RAG 시스템을 만들 때 가장 오래된 고민 중 하나는 청크 크기다.
문서를 문장이나 짧은 문단 단위로 잘게 자르면 정밀한 evidence를 찾기 쉽지만, 인덱스와 검색 후보가 커져 비용과 지연 시간이 늘어난다.
반대로 큰 청크를 쓰면 후보 수는 줄고 문맥은 보존되지만, 하나의 embedding 안에 여러 주제가 섞이면서 dense similarity가 흐려진다.
MCompassRAG: Topic Metadata as a Semantic Compass for Paragraph-Level Retrieval은 이 trade-off를 다른 방향에서 푼다.
청크를 더 잘게 쪼개거나, 런타임에 LLM reranker를 붙이는 대신, 큰 청크에 토픽 메타데이터를 붙여 검색이 “어느 의미 방향을 봐야 하는지”를 알려준다.
논문 표현처럼 토픽이 semantic compass 역할을 하는 셈이다.
핵심 메시지는 간단하다.
청크 embedding 하나만으로 큰 문단 전체를 대표하게 하지 말고, 그 청크 안에 들어 있는 토픽 분포와 토픽 centroid를 함께 캐시해 두자.
그리고 LLM teacher는 학습 때만 써서 relevance 판단을 distill하고, 실제 추론 시점에는 가벼운 student retriever만으로 topic-aware retrieval을 하자는 것이다.
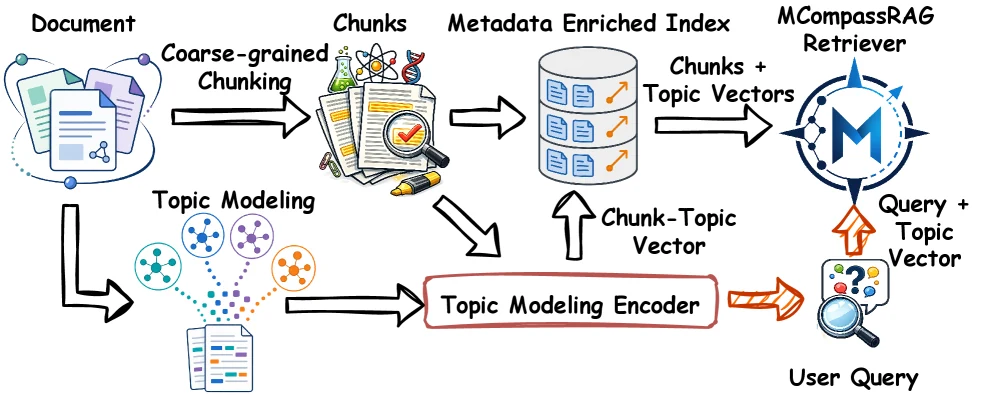
무엇을 해결하려는가
표준 dense retrieval은 query embedding과 chunk embedding의 cosine similarity에 크게 의존한다.
이 방식은 청크가 짧고 단일 주제에 가까울 때는 꽤 잘 맞는다.
문제는 실제 deep research나 사내 지식베이스처럼 긴 문서, 다양한 섹션, 여러 관점이 섞인 corpora에서는 “표면적으로 비슷한 청크”와 “질문에 답하는 청크”가 자주 갈라진다는 점이다.
논문이 보는 기존 해법은 크게 세 갈래다.
| 접근 | 장점 | 비용/한계 |
|---|---|---|
| 더 작은 청크 | evidence precision 상승 | 후보 수 증가, context 손실 가능성 |
| 계층형/구조적 retrieval | 문서 구조를 더 잘 반영 | 전처리·인덱스·선택 단계가 복잡해짐 |
| LLM reranking/filtering | relevance 판단이 좋아짐 | 검색할 때마다 LLM 비용과 latency 발생 |
MCompassRAG는 “큰 청크를 포기하지 않되, 큰 청크 embedding의 semantic noise를 줄이자”는 쪽이다.
큰 청크를 쓰면 검색 공간은 작게 유지할 수 있다.
여기에 토픽 모델이 만든 메타데이터를 붙이면, 청크 안의 여러 의미 축 중 query와 관련된 축을 더 명확히 볼 수 있다.
특히 이 발상은 반복 검색을 많이 하는 deep research agent에 잘 맞는다.
한 번의 retrieval latency 차이는 작아 보여도, agent가 수십 번 evidence를 찾는 흐름에서는 런타임 LLM reranker나 long-context 방식의 비용이 누적된다.
MCompassRAG는 LLM을 학습 단계로 밀어내고, 추론 단계에서는 embedding lookup과 작은 scorer에 가깝게 돌리는 것이 목표다.
핵심 아이디어 / 구조 / 동작 방식
MCompassRAG의 pipeline은 offline 단계와 inference 단계로 나누면 이해하기 쉽다.
Offline에서는 먼저 문서를 청크로 나누고, 각 청크에 대해 토픽 모델이 chunk-topic distribution을 만든다.
각 토픽은 retriever embedding space 안의 centroid vector로 표현된다.
그래서 청크 c는 일반 chunk embedding뿐 아니라, θ_c라는 토픽 분포와 해당 토픽들의 centroid 조합을 함께 갖는다.
이 chunk-topic distribution들은 corpus-level metadata bank에 캐시된다.
추론 때는 query가 들어오면 바로 query topic model을 돌리지 않는다.
논문은 query가 보통 짧아서 직접 토픽 분포를 추정하기 어렵다고 본다.
대신 query embedding으로 metadata bank 안의 관련 chunk-topic distribution들을 고르고, abstraction module이 이 선택된 토픽 분포들을 압축해 query-side topic vector를 만든다.
이후 student MLP classifier가 query 표현과 chunk 표현을 함께 보고 top-k 청크를 점수화한다.
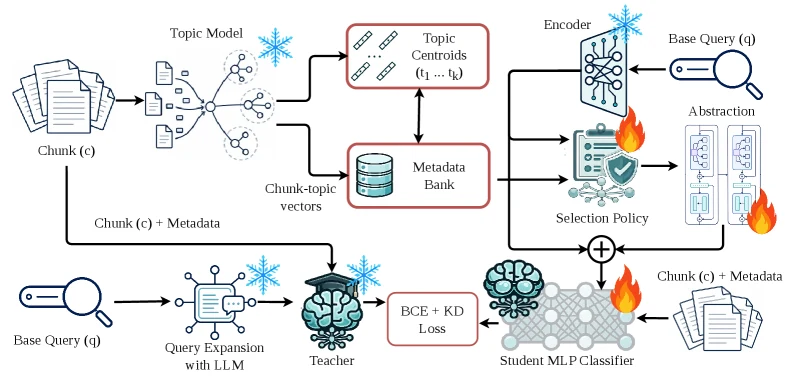
구조를 더 압축하면 다음과 같다.
| 구성 요소 | 하는 일 | 추론 시점 비용 |
|---|---|---|
| Topic model | 청크별 토픽 분포와 topic centroid 생성 | 주로 offline/cache |
| Metadata bank | 모든 chunk-topic distribution 저장 | query별 선택 대상 |
| Selection policy | query와 관련 높은 metadata entry 선택 | 가벼운 neural scoring |
| Abstraction module | 선택된 토픽 분포를 query-side topic vector로 요약 | 작은 Transformer encoder |
| Student retriever / MLP scorer | topic-enriched query와 chunk를 점수화 | 런타임 LLM 호출 없음 |
| LLM teacher | query-chunk relevance label 생성 | 학습 때만 사용 |
여기서 중요한 점은 LLM teacher가 system path에서 사라진다는 것이다.
논문은 GPT-4o로 synthetic query를 만들고, LLM teacher로 relevance supervision을 생성한 뒤, BCE와 distillation loss로 student retriever를 학습한다.
하지만 실제 retrieval에서는 base query만 들어오고, expanded query나 LLM teacher는 쓰지 않는다.
공개 GitHub 저장소도 이 설계와 맞게 구성되어 있다. src/에는 RAG core, index, retriever model, inference code가 있고, topic_models/에는 CEMTM, ETM, CWTM, SoftLTM backend가 있다. data_gen/에는 OpenRouter client, query generation, teacher labeling, negative mining이 들어 있다.
README 기준 기본 흐름은 topic model 학습 → distillation data 생성 → metadata index build → retriever 학습 → retrieval 실행이다.
Python 3.10+, PyTorch 2.x, Transformers 4.51+를 전제로 하며, data generation 단계에는 OpenRouter API key가 필요하다고 되어 있다.
공개된 근거에서 확인되는 점
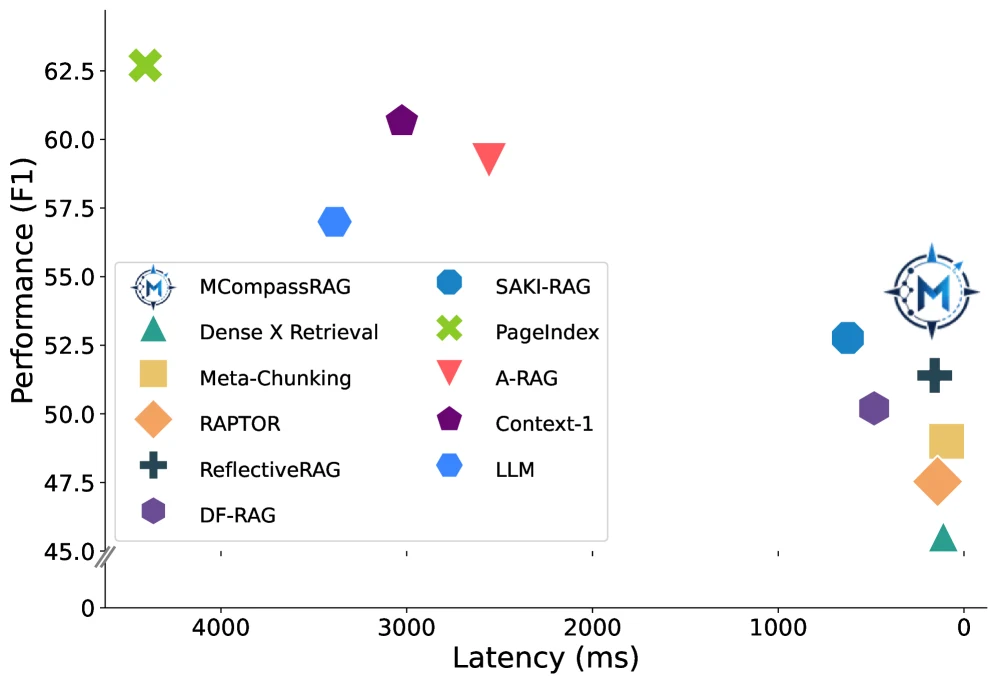
논문은 여섯 개 retrieval benchmark에서 MCompassRAG가 strongest efficient RAG baseline 대비 평균 IE를 8.24% 높이고, 강한 LLM 기반 baseline보다 5배 이상 낮은 latency를 보였다고 보고한다.
여기서 IE는 information efficiency 계열 지표로, precision과 recall을 함께 보는 retrieval 품질 지표로 쓰인다.
대표적인 수치는 다음과 같다.
| 비교 지점 | 보고된 결과 |
|---|---|
| DRBench IE | MCompassRAG 47.97 vs SAKI-RAG 37.47 |
| LegalBench-RAG IE | MCompassRAG 38.40 vs SAKI-RAG 31.23 |
| SCI-DOCS IE | MCompassRAG 94.13 vs LLM+10 Topics oracle 94.67 |
| SQuAD IE | MCompassRAG 93.80 vs LLM+10 Topics oracle 94.10 |
| 평균 IE 개선 | strongest efficient RAG baseline 대비 +8.24% |
| latency 주장 | 강한 LLM 기반 baseline 대비 5배 이상 낮음 |
MCompassRAG가 흥미로운 이유는 LLM+10 Topics oracle과의 간격이다. oracle은 retrieval time에 LLM을 쓰는 상한선에 가깝다.
MCompassRAG는 그보다 조금 낮지만, inference-time LLM 호출 없이 비슷한 retrieval 방향성을 따라간다.
논문의 해석은 “토픽 메타데이터 자체에 chunk embedding만으로는 잡기 어려운 relevance signal이 있고, student retriever가 이를 효율적으로 흡수한다”에 가깝다.
Downstream generation 쪽에서도 비용 차이가 선명하다.
논문 Table 2에서 MCompassRAG는 평균 4,126 tokens/query, 174ms latency로 보고된다.
같은 표에서 SAKI-RAG는 5,584 tokens/query와 925ms, REFRAG는 7,800 tokens/query와 720ms다.
PageIndex는 53,883 tokens/query와 4,408ms, long-context LLM baseline은 41,058 tokens/query와 3,388ms로 훨씬 무겁다.
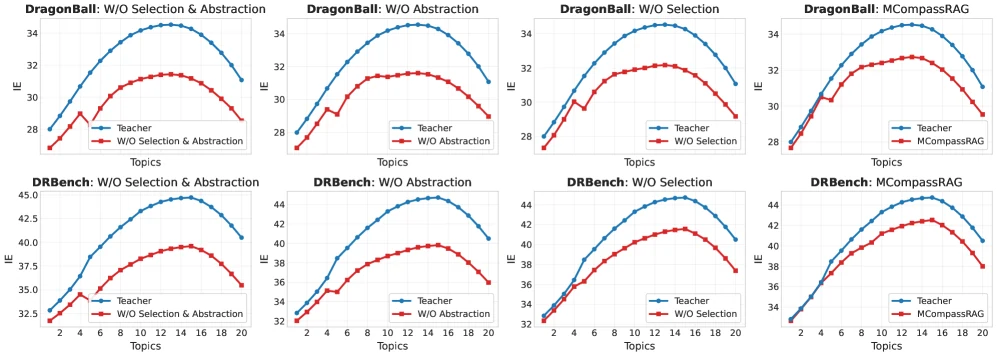
Ablation도 논문의 주장과 잘 맞는다. abstraction module이나 selection policy를 제거하면 IE가 대체로 떨어지고, 둘을 함께 제거했을 때 하락폭이 더 커진다. selection은 query와 관련 있는 metadata entry를 고르는 역할이고, abstraction은 선택된 토픽 분포의 noise를 줄여 query-side signal로 만드는 역할이다.
둘 중 하나만 있어서는 topic metadata가 제대로 “나침반” 역할을 하기 어렵다는 뜻이다.
또 하나 재미있는 결과는 topic 개수다.
토픽을 많이 넘기면 무조건 좋아지는 것이 아니라, Dragonball과 DRBench에서 대체로 12~15개 근처까지 좋아졌다가 이후에는 noise가 늘어 성능이 떨어지는 경향이 보고된다.
실무적으로는 “메타데이터를 붙이면 좋다”보다 “압축된 semantic hint로 쓸 만큼만 붙여야 한다”는 쪽이 더 중요하다.
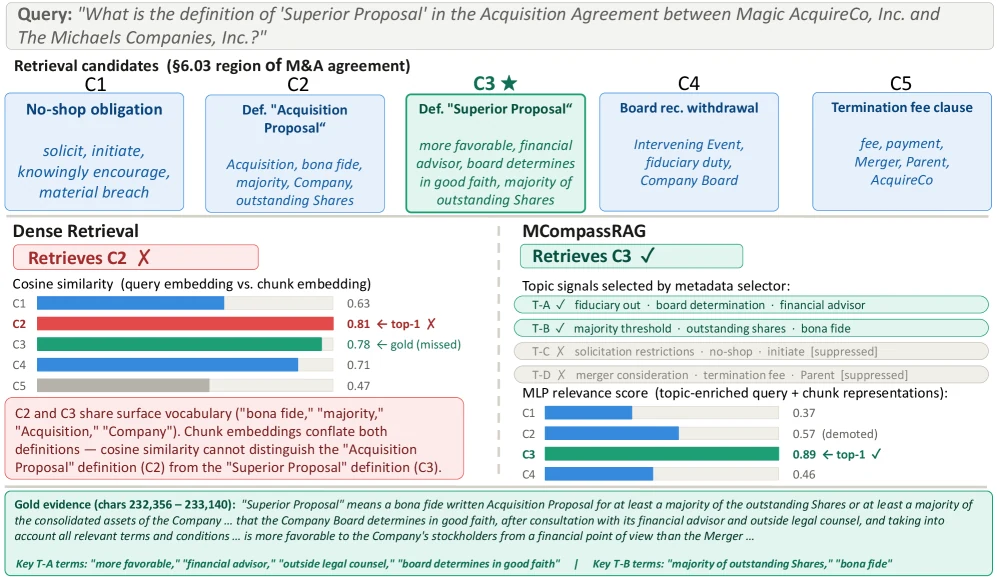
정성 예시도 설계 의도를 잘 보여 준다.
LegalBench-RAG 예시에서는 M&A 계약의 “Superior Proposal” 정의를 묻는 query가 나온다. dense retrieval은 비슷한 단어를 많이 공유하는 인접 clause를 위로 올리지만, MCompassRAG는 fiduciary out, board determination, majority threshold 같은 토픽 신호를 활성화해 gold chunk를 1위로 끌어올린다고 설명한다.
즉 단순 surface overlap이 아니라, 질문이 요구하는 법률적 의미 축을 더 잘 따라가려는 것이다.
실무 관점에서의 해석
MCompassRAG를 바로 “더 좋은 chunking 알고리즘”으로만 읽으면 조금 좁다.
이 논문의 실무적 포인트는 retrieval unit 자체보다, retrieval에 붙는 metadata plane이다.
검색 대상은 여전히 coarse chunk지만, 검색 판단은 chunk embedding 하나가 아니라 chunk가 어떤 토픽 축들을 포함하는지까지 같이 본다.
이 관점은 사내 지식 검색, 긴 기술문서 QA, compliance evidence search, research agent memory retrieval 같은 곳에 유용하다.
이런 corpus에서는 한 문단이나 한 섹션 안에 여러 하위 주제가 섞이는 일이 흔하다.
단일 embedding은 “전체적으로 비슷한 문단”을 찾기 쉽지만, 사용자가 묻는 세부 쟁점이 문단의 일부에만 들어 있으면 신호가 희석된다.
토픽 메타데이터는 이 희석을 줄이는 보조 좌표계가 될 수 있다.
또 하나의 메시지는 LLM을 어디에 둘 것인가다.
MCompassRAG는 LLM teacher를 버리지 않는다.
오히려 LLM의 relevance 판단 능력을 training data generation에 적극적으로 쓴다.
다만 그 비용을 runtime path에서 제거한다.
제품 관점에서는 “강한 LLM으로 비싼 판단을 offline에 모아 student retriever에 증류하고, online path는 작게 유지한다”는 패턴이다.
물론 한계도 분명하다.
| 한계 | 읽을 때의 주의점 |
|---|---|
| 학습 pipeline이 필요함 | 단순 BM25/dense retriever처럼 바로 꽂아 쓰는 방식은 아니다. topic model, metadata index, distillation data, retriever 학습이 필요하다. |
| metadata bank scalability | 아주 큰 corpus에서는 metadata selection 자체도 approximate strategy가 필요할 수 있다고 논문이 future work로 언급한다. |
| 토픽 품질 의존성 | topic model이 실제 query-relevance와 어긋나면 compass가 잘못된 방향을 가리킬 수 있다. |
| benchmark 재현 비용 | 논문 수치를 그대로 재현하려면 benchmark data, GPU, OpenRouter/API 설정, teacher labeling pipeline이 필요하다. |
| long-context 대비 상한 | long-context method처럼 모든 evidence를 한 번에 보는 것이 아니라 fixed retrieval budget에 묶인다. |
그래도 방향은 꽤 설득력 있다.
최근 RAG 최적화가 “더 긴 컨텍스트를 넣자”, “LLM reranker를 붙이자”, “agent가 더 많이 검색하게 하자”로 흐를 때, MCompassRAG는 검색 인덱스 안에 더 좋은 semantic structure를 심어 runtime 비용을 줄이는 쪽을 보여 준다.
특히 반복 retrieval을 많이 하는 agentic RAG에서는 이런 작은 latency 차이가 전체 loop 비용을 크게 바꿀 수 있다.
한 줄로 요약하면
MCompassRAG는 큰 청크의 효율성을 유지하면서도 embedding 하나에 섞인 semantic noise를 줄이기 위해, 청크별 토픽 메타데이터를 “나침반”처럼 붙이고 LLM-teacher distillation으로 런타임 LLM 없이 topic-aware retrieval을 수행하게 만드는 RAG 프레임워크다.