에이전트 시스템에서 “스킬”은 이제 단순한 프롬프트 팁이 아니다.
파일을 찾고, 도구를 호출하고, 실패 로그를 읽고, 다음 시도를 검증하는 반복 절차가 잘 추상화되면 모델은 더 긴 작업을 안정적으로 수행할 수 있다.
문제는 그 스킬을 사람이 계속 손으로 작성하고 관리하기 어렵다는 점이다.
더 큰 문제는 스킬이 많아져도 그것들이 서로 어떻게 이어지는지, 다른 모델에서도 통하는지, 실제 긴 작업에서 어떤 순서로 조합해야 하는지가 분명하지 않다는 점이다.
OpenClaw-Skill: Collective Skill Tree Search for Agentic Large Language Models는 이 문제를 스킬 자동 생성이 아니라 스킬 탐색과 전이성 평가 문제로 잡는다.
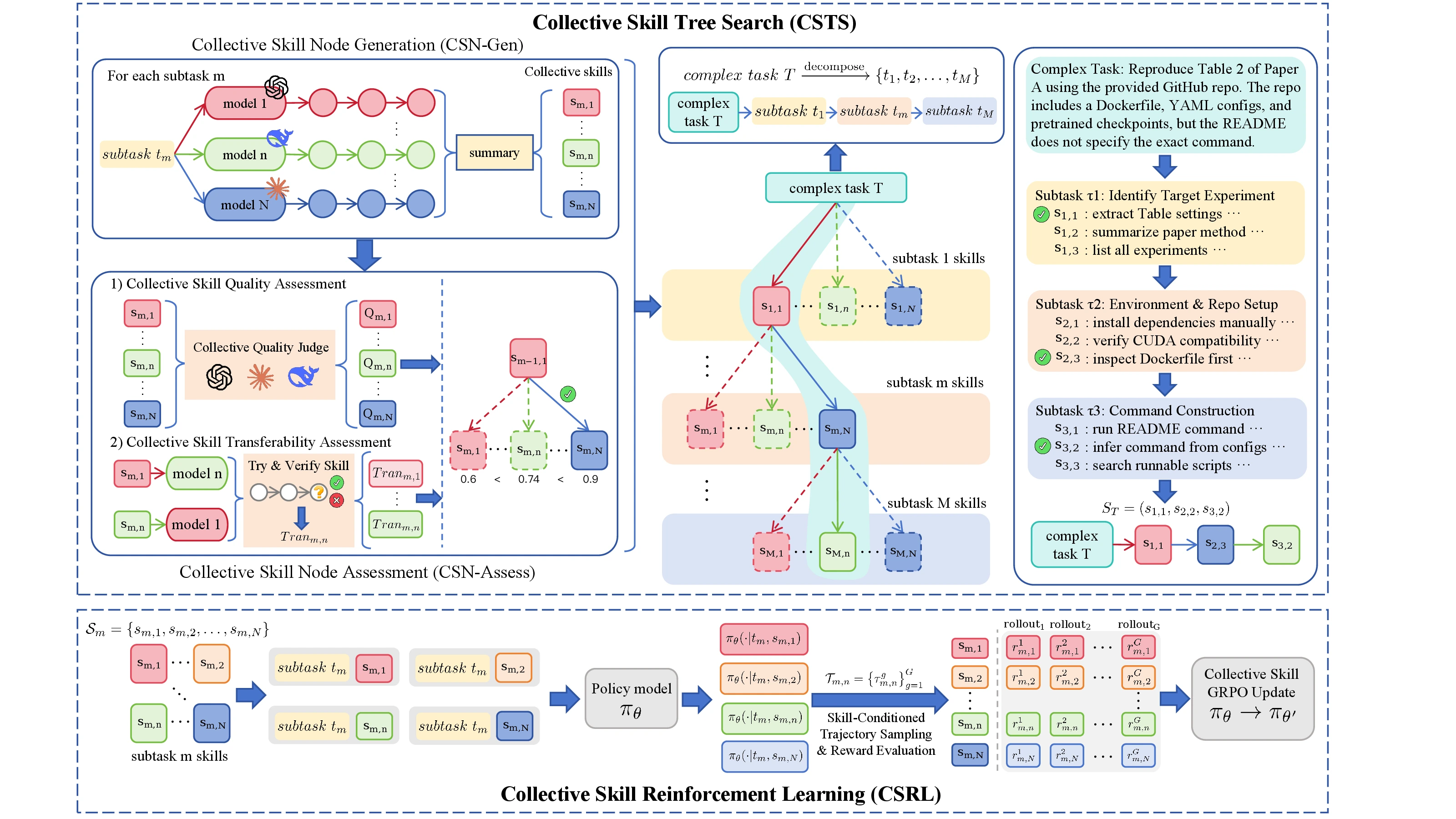
논문의 핵심 제안은 Collective Skill Tree Search, 줄여서 CSTS다.
여러 모델이 같은 하위 작업을 풀며 만든 궤적을 모아 후보 스킬을 만들고, 다시 여러 judge와 다른 모델에서의 전이 실험으로 그 스킬을 평가한다.
선택된 스킬은 낱개 목록이 아니라 task decomposition을 따라 이어지는 “tree of skills”로 정리된다.
왜 스킬 트리가 필요한가
논문이 출발점으로 삼는 OpenClaw-style 환경은 단순한 QA 벤치마크가 아니다.
에이전트가 파일시스템, 웹 페이지, 도구 호출, 코드 실행, 실행 피드백, 중간 산출물, 장기 세션 상태를 함께 다루는 환경이다.
이런 환경에서 스킬은 “검색을 잘하라” 같은 추상 조언보다 훨씬 구체적이어야 한다.
언제 어떤 파일을 먼저 열고, 실패했을 때 무엇을 확인하며, 최종 결과를 어떤 기준으로 검증할지까지 담아야 한다.
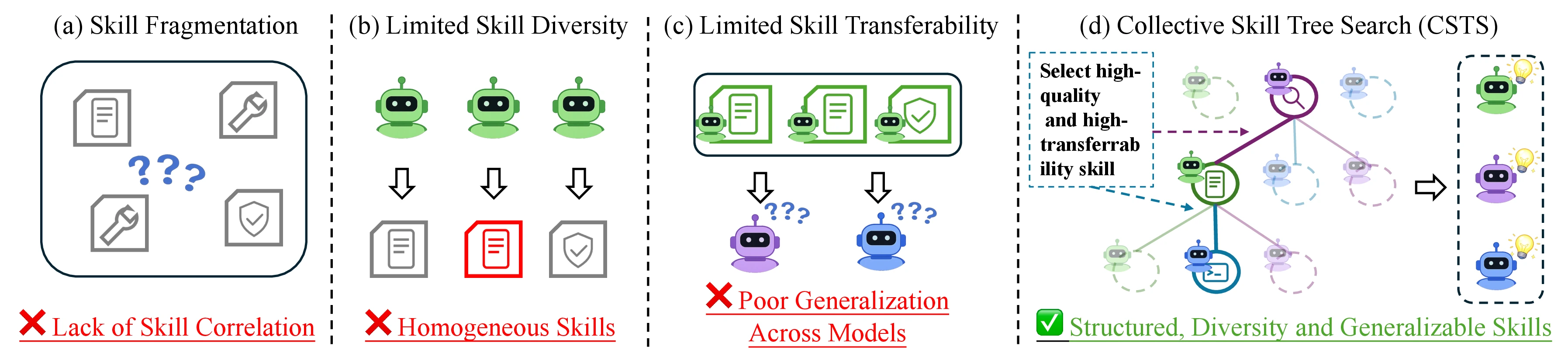
기존 스킬 구성 방식에 대해 논문은 세 가지 한계를 짚는다.
| 한계 | 논문이 보는 문제 | CSTS의 대응 |
|---|---|---|
| 스킬 단편화 | 스킬이 개별 하위 작업의 지역 절차에 머물고, 긴 작업 안에서 어떻게 연결되는지 약하다 | 복잡한 task를 ordered subtasks로 나누고, 각 layer의 스킬을 path로 연결한다 |
| 다양성 부족 | 한 모델의 trajectory에서 스킬을 뽑으면 그 모델의 습관과 실패 양식에 편향된다 | 여러 heterogeneous model의 rollout을 모아 후보 스킬을 넓힌다 |
| 전이성 부족 | 한 모델이 만든 스킬이 다른 모델에는 잘 안 먹힐 수 있다 | 후보 스킬을 다른 모델에 주고 실제 rollout score로 transferability를 본다 |
여기서 중요한 점은 CSTS가 스킬을 “문서화된 조언”으로만 보지 않는다는 것이다.
각 스킬 후보는 적용 맥락, 입력, 권장 행동, 기대 출력, 검증 기준, 복구 전략을 포함하는 절차적 노드다.
그리고 노드의 가치는 사람이 읽기에 좋아 보이는지뿐 아니라, 실제 다른 모델에게 줬을 때 도움이 되는지로 평가된다.
CSTS: 생성보다 평가가 더 중요하다
CSTS는 크게 세 단계로 읽으면 된다.
첫째, 복잡한 작업 T를 순서 있는 하위 작업 (t1, t2, ..., tM)으로 분해한다.
예를 들어 “저장소에서 버그를 고치고 PR까지 준비하라” 같은 작업이라면, 파일 탐색, 설정 확인, 명령 구성, 테스트 실행, 실패 진단, 결과 검증 같은 층으로 나눌 수 있다.
이 하위 작업의 순서가 스킬 트리의 깊이가 된다.
둘째, 각 하위 작업마다 여러 모델이 실행 궤적을 만든다.
논문은 이를 Collective Skill Node Generation, CSN-Gen이라고 부른다.
같은 하위 작업을 풀어도 모델마다 다른 파일을 먼저 보거나, 다른 명령을 시도하거나, 다른 복구 전략을 발견할 수 있다.
CSTS는 이 차이를 noise로 버리지 않고 후보 스킬의 다양성으로 활용한다.
셋째, 후보 스킬을 평가한다.
CSN-Assess는 두 축을 더한다.
| 평가 축 | 의미 |
|---|---|
| Collective quality score | 여러 judge 모델이 스킬이 명확하고 실행 가능하며 하위 작업에 맞는지 평가한다 |
| Collective transferability score | 한 모델의 trajectory에서 나온 스킬을 다른 모델에게 주고, 실제 같은 하위 작업을 더 잘 푸는지 본다 |
이 설계가 흥미로운 이유는 “스킬 작성 능력”과 “스킬 사용 가능성”을 분리하기 때문이다.
어떤 모델이 멋진 스킬 문장을 만들 수 있어도, 그 스킬이 다른 모델의 행동을 실제로 개선하지 못하면 좋은 스킬로 선택되지 않는다.
반대로 특정 모델의 우연한 습관이 아니라 여러 모델에서 재사용되는 절차라면, 전이성 점수에서 살아남을 수 있다.
CSRL: 하나의 스킬에 갇히지 않게 학습한다
CSTS가 좋은 스킬 후보와 스킬 경로를 만든다면, 다음 질문은 모델이 그 스킬들을 어떻게 학습하느냐다.
논문은 두 단계를 사용한다.
먼저 CSTS에서 선택된 skill path와 demonstration trajectory로 supervised fine-tuning 데이터를 만든다.
구현 세부 기준으로는 2,000개 high-quality SFT example을 수집하고, Qwen3-4B, Qwen3-8B, Qwen3.5-4B, Qwen3.5-9B 네 backbone을 8개 H100 GPU에서 2 epoch 학습했다고 보고한다.
학습률은 5e-6이다.
그 다음 Collective Skill Reinforcement Learning, CSRL을 붙인다.
CSRL의 핵심은 한 하위 작업에 대해 하나의 스킬만 고정하지 않는 것이다.
각 subtask마다 여러 candidate skill을 선택하고, 각 skill 조건에서 여러 rollout을 만든 뒤, 같은 subtask 안의 모든 skill-conditioned rollout을 하나의 group으로 비교한다.
보상 정규화도 skill별로 따로 하지 않고 collective group 전체의 평균과 표준편차를 기준으로 한다.
이 차이는 작아 보이지만 중요하다. skill A를 쓰는 rollout끼리만 비교하면 모델은 특정 스킬 내부에서만 개선된다.
CSRL은 skill A, B, C가 같은 하위 작업에서 경쟁하게 만들기 때문에, 모델이 “어떤 절차적 관점이 이 상황에서 더 낫나”를 직접 학습할 수 있다.
논문은 이를 GRPO-style clipped objective로 최적화한다.
결과: 작은 Qwen 계열에서 특히 절차 학습 이득이 크다
논문은 QwenClawBench와 PinchBench를 중심으로 OpenClaw-Skill을 평가한다.
숫자는 모두 논문이 보고한 결과 기준이다.
QwenClawBench에서는 네 개 Qwen backbone 모두 전체 점수가 오른다.
| Backbone | Base overall | OpenClaw-Skill overall | 개선폭 |
|---|---|---|---|
| Qwen3-4B | 7.0 | 12.8 | +5.8 |
| Qwen3-8B | 11.5 | 15.8 | +4.3 |
| Qwen3.5-4B | 31.5 | 41.2 | +9.7 |
| Qwen3.5-9B | 34.5 | 44.9 | +10.4 |
카테고리별로 보면 절차적 실행과 복구가 필요한 축에서 변화가 두드러진다.
예를 들어 OpenClaw-Skill 9B는 Qwen3.5-9B 대비 SVM을 33.2에서 70.9로, CS를 30.2에서 78.4로 끌어올렸다고 보고한다.
OpenClaw-Skill 4B도 RIR에서 24.4에서 54.1로 오른다.
논문 해석처럼 CSTS-generated skill과 CSRL이 중간 상태 검증, tool-use 절차, 실행 오류 복구를 개선했다는 쪽으로 읽을 수 있다.
PinchBench에서도 같은 패턴이 나온다.
123-task 확장 버전에서 OpenClaw-Skill 9B는 best success rate를 61.1에서 68.2로, average success rate를 47.1에서 53.6으로 올린다.
Qwen3.5-4B 기반 OpenClaw-Skill 4B도 123-task average를 45.9에서 47.6으로 개선한다.
작은 Qwen3 계열에서는 절대 점수는 낮지만 average 기준으로 Qwen3-4B가 13.6에서 20.8, Qwen3-8B가 18.3에서 22.5로 오른다.
Ablation도 방법의 역할을 비교적 깔끔하게 보여 준다.
Qwen3.5-9B 기준 base model은 34.5, CSN-Gen만 더하면 39.8, CSN-Gen과 CSN-Assess를 함께 쓰면 42.8, 여기에 CSRL을 붙이면 44.9가 된다.
즉 다양하게 만든 후보가 먼저 이득을 만들고, transferability/quality 평가가 후보를 거르며, 마지막으로 skill-conditioned rollout을 비교하는 RL이 추가 이득을 만든다는 구조다.
실무 관점에서의 해석
내가 보기에 이 논문의 가장 좋은 메시지는 “스킬 파일을 많이 만들자”가 아니다.
더 정확한 메시지는 스킬을 실행 증거와 전이성으로 평가 가능한 객체로 만들자에 가깝다.
실제 에이전트 운영에서 나쁜 스킬은 두 가지 방식으로 위험하다.
하나는 너무 추상적이어서 아무 행동도 바꾸지 못하는 경우다.
다른 하나는 특정 모델, 특정 환경, 특정 실패 로그에 과적합되어 다른 상황에서 오히려 방해가 되는 경우다.
CSTS는 이 둘을 동시에 겨냥한다.
여러 모델의 궤적을 모으는 것은 diversity를 만들고, 다른 모델에게 스킬을 건네 성능을 재는 것은 transferability를 본다.
이 관점은 사람 중심의 skill curation에도 그대로 적용할 수 있다.
좋은 skill repository라면 단순히 “깔끔한 Markdown”이 아니라 다음 질문에 답해야 한다.
| 질문 | 왜 중요한가 |
|---|---|
| 이 스킬은 어떤 하위 작업에 적용되는가 | 적용 범위가 흐리면 검색과 호출이 흔들린다 |
| 입력과 출력, 검증 기준이 명시되어 있는가 | 실행 가능한 절차인지 판단할 수 있다 |
| 실패했을 때의 recovery path가 있는가 | 긴 작업에서는 정상 경로보다 복구 경로가 중요하다 |
| 다른 모델/다른 agent harness에서도 통하는가 | 특정 모델의 말투나 도구 습관에 과적합된 스킬을 걸러야 한다 |
| 여러 스킬과 어떤 순서로 조합되는가 | 실제 업무는 한 개 스킬 호출로 끝나지 않는다 |
다만 논문을 읽을 때 조심할 점도 있다.
첫째, OpenClaw-Skill은 단순 inference-time prompt 패키지가 아니라 데이터 생성, multi-model rollout, judge 평가, SFT, RL까지 포함한 학습 파이프라인이다.
따라서 개인이나 작은 팀이 바로 똑같이 재현하기에는 계산·데이터·평가 인프라 비용이 크다.
둘째, arXiv 페이지와 논문 본문 기준으로는 모델 체크포인트나 재현용 코드 릴리스가 별도 companion artifact로 명확히 제시되지는 않는다.
그래서 이 글의 수치 해석은 “공개 논문이 보고한 결과”에 머문다.
실제 사용 가능성, 체크포인트 라이선스, 학습 데이터 공개 범위, benchmark harness 재현성은 후속 공개 자료가 있어야 더 강하게 판단할 수 있다.
셋째, 스킬을 자동 생성한다고 해서 skill governance 문제가 사라지지는 않는다.
오히려 대량 생성된 스킬이 registry에 쌓이면 중복, 오래된 절차, 위험한 tool-use pattern, credential leakage 같은 문제가 더 중요해진다.
CSTS의 quality/transferability scoring은 좋은 시작점이지만, 운영 환경에서는 권한, 감사 로그, human review, 버전 관리가 함께 필요하다.
결론
OpenClaw-Skill은 에이전트 스킬을 “좋은 조언의 모음”이 아니라, 장기 작업을 따라 구성되는 절차적 검색 공간으로 다룬다.
CSTS는 여러 모델의 경험에서 후보 스킬을 만들고, 품질과 전이성을 함께 평가해 트리 구조로 묶는다.
CSRL은 그 트리 안의 여러 스킬 조건부 rollout을 서로 비교하며 모델이 더 나은 절차를 선택하도록 학습시킨다.
그래서 이 논문은 agent skill 연구에서 꽤 중요한 방향 전환을 보여 준다.
앞으로 스킬의 품질은 얼마나 예쁜 Markdown인가보다, 다른 모델과 다른 작업에서도 실제 행동을 개선하는가로 평가되어야 한다.
OpenClaw-Skill은 그 평가 기준을 tree search와 collective reinforcement learning으로 formalize하려는 시도다.