검색 에이전트를 학습시킬 때 흔한 형태는 모델이 계속 길어지는 transcript를 읽고, 그 안에서 무엇을 검색했는지, 어떤 문서가 후보인지, 어떤 증거를 이미 검증했는지까지 모두 기억하게 만드는 것이다.
이 방식은 구현하기 쉽지만, 강화학습 관점에서는 문제가 생긴다.
모델은 의미 있는 검색 결정을 배우는 동시에, 반복 가능한 장부 정리까지 내부 policy로 떠안는다.
Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses는 이 병목을 검색 모델의 지능 부족이 아니라 에이전트-환경 인터페이스 설계 문제로 본다.
논문이 제안하는 Harness-1은 openai/gpt-oss-20b 기반 20B 검색 에이전트로, 후보 문서 풀, 중요도 태그가 붙은 curated set, evidence graph, verification record, 압축·중복 제거 상태를 하네스가 유지한다.
모델은 여전히 무엇을 검색하고, 무엇을 읽고, 어떤 문서를 남기고, 어떤 claim을 검증할지 결정한다.
이 차이는 작아 보이지만, 검색 에이전트 학습의 난이도를 꽤 크게 바꾼다.
논문은 8개 검색 benchmark에서 Harness-1이 평균 curated recall 0.730을 기록해, 평가된 open small search subagent 중 가장 높고, 더 큰 frontier searcher들과도 경쟁적인 성능을 보인다고 보고한다.
핵심은 “20B 모델이 frontier 모델을 이겼다”보다, 명시적 search state 위에서 RL을 하면 작은 모델도 훨씬 안정적인 검색 행동을 배울 수 있다는 주장이다.
무엇을 해결하려는가
일반적인 tool-use search agent는 도구 호출 결과가 prompt에 계속 붙는 형태로 움직인다.
초반에는 단순하지만, episode가 길어지면 transcript는 빠르게 비대해진다.
이미 본 문서를 다시 찾고, 여러 문서에 걸친 entity bridge를 기억하고, 어떤 claim이 어떤 문서로 검증됐는지 추적하는 일은 모두 모델의 암묵적 기억에 의존하게 된다.
문제는 이 장부 정리가 강화학습의 reward 신호를 흐린다는 점이다.
최종 curated set이 비어 있거나 틀렸을 때, 실패 원인이 나쁜 검색어 때문인지, 이미 찾은 증거를 잊어서인지, 검증을 안 해서인지, 아니면 curation을 잘못해서인지 분리하기 어렵다.
도구 vocabulary가 커질수록 policy가 반복 검색만 하거나, 문서 발견은 했지만 final evidence set에 올리지 못하는 실패도 생긴다.
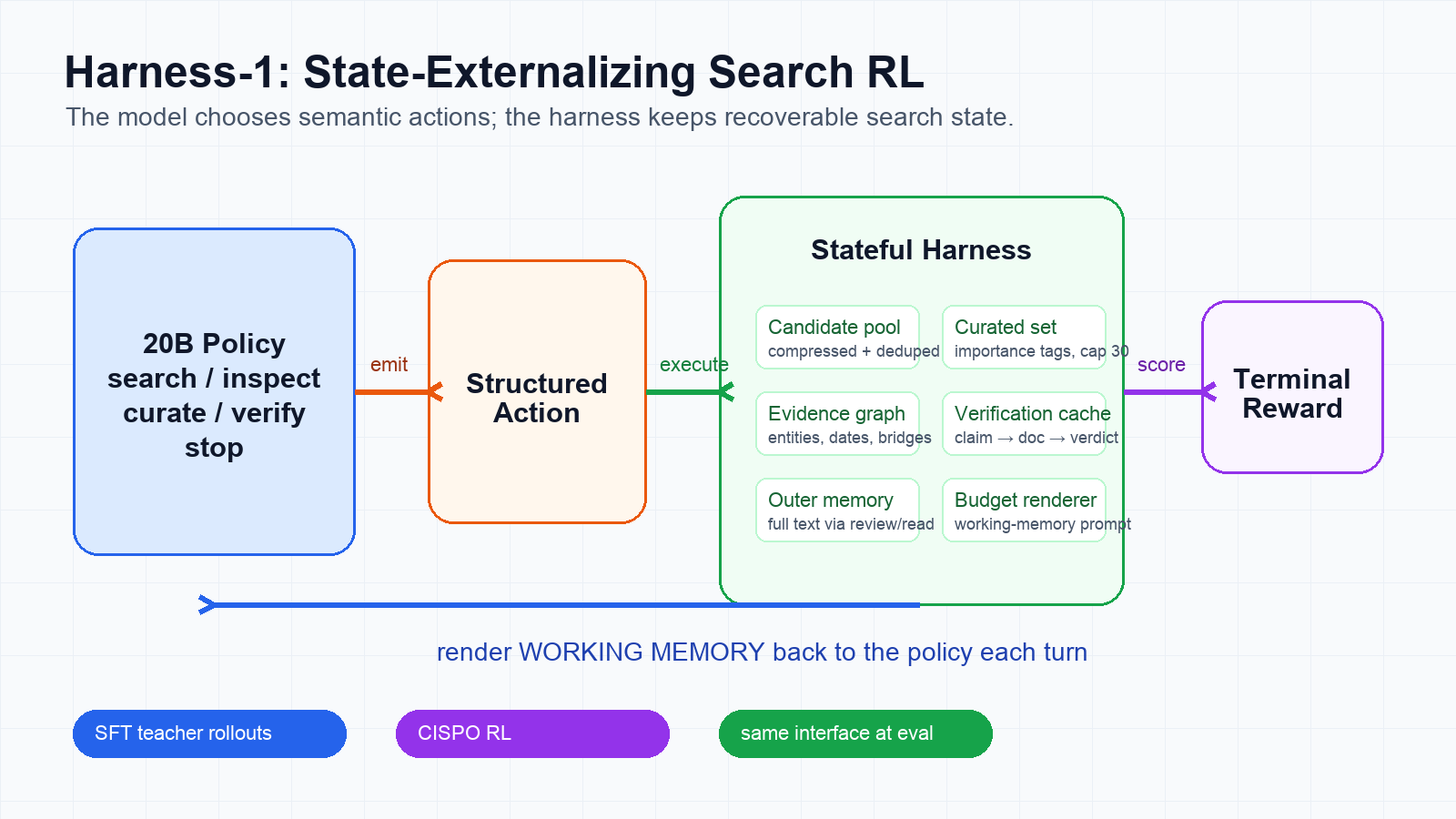
Harness-1은 이 문제를 “stateful cognitive offloading”으로 정식화한다. policy가 맡아야 하는 것은 semantic decision이다.
반대로 후보 풀 관리, 중복 제거, 검색 이력 요약, evidence graph, verification record, context budget 관리는 환경이 더 안정적으로 유지할 수 있다.
하네스는 state machine처럼 동작하고, policy action은 그 state를 편집한다.
핵심 아이디어 / 구조 / 동작 방식
논문이 정의하는 하네스 state는 후보 풀, curated output set, full-text memory, evidence graph, verification record, search history, budget-safe renderer로 나뉜다.
중요한 점은 이 state가 단순 로그가 아니라 다음 action의 조작 대상이라는 것이다.
모델은 search, inspect, curate, verify, stop 같은 구조화된 action을 내고, 하네스는 그 결과를 persistent state에 반영한 뒤 다음 observation을 만든다.
| 구성 요소 | 하네스가 맡는 장부 정리 | policy가 여전히 결정하는 것 |
|---|---|---|
| Candidate pool | 검색 결과를 압축·중복 제거해 후보로 유지 | 어떤 후보를 읽고, 다시 검색하고, curated set에 넣을지 |
| Curated set / importance tags | 최대 30개 문서를 중요도별로 관리하고 eviction 수행 | 어떤 문서를 very high/high/fair/low로 승격·강등할지 |
| Full-text memory | 검색된 chunk의 원문을 prompt 밖 outer memory에 저장 | 어떤 문서를 다시 열어 상세 검토할지 |
| Evidence graph | entity·date·document 간 bridge와 singleton 요약 | 어떤 bridge entity나 관계를 추적할지 |
| Verification records | policy가 쓴 claim에 대한 문서별 yes/no/rationale cache | 어떤 claim을 어떤 문서로 검증할지 |
| Budget renderer | context limit 안에 들어오도록 working memory를 렌더링 | 언제 더 찾고, 언제 멈출지 |
working memory도 두 tier로 나뉜다. prompt-facing tier는 query, curated set, 최근 후보, search history, evidence graph, dedup notice를 작게 보여준다. outer tier는 전체 full-text document memory를 들고 있고, 모델은 review_docs나 read_document로 다시 접근한다.
즉 모델이 매 턴 전체 transcript를 다시 읽는 것이 아니라, 하네스가 정리한 검색 상태를 보고 다음 편집을 결정한다.
학습 pipeline은 teacher rollout, SFT, RL로 이어진다.
논문은 GPT-5.4 live agent를 teacher로 사용해 모든 하네스 기능이 켜진 상태에서 rollout을 만들고, 필터링 후 899개 SFT trajectory를 남긴다.
RL은 SEC train split 3,453 query 위에서 수행된다.
논문이 강조하는 포인트는 대규모 데이터만으로 밀어붙인 것이 아니라, 작은 SFT와 집중된 RL이 명시적 state interface 위에서 작동했다는 점이다.
공개된 근거에서 확인되는 점
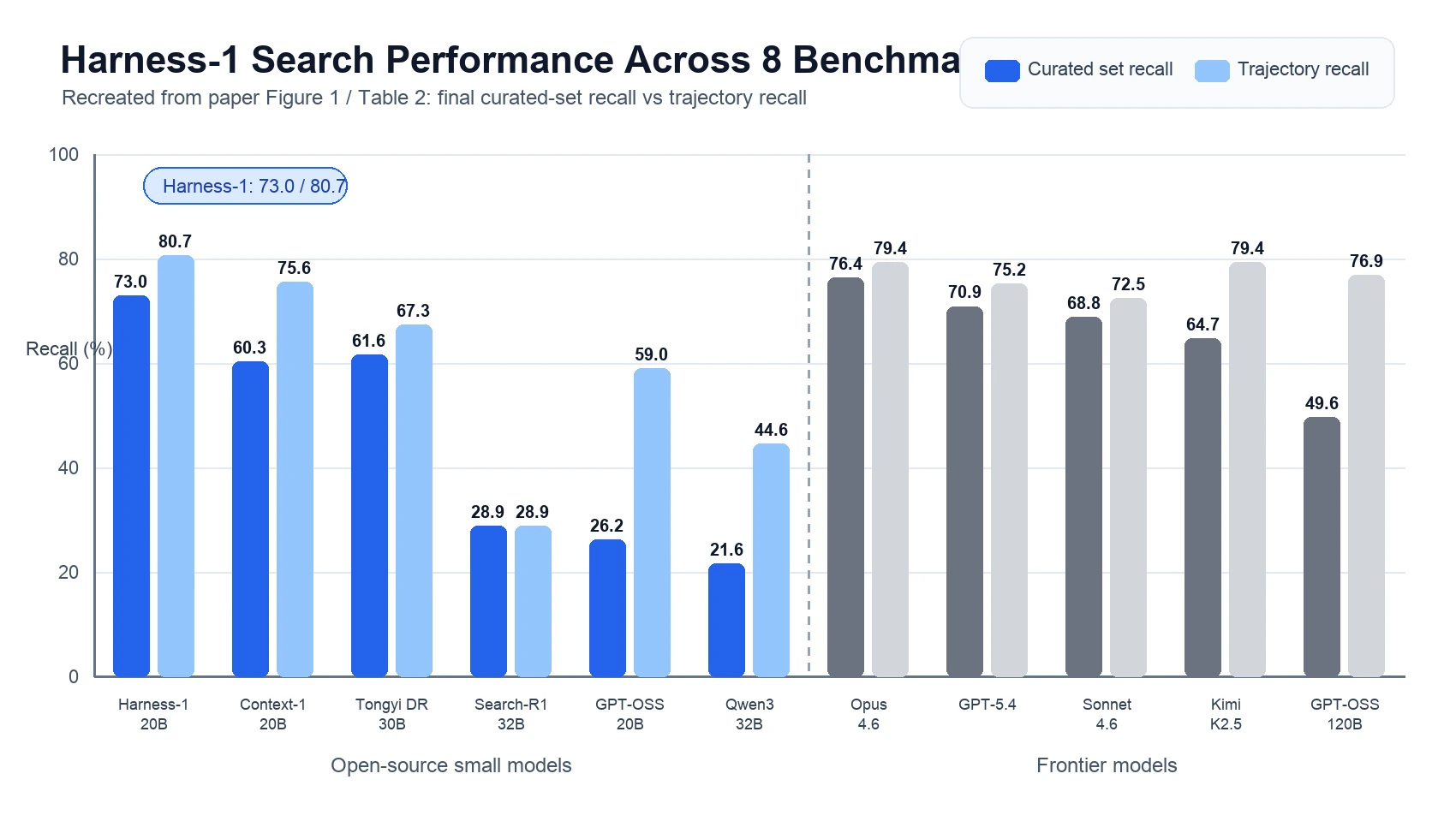
Table 2의 평균 결과를 보면 Harness-1은 open small model 그룹에서 가장 강하다.
8개 benchmark 평균 curated recall은 73.0%, trajectory recall은 80.7%다.
다음으로 강한 open search subagent인 Tongyi DeepResearch 30B의 평균 curated recall 61.6%보다 +11.4p 높다. frontier 모델까지 포함하면 Opus-4.6의 curated recall 76.4%가 가장 높지만, Harness-1은 GPT-5.4, Sonnet-4.6, Kimi-K2.5, GPT-OSS-120B보다 높은 평균 curated recall을 보인다.
| 모델 | 평균 curated recall | 평균 trajectory recall | 해석 |
|---|---|---|---|
| Harness-1 20B | 73.0 | 80.7 | open small search agent 중 최고, frontier 일부와 경쟁 |
| Context-1 20B | 60.3 | 75.6 | 같은 20B급에서 Harness-1의 직접 baseline 역할 |
| Tongyi DeepResearch 30B | 61.6 | 67.3 | 다음으로 강한 open search subagent |
| Search-R1 32B | 28.9 | 28.9 | 이 평가 protocol에서는 낮은 recall |
| Qwen3 32B | 21.6 | 44.6 | trajectory에서 본 문서가 final curation으로 잘 이어지지 않음 |
| Opus-4.6 | 76.4 | 79.4 | 전체 평균 curated recall 1위 frontier baseline |
| GPT-5.4 | 70.9 | 75.2 | Harness-1보다 평균 curated recall은 낮음 |
| Kimi-K2.5 | 64.7 | 79.4 | trajectory recall은 높지만 최종 curated set에서 차이 |
benchmark별로 보면 transfer 신호가 특히 중요하다.
Harness-1의 SFT 데이터는 BrowseComp+, Web, Patents, SEC 계열에 걸쳐 있고, RL은 SEC에서만 수행된다.
그런데 논문은 Context-1 대비 recall gain이 source-family benchmark 평균 +7.9p인 반면, LongSealQA, Seal0QA, FRAMES, HotpotQA 같은 held-out transfer benchmark에서는 평균 +17.0p라고 보고한다.
단순히 훈련 domain을 외운 것이 아니라, search state를 편집하는 행동이 다른 corpus에도 옮겨갔다는 해석을 붙인다.
ablation도 이 해석을 뒷받침한다.
같은 Harness-1 checkpoint에서 inference-time 하네스 기능을 하나씩 끄면, 중요도 태그를 제거했을 때 final-answer recall이 -7.9%, evidence graph를 observation에서 숨기면 -5.4%, verify tool을 unavailable로 만들면 -3.9%가 된다.
모든 하네스 mechanism을 끄면 BrowseComp+ curated recall은 0.584에서 0.513으로 내려간다.
반대로 일부 중복 제거나 review path는 수치가 단순히 한 방향으로만 움직이지 않는데, 이는 하네스 기능이 “있으면 무조건 좋다”라기보다 policy와 reward, context budget이 같이 맞물린 설계 문제임을 보여준다.
공개 release surface도 확인할 만하다.
GitHub 저장소 pat-jj/harness-1는 하네스, training, inference, datagen, evaluation script, vLLM/BrowseComp+ 실행 문서를 포함한다.
2026년 6월 5일 GitHub API 기준으로는 30 stars, 5 forks, 1 open issue, 기본 브랜치 main, tags 없음, /releases/latest 404, 별도 checked-in LICENSE 파일 없음으로 확인됐다.
따라서 저장소는 논문·모델 검토와 재현용 runbook을 제공하지만, 아직 versioned production package처럼 읽기는 어렵다.
Hugging Face 모델 pat-jj/harness-1은 public·ungated이고, openai/gpt-oss-20b를 base model로 둔 transformers/safetensors checkpoint다.
같은 시점 HF API 기준으로 downloads 378, likes 13, BF16 약 20.9B 파라미터와 9개 safetensors shard, tokenizer/config 파일이 공개되어 있다.
모델 card는 vLLM, SGLang, Docker Model Runner, Transformers 로딩 예시를 제공하지만, BrowseComp+ full evaluation에는 Chroma corpus, qrel/answer 파일, OpenAI credential, 선택적 Baseten reranker credential 같은 별도 평가 환경이 필요하다.
실무 관점에서의 해석
Harness-1의 실무적 의미는 “검색 에이전트를 만들 때 더 강한 모델을 쓰자”가 아니다.
오히려 반대다.
모델이 매번 긴 transcript에서 장부를 복원하게 하는 대신, environment가 유지할 수 있는 상태는 명시적으로 분리하자는 주장이다.
이 방향은 agentic RAG, deep research, codebase search, 내부 문서 탐색처럼 긴 episode와 반복 검증이 필요한 시스템에서 특히 중요하다.
제품 관점에서는 세 가지 교훈이 있다.
첫째, 검색 에이전트 평가는 retriever recall만 보면 부족하다. trajectory에서 관련 문서를 만났는지, final curated set에 제대로 올렸는지, downstream answer document가 빠졌는지를 분리해 봐야 한다.
Harness-1은 trajectory recall과 curated recall을 함께 측정하면서 “찾았지만 최종 증거로 못 남긴” 실패를 드러낸다.
둘째, 하네스는 단순 scaffolding이 아니라 학습 대상의 일부다. importance tag, evidence graph, verification cache, budget renderer가 policy의 행동 공간을 바꾼다.
같은 20B 모델이라도 transcript-only 환경에서 학습하는 것과, 편집 가능한 search state 위에서 학습하는 것은 전혀 다른 문제다.
이 점은 최근 agentic search 논문들이 반복해서 보여주는 “retrieval은 모델·도구·출력 전달 방식의 결합체”라는 흐름과 맞닿아 있다.
셋째, release maturity는 아직 연구 artifact에 가깝다.
모델 weight와 코드가 공개된 것은 강한 장점이지만, 태그·릴리스·라이선스 파일이 비어 있고, 전체 benchmark 재현에는 외부 corpus와 credential이 필요하다.
당장 production 검색 subagent로 가져오기보다는, stateful harness 설계와 curation/verification metric을 내부 평가 harness에 차용하는 쪽이 더 현실적이다.
내가 보기에 Harness-1의 가장 흥미로운 문장은 “작은 모델이 frontier를 따라잡았다”가 아니라, RL이 배워야 할 일을 줄여 주면 RL이 더 잘 배울 수 있다는 쪽에 있다.
검색 에이전트에서 반복 가능한 bookkeeping을 environment로 빼고, 모델에는 의미 있는 search decision만 남기는 설계는 앞으로 많은 agent system에서 기본 패턴이 될 가능성이 크다.