비전-언어 모델이 “이미지 안의 무엇을 어디에 있는가”까지 다루려면 결국 언어와 좌표 사이를 오가야 한다.
최근 VLM들은 객체 탐지, 문서 레이아웃, GUI grounding, OCR 위치 추정, referring expression comprehension을 모두 텍스트 입출력 문제처럼 다루려 한다.
하지만 이 방식에는 불편한 병목이 있다.
박스 하나는 본질적으로 (x1, y1, x2, y2)가 함께 움직이는 2D 기하 구조인데, 많은 generative grounding 모델은 이를 여러 좌표 토큰으로 쪼개 순차 생성한다.
NVIDIA Research의 LocateAnything은 이 병목을 정면으로 겨냥한다.
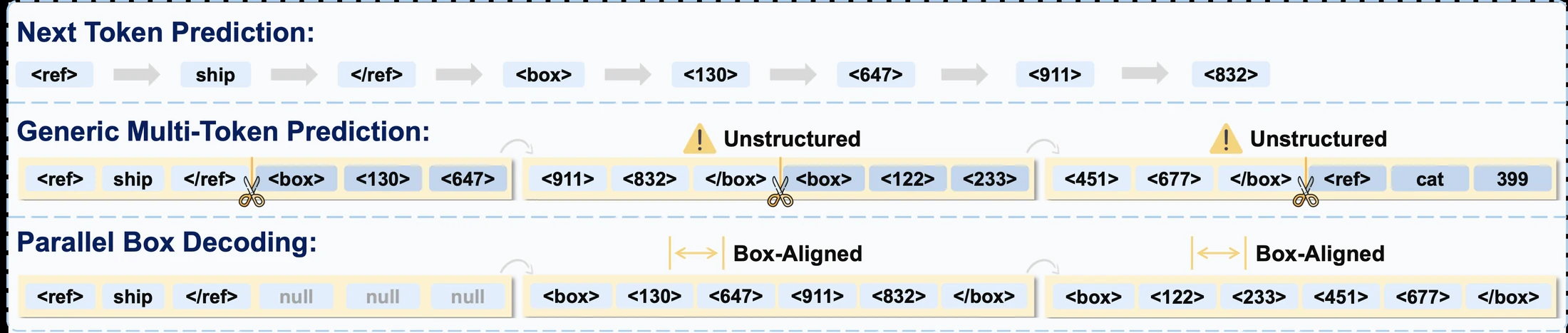
논문과 프로젝트 페이지가 내세우는 핵심은 **Parallel Box Decoding(PBD)**이다.
좌표를 x1 → y1 → x2 → y2처럼 하나씩 뽑는 대신, 박스나 포인트를 하나의 atomic geometric unit으로 보고 한 번에 병렬 예측한다.
그래서 이 글의 관전 포인트는 “또 다른 object detection 모델”이 아니라, VLM 기반 localization을 더 빠르고 더 기하적으로 일관된 decoding 문제로 바꿀 수 있는가다.
공개 bundle도 비교적 넓다. arXiv paper와 NVIDIA project page, NVlabs/Eagle/Embodied 코드, Hugging Face nvidia/LocateAnything-3B 모델, 데모 Space가 함께 제공된다.
다만 모델 license는 NVIDIA License 기반의 비상업 연구·평가용이고, 대규모 학습 데이터셋은 통계와 data engine 설명은 공개됐지만 project page 기준으로 dataset은 아직 incoming 상태다.
즉 실험을 읽을 때는 “논문+모델+코드는 나와 있지만, 전체 데이터 재현성은 아직 제한된 release”로 보는 편이 안전하다.
무엇을 해결하려는가
LocateAnything가 겨냥하는 문제는 좌표 표현의 구조적 mismatch다.
기존 VLM grounding 방식은 보통 박스 좌표를 텍스트 숫자나 quantized coordinate token으로 직렬화한다.
이 경우 좌표 네 개는 서로 강하게 결합되어 있는데도, 모델은 각 토큰을 causal sequence 안에서 하나씩 생성한다.
박스 수가 많아질수록 decoding step이 늘고, 한 좌표의 오차가 다음 좌표와 structural token으로 전파될 수 있다.
이 병목은 GUI agent나 document AI처럼 “정답이 대충 맞는 설명”이 아니라 “정확히 클릭하거나 자를 영역”이 필요한 응용에서 더 커진다.
예를 들어 아이콘 하나를 찍어야 하는 GUI grounding, 작은 글자를 박스로 감싸야 하는 OCR localization, 빽빽한 물체가 많은 dense detection에서는 high-IoU 품질과 latency가 동시에 중요하다.
모델이 큰지보다, 많은 박스와 포인트를 얼마나 빠르고 일관되게 뽑는지가 실제 시스템 성능을 좌우한다.
논문은 일반적인 multi-token prediction도 충분하지 않다고 본다.
임의 길이의 토큰 chunk를 병렬로 예측하면 category boundary나 box boundary를 가로지르는 이상한 묶음이 생길 수 있기 때문이다.
LocateAnything의 주장은 여기서 한 단계 더 구체적이다.
병렬화를 하되, 그 단위를 임의 token span이 아니라 박스·포인트라는 구조화된 기하 단위에 맞춰야 한다는 것이다.
핵심 아이디어 / 구조 / 동작 방식
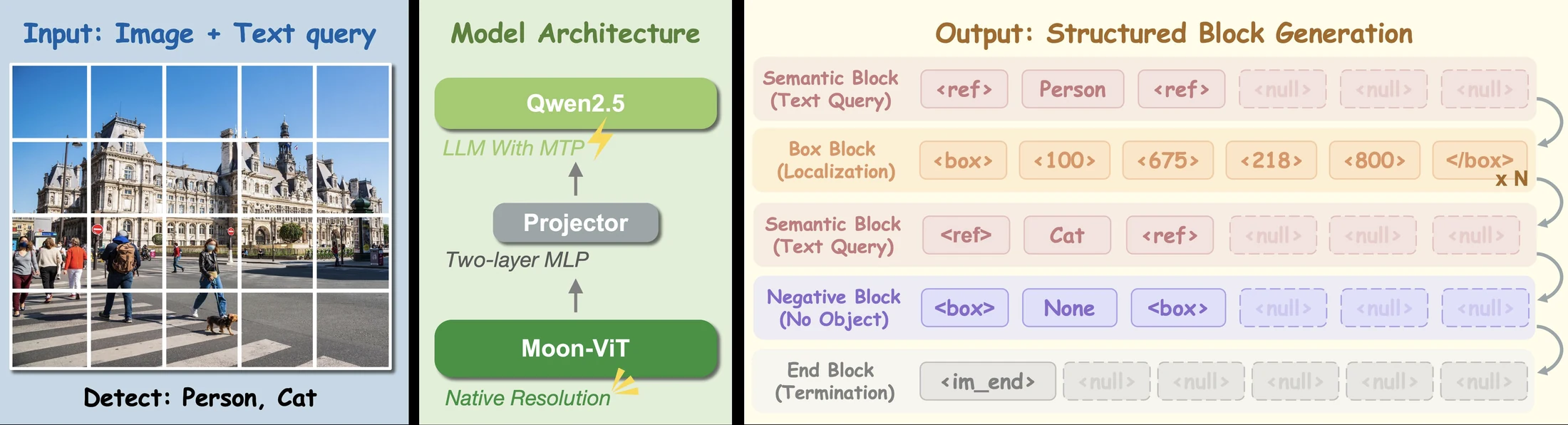
LocateAnything의 출력은 고정 길이 block sequence로 구성된다.
좌표는 [0, 1000] 범위의 coordinate token으로 정규화·이산화되고, 각 block은 semantic block, box block, negative block, end block처럼 기능별 의미를 갖는다.
논문은 block length를 L = 6으로 두고, box block 안에 <box> x1 y1 x2 y2 </box>와 같은 구조를 담는다.
핵심은 box 내부 token들이 같은 기하 객체를 구성한다는 사실을 모델 학습과 decoding에 반영한다는 점이다.
아키텍처는 Moon-ViT vision encoder, Qwen2.5 language decoder, MLP projector를 결합한 native-resolution VLM 형태다.
이미지와 자연어 query를 입력으로 받아 visual token을 만들고, language decoder가 box-aligned block을 생성한다.
Hugging Face config도 LocateAnythingForConditionalGeneration, custom LocateAnythingProcessor, block_size: 6, Qwen/Qwen2.5-3B-Instruct 기반 text config, moonshotai/MoonViT-SO-400M 기반 vision config를 노출한다.
학습은 next-token prediction(NTP)과 block-wise multi-token prediction(MTP/PBD)을 함께 둔다.
순수 병렬 block만 학습하면 causal language modeling 능력이나 format robustness가 떨어질 수 있기 때문에, 공유 context 위에 NTP stream과 block stream을 나누고 attention mask를 설계한다. block 내부 token은 같은 구조 단위를 공유하고, block 간에는 causal 순서를 유지하는 식이다.
추론 모드는 세 가지로 읽을 수 있다.
Fast mode는 PBD/MTP를 적극적으로 써 throughput을 높인다.
Slow mode는 표준 NTP에 가까워 더 보수적이다.
Hybrid mode는 기본적으로 PBD를 쓰다가 format irregularity나 spatial ambiguity가 감지되면 해당 block을 버리고 마지막 검증 prefix로 되돌아가 NTP로 재생성한다.
실무적으로는 이 hybrid 설계가 중요하다.
병렬화는 빠르지만, localization output은 형식 하나가 깨져도 downstream action이 실패할 수 있기 때문이다.
LocateAnything-Data의 역할
PBD만으로 모든 성능이 설명되는 것은 아니다.
논문과 README는 LocateAnything-Data를 함께 강조한다.
공개 자료 기준 규모는 12M unique images, 138M+ natural-language queries, 785M bounding boxes다. task 구성도 일반 object detection에만 몰려 있지 않고, GUI grounding, referring comprehension, OCR, layout grounding, pointing을 같이 포함한다.
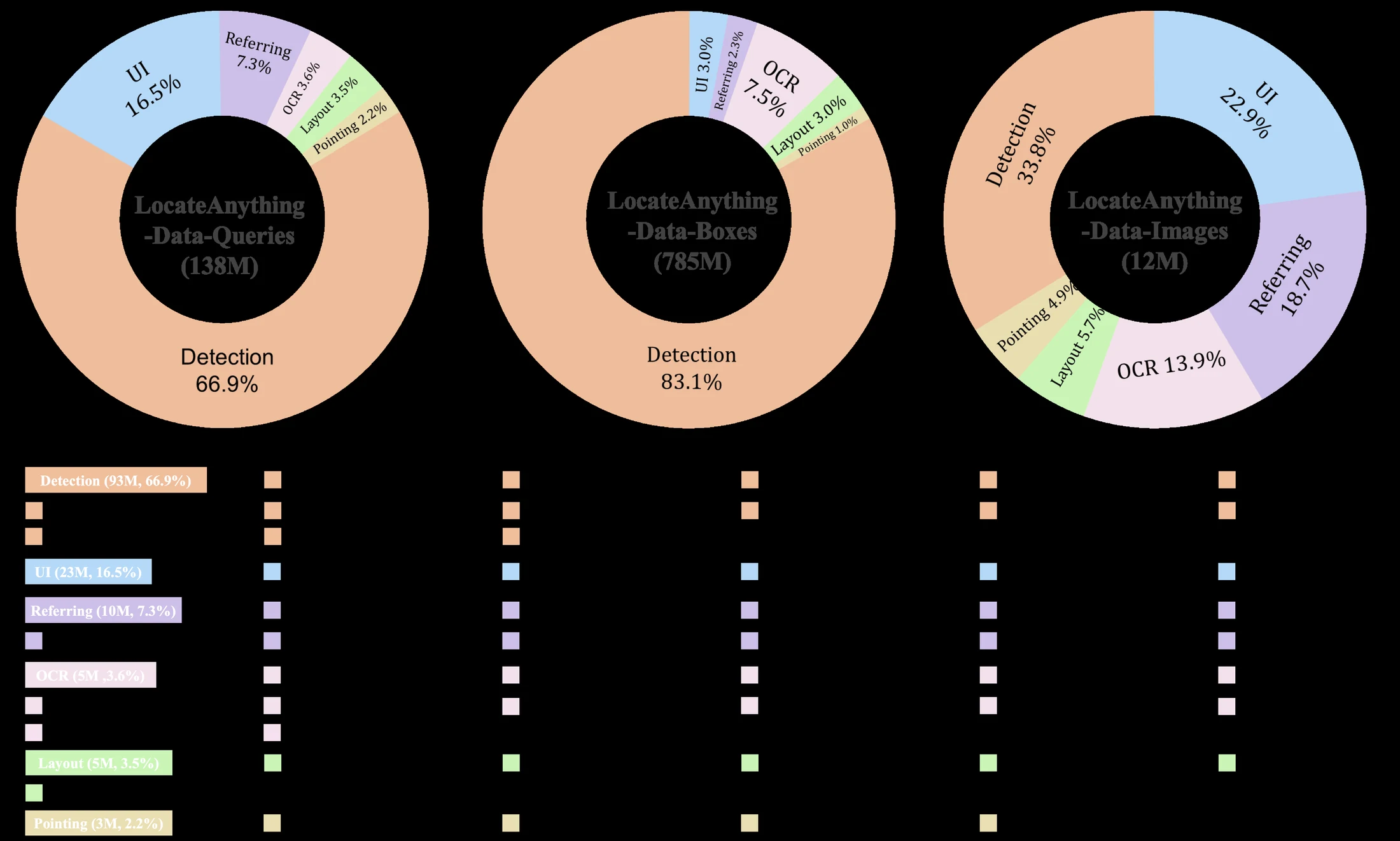
공개된 query 비중은 다음과 같다.
| 영역 | query 비중 | 해석 |
|---|---|---|
| General Object Detection | 66.9% | 대부분의 박스 supervision을 담당하는 기본 축 |
| GUI Element Grounding | 16.5% | embodied/GUI agent용 화면 요소 grounding |
| Referring Comprehension | 7.3% | 자연어 지시와 특정 영역 연결 |
| Text Localization / OCR | 3.6% | 글자·텍스트 영역 위치 추정 |
| Layout Grounding | 3.5% | 문서·장면 layout 구조 grounding |
| Point-Based Localization | 2.2% | 박스가 아니라 점 좌표를 직접 요구하는 task |
여기서 흥미로운 점은 데이터 엔진이 단순히 box label을 많이 모은 것이 아니라, “자연어 query가 어떤 target set을 요구하는가”를 다양화하려 한다는 점이다. detection query, GUI instruction, referring phrase, OCR text, document layout category, pointing prompt가 같은 localization interface로 묶인다.
따라서 LocateAnything는 detector라기보다, 다양한 perception task를 하나의 VLM localization grammar로 통합하려는 시도에 가깝다.
공개된 근거에서 확인되는 점
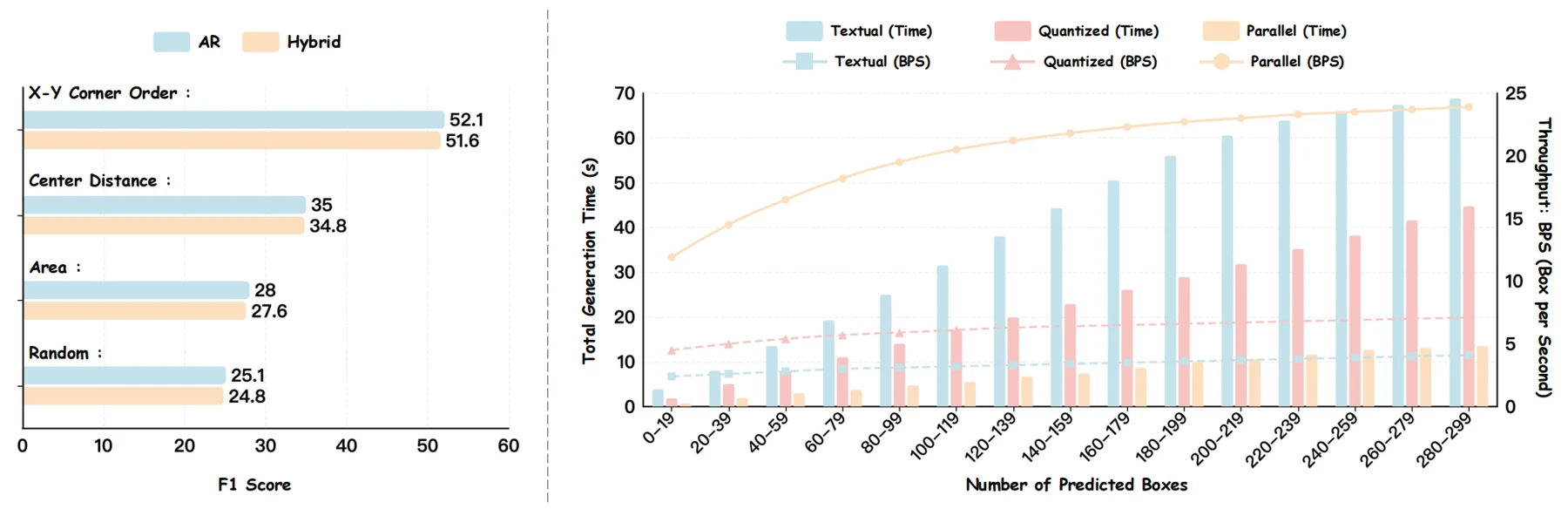
논문과 document/RESULTS.md가 가장 강하게 내세우는 수치는 throughput과 high-IoU 품질이다.
주요 table에서 BPS는 Boxes Per Second를 의미한다.
README의 headline 기준 LocateAnything-3B는 single H100에서 12.7 BPS를 보고하며, Qwen3-VL의 1.1 BPS 대비 약 10배, Rex-Omni의 5.0 BPS 대비 약 2.5배 빠르다고 제시한다.
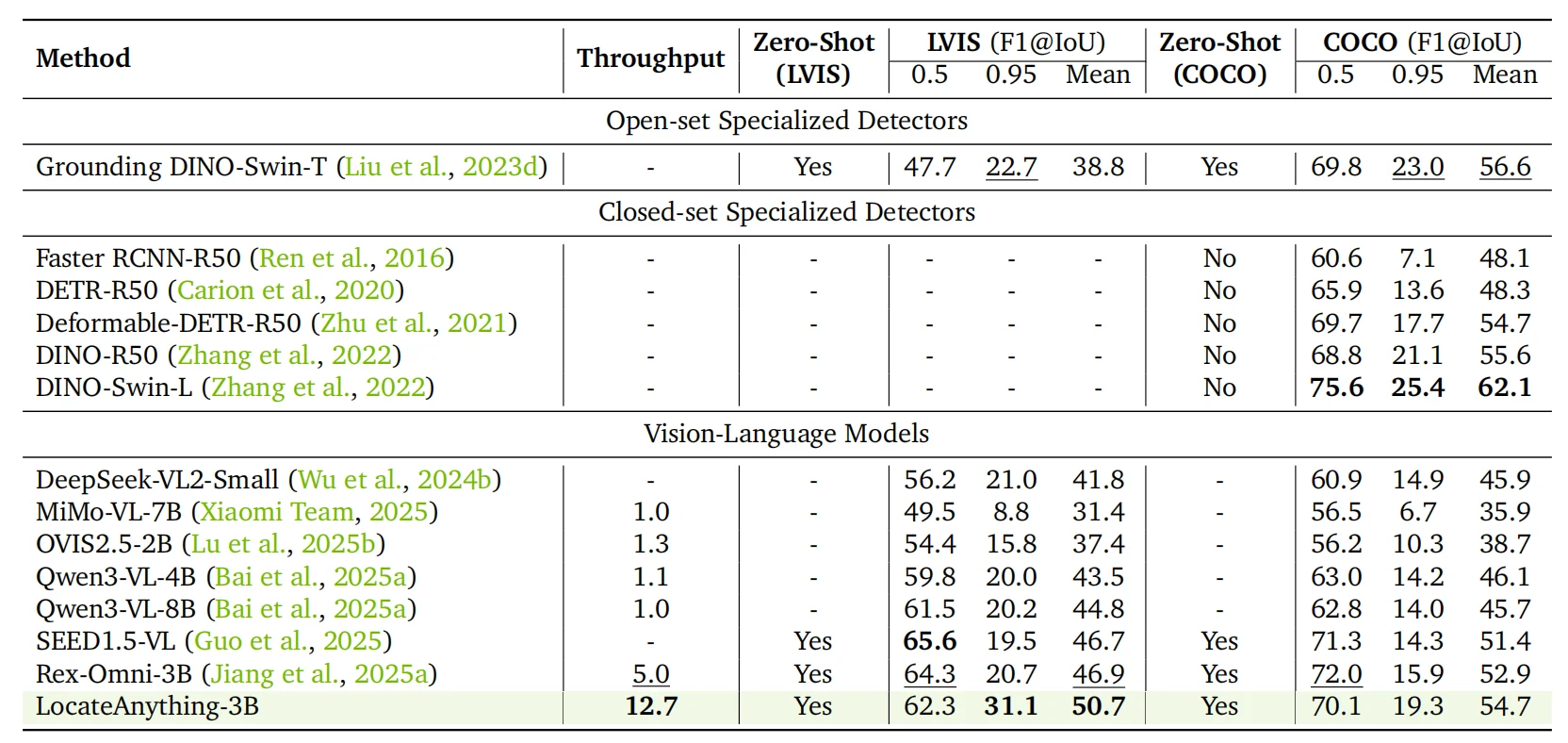
| 공개 근거 | LocateAnything-3B 수치 | 읽는 법 |
|---|---|---|
| Throughput on H100 | 12.7 BPS | Hybrid setting의 headline throughput |
| LVIS F1@Mean | 50.7 | Rex-Omni 46.9 대비 +3.8 |
| LVIS F1@0.95 | 31.1 | Rex-Omni 20.7 대비 high-IoU 개선 폭이 큼 |
| COCO F1@Mean | 54.7 | Rex-Omni 52.9 대비 +1.8 |
| Dense200 F1@Mean | 58.7 | dense detection에서도 Rex-Omni 58.3보다 소폭 높음 |
| DocLayNet F1@Mean | 76.8 | Rex-Omni 70.7 대비 +6.1 |
| M6Doc F1@Mean | 70.1 | Rex-Omni 55.6 대비 +14.5 |
| ScreenSpot-Pro Avg | 60.3 | GUI-Owl-32B 58.0보다 높은 평균 |
| HumanRef F1@0.95 | 68.8 | referring comprehension의 고정밀 영역에서 강점 |
| Pointing | 7개 benchmark 모두 최고 | point-based localization에서도 일반화 주장 |
Ablation도 핵심 메시지를 강화한다.
COCO 기준 coordinate representation 비교에서 textual decoding은 1.3 BPS, quantized decoding은 3.9 BPS, PBD fast는 16.9 BPS, PBD hybrid는 13.2 BPS로 제시된다.
같은 표에서 hybrid는 fast보다 느리지만 F1을 더 끌어올리고, slow보다 훨씬 빠르다.
즉 PBD의 포지션은 “항상 가장 정확한 모드”라기보다, 느린 autoregressive decoding과 불안정한 순수 병렬 decoding 사이에서 speed-quality trade-off를 재설계하는 방법에 가깝다.
Release 관점에서는 몇 가지 제약도 분명하다.
Hugging Face 모델은 image-text-to-text, transformers, custom_code, safetensors로 공개되어 있고, API 기준 작성 시점에 downloads 1,755, likes 239, gated false로 확인된다. repo에는 training, data preparation, evaluation 문서가 있지만, Git tag는 아직 보이지 않았고 모델 card는 연구·개발용이라고 명시한다.
코드 badge는 Apache-2.0을 가리키지만 모델 weight는 NVIDIA License의 non-commercial use limitation을 따른다.
또한 training docs는 Magi Attention을 권장하며 Hopper/Blackwell GPU에서 16K–32K+ long-context training이 현실적이라고 설명한다.
연구 재현이나 fine-tuning을 고려한다면 이 hardware boundary도 가볍게 넘길 수 없는 제약이다.
실무 관점에서의 해석
LocateAnything의 실무적 의미는 “좌표도 언어 토큰처럼 생성하면 된다”는 초기 VLM grounding 접근을 한 번 조정한다는 데 있다.
자연어 query를 받아 <ref>...<box>...</box> 형태로 답하는 interface는 유연하지만, 좌표는 자연어 문장과 다르게 강한 구조를 가진다.
PBD는 이 구조를 모델 출력 단위에 직접 반영한다.
그래서 속도만이 아니라 high-IoU에서의 gain이 같이 나온다는 점이 중요하다.
두 번째 의미는 GUI agent와 document AI 쪽이다.
GUI grounding에서는 버튼이나 아이콘을 정확히 찍어야 하고, OCR·layout에서는 작은 영역을 tight box로 잡아야 한다.
ScreenSpot-Pro, DocLayNet, M6Doc, TotalText에서의 성능 주장은 LocateAnything가 단순 open-vocabulary detection보다 “agent가 실제로 사용할 수 있는 localization primitive”에 가깝게 설계되었음을 보여준다.
특히 ScreenSpot-Pro 평균 60.3과 icon query에서의 강점은 GUI automation 계층에 직접 연결되는 신호다.
세 번째는 통합 모델 전략이다. object detection, dense detection, OCR, layout, referring expression, pointing을 모두 별도 specialist 모델로 운영할 수도 있다.
하지만 multimodal agent system에서는 이런 모델들을 매번 router로 묶는 비용이 생긴다.
LocateAnything는 “localization을 하나의 VLM grammar로 통합하고, decoding만 구조화하자”는 방향을 제시한다.
이 접근이 충분히 안정적이면, agent stack 입장에서는 detection API, OCR box API, GUI click API를 따로 부르는 대신 하나의 grounding model을 더 넓게 쓸 수 있다.
다만 과장해서 읽으면 안 되는 부분도 있다.
첫째, 공개된 성능은 특정 benchmark와 evaluation harness에서의 수치이며, 실제 로봇·GUI·문서 workflow에서는 image resolution, prompt design, post-processing, safety policy가 함께 작동한다.
둘째, LocateAnything-Data의 전체 구성과 학습 재현성은 아직 완전한 dataset release와는 거리가 있다.
셋째, custom code와 non-commercial model license는 제품 배포 관점에서 명확한 제약이다.
따라서 지금 단계의 LocateAnything는 production-ready 범용 detector라기보다, VLM localization에서 decoding unit을 어떻게 바꿔야 하는지 보여주는 강한 연구·개발용 release로 보는 편이 맞다.
결국 이 논문의 핵심 메시지는 단순하다.
박스는 네 개의 독립 좌표 토큰이 아니라 하나의 기하 객체다.
LocateAnything는 그 사실을 모델의 출력 문법, 학습 mask, 추론 fallback, 데이터 설계까지 밀어 넣는다.
VLM이 점점 더 많은 시각 행동을 맡게 될수록, 이런 “출력 구조 자체를 task object에 맞추는 설계”가 더 중요해질 가능성이 크다.