LLM 에이전트 논의는 대개 “무엇을 할 것인가”에 집중한다.
어떤 도구를 호출할지, 어떤 파일을 고칠지, 어떤 웹페이지를 열지, 어떤 명령을 실행할지에 대한 policy가 중심이다.
하지만 실제 에이전트 루프에서는 그 다음 질문이 바로 따라온다.
그 행동을 하면 환경이 어떻게 바뀌는가.
Qwen-AgentWorld: Language World Models for General Agents는 이 두 번째 질문을 정면으로 다룬다.
Qwen Team은 에이전트가 행동한 뒤 돌아오는 다음 관찰, 즉 터미널 출력, API 응답, 검색 결과, DOM 변화, UI hierarchy, 파일 시스템 상태를 예측하는 모델을 language world model로 정의한다.
공개 패키지는 arXiv 논문, Qwen 공식 블로그, GitHub 저장소, Hugging Face 모델 Qwen/Qwen-AgentWorld-35B-A3B, 그리고 데이터셋 Qwen/AgentWorldBench로 이어진다.
핵심은 이것이 단순한 “에이전트 전용 프롬프트”가 아니라는 점이다.
Qwen은 환경 모델링을 CPT 단계부터 학습 목표로 넣고, SFT로 next-state-prediction reasoning을 활성화한 뒤, RL로 simulation fidelity를 다듬는다고 설명한다.
다시 말해 Qwen-AgentWorld는 에이전트의 행동 policy가 아니라, policy가 마주할 세계의 반응 함수를 언어 모델 형태로 학습하려는 시도다.
무엇을 해결하려는가
현재의 LLM 에이전트는 real environment를 직접 때려 보며 배운다.
브라우저 자동화라면 실제 페이지를 열어야 하고, SWE agent라면 실제 repo에서 파일을 읽고 테스트를 돌려야 하며, Android나 OS agent라면 UI 상태를 직접 관찰해야 한다.
이 방식은 정확하지만 비용이 크고, 느리고, 위험하며, 대규모 RL data를 만들기 어렵다.
특히 irreversible operation, proprietary deployment, GUI sandbox, 고가의 professional workflow처럼 실제 실행이 비싼 환경에서는 agent training이 쉽게 막힌다.
Qwen-AgentWorld의 문제의식은 여기서 출발한다.
에이전트에게 필요한 것은 단순한 world knowledge가 아니라 행동 이후의 상태 전이 감각이다.
예를 들어 ls, git diff, Notion MCP 호출, 검색 query, 웹 클릭, Android swipe는 모두 action이지만, 에이전트가 학습하려면 각 action 뒤에 어떤 observation이 돌아올지 예측할 수 있어야 한다.
이 예측이 틀리면 계획은 그럴듯해도 실제 환경에서는 무너진다.
논문은 언어 기반 에이전트 환경을 하나의 transition problem으로 정식화한다.
모델은 system prompt, 이전 observation/action history, 현재 action을 보고 다음 observation을 생성한다.
그래서 Qwen-AgentWorld는 “대답을 잘하는 모델”보다 “환경이 다음에 무엇을 보여줄지 흉내 내는 모델”에 가깝다.
이 관점에서는 terminal output, tool response, accessibility tree, browser DOM, IDE diff가 모두 같은 종류의 학습 대상이 된다.
핵심 아이디어 / 구조 / 동작 방식
Qwen-AgentWorld가 다루는 범위는 넓다.
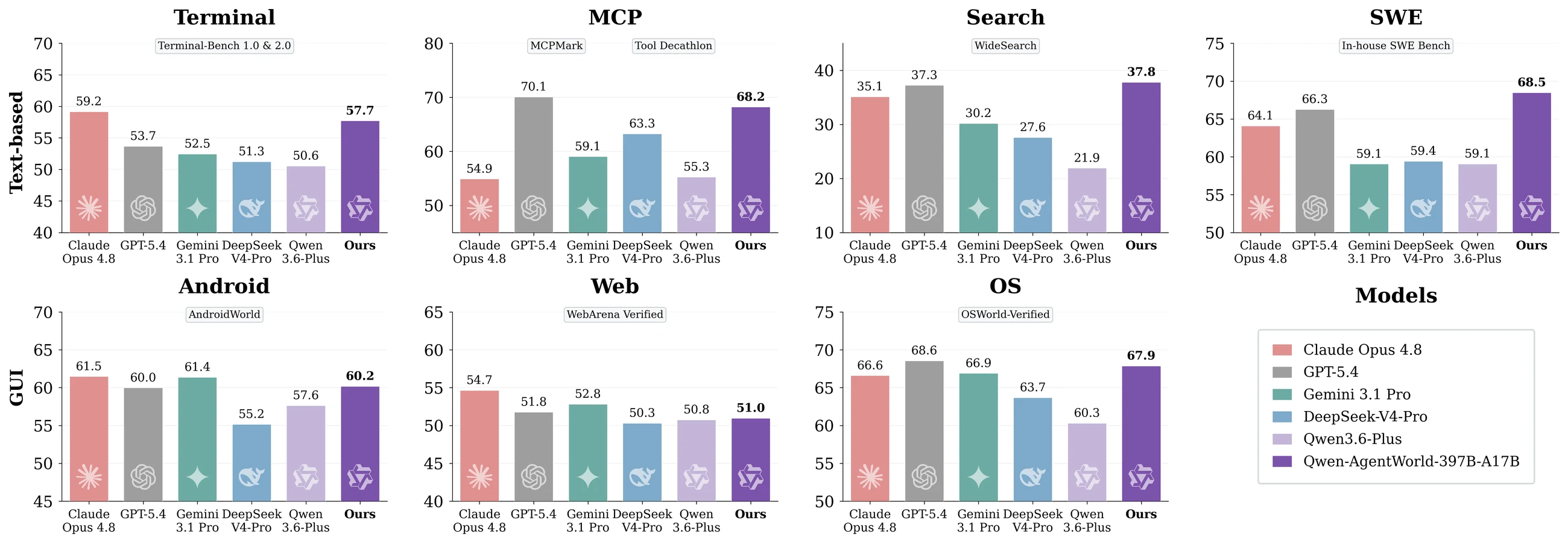
논문과 README는 7개 domain을 하나의 schema로 통합한다.
텍스트 중심 환경인 MCP, Search, Terminal, SWE와 GUI 중심 환경인 Android, Web, OS를 함께 다루며, GUI도 pixel 대신 accessibility tree, HTML, UI hierarchy 같은 text-renderable representation으로 모델링한다.
| 도메인 | 모델이 예측하는 관찰 | 실무적 의미 |
|---|---|---|
| MCP | tool call 결과, DB/API 상태, 서비스 protocol 응답 | 도구 호출이 연쇄될 때 schema와 상태를 유지해야 한다 |
| Search | query 결과, URL·snippet·page content | 단순 답변이 아니라 검색 표면의 ranking과 factual detail을 흉내 내야 한다 |
| Terminal | stdout, shell prompt, 파일 시스템 변화 | 명령 실행과 long-context causal state를 함께 추적한다 |
| SWE | 파일 내용, diff, test/build 결과 | coding agent가 수정 뒤 받는 feedback loop를 모델링한다 |
| Android | touch/swipe/type 뒤 UI hierarchy | 화면 픽셀 대신 접근성 트리 수준에서 모바일 상태를 예측한다 |
| Web | click/type/navigation 뒤 DOM·accessibility tree | 브라우저 조작 뒤 페이지 상태를 text state로 예측한다 |
| OS | desktop window/app/file state | GUI OS agent의 관찰 표면을 언어 상태로 바꿔 다룬다 |
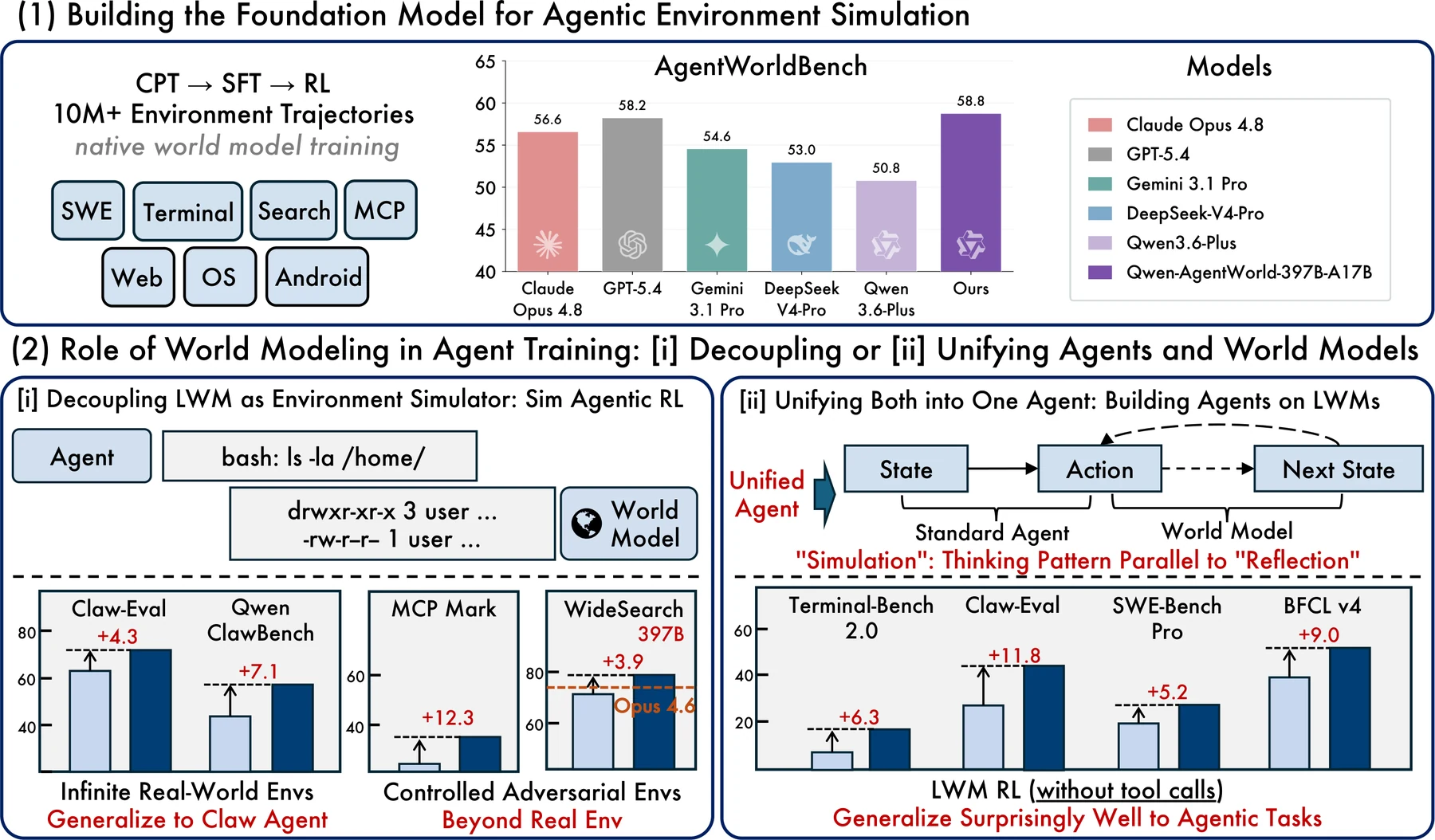
학습 pipeline은 공식 설명 그대로 CPT injects, SFT activates, RL sharpens로 요약된다.
CPT는 1,000만 개 이상의 real-world environment interaction trajectory와 전문 영역 corpora를 이용해 state transition dynamics를 주입한다.
SFT는 next-state prediction을 명시적 reasoning task로 활성화하고, paper와 model card는 256K context를 중요한 전제 조건으로 둔다.
RL은 GSPO와 hybrid rubric-and-rule reward를 사용해 환경 simulation의 fidelity를 높이는 단계로 설명된다.
적용 방식은 두 갈래다.
첫째는 Decouple이다. policy agent와 world model을 분리하고, world model을 simulator로 사용해 real environment 없이도 많은 RL trajectory를 만든다.
Qwen 공식 자료는 OpenClaw 같은 out-of-distribution 환경과 controllable perturbation, fictional-world construction을 예로 든다.
이 경우 world model은 “훈련용 가상 환경”이 된다.
둘째는 Unify다.
같은 모델을 agent foundation model로 보고, world-model training 자체를 downstream agent 능력의 warm-up으로 사용한다.
논문은 single-turn, non-agentic trajectory에서 얻은 LWM RL warm-up이 Terminal-Bench, SWE-Bench, WideSearch, Claw-Eval, BFCL 같은 multi-turn tool-calling benchmark로 전이된다고 주장한다.
이 경우 world model은 별도 simulator가 아니라 agent 내부의 미래 상태 감각을 만드는 사전학습이 된다.
공개된 근거에서 확인되는 점
공개 artifact의 모양은 비교적 분명하다.
논문은 Qwen-AgentWorld-35B-A3B와 Qwen-AgentWorld-397B-A17B를 함께 소개하지만, Hugging Face collection과 GitHub README 기준 실제 공개 weight는 Qwen-AgentWorld-35B-A3B다.
이 모델은 Qwen3.5-35B-A3B-Base 기반의 MoE 모델로, model card와 HF API는 총 34,660,610,688개 BF16 parameter, 35B total / 3B activated, 262,144 token context, Apache-2.0 license tag를 표시한다.
공개 파일은 safetensors shard 21개, config, tokenizer, chat template 등을 포함한다.
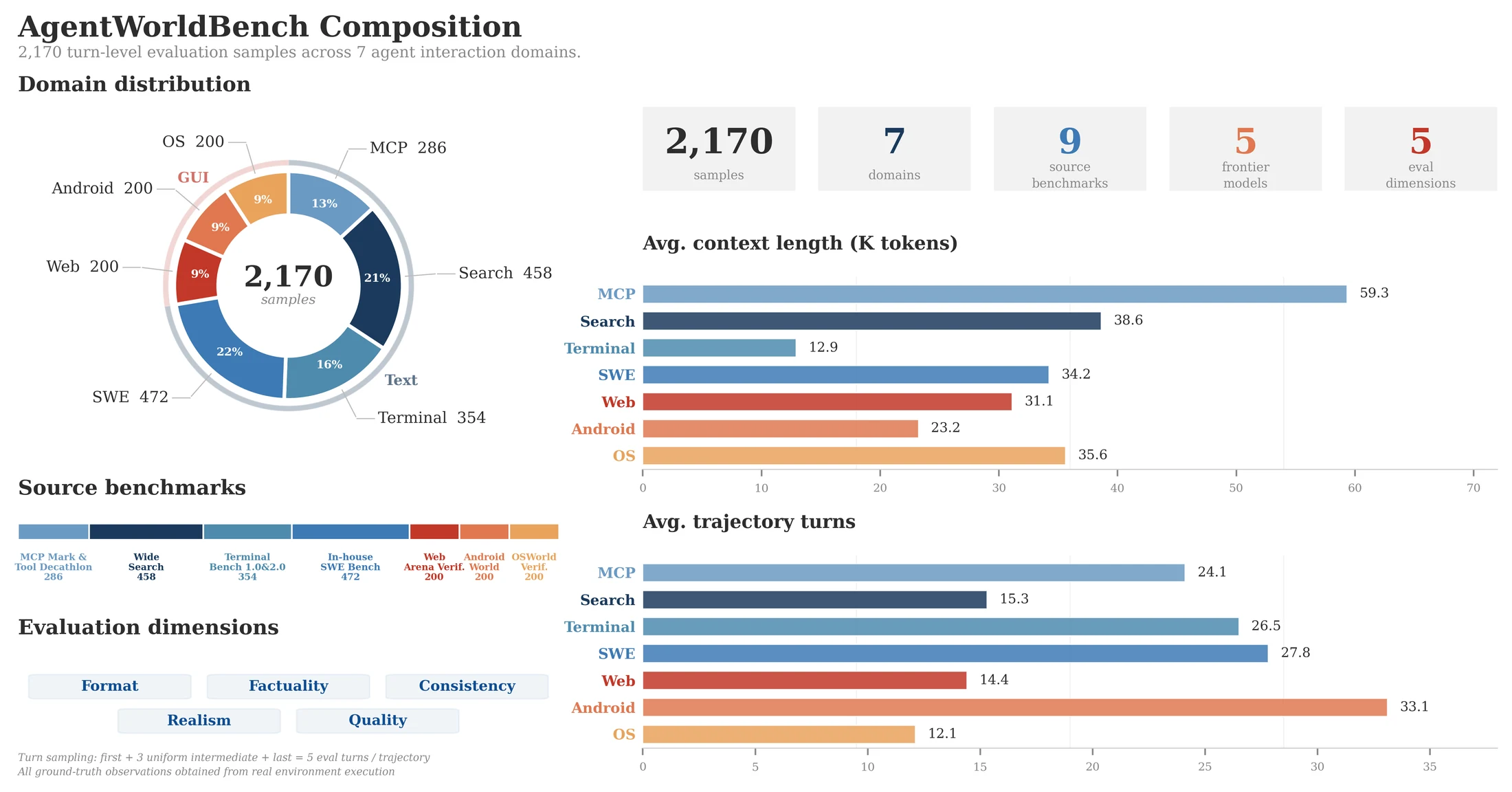
AgentWorldBench도 함께 공개되어 있다.
Hugging Face dataset API 기준 gated가 아니고 Apache-2.0 tag가 붙어 있으며, mcp_test.jsonl, search_test.jsonl, terminal_test.jsonl, swe_test.jsonl, android_test.jsonl, web_test.jsonl, os_test.jsonl 파일을 제공한다. dataset card와 공식 자료는 총 2,170개 sample, 평균 22.8 turn, 7개 domain으로 구성된 평가셋이라고 설명한다.
| 공개 표면 | 확인되는 내용 | 해석 |
|---|---|---|
| arXiv / HF Papers | 2026년 6월 23일 v1, Qwen Team, 7개 domain language world model, AgentWorldBench 제안 | 중심 기여는 에이전트 환경의 다음 관찰을 예측하는 foundation model과 평가 프로토콜이다 |
| Qwen 공식 블로그 | Paper, GitHub, Hugging Face, ModelScope, demo 링크와 Decouple/Unify 설명 | 논문만이 아니라 공식 release bundle로 포지셔닝한다 |
GitHub QwenLM/Qwen-AgentWorld |
Apache-2.0 repo, README, assets, eval, prompts, releases/latest 404, tag 목록 비어 있음 |
공개 직후 연구/모델 release hub이며 versioned software package로 보기에는 아직 이르다 |
HF model Qwen/Qwen-AgentWorld-35B-A3B |
public, ungated, Transformers/safetensors, 35B total / 3B active, 256K context, base model·dataset·paper 연결 | 실제 사용 가능한 공개 weight는 35B-A3B 쪽이다 |
HF dataset Qwen/AgentWorldBench |
2,170 sample, 7개 JSONL split, Apache-2.0 tag, benchmark card | world model 평가를 위한 ground-truth observation dataset으로 공개됐다 |
성능 표도 흥미롭다.
AgentWorldBench는 모델이 예측한 observation을 five-dimensional rubric mean으로 0–100 scale에 정규화해 평가한다.
README와 model card의 주 표에서 Qwen-AgentWorld-397B-A17B는 overall 58.71로 GPT-5.4의 58.25보다 높고, Qwen-AgentWorld-35B-A3B는 56.39로 base Qwen3.5-35B-A3B의 47.73보다 +8.66 높게 보고된다.
다만 397B-A17B는 논문/표의 평가 대상이지, 조회 시점의 HF collection에 공개 weight로 올라온 항목은 아니다.
응용 결과는 “world model이 단순 비용 절감용 mock server인가”라는 질문에 대한 Qwen의 답을 보여준다.
공식 README는 Qwen-AgentWorld-397B-A17B를 simulator로 사용한 Sim RL이 OpenClaw out-of-distribution 환경에서 Claw-Eval 65.4 → 69.7, QwenClawBench 47.9 → 55.0으로 개선됐다고 적는다.
MCP controllable simulation에서는 Tool Decathlon 32.4 → 36.1, MCPMark 21.5 → 33.8이 보고된다.
Search fictional-world construction에서는 WideSearch F1 Item과 Row가 각각 34.02 → 50.31, 13.72 → 24.21로 오른다.
Unify 쪽도 비슷한 방향이다.
Qwen3.5-35B-A3B-SFT에 LWM RL warm-up을 더한 설정은 Terminal-Bench 2.0 33.25 → 39.55, SWE-Bench Verified 64.47 → 67.86, SWE-Bench Pro 42.18 → 47.42, WideSearch F1 Item 33.38 → 46.17, Claw-Eval 53.60 → 64.88, QwenClawBench 39.76 → 49.43, BFCL v4 62.29 → 71.25로 제시된다.
숫자를 그대로 제품 성능 보증으로 읽기보다는, world-model training이 agent benchmark 전이에 영향을 줄 수 있다는 evidence map으로 보는 편이 맞다.
실무 관점에서의 해석
Qwen-AgentWorld의 가장 중요한 메시지는 agent training에서 “환경”을 별도 모델링 대상으로 끌어올렸다는 점이다.
지금까지 많은 agent framework는 실행 환경을 외부 black box로 두고, policy model만 개선하려 했다.
하지만 expensive sandbox, browser automation, mobile UI, production API, codebase state처럼 현실적인 환경은 policy가 마음껏 호출하기 어렵다. world model이 충분히 정확하다면, 일부 training loop는 실제 실행과 simulated execution을 섞어 더 큰 coverage와 더 안전한 perturbation을 만들 수 있다.
특히 controllable simulation은 실무적으로 매력적이다.
실제 production system에서 장애, 권한 오류, API schema drift, 파일 손상, 검색 결과 오염, UI edge case를 대량으로 만들기는 어렵다.
반면 language world model이 환경 반응을 어느 정도 조작 가능하게 생성할 수 있다면, agent는 평상시에는 거의 만나지 못하는 실패 상태를 더 자주 학습할 수 있다.
이 지점에서 Qwen-AgentWorld는 단순히 “가짜 환경으로 비용을 줄인다”보다 “현실에서는 만들기 어려운 분포를 훈련에 넣는다”에 가깝다.
하지만 caveat도 크다.
첫째, world model의 오류는 agent 학습에 그대로 편향을 주입한다. simulator가 특정 도구 응답을 그럴듯하지만 틀리게 만들거나, GUI state transition을 현실보다 단순화하면, agent는 실제 환경에서 깨지는 습관을 배울 수 있다.
따라서 Qwen이 AgentWorldBench에서 format, factuality, consistency, realism, quality를 분리한 것은 중요하지만, 이 rubric이 모든 operational failure를 포착한다고 보기는 어렵다.
둘째, 공개 weight와 논문 최고 성능의 범위를 구분해야 한다.
397B-A17B 결과는 논문 주장과 공식 표의 핵심이지만, 실사용자가 지금 바로 내려받아 테스트할 수 있는 것은 35B-A3B 공개 모델이다.
또한 35B라 해도 256K context와 MoE serving, vLLM/SGLang tensor parallel 구성이 필요하므로 가벼운 로컬 agent sandbox 대체재는 아니다. model card도 OOM이 나면 context window를 줄일 수 있지만, multi-turn environment simulation 때문에 최소 128K context 유지가 권장된다고 적는다.
셋째, GitHub 저장소의 성숙도는 아직 초기 release에 가깝다.
README, assets, eval, prompts는 공개되어 있지만, API 조회 기준 latest release는 404이고 tag 목록도 비어 있었다.
따라서 이 repo를 안정된 library나 long-term benchmark package로 보기보다는, 논문과 모델·데이터셋을 연결하는 공개 허브이자 초기 평가 코드 묶음으로 읽는 것이 안전하다.
그럼에도 방향성은 중요하다.
에이전트가 더 많은 외부 상태를 다루려면, policy model만 키우는 전략은 한계가 있다.
행동 이후의 관찰을 예측하는 model, 그 예측을 검증하는 benchmark, 실제 환경과 simulated environment를 섞는 training recipe가 함께 필요하다.
Qwen-AgentWorld는 이 세 가지를 하나의 release bundle로 제시했다는 점에서 agent system 연구의 기준선을 한 단계 이동시킨다.
결론적으로 Qwen-AgentWorld는 “에이전트가 더 똑똑하게 행동하게 하자”가 아니라, 에이전트가 행동할 세계를 언어 모델이 얼마나 충실하게 흉내 낼 수 있는가를 묻는 작업이다.
당장 모든 실환경을 대체할 simulator라기보다는, agent RL과 evaluation에서 real environment bottleneck을 완화하고, 실패 분포를 의도적으로 만들고, future-state reasoning을 agent 내부에 주입하기 위한 기반 모델로 보는 편이 정확하다.
앞으로 중요한 질문은 성능 표의 overall score가 조금 더 오르는지가 아니라, 이런 language world model이 실제 production agent의 안전성, 일반화, 비용 구조를 어디까지 바꿀 수 있느냐다.