딥리서치 에이전트를 오래 돌리면 병목은 금방 명확해진다.
검색 결과, 방문한 웹페이지, 중간 가설, 반례, citation 후보가 계속 쌓이는데, 모델의 context window는 유한하다.
단순히 더 긴 context를 주거나 오래된 로그를 잘라내는 방식은 어느 순간 메인 에이전트가 “무엇을 알고 있고 무엇을 아직 모르는지”를 잃게 만든다.
SearchSwarm: Towards Delegation Intelligence in Agentic LLMs for Long-Horizon Deep Research는 이 문제를 subagent를 몇 개 붙였는가가 아니라, 메인 에이전트가 언제 위임하고, 어떤 brief를 쓰고, 돌아온 보고서를 어떻게 검증할지를 배워야 하는 문제로 재정의한다.
논문이 붙인 이름은 delegation intelligence다.
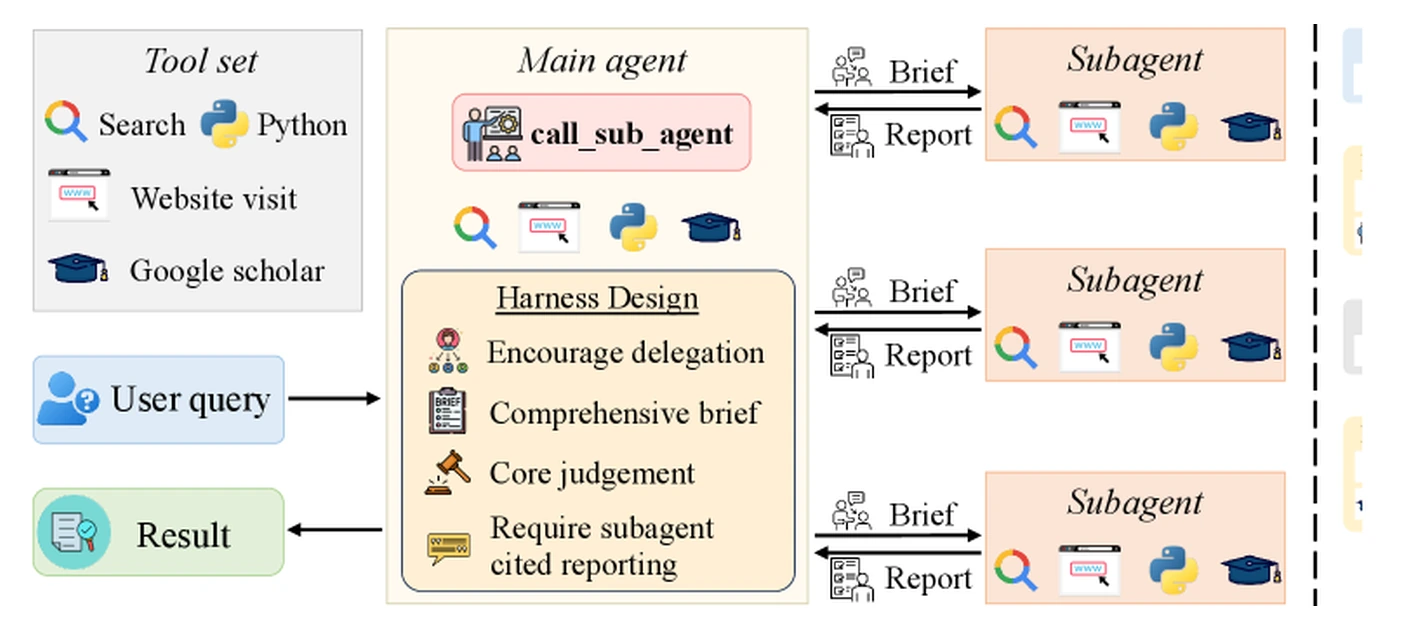
중요한 점은 SearchSwarm가 전통적인 의미의 “서로 다른 여러 모델로 구성된 multi-agent system”을 내세우지 않는다는 것이다. subagent는 같은 모델을 독립된 fresh context에서 호출한 것이다.
메인 에이전트는 전체 히스토리를 subagent에게 넘기지 않고, 필요한 맥락만 brief로 압축한다. subagent는 별도 context에서 검색·방문·계산을 수행한 뒤, citation이 붙은 report만 메인 context로 돌려준다.
그래서 논문의 핵심 주장은 multi-agent라기보다 모델이 스스로 context를 내용 기반으로 압축·분배하는 법을 학습한다에 가깝다.
무엇을 해결하려는가
논문은 deep research를 ReAct 스타일의 multi-turn tool-use 문제로 둔다.
에이전트는 매 step에서 생각하고, 검색·방문·Google Scholar·Python 같은 도구를 호출하고, 관찰 결과를 받아 다음 행동을 고른다.
일반적인 장기 검색 작업에서는 이 히스토리가 계속 커진다.
과거 context를 자르면 중요한 증거를 잃고, 전부 보존하면 planning과 synthesis에 써야 할 attention이 raw evidence에 잠식된다.
SearchSwarm의 관점에서 delegation은 병렬 compute trick이 아니다. call_sub_agent(brief)가 호출되면 subagent는 메인 에이전트의 이전 히스토리 전체를 볼 수 없다.
오직 brief만 보고 독립 trajectory를 실행한다.
따라서 brief는 “이거 찾아봐” 같은 얕은 지시가 아니라, 왜 이 subtask가 전체 질문에서 중요한지, 이미 무엇을 확인했는지, 어떤 방향은 시도했거나 배제했는지까지 포함해야 한다.
그 다음 report도 중요하다.
메인 에이전트는 subagent의 중간 도구 호출을 보지 못하므로, report에 source citation이 없으면 검증할 방법이 없다.
SearchSwarm harness는 subagent가 근거가 붙은 보고서를 내게 하고, 메인 에이전트가 이를 그대로 믿지 말고 전체 evidence landscape 안에서 다시 판단하도록 유도한다.
요약하면 역할 분담은 다음과 같다.
| 역할 | 맡는 일 | 경계 |
|---|---|---|
| Main agent | 전체 질문의 decomposition, 위임 여부 결정, conflicting evidence 판단, 최종 synthesis | 모든 subtask의 중간 탐색 로그를 직접 들고 있지 않음 |
| Subagent | 제한된 brief에 따라 검색·방문·계산을 수행하고 근거 보고서 작성 | call_sub_agent는 없음. 한 단계 위임만 가능 |
| Harness | 위임을 장려하고, brief/report 형식과 citation discipline을 강제 | 단순 tool schema만 주는 것보다 강한 행동 유도 |
| SFT data | 좋은 위임 trajectory를 모델 weight에 내재화 | harness만 붙인 base model은 자동으로 위임하지 않음 |
핵심 아이디어 / 구조 / 동작 방식
SearchSwarm harness는 네 가지 원칙으로 메인 에이전트를 압박한다.
첫째, raw search와 visit처럼 token을 많이 쓰지만 인지적으로 얕은 탐색은 subagent에게 넘기게 한다.
둘째, subagent가 fresh context에서 시작한다는 사실을 전제로 comprehensive brief를 쓰게 한다.
셋째, 가설 선택·종료 판단·상충 보고서 조정 같은 core judgment는 메인 에이전트가 유지하게 한다.
넷째, subagent report에는 citation을 요구해 메인 에이전트가 결론을 검증하고 최종 답변의 출처로 이어 붙일 수 있게 한다.
학습 데이터는 이 harness를 실제 deep research query에 적용해 만든 trajectory다.
논문은 RedSearcher와 OpenSeeker 계열 query를 사용하고, 두 가지 수집 설정을 섞는다.
하나는 같은 모델이 main/subagent를 모두 맡고 양쪽 trajectory를 저장하는 설정이다.
다른 하나는 더 강한 모델을 main agent로 두고 약한 subagent를 붙인 뒤 main-agent trajectory만 저장하는 설정이다.
후자는 subagent 결과가 덜 안정적일 때 메인 에이전트가 더 신중하게 분해·검증하는 행동을 만들기 위한 장치다.
필터링도 꽤 실무적이다.
최종 답이 맞은 main trajectory만 남기고, 그 main trajectory가 맞은 경우의 subagent trajectory만 유지한다.
너무 짧은 subagent trajectory는 downsample하고, 동일한 tool call 반복, 존재하지 않는 source citation hallucination, Python으로 웹 접근을 시도하는 tool misuse 같은 패턴은 제거한다.
학습 objective는 next-token prediction이지만, tool 결과나 subagent report 같은 environment return은 loss에서 mask한다.
모델이 환경 내용을 외우는 것이 아니라, 관찰된 context에서 다음 reasoning과 tool invocation을 생성하도록 만드는 쪽이다.
공개 artifact도 이 방향과 맞다.
GitHub 저장소 Search-Swarm/SearchSwarm는 harness 실행 스크립트, .env.example, training script를 포함하고, Hugging Face에는 SearchSwarm/SearchSwarm-30B-A3B 모델과 SearchSwarm/SearchSwarm-SFT dataset이 올라와 있다.
모델 card와 config 기준으로 모델은 Alibaba-NLP/Tongyi-DeepResearch-30B-A3B를 base로 둔 Qwen3MoeForCausalLM 계열이며, config에는 48 layers, 128 experts, top-8 expert routing 같은 MoE 설정이 보인다.
SFT dataset은 MIT license, 영어·중국어 text-generation dataset으로 공개되어 있고 train.parquet가 약 2.1GB 규모다.
공개된 근거에서 확인되는 점
가장 직접적인 결과는 네 개 short-answer deep research benchmark다.
SearchSwarm-30B-A3B는 같은 30B-A3B급 open-source lightweight model 중 BrowseComp, BrowseComp-ZH, GAIA, xbench-DeepSearch-2505 모두에서 가장 높은 점수를 기록했다고 보고된다.
| 모델 | 규모 | BrowseComp | BrowseComp-ZH | GAIA | xbench-DeepSearch-2505 |
|---|---|---|---|---|---|
| Tongyi DeepResearch | 30B-A3B | 43.4 | 46.7 | 70.9 | 75.0 |
| RedSearcher | 30B-A3B | 57.4 | 58.2 | 80.1 | - |
| LongSeeker | 30B-A3B | 61.5 | 62.5 | 77.7 | 78.0 |
| MiroThinker-1.7-mini | 30B-A3B | 67.9 | 72.3 | 80.3 | - |
| SearchSwarm | 30B-A3B | 68.1 | 73.3 | 82.5 | 80.8 |
이 표에서 내가 가장 중요하게 보는 비교는 base model 대비 차이다.
Tongyi DeepResearch는 BrowseComp 43.4, BrowseComp-ZH 46.7인데 SearchSwarm은 각각 68.1, 73.3까지 올라간다.
같은 base 계열에서 “subagent tool을 붙이면 알아서 쓰겠지”가 아니라, 위임 행동 자체를 trajectory로 만들어 학습시켰을 때 차이가 난다는 주장이다.
논문도 이 점을 따로 ablation한다.
DeepSeek V3.2를 200문항 BrowseComp subset에서 평가했을 때, 원래 Tongyi DeepResearch framework는 47.7, call_sub_agent tool schema만 추가한 설정은 50.0, full harness는 57.7을 기록한다.
즉 도구를 하나 더 준 효과는 +2.3에 그치지만, delegation을 장려하고 brief/report discipline을 넣은 harness는 +10.0까지 올라간다.
또 흥미로운 결과는 Qwen3-30B-A3B-Thinking-2507에 같은 data를 적용한 실험이다.
논문은 이 모델이 동일 설정에서 BrowseComp 200-question subset 66.5, BrowseComp-ZH 64.0을 기록했다고 보고한다.
Tongyi DeepResearch라는 특정 base의 사전 deep-search 능력만이 아니라, harness가 만든 data 자체가 위임형 research behavior를 어느 정도 전달한다는 해석을 붙인다.
SearchSwarm이 subagent tool이 사라져도 좋아지는지도 확인한다. call_sub_agent를 비활성화하고 128K single-agent context만 둔 조건에서 SearchSwarm은 BrowseComp subset 52.0, BrowseComp-ZH 53.3을 기록해 Tongyi DeepResearch의 43.5, 46.5보다 높다.
학습 데이터가 subagent tool이 있는 trajectory였는데도, 문제 분해·subquestion 해결·진행 상태 유지 같은 행동이 single-agent setting으로 일부 전이된다는 주장이다.
open-ended deep research benchmark에서도 같은 방향이 보인다.
ScholarQA-v2, HealthBench, ResearchQA, DeepResearchBench 평균에서 SearchSwarm은 64.2를 기록해 base Tongyi DeepResearch의 50.0보다 +14.2 높다.
OpenAI DeepResearch 평균 64.9, Dr.Tulu 65.6과 비슷한 수준까지 접근한다.
다만 HealthBench와 ResearchQA는 resource constraint 때문에 200-question subset으로 평가했다는 단서를 함께 읽어야 한다.
행동 분석도 논문 주장과 잘 맞는다.
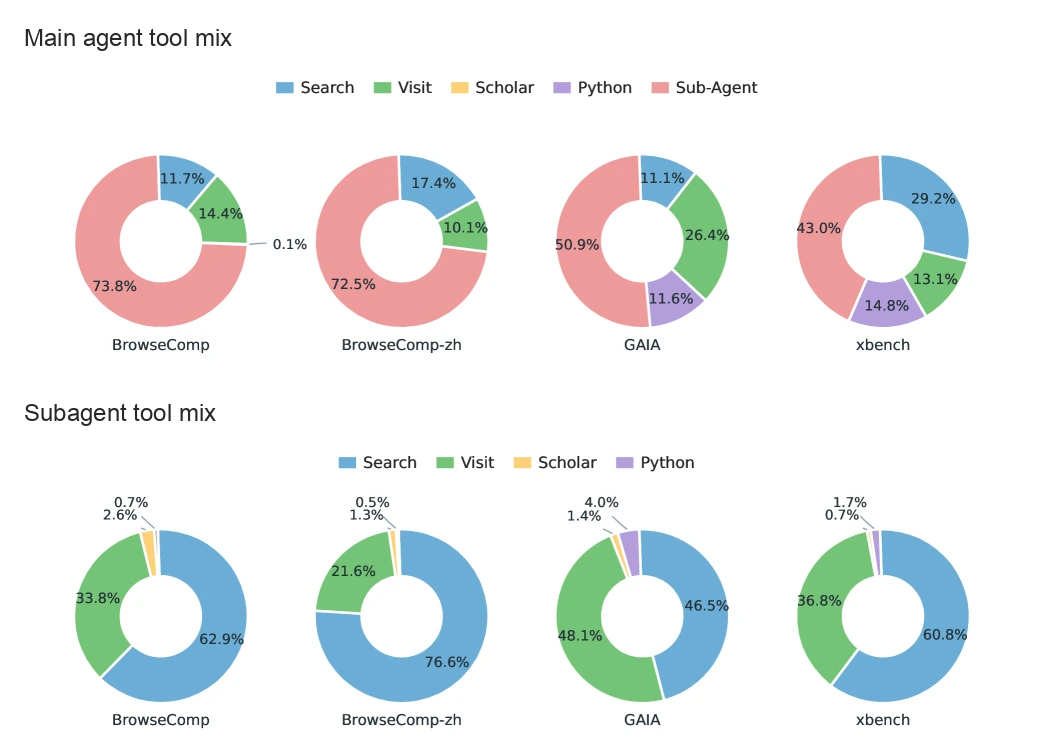
메인 에이전트의 가장 많이 쓰는 도구는 call_sub_agent다.
BrowseComp와 BrowseComp-ZH에서는 70% 이상이고, GAIA와 xbench에서도 4351% 수준이다.76.6%로 높다.
메인 에이전트가 직접 도구를 쓸 때는 search보다 visit이 상대적으로 두드러지는데, 이는 subagent report의 citation URL을 따라가 검증하는 행동으로 해석된다.
반대로 subagent는 search가 46.5
즉 메인 에이전트는 orchestrator와 verifier에 가깝고, subagent는 exploratory retrieval worker에 가깝다는 분업이 실제 tool distribution에서도 나타난다.
공개 release 관점에서는 꽤 강한 편이다.
논문 abstract는 harness, model weights, training data release를 예고하고, 실제로 GitHub·project page·Hugging Face model·Hugging Face dataset이 연결되어 있다.
확인 시점의 GitHub API 기준 Search-Swarm/SearchSwarm는 MIT license, 기본 브랜치 main, stars 65, forks 4, open issues 1이었다.
다만 README가 명시하듯 repository에는 tiny synthetic example dataset만 포함되어 있고, BrowseComp·BrowseComp-ZH·GAIA·xbench 같은 실제 benchmark data는 재배포하지 않는다. evaluation을 그대로 재현하려면 각 benchmark의 공식 data와 Serper/Jina 같은 외부 tool credential, judge 설정이 따로 필요하다.
실무 관점에서의 해석
SearchSwarm의 좋은 메시지는 “subagent를 붙이면 성능이 오른다”가 아니다.
오히려 반대에 가깝다. base Tongyi DeepResearch에 harness만 붙인 Tongyi DR Swarm은 call_sub_agent를 전혀 호출하지 않았고, 사실상 기존 Tongyi DeepResearch와 동일하게 행동했다고 논문은 적는다.
즉 위임은 tool availability에서 자동으로 생기는 emergent behavior가 아니라, prompt/harness와 trajectory 학습으로 만들어야 하는 skill이다.
이 관점은 사내 deep research agent나 agentic RAG 설계에 직접적이다.
긴 조사 작업에서 subagent는 “일꾼을 더 붙여 속도를 높이는 장치”라기보다, 메인 에이전트의 context를 보호하는 내용 기반 compression boundary다.
메인 에이전트는 raw evidence를 모두 삼키지 않고, 잘 쓴 brief를 통해 subtask에 필요한 정보만 넘긴다. subagent는 탐색 비용을 자기 context에서 지불하고, citation이 달린 compact report만 반환한다.
이 구조는 장기 프로젝트 조사, codebase archaeology, compliance evidence gathering처럼 증거가 넓게 흩어진 작업에서 특히 유용하다.
또 하나의 교훈은 brief 품질이 agent orchestration의 핵심 interface라는 점이다. subagent가 fresh context에서 시작한다면, brief는 단순 task title이 아니라 작은 onboarding document여야 한다.
“왜 이 조사가 필요한가”, “지금까지 무엇이 확정됐는가”, “어떤 가설이 남았는가”, “무엇을 citation으로 보고해야 하는가”가 들어가야 한다.
이건 인간 팀에 일을 위임할 때도 마찬가지다.
좋은 manager가 좋은 brief를 쓰듯, 좋은 main agent도 좋은 brief를 써야 한다.
물론 한계도 분명하다.
첫째, 비용은 공짜가 아니다. subagent context를 별도로 열고 검색·방문을 수행하므로 tool budget과 latency가 늘어난다.
둘째, report 기반 architecture는 subagent citation discipline이 무너지면 위험하다.
메인 에이전트가 중간 trajectory를 보지 못하기 때문에 citation hallucination과 over-compression을 강하게 필터링해야 한다.
셋째, benchmark 결과에는 context management가 있는 baseline과 없는 baseline, judge model 및 manual verification protocol이 섞여 있으므로 단순 순위표보다 평가 조건을 같이 봐야 한다.
그럼에도 SearchSwarm은 최근 search/research agent 흐름에서 중요한 위치를 차지한다.
Harness-1이 검색 상태를 하네스 밖으로 빼내 작은 모델의 RL을 쉽게 만들었다면, SearchSwarm은 탐색 자체를 독립 context로 분산하고, 그 brief/report 경계를 SFT 데이터로 학습시킨다.
둘 다 공통적으로 말하는 것은 “강한 모델 하나가 긴 transcript를 다 기억하게 두지 말라”는 것이다.
장기 에이전트의 성능은 모델 크기만이 아니라, 어떤 상태를 어디에 보존하고, 어떤 정보를 어떤 경계에서 압축할지에 달려 있다.
한 줄로 요약하면
SearchSwarm은 딥리서치 에이전트의 subagent 병렬화를 단순 orchestration trick이 아니라, 유한 context 안에서 일을 나누고, 근거 보고서를 검증하고, 최종 답변으로 통합하는 위임 지능을 학습시키는 문제로 만든 논문이다.