프런티어급 LLM 사전학습에서 throughput은 곧 비용이다.
수조 토큰, 수천 accelerator, 수주 단위의 학습을 돌리는 환경에서는 step time 몇 퍼센트가 실제로 며칠의 GPU 시간과 연결된다.
그래서 precision은 가장 강력한 레버 중 하나지만, 4비트로 내려가는 순간 문제는 단순한 dtype 변경이 아니다. outlier, gradient rounding bias, transpose consistency, attention softmax noise 같은 수치 안정성 문제가 바로 튀어나온다.
NVIDIA의 글 “Train Models Faster with JAX and MaxText Using NVFP4 on NVIDIA Blackwell”은 이 지점을 JAX/MaxText 실행 레시피로 정리한다.
핵심은 NVIDIA Transformer Engine의 NVFP4 training recipe를 MaxText에서 켜고, Blackwell 세대 GB200·GB300에서 FP8 baseline 대비 더 높은 per-GPU TFLOP/s를 얻는 것이다.
공개 글 기준 Llama 3 8B와 Llama 3.1 405B 설정에서 NVFP4는 FP8 대비 1.31×~1.73× throughput 개선을 보였고, Llama 3 8B 10k-step C4 loss curve에서는 FP8과 거의 같은 곡선을 따라갔다고 보고된다.
흥미로운 점은 이 글이 “4비트가 빠르다”는 하드웨어 주장에 머물지 않는다는 것이다.
NVFP4를 실제 학습 recipe로 만들기 위해 어떤 GEMM만 낮출지, 어떤 scale을 둘지, RHT를 어디에만 적용할지, stochastic rounding을 어떤 tensor에만 쓸지까지 정해 둔다.
다시 말해 이 글은 JAX 사용자를 위한 실행 가이드이면서, 낮은 precision 학습을 안정화하는 시스템 설계 문서에 가깝다.
무엇을 해결하려는가
FP8 학습은 이미 대규모 LLM 학습에서 널리 쓰인다.
하지만 FP4로 내려가면 이론상 arithmetic throughput과 memory bandwidth 측면에서 더 큰 이득을 기대할 수 있다.
문제는 4비트 floating point가 표현할 수 있는 값의 해상도와 범위가 매우 좁다는 점이다.
NVIDIA Transformer Engine 문서 기준 NVFP4 값 자체는 E2M1, 즉 sign 1bit, exponent 2bit, mantissa 1bit 구조이며 magnitude는 대략 ±6까지 표현한다.
실제 tensor 값은 여기에 block scale과 tensor scale을 곱해 복원된다.
따라서 4비트 학습 recipe의 핵심은 단순히 값을 FP4로 잘라 넣는 것이 아니라, 어떤 단위로 scale을 잡고, outlier를 어떻게 누르고, rounding bias를 어떻게 줄이며, 어떤 layer는 고정밀로 남길지를 정하는 일이다.
NVIDIA가 링크한 NVFP4 pretraining paper도 Random Hadamard Transform, 2D quantization, stochastic rounding, selective high-precision layers를 함께 써서 12B 모델을 10T tokens 규모로 학습했고, FP8 baseline과 유사한 loss 및 downstream accuracy를 보였다고 설명한다.
JAX/MaxText 글은 이 연구 결과를 개발자가 실행할 수 있는 경로로 내린다.
MaxText는 Google 계열의 JAX LLM training framework이고, NVIDIA JAX-Toolbox는 NVIDIA GPU에서 JAX stack을 쓰기 위한 container, CI, framework example을 제공한다.
이번 글의 실용적 메시지는 간단하다.
Blackwell 환경에서 MaxText를 쓴다면 quantization flag 하나로 NVFP4 path를 타게 만들 수 있지만, 그 뒤에는 Transformer Engine의 꽤 복잡한 안정화 recipe가 들어 있다.
핵심 아이디어 / 구조 / 동작 방식
NVIDIA 글이 정리한 NVFP4 recipe의 첫 번째 축은 16-element micro block scaling이다.
MXFP4의 32-element block보다 작은 단위를 쓰기 때문에, 한 outlier가 공유 scale 전체를 망치는 영향이 줄어든다.
여기에 block scale은 FP8 E4M3로 저장하고, 전체 tensor에는 FP32 scale을 둔다.
즉 값 자체는 4비트지만 dynamic range를 다루는 scale 계층은 더 풍부하게 설계한다.
두 번째 축은 2D weight scaling이다. weight는 16×16 block마다 FP8 scale을 둔다.
이유는 forward FPROP과 transpose를 쓰는 DGRAD에서 weight 표현이 서로 일관되도록 만들기 위해서다.
반면 activation과 gradient는 overhead를 줄이기 위해 1×16 scaling을 유지한다.
이 차이가 중요하다.
모든 tensor에 같은 scaling을 쓰는 단순 규칙이 아니라, GEMM 방향과 transpose consistency를 기준으로 scale layout을 다르게 둔다.
세 번째 축은 **Random Hadamard Transform(RHT)**와 stochastic rounding이다.
RHT는 outlier를 더 Gaussian-like하게 펴서 4비트 quantization 전에 분포를 완화하는 역할을 한다.
다만 NVIDIA 글은 RHT를 모든 경로에 붙이지 않고 WGRAD GEMM input에만 적용한다고 설명한다.
FPROP과 DGRAD에 붙이면 weight transform까지 필요해져 2D scale consistency를 깨기 때문이다.
Stochastic rounding은 작은 update가 0으로 뭉개지는 bias를 줄이기 위해 gradient quantizer에만 쓴다. weights와 activations는 round-to-nearest-even을 유지한다.
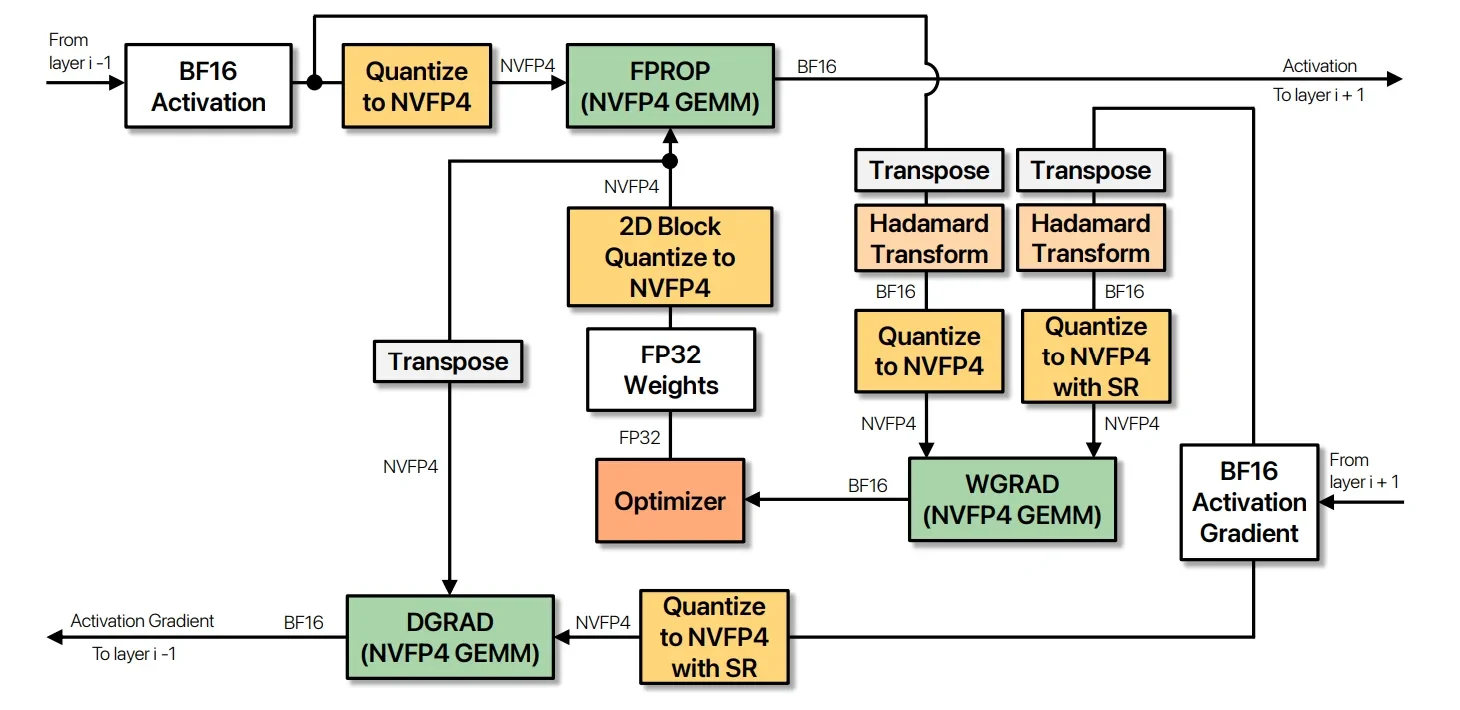
Figure 1의 compute flow도 이 관점을 잘 보여준다.
Transformer의 모든 연산을 무작정 4비트로 내리는 것이 아니라, MLP feed-forward layer의 FPROP, DGRAD, WGRAD GEMM을 NVFP4 input으로 계산하고 output은 BF16으로 둔다.
Attention block 안의 QKV projection, attention output projection, score/context matmul은 더 높은 precision에 남긴다.
NVIDIA의 설명은 명확하다.
Attention softmax는 QK^T score의 quantization noise를 지수적으로 증폭할 수 있고, attention activation에는 concentrated outlier가 많아 4비트 표현이 위험하다.
반면 MLP가 training FLOP의 큰 비중을 차지하기 때문에, MLP GEMM만 낮춰도 대부분의 속도 이득을 얻을 수 있다.
MaxText에서 노출되는 flag는 두 가지다.
quantization=te_nvfp4 # RHT 포함. no_rht 수렴이 부족할 때 권장
quantization=te_nvfp4_no_rht # RHT 없는 낮은 overhead 경로. 수렴 품질이 나빠질 수 있음
공개된 JAX-Toolbox 예제 docs/frameworks/maxtext/nvfp4/nvfp4_example.sh는 Llama 3 8B debug run을 대상으로 quantization=te_nvfp4_no_rht를 넣는다.
같은 script에서 FP8 baseline은 quantization=te_fp8_delayedscaling로 바꿔 비교한다.
실행 환경은 JAX, NVIDIA Transformer Engine, CUDA/cuDNN이 포함된 container이며, 글에서는 ghcr.io/nvidia/jax:maxtext를 권장한다.
공개된 근거에서 확인되는 점
NVIDIA 글의 benchmark는 MaxText pre-training 기준이다.
Llama 3 8B는 GB200/GB300 각각 4 GPUs, FSDP 4, sequence length 8,192, per-device batch size 4, global batch size 16으로 측정됐다.
Llama 3.1 405B는 GB200/GB300 각각 128 GPUs, FSDP 128, per-device batch size 1, global batch size 128, sequence length 8,192 설정이다.
| Model | Hardware | FP8 per-GPU TFLOP/s | NVFP4 per-GPU TFLOP/s | Speedup vs FP8 |
|---|---|---|---|---|
| Llama 3 8B | GB200 | 1497 | 2017 | 1.35× |
| Llama 3 8B | GB300 | 1759 | 2301 | 1.31× |
| Llama 3.1 405B | GB200 | 1557 | 2241 | 1.44× |
| Llama 3.1 405B | GB300 | 2103 | 3633 | 1.73× |
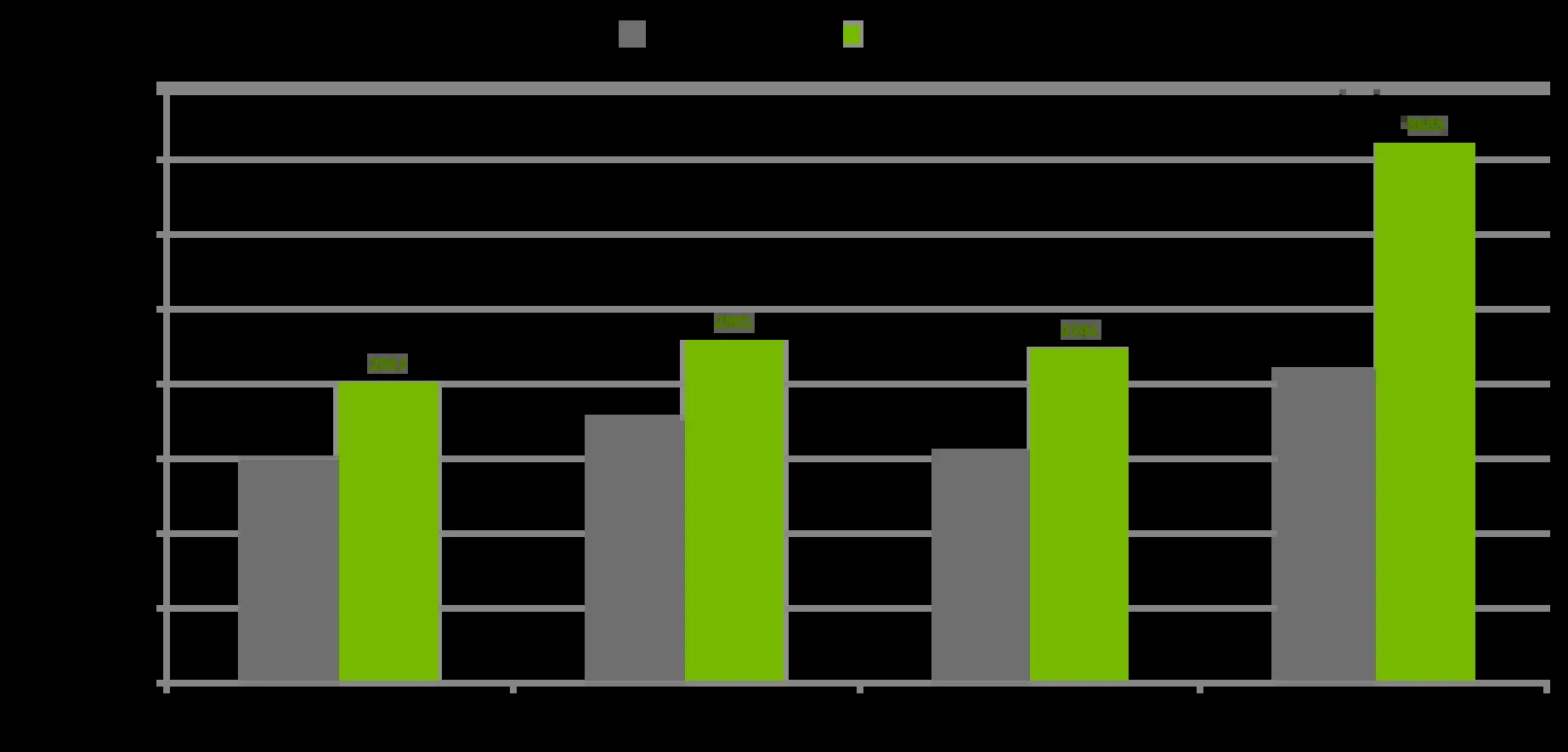
가장 큰 상대 개선은 Llama 3.1 405B on GB300의 1.73×다.
NVIDIA는 405B 설정에서 per-step GEMM 비중이 FSDP collective overhead보다 더 지배적이기 때문에 precision-level speedup이 wall-clock saving으로 더 직접적으로 이어진다고 해석한다.
반대로 8B 설정에서도 NVFP4가 FP8보다 빠르지만, 상대 개선 폭은 1.31×~1.35×로 더 낮다.
즉 NVFP4의 효과는 모델 크기, GEMM 비중, 통신 overhead 비율에 따라 다르게 나타난다.
품질 쪽 공개 근거는 Llama 3 8B 10,000-step C4 loss overlay다.
NVIDIA 글은 FP8 baseline과 NVFP4가 같은 hyperparameter에서 약 12.2 nats에서 3.9 nats까지 거의 같은 곡선을 따라 내려가며, converged regime의 평균 gap이 +0.026 nats라고 설명한다.
글의 표현대로라면 Figure 2의 throughput 개선이 이 작은 실험에서는 측정 가능한 accuracy cost 없이 나온 셈이다.
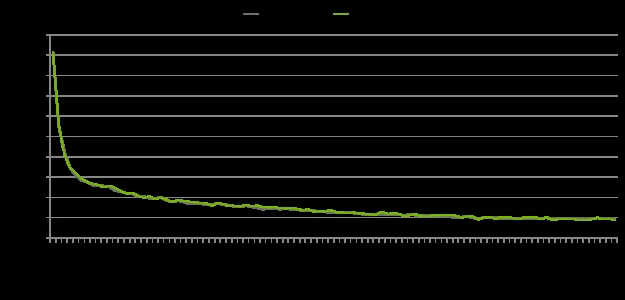
다만 이 loss curve를 “모든 학습에서 품질 손실이 없다”로 읽으면 과하다.
본문 자체도 중요한 정보는 검증하라고 안내하고, linked NVFP4 paper 역시 안정적인 4비트 학습을 위해 RHT, 2D scaling, stochastic rounding, selective high-precision layer가 함께 필요하다고 본다.
특히 public MaxText 예제의 te_nvfp4_no_rht는 overhead가 낮지만 convergence quality가 나빠질 수 있다고 명시되어 있다.
실전에서는 no-RHT path를 기본 속도 실험으로 보고, 수렴이 나쁘면 RHT 포함 path로 옮기는 방식이 더 안전하다.
| Recipe 요소 | 공개 글에서의 역할 | 실무적 해석 |
|---|---|---|
| 16-element micro block scaling | outlier가 shared scale에 미치는 영향 축소 | 4비트 값 자체보다 scale granularity가 중요 |
| E4M3 block scale + FP32 tensor scale | MXFP4의 power-of-two scale보다 표현력 있는 scaling | dynamic range 보존 장치 |
| 2D weight scaling | FPROP/DGRAD transpose 경로의 weight representation 일관성 유지 | forward/backward를 함께 보는 scale 설계 |
| WGRAD input RHT | outlier를 평탄화하되 FPROP/DGRAD 2D-scale consistency는 깨지 않음 | 모든 경로에 무작정 transform을 붙이지 않음 |
| Gradient stochastic rounding | 작은 gradient update의 rounding bias 완화 | Blackwell FP4 conversion instruction과 연결 |
| Attention 고정밀 유지 | softmax noise amplification과 activation outlier 회피 | speed path와 stability path를 분리 |
실무 관점에서의 해석
이 글의 가장 중요한 메시지는 NVFP4가 dtype 하나가 아니라 recipe라는 점이다.
4비트 학습을 성공시키려면 GEMM precision만 낮추는 것이 아니라, 어떤 layer를 제외할지, 어떤 tensor에 어떤 scaling을 쓸지, 어떤 rounding을 어디에 적용할지, RHT overhead와 convergence를 어떻게 trade-off할지까지 함께 결정해야 한다.
그래서 MaxText의 quantization flag는 간단해 보이지만, 그 아래에는 Transformer Engine과 Blackwell hardware path에 맞춘 꽤 많은 co-design이 들어 있다.
JAX 팀에게는 특히 의미가 있다.
PyTorch/NeMo 쪽 저정밀 학습 자료는 이미 많지만, JAX/MaxText에서 NVIDIA GPU를 쓰는 팀은 container, XLA flags, Transformer Engine integration, FSDP 설정까지 한 번에 맞춰야 한다.
JAX-Toolbox가 ghcr.io/nvidia/jax:maxtext container와 nvfp4_example.sh를 제공한다는 점은 재현 진입 장벽을 낮춘다.
공개 예제는 synthetic dataset, 50 steps debug run 중심이므로 그대로 production recipe는 아니지만, performance counter, step time, TFLOP/s/device, tokens/s/device, Nsight Systems trace를 수집하는 출발점으로는 충분히 구체적이다.
반대로 한계도 분명하다.
수치는 NVIDIA가 공개한 vendor benchmark이고, hardware는 GB200/GB300 Blackwell 계열이다.
Attention block을 고정밀로 남긴 선택도 중요하다.
만약 workload가 MLP GEMM 지배적이지 않거나, communication overhead가 더 크거나, sequence layout과 batch size가 다르면 같은 1.31×~1.73×가 나오리라고 가정하면 안 된다.
또한 10k-step C4 loss overlay는 수렴 신호를 보여 주지만, 장기 pretraining 품질과 downstream task는 별도 검증이 필요하다. linked paper의 12B/10T-token 결과는 NVFP4 recipe의 가능성을 뒷받침하지만, MaxText blog의 모든 설정이 그 규모 실험과 동일하다는 뜻은 아니다.
그래도 이 릴리스는 중요한 방향을 보여준다.
저정밀 학습의 경쟁은 이제 “FP8보다 더 낮은 bit width”라는 포맷 경쟁만이 아니다.
실제로는 framework flag, container, XLA/TE integration, layer별 precision policy, scale layout, rounding mode, profiler trace까지 묶인 운영 가능한 training system 경쟁이다.
NVIDIA의 JAX/MaxText NVFP4 글은 4비트 학습을 연구 논문에서 JAX 개발자의 실행 경로로 내려놓은 사례로 읽는 편이 가장 정확하다.