LLM 환각 탐지는 실무에서 꽤 불편한 문제다.
답변이 나온 뒤 외부 검색이나 NLI 모델로 검증하면 더 안전해질 수 있지만, 비용과 지연이 커진다.
여러 번 샘플링해 semantic entropy나 consistency를 재면 신호는 강해지지만, API 비용과 throughput이 바로 부담이 된다.
반대로 perplexity나 length-normalized entropy처럼 한 번의 생성에서 얻는 값은 싸고 빠르지만, 전체 entropy trace를 하나의 평균값으로 눌러 버린다는 한계가 있다.
Entropy Distribution as a Fingerprint for Hallucinations in Generative Models는 이 중간 지점을 겨냥한다.
논문의 핵심 가설은 단순하다.
모델이 환각할 때는 토큰별 엔트로피 평균만 올라가는 것이 아니라, 엔트로피 분포의 모양과 꼬리가 faithful generation과 달라진다.
저자들은 이를 환각의 fingerprint로 보고, token-level entropy sequence를 기준 분포와 비교하는 **Calibrated Entropy Score(CES)**를 제안한다.
이 작업의 포인트는 “LLM이 불확실하면 환각한다”는 익숙한 직관을 조금 더 통계적인 형태로 바꾼 데 있다.
CES는 생성 1회에서 나온 token logit 또는 top-k logprob만 사용하고, 추가 LLM query나 hidden-state 접근을 요구하지 않는다.
그래서 제품 관점에서는 완전한 사실 검증기라기보다, 답변이 나온 직후 낮은 비용으로 위험도를 매기는 runtime triage score에 가깝다.
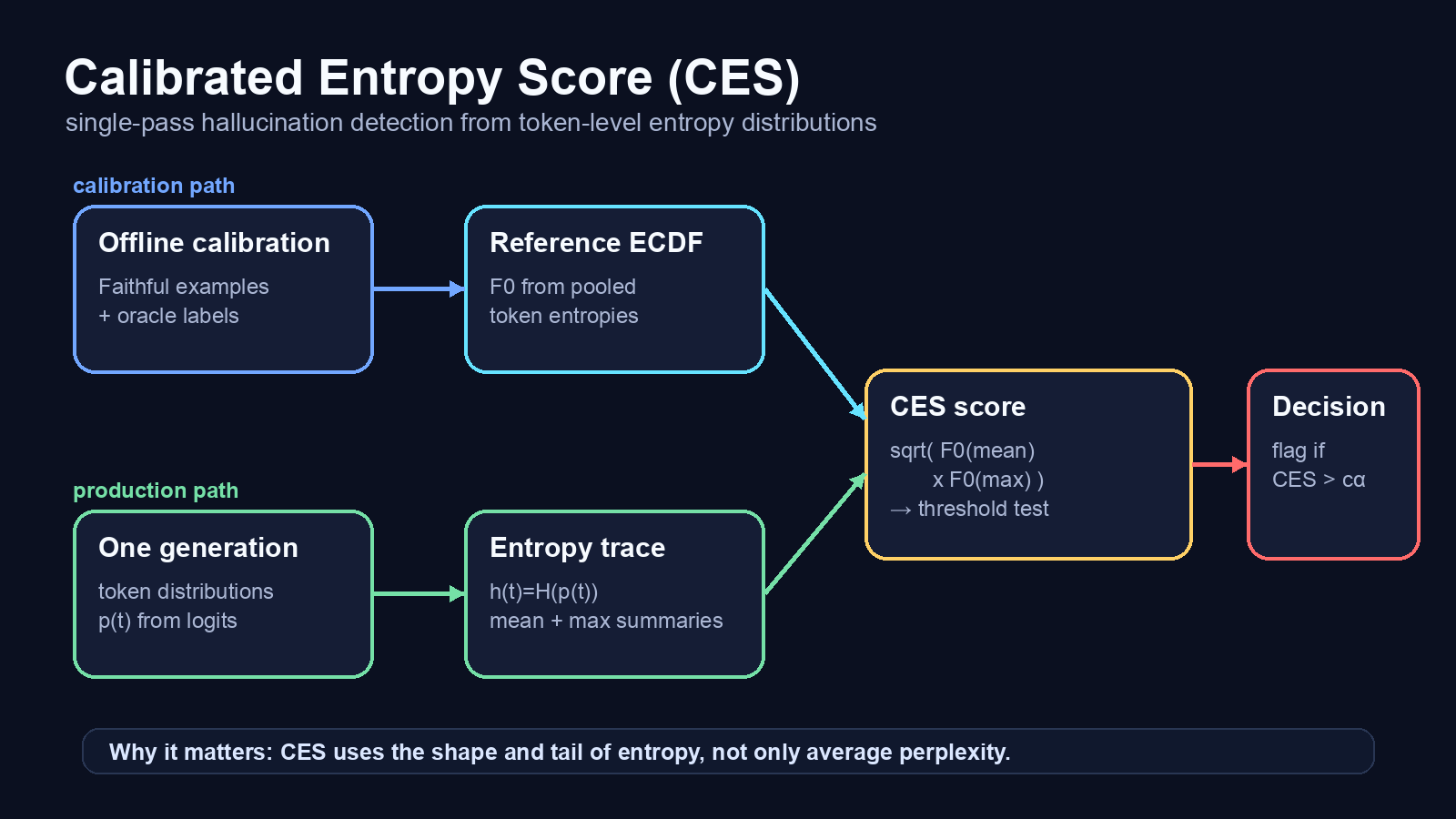
논문의 Figure 1을 바탕으로 재구성한 CES 흐름. calibration set으로 faithful entropy reference ECDF를 만들고, production generation에서는 mean·max entropy를 그 reference에 매핑해 threshold test를 수행한다.
무엇을 해결하려는가
기존 환각 탐지 방법은 크게 세 부류로 나뉜다.
첫째는 perplexity, generation length, length-normalized entropy처럼 단일 생성의 trace를 쓰는 방법이다.
이들은 빠르지만 signal을 너무 거칠게 요약한다.
둘째는 Semantic Entropy, SelfCheckGPT, Kernel Language Entropy(KLE)처럼 여러 번 생성한 뒤 의미적 일관성을 비교하는 방법이다.
성능은 강할 수 있지만 보통 5회 이상 forward pass 또는 외부 NLI/embedding 모델이 필요하다.
셋째는 P(True), self-evaluation, FAVA류처럼 모델이나 보조 모델에게 직접 판단을 묻는 elicitation 방식이다.
CES가 묻는 질문은 다르다.
“단일 생성에서 이미 logit/logprob trace를 얻을 수 있다면, 그 안의 분포 구조를 더 잘 쓰면 되지 않을까?”
평균 entropy는 위치 신호만 본다.
하지만 hallucinated output은 특정 구간에서 tail anomaly를 만들거나, 평균을 맞춘 뒤에도 CDF 모양이 달라질 수 있다.
논문은 이 shape signal이 실제로 존재하는지 먼저 검정하고, 그 다음 이를 점수화한다.
이 접근은 특히 hosted API와 production inference에서 매력적이다.
모든 모델이 hidden state를 주지는 않고, 모든 서비스가 여러 번 재생성할 여유를 갖지도 않는다.
하지만 일부 API는 token logprob를 제공하고, open-weight serving stack은 logit을 이미 가지고 있다.
CES는 그 최소 접근권에서 환각 위험 신호를 뽑으려는 시도다.
핵심 아이디어 / 구조 / 동작 방식
CES의 출발점은 각 생성 step의 next-token distribution이다.
모델이 시점 t에서 vocabulary 위의 확률분포 p(t)를 내면, token entropy는 h(t)=H(p(t))로 계산된다.
하나의 답변은 h(1), ..., h(m)이라는 entropy sequence가 된다.
그 다음 calibration 단계에서 faithful generation만 모아 reference empirical CDF, 즉 F0를 만든다.
이때 hallucination 여부의 정의는 별도 oracle에 맡긴다. oracle은 사람이 될 수도 있고, GPT-4.1-nano 같은 LLM judge가 될 수도 있다.
중요한 점은 calibration 때만 oracle label을 쓰고, production detection에서는 새 답변의 entropy trace만 본다는 것이다.
새 generation이 들어오면 CES는 두 가지 요약값을 사용한다.
mean entropy: 답변 전체의 평균적 불확실성max entropy: 답변 중 가장 불확실한 tail 구간
두 값은 reference CDF F0에 통과되어 “faithful reference 안에서 얼마나 높은 위치에 있는가”로 바뀐다.
논문의 CES는 이 mean signal과 max signal을 geometric mean으로 결합한다.
즉 평균적인 분포 shift와 순간적인 tail anomaly를 동시에 반영하려는 설계다.
| 구성 요소 | CES에서 하는 일 | 실무적 의미 |
|---|---|---|
| Token entropy trace | 생성 중 각 token step의 불확실성을 기록 | 별도 judge 호출 없이 inference trace를 활용 |
Reference ECDF F0 |
faithful calibration entropy 분포를 추정 | 모델·태스크별 기준선을 만든 뒤 비교 가능 |
| Mean entropy signal | 전체 답변의 평균적 불확실성 측정 | perplexity/LN entropy가 보던 위치 신호를 유지 |
| Max entropy signal | 답변 내부 tail anomaly 포착 | 짧은 고위험 구간을 평균에 묻히지 않게 함 |
| Geometric aggregation | mean과 max를 결합해 CES 계산 | 위치 shift와 꼬리 신호를 한 점수로 합침 |
| Threshold test | CES > cα이면 환각 위험으로 flag |
runtime triage나 human review routing에 연결 가능 |
논문은 이 절차를 단순 heuristic으로만 두지 않는다. varying-length entropy sequence를 pooling해 reference CDF를 만들 때의 finite-sample calibration을 random-length Dvoretzky-Kiefer-Wolfowitz(DKW) inequality로 다루고, generation length가 길어질수록 CES test의 Type I/II error가 지수적으로 감소한다는 power 분석도 제시한다.
물론 이 보장은 conditional i.i.d.
가정 위에 있다.
실제 autoregressive token은 완전히 독립이 아니기 때문에, 논문은 appendix에서 lag-1 autocorrelation을 따로 점검한다.
공개된 근거에서 확인되는 점
저자들은 8개 QA benchmark와 10개 generator model 조합을 중심으로 80개 model-dataset experiment를 만든다.
데이터셋은 BioASQ, CoQA, DROP, GSM8K, NQ-Open, SQuAD, SVAMP, TriviaQA이고, 모델은 Falcon-7B-Instruct, Llama-3.2-1B-Instruct, Llama-2-7B/13B-Chat, Meta-Llama-3-8B-Instruct, Mistral-7B-Instruct-v0.3, GPT-4.1 계열과 GPT-4o-mini를 포함한다. binary hallucination label은 GPT-4.1-nano judge로 붙였고, 평가는 AUROC를 중심으로 진행된다.
먼저 entropy distribution 자체가 구분 신호인지 확인한 결과가 중요하다.
80개 실험 중 72개, 즉 90%에서 hallucinated generation과 faithful generation의 token entropy 분포가 two-sample KS test 기준 α=0.05에서 유의하게 달랐다. median KS distance는 0.100, median Cohen’s d는 0.192로 크지 않지만 통계적으로 일관된 shift다.
더 중요한 것은 평균을 제거한 mean-centered entropy에서도 80/80 실험이 유의했다는 점이다.
즉 평균 entropy 하나만으로는 설명되지 않는 shape signal이 남아 있다는 주장이다.
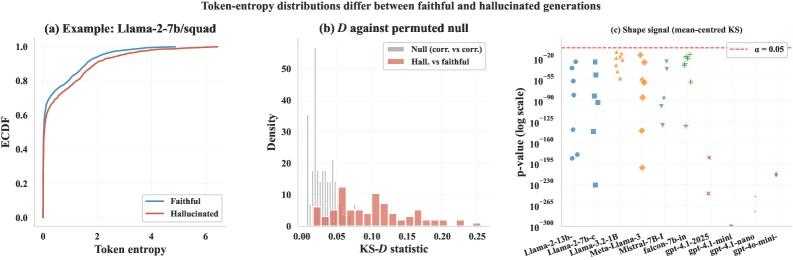
논문 Figure 2. faithful/hallucinated entropy ECDF 차이, 80개 실험의 KS distance 분포, mean-centered shape signal을 함께 보여 준다.
성능 비교에서는 CES가 “가장 강한 전체 방법”이라기보다 “가장 실용적인 single-pass tier”에 가깝게 나온다.
논문은 16개 benchmark method와 비교했고, CES unsupervised는 전체 pairwise comparison 1279개 중 854개를 이겨 66.8% win rate를 보였다.
평균 rank는 6.29로, KLE heat/KLE 계열과 함께 top statistical clique에 들어간다.
Appendix E.2의 요약에 따르면 CES median AUROC는 0.653, IQR은 대략 0.6170.700이며, Embedding Regression 0.665와 KLE variants 0.6470.651에 근접한다.
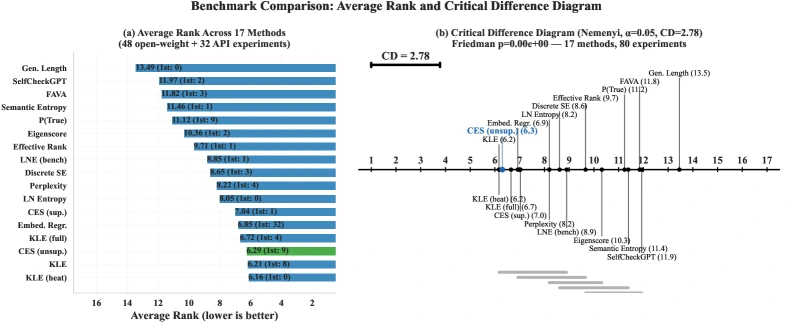
논문 Figure 3.
CES는 여러 multi-sample method와 통계적으로 구분되지 않는 상위 clique에 들어가지만, 단일 generation entropy trace만 사용한다는 점에서 비용 구조가 다르다.
다만 숫자는 과장 없이 읽어야 한다.
CES가 LN Entropy/Perplexity보다 일관되게 나은 것은 맞지만, median AUROC 차이는 작다.
논문도 CES median 0.653, LN Entropy/Perplexity 0.652로 보고한다.
CES의 강점은 “평균값 heuristic을 압도적으로 이겼다”보다는, 비슷한 비용 수준에서 평균과 tail을 함께 쓰고, 통계적 calibration framework와 robustness 분석을 붙였다는 데 있다.
실무적으로 더 흥미로운 부분은 robustness다. calibration reference에 hallucinated token을 50%까지 섞어도 CES median AUROC는 0.6531에서 0.6533으로 사실상 변하지 않았다고 보고된다. label noise 실험에서도 50% flip까지 성능이 거의 평평하게 유지된다.
이는 supervised reference가 완벽하지 않아도 unsupervised pooled reference와 비슷하게 동작한다는 의미다.
실제 운영에서는 LLM judge label이나 human label이 완벽하지 않기 때문에 이 결과가 꽤 중요하다.
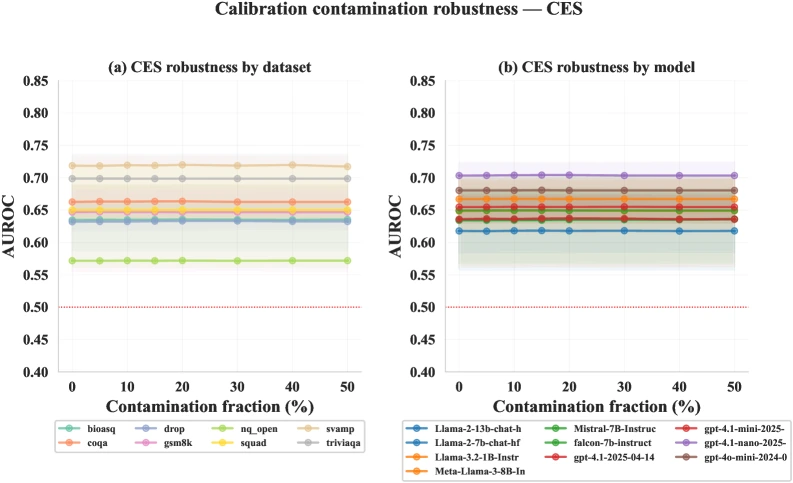
논문 Figure 10. calibration reference에 hallucinated token contamination을 넣어도 CES AUROC가 거의 변하지 않는다는 robustness 실험.
API model generalization도 확인된다.
GPT-4.1 계열과 GPT-4o-mini 같은 API-only 모델에서는 full logit vector가 아니라 token-level logprob 기반 entropy를 사용한다.
그럼에도 CES median AUROC는 API 모델 0.669, open-weight 모델 0.642로 보고된다.
저자들은 API 모델의 hallucination rate가 더 낮고 dataset별 방향이 엇갈린다는 caveat를 붙이지만, 적어도 top-k logprob만으로도 distributional signal을 만들 수 있다는 점은 production deployment 관점에서 의미가 있다.
마지막으로 이 논문은 공개 artifact 관점에서는 paper 중심이다. arXiv abstract/html에서 별도 공식 GitHub, Hugging Face model/dataset, project page 링크는 확인되지 않았고, 제목·CES 키워드 기반 GitHub/Hugging Face 검색에서도 명확한 공식 companion artifact는 찾지 못했다.
따라서 현재 기준으로는 runnable detector package나 공개 benchmark release를 검토하는 글이 아니라, arXiv HTML/PDF에 제시된 방법·실험·그림에 근거한 논문 리뷰로 보는 편이 맞다.
실무 관점에서의 해석
내가 보기에 CES의 가장 좋은 사용처는 “환각을 최종 판정하는 판사”가 아니라, 생성 직후 위험도를 낮은 비용으로 스코어링하는 early warning layer다.
예를 들어 고객 응대, 의료·법률 보조, 내부 지식 검색 답변처럼 human review나 retrieval verification을 모든 답변에 붙이기 부담스러운 환경에서, CES가 높은 답변만 추가 검증 queue로 보내는 식의 triage가 가능하다.
또 하나의 장점은 calibration의 언어가 명확하다는 점이다.
단순히 “entropy가 높으면 위험하다”가 아니라, 특정 모델·태스크·디코딩 설정에서 faithful generation의 entropy reference를 만들고, 새 답변이 그 reference의 어느 위치에 있는지 본다.
이 구조는 모델별 threshold가 흔들리는 문제를 줄이고, 서비스별 calibration set을 만들 수 있게 한다.
하지만 한계도 뚜렷하다.
첫째, CES는 사실 검증기가 아니다.
모델이 훈련 데이터의 잘못된 사실을 낮은 entropy로 자신 있게 말하면 entropy trace만으로는 잡기 어렵다.
논문도 F0와 F1의 KS distance가 0이면 어떤 test도 power를 갖기 어렵다고 적는다.
둘째, 짧은 답변에서는 분포 검정에 쓸 token 수가 적다.
Appendix E.12의 synthetic 길이 실험은 100 token 이상에서 error가 크게 줄어드는 방향을 보이지만, factoid QA처럼 10 token 안팎인 경우에는 오류율이 여전히 높을 수 있다.
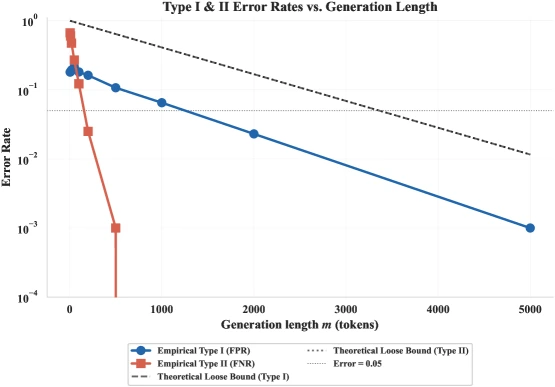
논문 Figure 17. i.i.d.
가정 아래 synthetic entropy sequence 길이가 길어질수록 Type I/II error가 지수적으로 감소하는 경향을 검증한다.
셋째, 이 실험은 in-sample ranking 성격이 강하다.
논문은 각 experiment의 전체 샘플을 reference ECDF 구성과 AUROC 계산에 함께 사용한다고 명시한다.
따라서 숫자를 production generalization 성능으로 바로 옮기기보다는, distributional signal이 있는지와 method ranking이 어떤지를 보는 근거로 읽어야 한다.
실제 배포에서는 calibration set, hold-out validation, drift monitoring, judge quality를 별도로 설계해야 한다.
넷째, API 접근성도 제약이다.
CES는 hidden state를 요구하지 않지만 token logit 또는 top-k logprob는 필요하다.
모든 provider가 안정적인 logprob를 제공하지 않고, streaming·tool-use·structured output 환경에서는 token trace 수집이 까다로울 수 있다.
또 모델이나 prompt가 바뀌면 reference ECDF도 다시 맞춰야 한다.
그럼에도 이 논문이 던지는 방향은 중요하다.
환각 탐지는 “더 큰 verifier를 붙인다”는 방향만으로는 운영 비용을 감당하기 어렵다.
반대로 평균 perplexity 하나로 모든 것을 판단하기에도 신호가 너무 얇다.
CES는 그 사이에서 이미 inference 중에 얻는 token uncertainty를 더 구조적으로 읽는 방법을 보여 준다.
실제 시스템에서는 retrieval grounding, citation check, policy filter, human review와 함께 쓰일 때 가장 설득력 있는 안전 계층이 될 가능성이 크다.