Anthropic Institute의 **When AI builds itself**는 제목만 보면 “재귀적 자기개선이 곧 온다”는 선언처럼 읽히기 쉽다.
하지만 글의 실제 무게중심은 조금 더 운영적이다.
Anthropic은 AI가 이미 AI 개발 과정을 가속하고 있으며, 그 결과 인간의 역할이 “직접 실행”에서 “목표 선택, 판단, 검증, 감독”으로 빠르게 이동하고 있다고 주장한다.
핵심은 recursive self-improvement를 과장해서 이미 도착한 사건으로 포장하는 것이 아니다.
Anthropic도 “아직 거기에 도달하지 않았고, 필연적이지도 않다”고 선을 긋는다.
대신 공개 벤치마크, Claude Code 사용 데이터, 내부 연구·엔지니어링 사례를 묶어 AI 연구개발 루프의 어느 부분이 자동화되고 있고, 그 자동화가 조직의 병목을 어디로 옮기는지를 보여 준다.
무엇을 해결하려는가
이 글이 다루는 문제는 “AI가 스스로 다음 모델을 만들 수 있는가”라는 먼 질문만이 아니다.
더 가까운 질문은 다음과 같다. frontier AI lab에서 모델 개발은 코드 작성, 인프라 운영, 실험 설계, 실험 실행, 결과 해석, 다음 연구 방향 선택으로 이어지는 긴 루프인데, 이 루프 중 얼마나 많은 부분이 이미 AI에게 넘어갔는가.
Anthropic은 AI 개발 업무를 크게 두 축으로 나눈다.
하나는 engineering이다.
코드를 쓰고, 인프라를 세우고, training run을 감시하고, 문제를 디버깅하는 일이다.
다른 하나는 research다.
어떤 실험을 할지 고르고, 결과를 해석하고, 다음 아이디어를 선택하는 일이다.
글의 주장은 engineering과 well-specified research execution에서는 Claude가 이미 매우 강해졌지만, “어떤 문제가 중요하고 어떤 결과를 믿을 것인가”라는 research taste와 judgment는 여전히 핵심 병목이라는 것이다.
따라서 이 글은 recursive self-improvement를 단일한 미래 이벤트로 보기보다, AI R&D 조직에서 사람의 비교우위가 한 단계씩 좁아지는 과정으로 읽는 편이 더 정확하다.
처음에는 사람이 코드를 쓰고 모델은 짧은 snippet을 제안했다.
이후 모델이 파일을 직접 고치기 시작했다.
이제는 agent가 코드를 실행하고, 다른 agent에게 일을 위임하고, 실험 루프를 돌린다.
다음 단계가 온다면 agent가 모델 개발 루프 자체를 닫는 것이다.
핵심 아이디어 / 구조 / 동작 방식
Anthropic이 제시한 진행 구조는 “더 좋은 챗봇”의 역사가 아니라 “개발 루프 안에서 누가 무엇을 하는가”의 변화다.
| 단계 | AI의 역할 | 인간의 주된 역할 | 새로 생기는 병목 |
|---|---|---|---|
| 2021–2023: 첫 Claude 개발 | 거의 없음 | 코드·문서·실험을 직접 수행 | 사람의 실행 속도 |
| 2023–2025: Chatbots | 짧은 코드 조각과 설명 생성 | 출력 복사, 수정, 통합 | 모델 출력 품질과 사용자의 수작업 |
| 2025–2026: Coding agents | 파일 수정, 코드 실행, 일부 작업 완결 | 목표 제시, review, merge 판단 | 검증·리뷰·권한 관리 |
| Today: Autonomous agents | 장시간 작업, 다른 agent 위임, 실험 반복 | 문제 선택, 감독, 결과 해석 | research taste, human review capacity |
| 20XX?: Closing the loop | 모델을 만들고 훈련하는 루프까지 자동화 가능 | oversight, validation, governance | alignment, verifiable coordination, 통제 가능성 |
여기서 중요한 변화는 “실행”의 가격이 낮아진다는 점이다.
코드 작성, 실험 반복, 로그 조사, benchmark 실행 같은 일은 원래 연구자와 엔지니어의 시간을 많이 먹는다.
그런데 agent가 이 실행층을 맡기 시작하면, 사람은 더 많은 일을 직접 하는 것이 아니라 더 많은 작업 흐름을 지휘하게 된다.
이 변화는 낙관적 효과와 위험을 동시에 만든다.
좋은 쪽으로는 과학, 의료, 보안, 소프트웨어 품질 같은 영역에서 더 많은 실험과 개선을 빠르게 시도할 수 있다.
반대로 나쁜 쪽으로는 잘못된 목표, 약한 검증, 보안 취약점, 권한 남용, alignment 실패가 훨씬 더 빠른 속도로 증폭될 수 있다.
Anthropic이 recursive self-improvement를 기술 문제이면서 동시에 governance 문제로 다루는 이유도 여기에 있다.
공개된 근거에서 확인되는 점
Anthropic 글의 근거는 크게 외부 벤치마크와 내부 운영 데이터로 나뉜다.
외부 벤치마크는 agent의 일반적 장시간 작업 능력이 올라가고 있음을 보여 주고, 내부 데이터는 그 능력이 실제 AI lab의 코드·실험·리뷰 루프에 어떻게 들어오고 있는지를 보여 준다.
| 근거 표면 | 공개된 내용 | 읽을 때의 caveat |
|---|---|---|
| METR time horizon | AI agent가 신뢰성 있게 완료할 수 있는 task duration이 과거 약 7개월마다 두 배에서 최근 약 4개월마다 두 배로 빨라졌다고 Anthropic은 요약한다. METR의 time horizon은 사람이 걸리는 작업 시간 기준의 50% 또는 80% 성공 지점이다. | time horizon은 AI가 실제로 그 시간 동안 연속 실행했다는 뜻이 아니다. 또한 METR은 16시간을 넘는 측정은 현재 task suite로는 불안정하다고 명시한다. |
| SWE-bench / CORE-Bench | software engineering과 computational reproducibility benchmark가 빠르게 포화되고 있다는 패턴을 제시한다. CORE-Bench는 2024년 paper reproducibility task에서 약 20% 수준이던 성공률이 15개월 뒤 포화됐다고 설명된다. | benchmark 포화는 실제 업무 전체의 자동화를 곧장 의미하지 않는다. benchmark 자체의 오류, task selection, 평가 방식, open-endedness 변화도 함께 봐야 한다. |
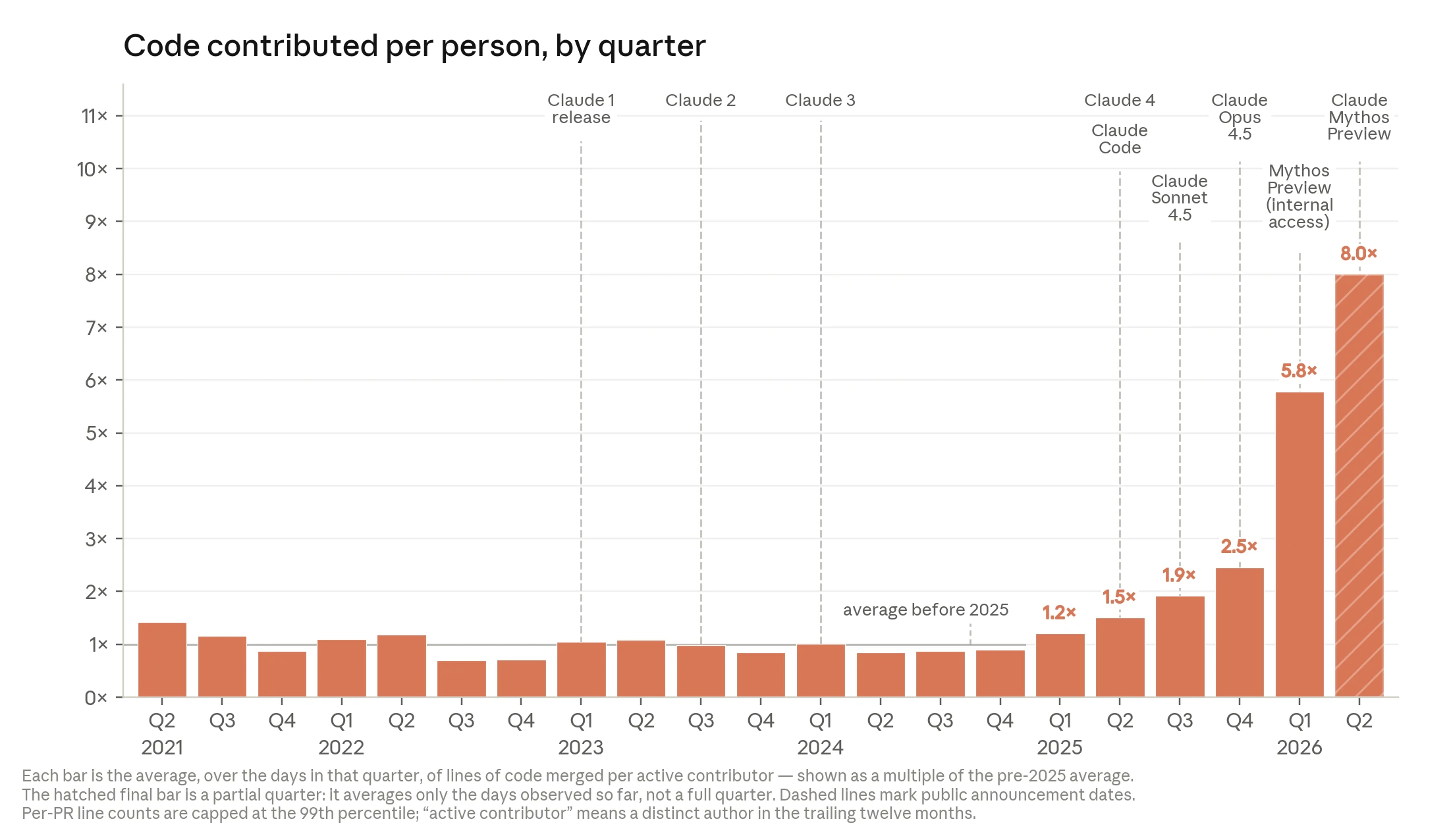
| Anthropic 코드 기여 | 2026년 5월 기준 Anthropic production codebase에 merge된 코드 라인 중 80% 이상이 Claude 작성으로 attribution됐다고 설명한다. Q2 2026의 engineer당 merged lines/day는 2024년 대비 약 8배로 제시된다. | lines of code는 품질과 생산성을 과대평가할 수 있다. Anthropic도 attribution pipeline gap과 자동 생성 코드 문제를 caveat로 둔다. |
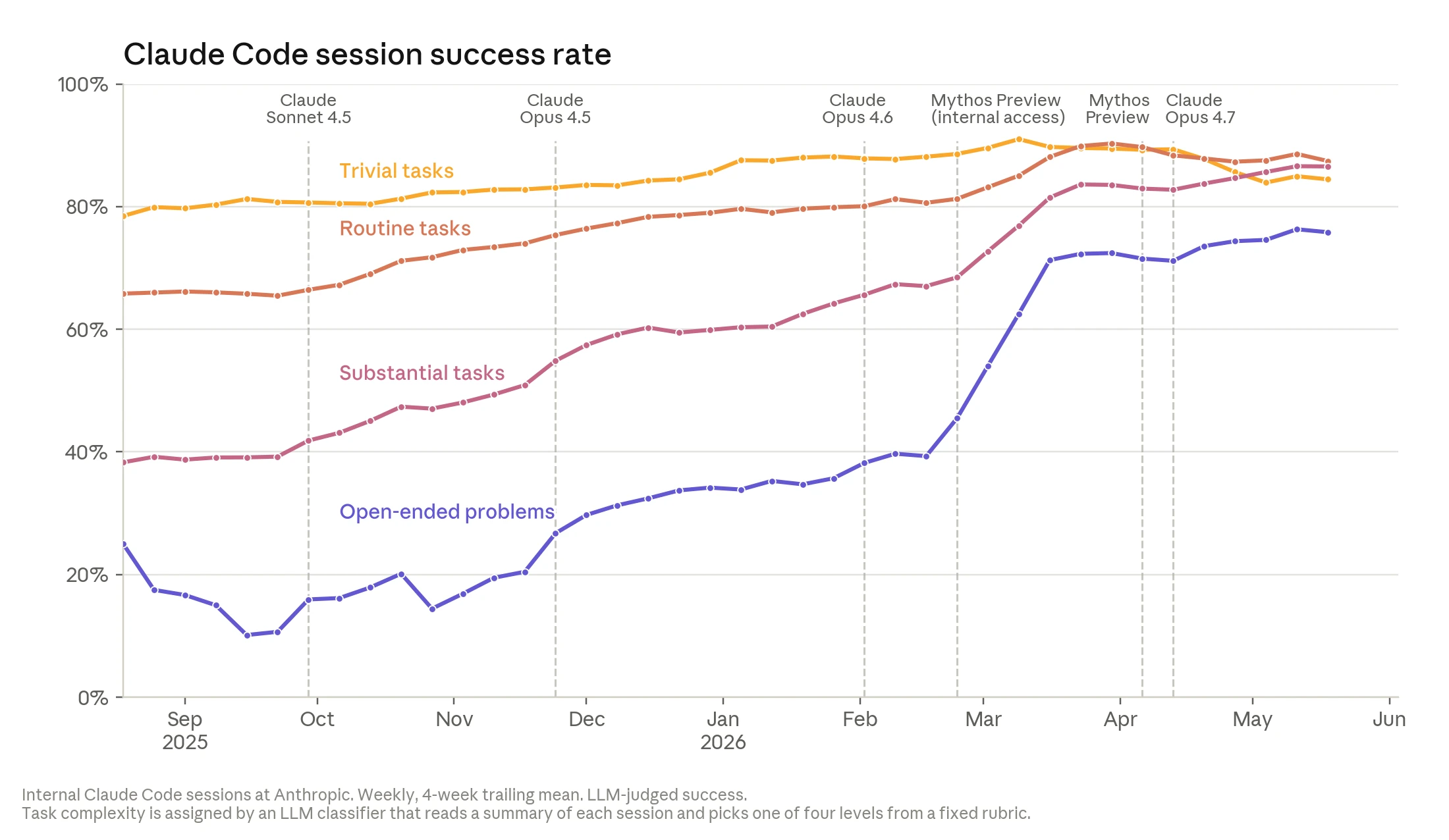
| Claude Code session success | 복잡도별 Claude Code session success rate가 개선됐고, 가장 open-ended한 task에서 2026년 5월 76%까지 올라갔다고 설명한다. | 성공 판정은 Claude judge 기반이며 workload 변화에 따라 단기 변동이 생길 수 있다. |
| 실험 실행 benchmark | 작은 모델 training code를 더 빠르게 만들라는 고정 과제에서 Claude Opus 4는 2025년 5월 약 3배 speedup, Mythos Preview는 2026년 4월 약 52배 speedup을 냈다고 설명한다. | 이 배수는 시작 코드에 남아 있던 개선 여지에 크게 좌우된다. Anthropic도 실제 training speedup 자체로 읽지 말라고 경고한다. |
| Automated weak-to-strong researcher | Claude-powered agents가 weak-to-strong supervision 문제에서 800 cumulative hours, 약 18,000달러 compute를 써서 gap recovered 97%를 달성했고, 두 인간 연구자의 약 23% 결과를 넘었다고 설명한다. | 인간이 문제와 scoring rubric을 정했고, 결과가 production-scale 모델로 깨끗하게 이전되지는 않았다. 방향 설정은 여전히 사람이 했다. |
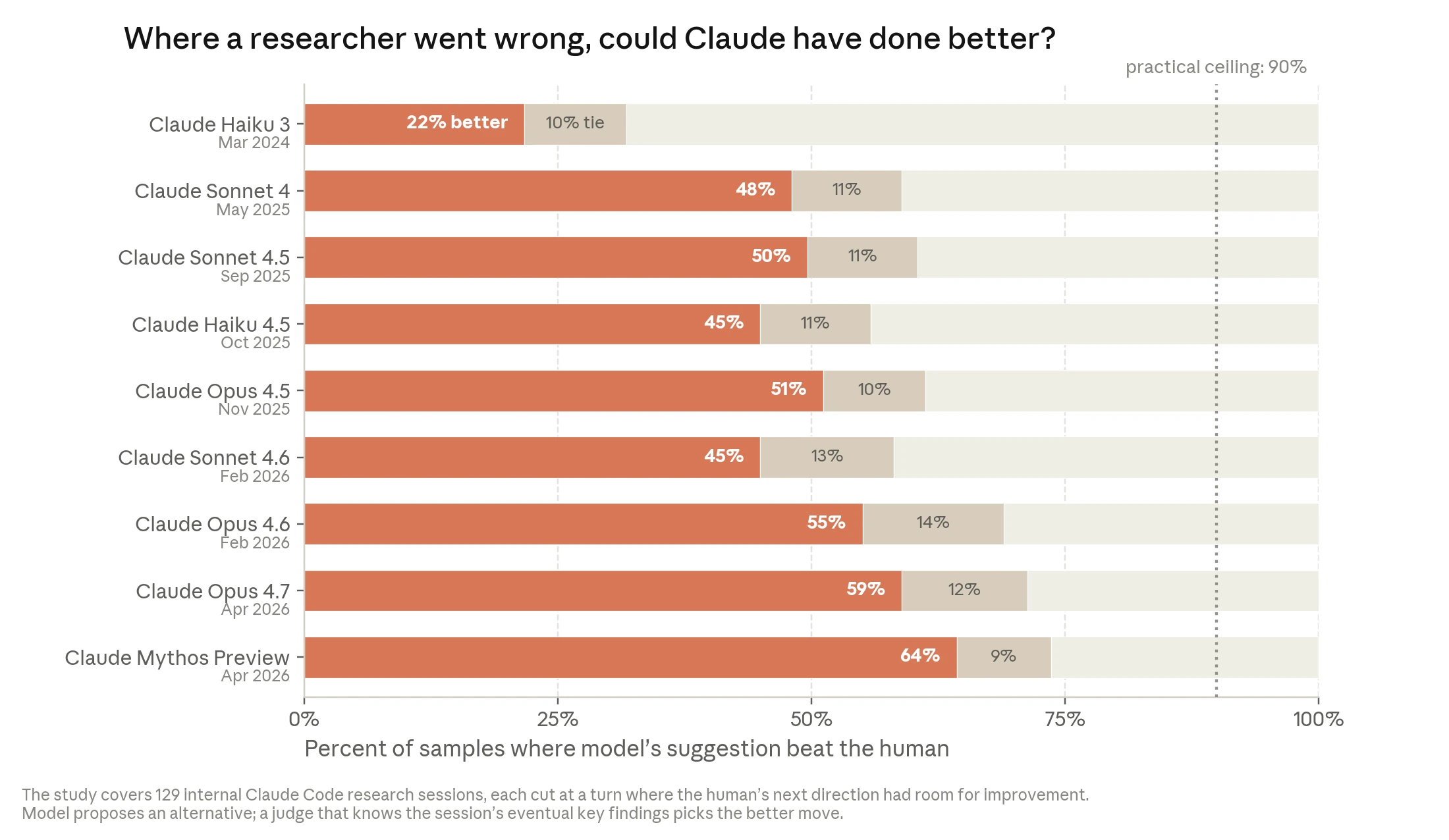
| 연구 next-step 판단 | Anthropic 내부 Claude Code 연구 세션 중 사람이 detour한 129개 순간을 골라, 모델이 더 나은 다음 단계를 제안했는지 비교했다. Opus 4.5는 51%, Mythos Preview는 64%에서 human choice를 앞섰다고 설명한다. | 일부러 “사람의 선택에 개선 여지가 있던 순간”을 고른 비교다. 별도 check set에서는 모델 제안이 더 낫다고 판정된 비율이 약 20%였다는 caveat가 있다. |
이 근거들을 한 문장으로 압축하면, Claude가 이미 실행층에서는 사람의 시간을 크게 아끼고 있지만, 무엇을 해야 하는지 정하는 일과 결과를 믿어도 되는지 판단하는 일은 아직 완전히 대체하지 못했다는 것이다.
이것이 바로 Anthropic이 말하는 현재와 recursive self-improvement 사이의 간격이다.
실무 관점에서의 해석
AI 제품·연구 조직 입장에서 이 글의 가장 중요한 포인트는 “모델이 코드를 많이 쓴다”가 아니다.
더 중요한 것은 작업 시스템의 병목이 바뀐다는 점이다.
코드 생성이 빨라지면 code review가 병목이 된다.
실험 실행이 빨라지면 어떤 실험을 할지 고르는 것이 병목이 된다. agent가 버그를 더 많이 고치면, 조직은 patch를 받아들이고 배포하고 regression을 막는 프로세스를 더 빨리 만들어야 한다.
이것은 Amdahl’s law의 조직 버전이다.
하나의 단계가 10배 빨라져도 나머지 단계가 그대로라면 전체 속도는 제한된다.
Anthropic 글이 흥미로운 이유는 이 법칙이 실제 AI lab 내부에서 벌어지고 있음을 드러내기 때문이다.
더 많은 코드가 조직 안으로 밀려 들어오면서 human review capacity가 새 병목이 되고, 더 많은 아이디어와 simulation이 쏟아지면서 무엇을 추적하고 무엇을 버릴지의 운영 능력이 중요해진다.
실무 팀이 이 글에서 바로 가져갈 질문은 다음에 가깝다.
| 질문 | 왜 중요한가 |
|---|---|
| agent가 생성하는 산출물을 누가, 어떤 기준으로 review하는가 | 생성 속도가 review 속도를 넘으면 품질과 보안 리스크가 누적된다. |
| 실험이 싸졌을 때 무엇을 실험하지 않을지 정하는 기준이 있는가 | 실행 비용이 낮아지면 나쁜 아이디어도 더 빠르게 늘어난다. |
| 성공 지표와 rollback 조건이 명확한가 | agent execution은 verification surface가 약하면 그럴듯한 실패를 대량 생산할 수 있다. |
| 사람이 방향 설정만 맡을 때 context loss를 어떻게 막는가 | 사람이 직접 손을 덜 대면 시스템이 실제로 무엇을 하고 있는지 잃어버릴 수 있다. |
| 조직이 더 빨라진 실행층에 맞춰 governance와 audit trail을 설계했는가 | recursive하지 않더라도 compounding efficiency gain은 권한·감사·승인 흐름을 압박한다. |
개인적으로 이 글의 가장 현실적인 해석은 “곧 AI가 혼자 다음 세대 모델을 만들 것이다”가 아니라, AI lab의 인간은 점점 더 연구 관리자, 검증 설계자, 병목 제거자, governance operator에 가까워진다는 것이다.
직접 타이핑하는 일보다 더 중요한 것은 목표를 정하고, 안전한 권한 경계를 만들고, agent가 만든 결과를 기계적으로 검증할 수 있는 환경을 설계하는 일이다.
거버넌스 관점에서 남는 질문
Anthropic은 가능한 미래를 세 가지로 나눈다.
첫째, 현재 추세가 S-curve처럼 꺾이지만 오늘의 capability가 넓게 확산되는 세계다.
둘째, AI lab들이 계속 compounding efficiency gain을 얻되 인간이 연구 방향과 결과 판단을 맡는 세계다.
셋째, AI systems가 full recursive self-improvement에 도달해 스스로 후속 시스템을 만들기 시작하는 세계다.
Anthropic이 보기에는 두 번째 시나리오가 가장 그럴듯한 현재 경로에 가깝다.
하지만 두 번째 시나리오도 충분히 크다.
100명 조직이 1만 명 또는 10만 명 조직 수준의 일을 할 수 있다면, 지식 노동과 정부 서비스의 효율은 크게 바뀔 수 있다.
동시에 감시, 영향력 작전, 취약점 탐색처럼 해로운 용도도 같은 규모의 이득을 얻을 수 있다.
세 번째 시나리오가 현실화될 경우 문제는 더 어려워진다.
모델 개발 속도가 인간 노동이 아니라 compute, algorithmic efficiency, verification capacity에 의해 결정된다면, 사람의 역할은 “직접 개발”이 아니라 “virtual lab을 감독하고 검증하는 일”로 축소된다.
이때 alignment 실패나 권한 남용이 후속 모델로 누적될 수 있다는 점이 Anthropic이 가장 조심스럽게 다루는 위험이다.
그래서 글의 마지막은 기술보다 coordination으로 간다.
Anthropic은 사회와 alignment 연구가 따라잡을 수 있도록 frontier AI 개발을 늦추거나 일시 정지할 수 있는 “option”이 있으면 좋겠다고 말한다.
그러나 의미 있는 pause는 한 회사의 선언으로 충분하지 않다.
여러 국가의 여러 frontier lab이 같은 조건에서 멈추고, 서로 실제로 멈췄는지 검증할 수 있어야 한다.
AI training run은 missile silo보다 숨기기 쉽고, 입력도 범용적이며, 몰래 앞서 나갈 유인이 크다.
따라서 여기서 필요한 것은 단순한 선의가 아니라 검증 가능한 국제적 메커니즘이다.
마무리
When AI builds itself의 제목은 자극적이지만, 글의 실무적 메시지는 차분하다. recursive self-improvement는 아직 오지 않았고 필연도 아니다.
하지만 그 방향으로 이어질 수 있는 하위 루프, 즉 코드 작성, 실험 실행, 디버깅, benchmark 최적화, 일부 연구 next-step 제안은 이미 빠르게 자동화되고 있다.
따라서 지금 중요한 질문은 “AI가 인간을 완전히 대체할 것인가”보다 “AI가 실행을 거의 무료에 가깝게 만들 때, 인간과 조직은 무엇을 검증하고 어떤 방향을 선택할 것인가”다.
Anthropic의 데이터가 맞다면, AI R&D의 다음 병목은 모델이 코드를 못 쓰는 데 있지 않다.
더 많은 실행을 감당할 수 있는 review system, research taste, audit trail, governance option을 우리가 얼마나 빨리 만들 수 있는가에 있다.