에이전트 스킬 논의는 보통 “반복 작업을 어떤 SKILL.md로 저장할 것인가”에서 출발한다.
그런데 실제 조직이나 개인 워크플로에서는 더 까다로운 요구가 생긴다.
동료가 떠난 뒤에도 그 사람이 코드 리뷰에서 중요하게 보던 기준, 장애 대응 때의 판단 순서, 문서를 쓰는 방식, 회의에서 선호하던 트레이드오프 설명법을 에이전트가 제한적으로 참조하게 만들 수 있을까?
COLLEAGUE.SKILL: Automated AI Skill Generation via Expert Knowledge Distillation는 이 질문을 “사람을 복제하는 persona 시스템”이 아니라 사람이나 역할에 관한 trace를 에이전트 스킬 패키지로 증류하는 artifact 문제로 바꾼다.
논문과 공식 저장소, 프로젝트 사이트를 함께 보면 핵심은 단순한 프롬프트 생성기가 아니다.
입력 trace를 수집하고, capability와 bounded behavior를 분리해 파일로 만들고, 설치·수정·롤백·삭제·공개 갤러리 배포까지 이어지는 수명주기 레이어를 제안한다.
흥미로운 점은 이 시스템이 “그 사람이 실제로 무엇을 말할지”를 맞힌다고 주장하지 않는다는 것이다.
오히려 논문은 generated skill을 읽고, 고치고, 버전을 되돌리고, 공개 여부를 통제할 수 있는 소프트웨어 패키지로 다룬다.
그래서 COLLEAGUE.SKILL은 개인화 모델이나 role-play agent보다 좁지만, 운영 관점에서는 더 구체적인 질문을 던진다.
어떤 인간 trace가 어떤 범위와 증거 아래 agent context에 들어가도 되는가다.

무엇을 해결하려는가
LLM agent가 오래 쓰일수록 유용한 지식은 모델 안보다 바깥에 쌓인다.
프로젝트별 명령, 팀의 코드 스타일, 리뷰 checklist, 운영 사고방식, 특정 사용자의 선호 같은 것들은 대부분 명시적인 문서가 아니라 채팅, PR 코멘트, 이메일, 회의 노트, 스크린샷, 이전 대화의 correction에 흩어져 있다.
메모리 시스템은 이 조각들을 검색할 수 있지만, 사용자가 읽고 수정할 수 있는 실행 단위로 정리해 주지는 않는다.
COLLEAGUE.SKILL이 겨냥하는 첫 번째 병목은 바로 이 heterogeneous trace → reusable skill 변환이다.
논문은 동료 인수인계를 가장 구체적인 출발점으로 둔다.
떠나는 엔지니어의 API 리뷰 기준, incident triage heuristic, escalation threshold, 커뮤니케이션 규칙을 hidden memory가 아니라 inspectable skill package로 남기자는 것이다.
두 번째 병목은 persona와 능력의 혼합이다.
사람 기반 agent를 만들 때 흔한 실패는 지식, 판단, 말투, 관계적 기대를 하나의 긴 prompt에 섞는 것이다.
그러면 무엇이 실제 업무 기준이고, 무엇이 표면적 표현 습관이며, 어디까지가 허용된 source boundary인지 구분하기 어렵다.
COLLEAGUE.SKILL은 capability track과 bounded behavior track을 분리해 이 문제를 파일 구조 차원에서 다룬다.
세 번째 병목은 거버넌스다.
사람의 trace를 다루는 순간 동의, 소유권, 삭제, 수정 이력, 공개 가능성, source boundary가 기술 설계의 일부가 된다.
논문이 “person-grounded skill”을 portable, inspectable, composable, correctable, governable artifact로 정의하는 이유도 여기에 있다.
핵심 아이디어 / 구조 / 동작 방식
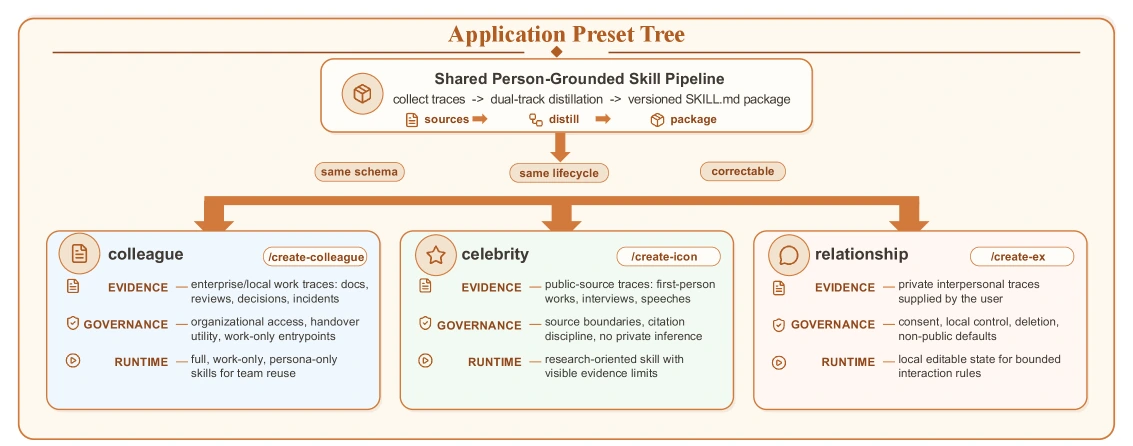
시스템의 기본 입력은 lightweight profile, source scope, 그리고 여러 source material이다.
출력은 generated files, machine-readable metadata, lifecycle state를 가진 skill package다.
이때 중요한 것은 스킬이 단일 문서가 아니라 여러 entrypoint와 metadata를 가진 패키지라는 점이다.
| 산출물 | 주 사용처 | 역할 |
|---|---|---|
SKILL.md |
agent runtime, 사용자 | capability와 behavior rule을 합친 기본 invokable skill |
work.md |
사용자, updater | 절차, 기준, heuristic, task pattern을 담는 editable capability 문서 |
persona.md |
사용자, updater | 표현 방식, interaction posture, boundary, correction log를 담는 behavior 문서 |
work_skill.md |
agent runtime | capability-only entrypoint |
persona_skill.md |
agent runtime | persona-only entrypoint |
manifest.json |
installer, gallery | entrypoint, artifact list, compatible runtime, slash command, toolchain metadata |
meta.json |
lifecycle tools | schema, provenance, lifecycle version, correction count, compatibility field |
이 artifact contract는 논문의 가장 실용적인 부분이다. agent가 전체 personality를 무조건 흉내 내는 대신, 상황에 따라 full skill, work-only, persona-only entrypoint를 나눠 호출할 수 있다.
예를 들어 코드 리뷰 자동화에서는 동료의 말투보다 work-only review standard가 더 적절하고, public figure mental-model skill에서는 source-grounded reasoning pattern과 citation boundary가 더 중요하다.
공식 README와 설치 문서를 보면 구현은 colleague, celebrity, relationship 세 family를 중심으로 구성되어 있다. colleague는 업무 문서·리뷰·incident note 같은 조직 trace에서 실무 판단을 추출한다. celebrity는 공개 인터뷰, 글, 연설, 의사결정 기록을 바탕으로 mental model과 표현 경계를 만든다. relationship은 훨씬 민감한 개인 trace를 전제로 하므로 local control, deletion, non-public default가 더 중요해진다.
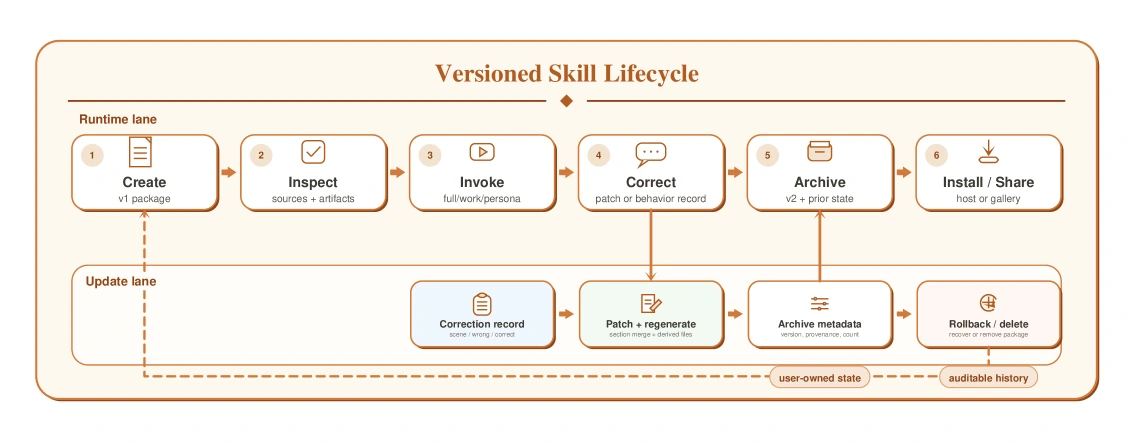
생성 workflow는 대략 다섯 단계로 읽을 수 있다.
먼저 Feishu, DingTalk, Slack, WeChat SQLite export, 이메일, PDF, 이미지, 스크린샷, Markdown, direct paste 같은 source를 수집한다.
그다음 analyzer가 capability와 behavior evidence를 분리한다. builder가 work.md와 persona.md를 만들고, writer가 schema v3 기반의 SKILL.md, manifest.json, meta.json, sub-skill entrypoint를 생성한다.
마지막으로 Claude Code, OpenClaw, Codex, Hermes 같은 host에 설치하거나, 권리와 metadata가 맞을 때 gallery 제출을 준비한다.
수정 루프도 별도 장치로 잡혀 있다.
“그 사람은 여기서 이렇게 말하지 않는다” 같은 자연어 correction이 들어오면, 시스템은 work 관련 correction을 Markdown patch로, behavior 관련 correction을 correction record로 정규화한다.
이후 현재 버전을 archive하고, 새 버전을 재생성하며, 필요하면 version manager로 rollback하거나 삭제할 수 있다.
공개된 근거에서 확인되는 점
이번 논문은 benchmark score로 “사람과 비슷하게 답한다”거나 “업무 성능이 얼마나 오른다”를 보이는 논문이 아니다.
공개 근거는 주로 artifact design, 구현 표면, 배포 지표에 있다.
이 차이를 분리해서 읽는 것이 중요하다.
| 공개 표면 | 확인되는 내용 | 해석 |
|---|---|---|
| arXiv 2605.31264 | person-grounded trace-to-skill distillation, dual representation, artifact schema, lifecycle, responsible deployment 논의 | 연구 주장은 artifact-level claim에 가깝다 |
| arXiv HTML figures | architecture, preset tree, lifecycle, public deployment counter 제공 | 블로그와 구현 검토에 쓸 수 있는 공식 시각 자료가 있다 |
GitHub titanwings/colleague-skill |
기본 브랜치 dot-skill, MIT License, Python/Shell 코드, README.md, INSTALL.md, ROADMAP.md, SKILL.md, 논문 PDF 포함 |
단순 논문 아이디어가 아니라 실제 skill creator repo로 공개되어 있다 |
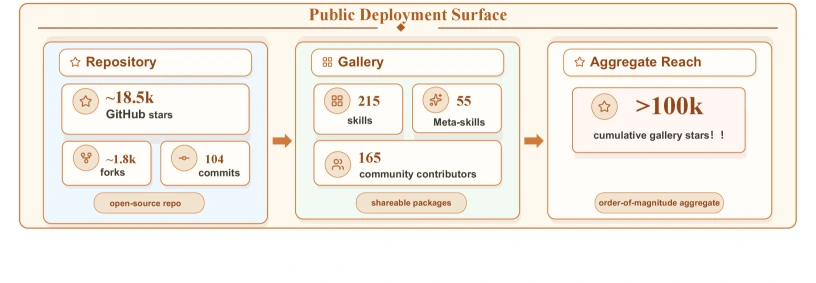
| GitHub API 조회 시점 | 약 18.9k stars, 1.9k forks, open issues 31, 최근 push 2026-06-01, latest release는 404, tag는 v0.01 확인 |
관심과 확산은 크지만, 공식 GitHub Release가 정리된 제품 릴리스라기보다 빠르게 움직이는 초기 공개물에 가깝다 |
| README / INSTALL | /dot-skill entrypoint, 생성 skill의 full/work/persona invocation, Claude Code/OpenClaw/Codex/Hermes 설치 경로, 다양한 source collector 설명 |
multi-host skill ecosystem을 전제로 한 배포 설계가 들어 있다 |
| 프로젝트 사이트 / 논문 카운터 | 2026-05-28 기준 gallery 215 skills, 55 meta-skills, 165 contributors, gallery star aggregate 100k+로 보고 | task performance 지표가 아니라 community distribution surface 지표로 읽어야 한다 |
논문 Figure 4도 이 해석을 명확히 한다. repository stars, gallery skill 수, cumulative gallery stars는 공개 배포 면적을 보여 주는 숫자이지, 생성된 skill의 충실도나 안전성을 직접 증명하지 않는다.
특히 person-grounded artifact에서는 “많이 쓰인다”와 “올바르게 경계 지어진다”가 같은 말이 아니다.
지원 source의 폭도 구현 관점에서 의미가 있다.
공식 README는 Feishu API, DingTalk browser path, Slack API, WeChat SQLite export, PDF/image/screenshot, Feishu JSON, email .eml/.mbox, Markdown/direct paste를 나열한다.
이는 COLLEAGUE.SKILL이 “문서 한 장을 요약하는 도구”가 아니라, 실제 사람 trace가 여러 시스템에 흩어져 있다는 전제에서 출발한다는 뜻이다.
동시에 release maturity에는 보수적으로 봐야 할 신호도 있다.
GitHub API 기준 latest release는 404였고, tags는 v0.01 하나가 확인된다.
ROADMAP은 v1.0.0 official release, discussion, public roadmap board 등을 앞으로의 작업으로 적고 있다.
따라서 내부 운영에 도입하려는 팀이라면 README의 지원 범위와 실제 collector 권한, private data retention, generated artifact review 절차를 별도로 검증해야 한다.
실무 관점에서의 해석
COLLEAGUE.SKILL의 가장 좋은 아이디어는 사람 기반 agent를 identity simulation 문제가 아니라 artifact governance 문제로 낮춰 잡은 것이다.
“퇴사한 동료를 agent로 되살린다”는 식의 과장된 프레임은 위험하다.
그러나 “그 동료가 반복적으로 남긴 리뷰 기준과 판단 heuristic을 source-bound skill로 저장하고, work-only entrypoint로 호출한다”는 프레임은 실무적으로 꽤 현실적이다.
기업 에이전트 운영에서 특히 유용한 부분은 capability/persona 분리다.
대부분의 업무 자동화에는 개인 말투보다 검토 기준, 예외 처리 방식, escalation rule, 문서화 습관이 중요하다.
이를 work.md로 분리하면 팀은 민감한 persona mimicry 없이도 실무 지식을 재사용할 수 있다.
반대로 style이나 interaction rule이 필요한 상황에서는 persona.md를 별도로 읽고, 그 경계를 사용자에게 보이게 만들 수 있다.
두 번째로 중요한 점은 correction이 first-class lifecycle이라는 것이다.
개인 trace에서 추출한 rule은 처음부터 완벽할 수 없다.
오래된 문서가 현재 규칙과 충돌할 수 있고, 한 번의 강한 의견이 일반 원칙처럼 과대해석될 수도 있다.
그래서 generated skill은 모델 memory보다 source file과 version history에 가까워야 한다.
읽고, 고치고, diff를 보고, 롤백할 수 있어야 한다.
세 번째는 distribution boundary다. generated skill이 로컬에 머무를지, 팀 host에 설치될지, public gallery로 나갈지는 완전히 다른 위험 프로파일을 갖는다.
논문이 gallery를 optional distribution layer로 두고, source rights와 metadata를 강조하는 이유도 여기에 있다.
특히 celebrity와 relationship preset은 잘못 설계하면 citation boundary, emotional overattachment, non-consensual simulation 문제로 바로 이어질 수 있다.
내가 보기에는 COLLEAGUE.SKILL을 agent skill ecosystem의 다음 흐름과 연결해서 읽는 편이 좋다.
SkillsVote가 “어떤 스킬을 추천하고 어떤 실행 증거를 라이브러리에 반영할 것인가”라는 registry governance 문제에 가깝다면, COLLEAGUE.SKILL은 “사람이나 역할에 관한 trace를 어떤 파일 계약과 수정 수명주기로 스킬화할 것인가”에 답한다.
즉 하나는 skill library 운영 레이어이고, 다른 하나는 person-grounded skill 생성 레이어다.
한계와 책임 있는 배포
가장 큰 한계는 평가의 성격이다.
논문은 artifact schema, workflow, deployment surface를 잘 보여 주지만, 생성된 skill이 실제 동료의 리뷰 품질을 어느 정도 보존하는지, capability-only variant가 persona risk를 얼마나 줄이는지, correction이 regression 없이 행동을 개선하는지는 별도의 human/task study가 필요하다고 인정한다.
따라서 이 시스템을 “전문가 복제”로 읽으면 과장이고, “inspectable skill package generator”로 읽으면 더 정확하다.
둘째, source quality와 consent가 성능만큼 중요하다. trace가 편향되어 있거나 오래되었거나, target person이 공유를 원하지 않는 자료라면 좋은 distillation pipeline도 안전한 artifact를 보장하지 못한다.
특히 relationship preset은 기술적으로 흥미롭더라도 기본값은 local, deletable, non-public이어야 하고, public sharing은 강한 opt-in과 takedown 경로가 있어야 한다.
셋째, gallery와 community scale은 양날의 검이다.
215개 skill과 165명의 contributor는 생태계 신호이지만, 사람 기반 skill이 많아질수록 source boundary label, license, provenance, review, redaction, disclosure가 더 중요해진다.
스킬은 단순 prompt snippet보다 강한 재사용 단위이기 때문에, 배포가 쉬워질수록 governance도 함께 강해져야 한다.
그래도 COLLEAGUE.SKILL이 제시하는 방향은 의미가 있다.
에이전트가 개인이나 팀의 맥락을 오래 다루려면 hidden memory만으로는 부족하다.
기억은 검색 가능해야 할 뿐 아니라, 사람이 읽을 수 있고, 수정할 수 있고, 설치 경계를 선택할 수 있어야 한다.
COLLEAGUE.SKILL은 그 요구를 SKILL.md 생태계의 언어로 번역한 초기 reference implementation에 가깝다.
결론적으로 이 논문은 “사람을 agent로 만든다”보다 훨씬 좁고 건전한 명제를 제안한다.
사람의 일부 trace는 source boundary와 lifecycle을 가진 skill artifact로 만들 수 있다.
그 artifact가 유용하려면 능력과 행동을 분리하고, correction과 rollback을 설계하며, 공개 배포를 별도 거버넌스 문제로 다뤄야 한다. agent skill이 단순 실행 팁에서 팀 지식과 개인화 운영 자산으로 확장될수록, 이런 artifact-level 설계가 점점 더 중요해질 것이다.