멀티모달 모델 경쟁은 이제 “이미지를 읽을 수 있는가”에서 “한 모델 안에서 이미지와 비디오를 읽고, 만들고, 고칠 수 있는가”로 이동하고 있다.
하지만 이 목표는 생각보다 어렵다.
이해 모델은 의미·문맥·추론에 강한 표현을 원하고, 생성 모델은 질감·기하·시간적 움직임을 보존하는 표현을 원한다.
둘을 억지로 하나의 경로에 넣으면 서로 간섭하고, 완전히 분리하면 unified model이라는 이름만 남는다.
Lance: Unified Multimodal Modeling by Multi-Task Synergy는 이 중간 지점을 겨냥한다.
ByteDance 연구진은 Lance를 이미지·비디오 understanding, generation, editing을 모두 지원하는 3B active parameter급 native unified multimodal model로 제시한다.
핵심 메시지는 단순히 “하나의 모델이 다 한다”가 아니다. shared interleaved multimodal context는 통합하되, understanding과 generation의 capability pathway는 분리해서 충돌을 줄이고, 멀티태스크 데이터 스케줄로 서로를 보강한다는 쪽에 가깝다.
공개 범위도 논문만이 아니다.
공식 프로젝트 페이지, GitHub 코드, Hugging Face checkpoint가 함께 열려 있다.
다만 이 릴리스를 “완전한 학습 재현 패키지”로 읽으면 안 된다.
현재 저장소는 inference, Gradio, benchmark sampling, 모델링 코드 중심이고, GitHub release/tag는 아직 없으며, recursive tree 기준 full training script는 보이지 않는다.
즉 Lance는 논문 아이디어와 공개 checkpoint를 실제로 만져볼 수 있는 research release지만, 전체 pretraining recipe를 그대로 재현하는 turnkey package는 아니다.
무엇을 해결하려는가
Lance가 겨냥하는 병목은 unified multimodal model의 범위와 충돌이다.
최근 모델들은 이미지 이해와 이미지 생성까지는 점점 통합하고 있지만, 비디오 이해·비디오 생성·비디오 편집·subject-driven generation까지 한 모델 계열에서 명시적으로 다루는 경우는 많지 않다.
논문 Table 1도 이 지점을 강조한다.
기존 native unified 모델 상당수는 text-image 중심이거나 일부 video task만 지원하고, editing이나 subject-driven video generation은 별도 downstream skill로 남는 경우가 많다.
또 다른 병목은 representation mismatch다.
이해는 language-aligned semantic feature를 선호하고, 생성은 low-level continuous visual representation을 원한다.
Lance는 둘 중 하나를 포기하지 않는다.
대신 shared context 안에서 서로 다른 token type과 objective를 함께 다루되, dual-stream mixture-of-experts와 task-specific head로 경로를 나눈다.
이 설계는 완전히 하나의 표현으로 모든 것을 밀어 넣는 방식보다 덜 순수하지만, 실제 학습 안정성과 task coverage를 생각하면 더 현실적인 통합 방식이다.
이 점이 Lance를 Tuna-2나 SenseNova-U1 같은 encoder-free/pixel-space 계열과 다르게 만든다.
Lance의 흥미로운 부분은 “비전 인코더와 VAE를 없앴다”가 아니라, semantic token과 generative latent token을 shared sequence에서 만나게 하면서도 task pathway는 분리한다는 데 있다.
그래서 Lance는 native unified라는 단어를 monolithic architecture가 아니라, multi-task context modeling과 capability routing의 문제로 다시 정의한다.
핵심 아이디어 / 구조 / 동작 방식
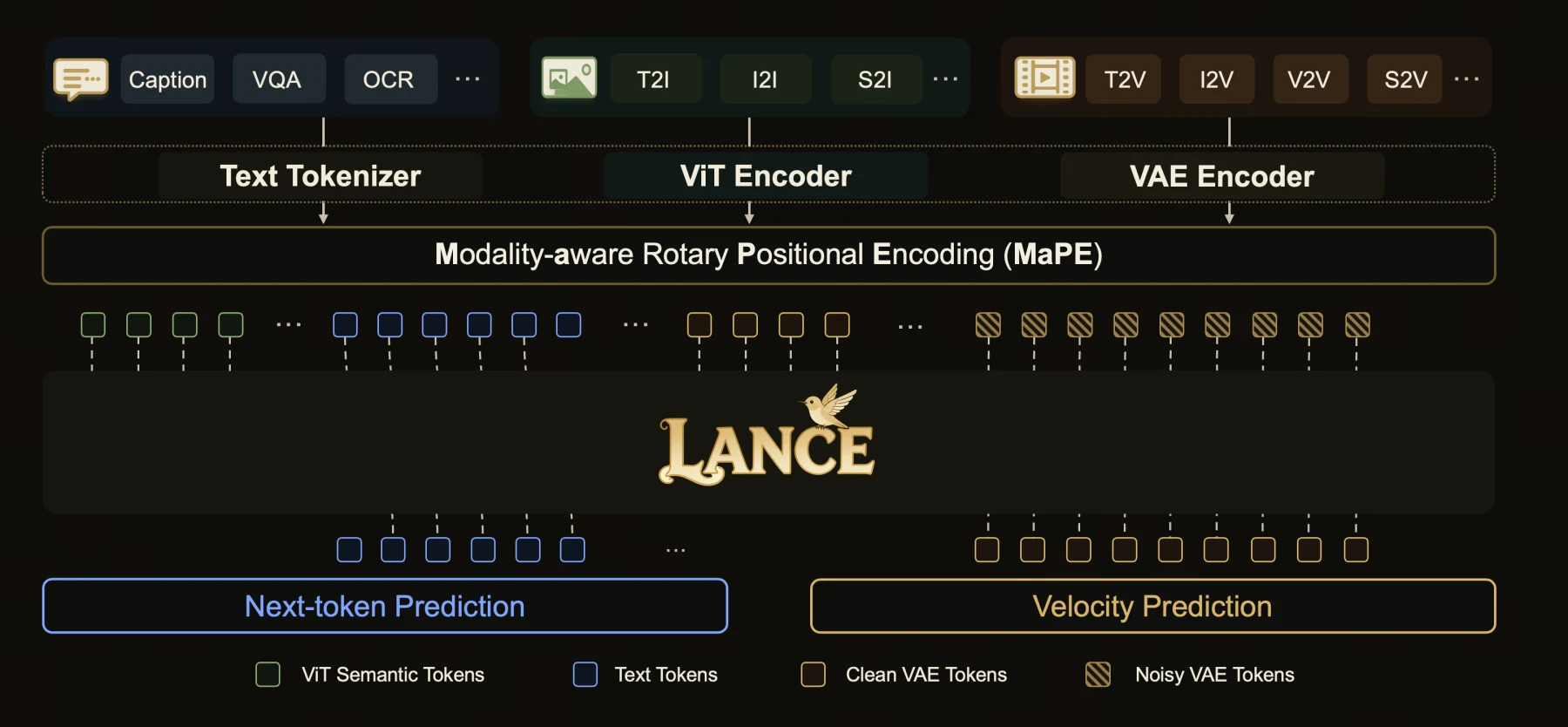
구조는 세 축으로 볼 수 있다.
첫째는 unified context modeling이다.
Lance는 captioning, visual question answering, OCR, image-to-text, video-to-text, text-to-image, image-to-video, video editing처럼 서로 다른 task를 interleaved multimodal sequence로 다룬다.
텍스트 토큰, ViT semantic token, clean VAE token, noisy VAE token이 한 컨텍스트 안에 들어오고, 모델은 3D causal attention 기반으로 task별 출력을 만든다.
둘째는 decoupled capability pathway다.
텍스트·이해 쪽은 autoregressive LM head로 next-token prediction을 수행하고, 생성 쪽은 flow head로 visual latent space의 velocity를 예측한다.
즉 input context는 공유하지만 output objective와 expert path는 분리된다.
이 설계 덕분에 이해 능력과 생성 능력이 같은 backbone에서 상호작용하면서도, 서로의 loss가 직접 충돌하는 정도를 줄인다.
셋째는 modality-aware rotary positional encoding, MaPE다.
이미지·비디오·텍스트 토큰은 공간·시간·순서 구조가 다르다.
Lance는 heterogeneous visual token 간 위치 간섭을 줄이기 위해 modality-aware RoPE를 도입한다.
논문 ablation에서 MaPE를 켜면 GenEval 80.94 vs 80.56, GEdit 6.86 vs 6.30, VBench 81.81 vs 80.95, MVBench 59.16 vs 59.02로 전반적 개선이 나타난다.
특히 editing과 video generation에서 차이가 더 눈에 띈다.
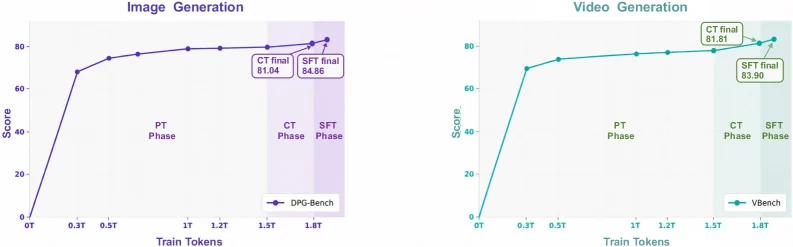
학습 recipe도 “데이터를 다 섞었다”보다 조금 더 세밀하다.
논문은 PT, CT, SFT, RL 네 단계를 사용하고, PT에서 1.5T token, CT에서 300B token, SFT에서 72B token, RL에서 0.5B token을 사용했다고 보고한다. global mixture는 video generation : video understanding : image generation : image understanding = 64:16:16:4로 유지하되, continual training 동안 generation task mixture를 점진적으로 어렵게 만든다.
예를 들어 T2I는 100:0:0에서 시작해 image editing과 subject-driven image generation을 늘리고, T2V도 I2V, video editing, subject-driven video generation 비중을 단계적으로 키운다.
데이터 규모도 task coverage를 보여준다.
Table 4 기준 일반 image captioning 1B, general video captioning 140M, image generation 1B, video generation 140M, image editing 2.8M, subject-driven image generation 3.6M, video editing 2.6M, subject-driven video generation 1M 샘플이 포함된다.
핵심은 한 번에 모든 어려운 task를 밀어 넣는 것이 아니라, 기본 생성에서 시작해 editing과 subject-driven generation을 점진적으로 섞는 curriculum에 있다.
공개된 근거에서 확인되는 점
가장 강한 신호는 task coverage다.
Lance는 공식 README와 Hugging Face model card 기준 t2i, t2v, image_edit, video_edit, x2t_image, x2t_video를 하나의 CLI 흐름에서 지원한다.
권장 환경은 Python 3.10+, CUDA 12.4+, inference용 최소 40GB VRAM GPU다.
Hugging Face의 bytedance-research/Lance는 gated false, Apache-2.0, any-to-any pipeline tag, 약 84개 sibling file, 약 57GB storage로 공개되어 있다.

성능은 “모든 것을 이긴다”보다 “통합 모델 중 넓은 범위에서 강하다”로 읽는 편이 맞다.
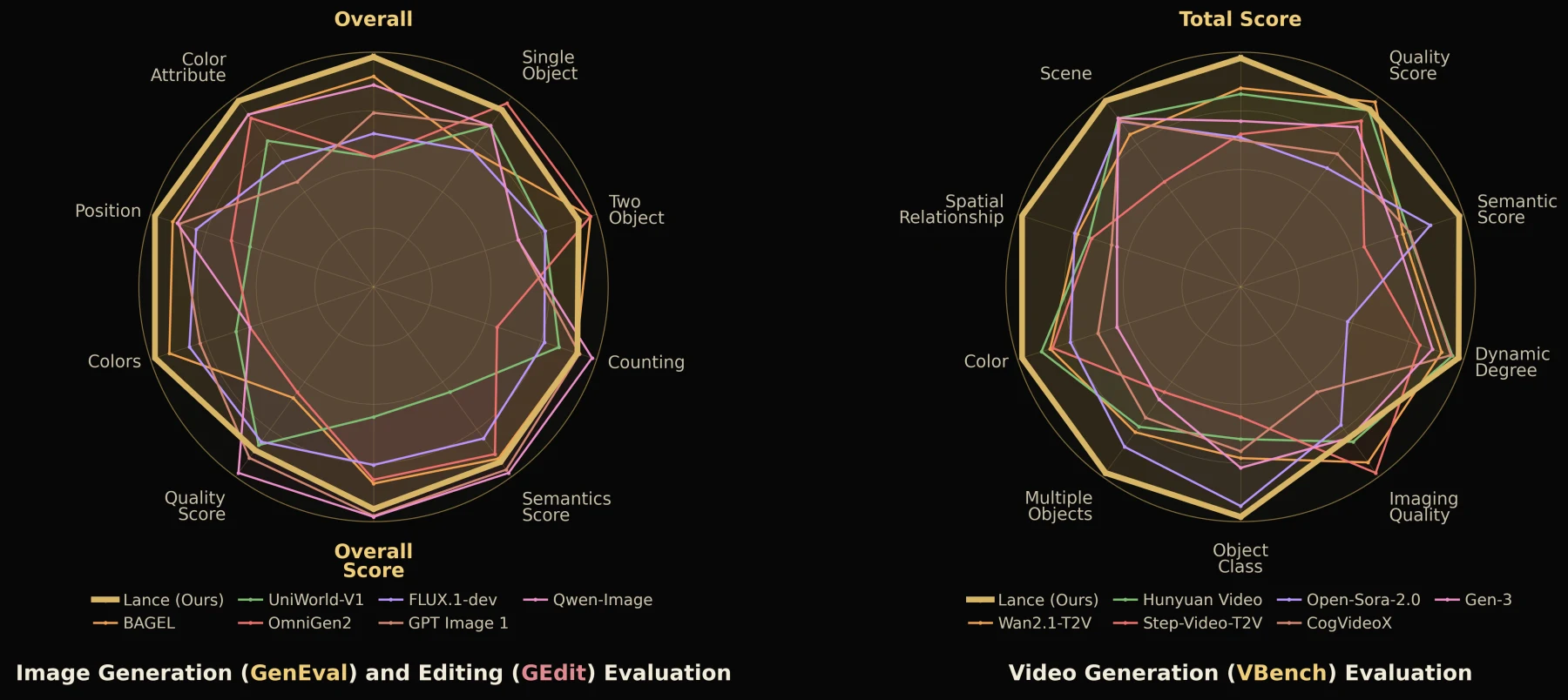
이미지 생성에서 Lance는 GenEval overall 0.90을 기록해 unified model 비교군 중 가장 높은 축에 있다.
BAGEL† 0.88, InternVL-U 0.85, Show-o2 0.76보다 높고, generation-only Qwen-Image 0.87보다도 높게 제시된다.
반면 DPG-Bench overall은 84.67로 Qwen-Image 88.32, Show-o2 86.14보다 낮다.
즉 compositional generation에서는 강하지만, 모든 image generation metric을 압도하는 것은 아니다.
비디오 생성은 Lance의 차별점이 더 분명하다.
VBench에서 Lance는 Quality Score 85.14, Semantic Score 84.96을 제시하고, part II까지 포함한 total score는 85.11로 보고된다.
통합 모델 비교군에서는 높은 수치이며, video generation을 단순 부가 기능이 아니라 핵심 task로 넣었다는 점이 중요하다.
다만 Wan2.1-T2V, HunyuanVideo 같은 generation-only/video-specialist 모델과 항목별로 비교하면 여전히 전문 모델이 강한 지점도 있다.
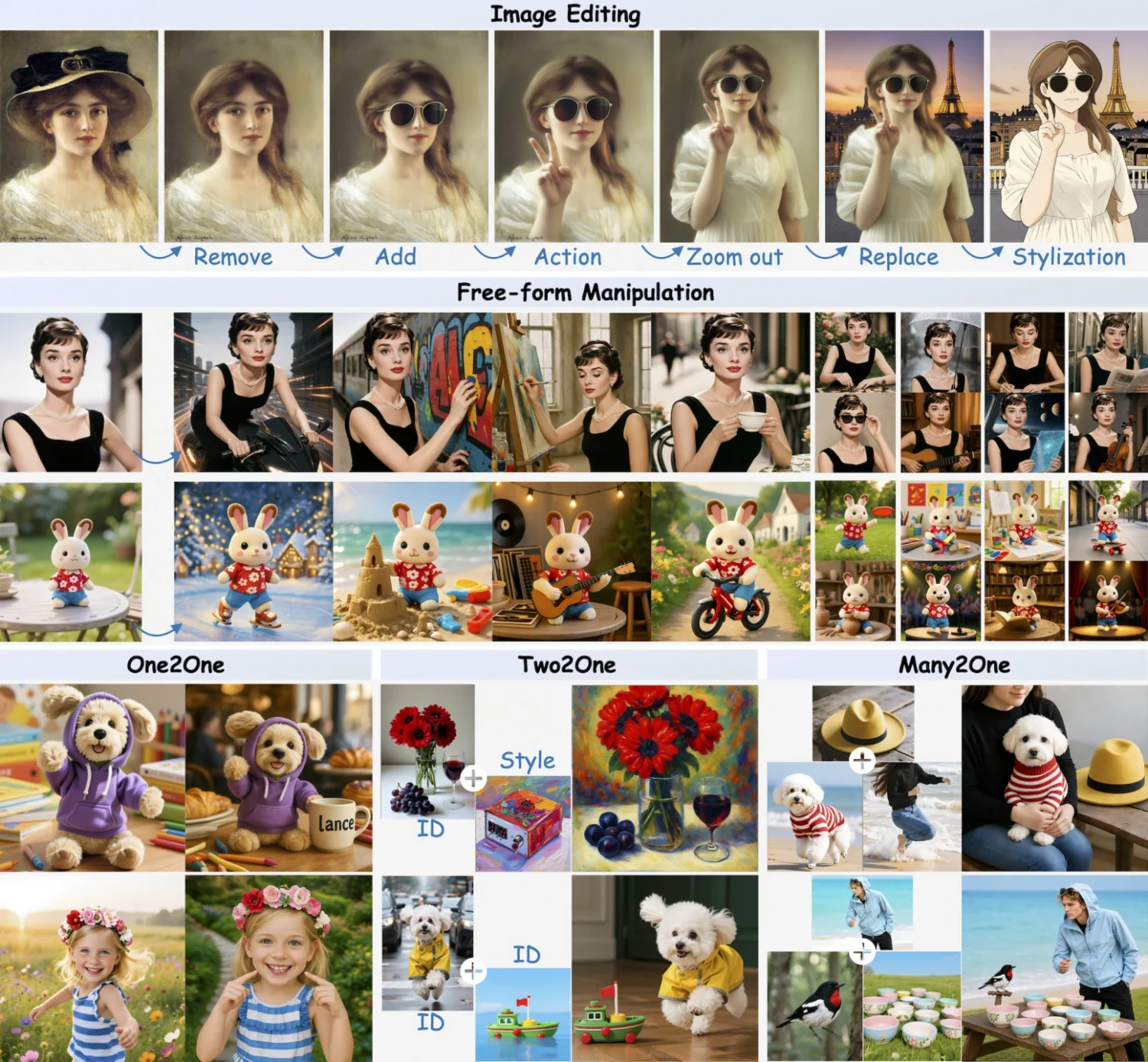
편집도 비슷하다.
GEdit-Bench 평균에서 Lance는 7.30으로 BAGEL 6.52, InternVL-U 6.66/CoT 6.88보다 높지만, Qwen-Image-Edit 8.01에는 못 미친다.
이 결과는 unified model의 실용적 위치를 잘 보여준다.
하나의 모델 안에서 image/video understanding과 generation/editing을 모두 다루는 장점은 있지만, 특정 편집 benchmark만 보면 specialist editor가 여전히 더 강하다.
이해 쪽에서도 trade-off가 있다.
MVBench에서 Lance는 average 62.0으로 Show-o2 7B의 55.7보다 높지만, understanding-only Qwen2.5-VL 3B의 67.0이나 TimeMarker 8B의 67.4에는 못 미친다.
따라서 Lance를 “비디오 이해까지 최고인 모델”로 읽기보다는, 3B active parameter 규모의 unified model이 generation-heavy training을 하면서도 비디오 이해 성능을 어느 정도 유지했다는 신호로 보는 편이 정확하다.
공개 저장소 상태도 실무적으로 중요하다.
GitHub bytedance/Lance는 확인 시점 기준 2026-05-15 생성, stars 315, forks 21, open issues 6, Apache-2.0 license, default branch main이다. top-level에는 inference_lance.py, inference_lance.sh, lance_gradio_t2v_v2t.py, benchmarks, config, data, modeling 등이 있고, DPG, GenEval, GEdit, VBench용 sampling script가 들어 있다.
하지만 releases와 tags는 빈 배열이고, recursive tree에서 train, sft, rl 이름의 학습 스크립트는 확인되지 않았다.
즉 공개 checkpoint와 inference/benchmark surface는 있지만, 논문 전체 훈련을 외부에서 재현하는 코드 릴리스로 보기는 어렵다.
실무 관점에서의 해석
내가 보기에 Lance의 핵심 가치는 “3B 모델이 모든 것을 이긴다”가 아니라, 통합 멀티모달 모델의 coverage를 이미지 중심에서 비디오 중심까지 넓히는 방법론에 있다.
기존에는 이미지 이해, 이미지 생성, 비디오 생성, 비디오 이해, 편집이 각기 다른 모델·토크나이저·서빙 경로로 흩어지기 쉬웠다.
Lance는 이를 shared context와 decoupled pathway 위에서 묶고, 데이터 mixture와 curriculum을 통해 task 간 transfer를 끌어내려 한다.
특히 cross-task ablation은 이 주장을 뒷받침한다. generation-only base는 GenEval 80.88, VBench 81.25에 머문다.
여기에 understanding data를 섞으면 VBench가 82.91까지 올라가고, multi-task generation data까지 넣으면 GenEval 82.06, VBench 83.05 수준까지 개선된다.
비디오 이해 MVBench도 multi-task setting에서 59 내외로 유지된다.
즉 Lance의 메시지는 “큰 모델을 만들자”보다 “task를 잘 섞으면 서로 다른 능력이 완전히 제로섬은 아니다”에 가깝다.

동시에 현실적인 한계도 분명하다.
첫째, Lance는 specialist model을 완전히 대체하지 않는다.
이미지 편집에서는 Qwen-Image-Edit가 더 강하고, 비디오 이해에서는 understanding-only 모델이 앞선다.
둘째, public release는 inference와 benchmark 사용에는 충분히 의미 있지만, full training reproduction에는 아직 부족하다.
셋째, 40GB 이상 VRAM과 57GB급 checkpoint surface는 “가볍게 로컬에서 테스트”하기에는 여전히 부담이 있다.
그래도 Lance는 중요한 방향 신호다. native unified multimodal model의 다음 단계는 단순히 이미지 생성과 이미지 이해를 한 모델에 넣는 것만으로는 부족하다.
실제 제품·에이전트·연구 워크플로에서는 이미지와 비디오를 읽고, 만들고, 고치고, 다시 설명하는 루프가 필요하다.
Lance는 그 루프를 하나의 모델 계열에서 다루려면 완전한 단일 pathway보다 shared context + decoupled expert path + staged multi-task curriculum이 더 현실적인 설계일 수 있음을 보여준다.