial/medical decision은 permission tier가 필요함 |
| Multimodal harness | screenshot, plot, robot state 같은 비텍스트 상태를 어떻게 저장·압축·검증할 것인가 | GUI/OS, embodied, science agent는 텍스트 로그만으로는 부족함 |
내가 보기에 가장 중요한 문장은 “final task success alone으로는 실패를 진단할 수 없다”는 쪽이다.
에이전트가 성공했는지보다, 왜 성공했는지, 어떤 verifier가 그것을 승인했는지, 그 과정이 재현 가능한지, 같은 하네스가 다음 task에서도 regression 없이 작동하는지가 더 중요해진다.
그래서 이 논문의 프레임은 단순한 survey 이상의 의미가 있다.
모델이 더 좋아질수록, 에이전트 주변의 software substrate가 더 중요해진다는 방향을 잘 포착한다.
모델은 생각하고 말하지만, 하네스는 보고, 실행하고, 기록하고, 막고, 되돌리고, 검증한다.
장기 실행 에이전트의 신뢰성은 이 두 층이 결합될 때 나온다.
정리
Code as Agent Harness는 코딩 에이전트 연구를 “코드 생성 성능”에서 “코드 중심 실행 시스템”으로 옮겨 읽게 만든다.
코드가 산출물일 뿐이라면 평가는 정답 여부로 끝난다.
하지만 코드가 하네스라면 평가는 execution, inspectability, statefulness, permission, feedback, coordination까지 확장된다.
실무 팀에게 이 논문은 특정 도구를 도입하라는 글이 아니다.
오히려 지금 쓰는 에이전트 환경을 다시 보게 만든다.
에이전트가 무엇을 볼 수 있는지, 무엇을 실행할 수 있는지, 무엇을 기억하는지, 어떤 실패 신호를 믿는지, 사람이 어디에서 승인하는지, 여러 agent가 같은 상태를 공유하는지 점검하라는 것이다.
앞으로 좋은 agent system은 더 똑똑한 모델 하나가 아니라, 실행 가능하고, 검사 가능하고, 상태를 보존하며, 거버넌스가 있는 하네스 위에서 만들어질 가능성이 크다.
이 논문은 그 방향을 “code as agent harness”라는 이름으로 정리한 로드맵에 가깝다.