LLM 에이전트는 이제 단일 프롬프트나 모델 호출만으로 동작하지 않는다.
실제 운영형 에이전트는 시스템 프롬프트, 스킬 문서, 메모리, 도구 스키마, 실행 정책 같은 외부 레이어를 함께 읽고 실행한다.
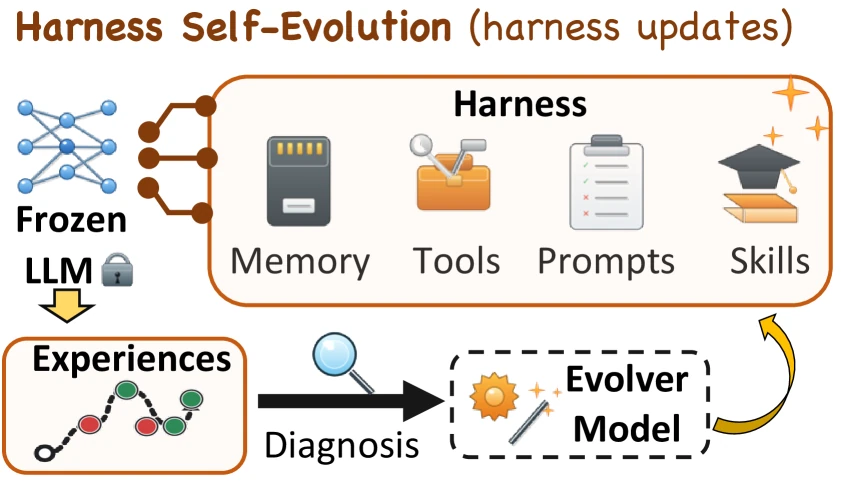
논문은 이 외부 레이어를 harness라고 부른다.
중요한 점은 harness가 모델 가중치를 바꾸지 않고도 에이전트의 행동을 크게 바꿀 수 있다는 것이다.
Harness Updating Is Not Harness Benefit은 이 지점을 한 단계 더 쪼갠다.
자기진화 에이전트가 과거 실행 증거를 보고 harness를 업데이트했을 때, 성능이 좋아졌다면 그것은 누가 잘한 결과인가.
업데이트를 쓴 evolver 모델이 좋은 것인가, 아니면 업데이트를 읽고 실제 작업에 적용한 task-solving agent가 좋은 것인가.
논문은 이 둘을 분리하지 않으면 self-evolving agent의 병목을 잘못 진단하게 된다고 주장한다.
공개 자료 기준으로 이 연구는 arXiv 논문과 함께 A-EVO-Lab/a-evolve 저장소의 release/harness-evolution 브랜치에 실험 코드와 재현 스크립트를 제공한다.
따라서 단순한 개념 제안이 아니라, SWE-bench Verified, MCP-Atlas, SkillsBench라는 세 agentic benchmark에서 harness 업데이트와 활용 능력을 분리 측정한 실험 보고서에 가깝다.
무엇을 해결하려는가
자기진화 에이전트를 평가할 때 흔히 보는 숫자는 “업데이트 후 성능이 얼마나 올랐는가”다.
하지만 이 숫자는 두 능력을 섞어 버린다.
첫째, 실행 로그와 실패 사례를 보고 더 나은 스킬·프롬프트·메모리를 작성하는 능력이다.
둘째, 다음 실행에서 그 업데이트를 찾아 읽고, 긴 trajectory 동안 지시를 지키며 실제 문제를 푸는 능력이다.
이 둘은 실무적으로 완전히 다른 병목이다.
업데이트 작성이 어렵다면 더 강한 모델을 evolver로 쓰거나, 더 좋은 reflection prompt와 평가 데이터를 써야 한다.
반대로 업데이트 활용이 어렵다면 task-solving agent가 적절한 스킬을 로드하도록 훈련하거나, context routing과 instruction-following을 고쳐야 한다.
같은 “self-evolution”이라는 이름 아래 있어도 투자해야 할 위치가 달라진다.
논문이 던지는 질문은 그래서 명확하다.
강한 모델일수록 더 좋은 harness update를 쓰는가?
그리고 강한 모델일수록 업데이트된 harness에서 더 큰 이득을 얻는가?
결과는 둘 다 단순하지 않다.
특히 두 번째 질문의 답은 “모델이 강할수록 항상 좋다”가 아니라, 약한 모델과 강한 모델 양쪽에서 서로 다른 이유로 이득이 작아지는 비단조 패턴이다.
핵심 아이디어 / 구조 / 동작 방식
논문은 에이전트를 A_t = (f, H_t)로 본다.
여기서 f는 고정된 모델 백본이고, H_t는 시점 t의 외부 harness 상태다.
업데이트는 모델 가중치가 아니라 H_t에만 일어난다.
즉 fine-tuning이나 RL이 아니라, prompt, skill, memory 같은 실행 주변부를 바꾸는 적응이다.
이를 위해 두 능력을 따로 정의한다.
| 구분 | 고정하는 것 | 바꾸는 것 | 묻는 질문 |
|---|---|---|---|
| Harness-updating | task-solving agent | evolver model | 누가 더 유용한 persistent harness update를 쓰는가 |
| Harness-benefit | evolver set | task-solving agent | 누가 업데이트된 harness를 실제 작업에서 더 잘 활용하는가 |
Δ_update는 evolver가 쓴 업데이트가 여러 고정 agent에서 평균적으로 얼마나 이득을 주는지 본다.
반대로 Δ_benefit은 특정 task-solving model이 여러 anchor evolver가 만든 업데이트 중에서 얼마나 이득을 얻는지 본다.
이 설계 덕분에 “업데이트를 만드는 능력”과 “업데이트를 쓰는 능력”이 서로 다른 곡선을 갖는다는 점을 관찰할 수 있다.
공개된 근거에서 확인되는 점
실험은 세 benchmark를 사용한다.
SWE-bench Verified는 코드 수정 작업 500개, MCP-Atlas는 36개 MCP server와 220개 tool을 쓰는 500개 과제, SkillsBench는 11개 task domain의 86개 과제를 포함한다.
모델은 Claude Opus 4.6, Sonnet 4.6, Haiku 4.5, Qwen3-235B, Qwen3-32B, GPT-OSS-120B를 task-solving agent와 evolver로 쓰고, Qwen3.5-9B는 추가 evolver로 넣는다.
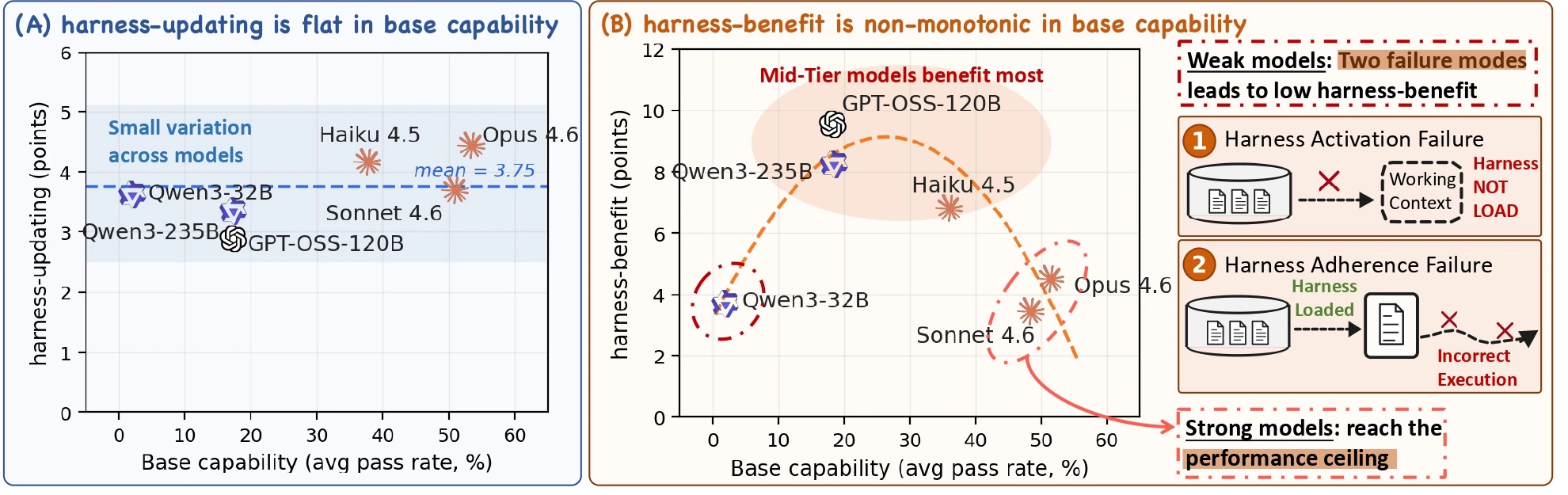
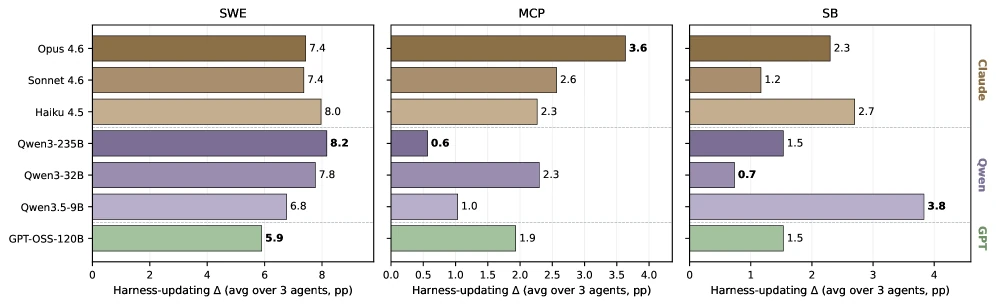
첫 번째 결론은 harness-updating 능력이 base capability에 대해 꽤 평평하다는 것이다. evolver를 바꿔도 Δ_update의 best-worst gap은 어떤 benchmark에서도 최대 3.1 percentage point에 그친다.
더 강한 모델이 항상 이기지도 않는다.
Qwen3-235B는 SWE에서 8.2pp로 가장 높지만 MCP에서는 0.6pp로 가장 낮고, 가장 작은 Qwen3.5-9B는 SkillsBench에서 3.8pp로 가장 높은 업데이트 이득을 만든다.
두 번째 결론은 post-evolution 성능의 대부분이 evolver가 아니라 task-solving agent의 base capability에 의해 결정된다는 것이다.
MCP-Atlas에서 같은 agent 안에서 evolver 7개를 바꿨을 때의 spread는 최대 5.1pp 수준이지만, Opus 4.6과 Qwen3-235B의 base capability gap은 36.0pp다.
더 극단적으로, 약한 anchor agent에 가장 좋은 evolver를 붙이고 강한 anchor agent에 가장 나쁜 evolver를 붙여도 강한 agent가 SWE 35.2pp, MCP 32.3pp, SkillsBench 18.6pp 앞선다.
세 번째 결론은 harness-benefit이 base capability에 대해 비단조적이라는 것이다.
강한 모델은 이미 초기 harness만으로 많은 문제를 풀기 때문에 ceiling effect가 생긴다.
반대로 약한 모델은 headroom이 있어도 필요한 harness를 로드하지 못하거나, 로드한 뒤에도 절차를 끝까지 따르지 못해 이득이 제한된다.
| Benchmark | Δ_benefit이 가장 큰 모델 |
Base pass rate | Δ_benefit |
해석 |
|---|---|---|---|---|
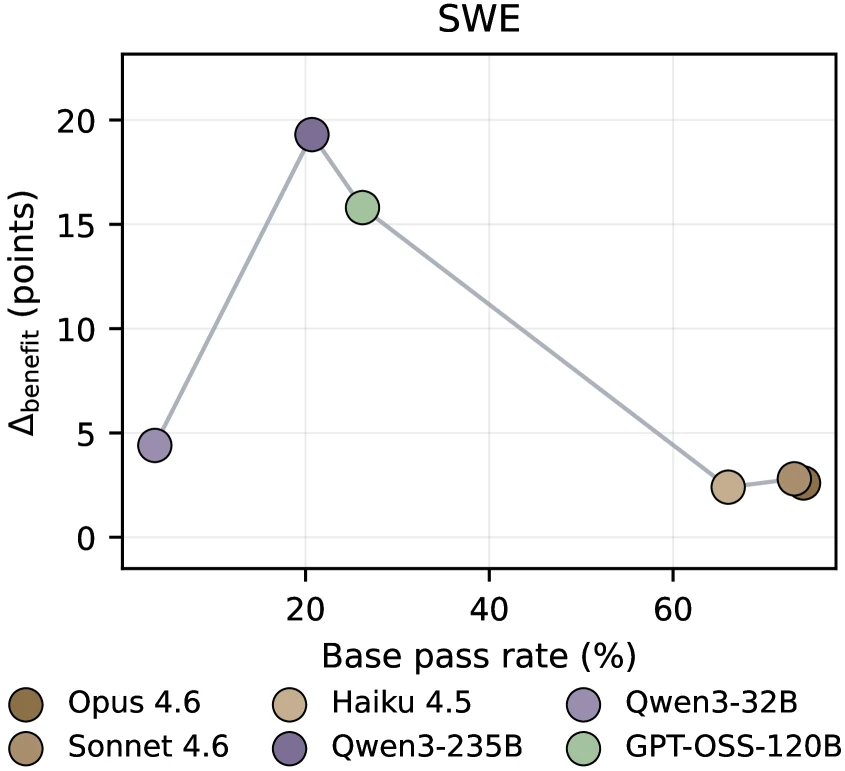
| SWE-bench Verified | Qwen3-235B | 20.7% | +19.3pp | 중간 성능 구간에서 업데이트 이득이 가장 큼 |
| MCP-Atlas | GPT-OSS-120B | 28.0% | +7.0pp | 약한 Qwen3-32B보다 중간급 모델이 더 잘 활용 |
| SkillsBench | Haiku 4.5 | 5.8% | +15.1pp | 기본 점수는 낮아도 skill load/adherence가 상대적으로 좋아 큰 이득 |
약한 모델의 병목은 SkillsBench 분석에서 더 잘 드러난다.
논문은 skill-load rate(SLR), harness-following rate(HFR), skill-loaded trajectory에서의 pass rate(LPR)를 분리한다.
| Model | SLR | HFR | LPR |
|---|---|---|---|
| Qwen3-32B | 0.251 | 0.142 | 0.023 |
| GPT-OSS-120B | 0.446 | 0.442 | 0.040 |
| Haiku 4.5 | 0.794 | 0.600 | 0.099 |
| Qwen3-235B | 0.961 | 0.350 | 0.022 |
| Sonnet 4.6 | 0.959 | 0.730 | 0.145 |
| Opus 4.6 | 0.957 | 0.757 | 0.177 |
이 표에서 흥미로운 점은 activation과 adherence가 다르다는 것이다.
Qwen3-235B는 skill-load rate가 0.961로 Opus 4.6과 거의 같지만, HFR은 0.350에 그친다.
즉 harness를 context에 넣는 것과, 그 내용을 작업 절차로 끝까지 따르는 것은 별개의 능력이다.
Qwen3-32B는 둘 다 약하다. skill을 불러오는 비율도 0.251로 낮고, 불러온 뒤 따르는 비율도 0.142에 머문다.
논문은 이 adherence 문제가 긴 실행에서 더 심해진다고 본다.
대표 모델 세 개를 보면 Qwen3-32B는 harness를 로드한 직후 0.52였던 adherence score가 final turn에서 0.13으로 떨어진다.
Opus 4.6은 같은 구간에서 0.89에서 0.80으로 비교적 안정적이다.
| Trajectory phase | Qwen3-32B | GPT-OSS-120B | Opus 4.6 |
|---|---|---|---|
| Harness loaded | 0.52 | 0.67 | 0.89 |
| Mid turn | 0.22 | 0.48 | 0.79 |
| Final turn | 0.13 | 0.43 | 0.80 |
| Drift, load → final | -0.39 | -0.24 | -0.09 |
공개 구현 상태도 실무적으로 볼 만하다.
GitHub API 조회 시점 기준 A-EVO-Lab/a-evolve는 2026년 2월 20일 생성, release/harness-evolution 브랜치는 2026년 6월 2일 마지막 커밋으로 Qwen3.5-9B evolver 목록을 반영했다. stars 573, forks 73, open issues 4로 확인됐다.
루트 LICENSE 파일은 보이지 않았고 GitHub API의 license 필드는 null이지만, pyproject.toml은 license = "MIT"와 MIT classifier를 명시한다. latest GitHub Release는 404였고 tag는 v0.1.0 하나가 확인됐다.
재현 경로는 연구 코드에 가깝다.
README는 Python 3.11 이상, benchmark별 optional extras, .env 기반 모델 provider credential, SWE-bench용 Docker, MCP-Atlas container/API key, SkillsBench clone/cache를 요구한다. examples/harness-evolution/ 아래에는 Exp0(harness-updating)와 Exp1(harness-benefit) driver가 따로 있고, HFR diagnostic pipeline도 제공된다.
즉 “pip install 후 바로 데모 앱을 실행하는 제품”이라기보다, 논문 실험을 재현·확장하기 위한 agent evolution 연구 harness로 보는 편이 정확하다.
실무 관점에서의 해석
가장 직접적인 메시지는 evolver를 무작정 키우는 것이 self-evolving agent의 최우선 투자처가 아닐 수 있다는 점이다.
논문 결과만 놓고 보면, harness update를 쓰는 모델의 체급 차이는 생각보다 작다.
심지어 작은 Qwen3.5-9B evolver가 SkillsBench에서 최고 Δ_update를 만든다.
따라서 운영 시스템에서는 “가장 비싼 frontier model을 reflection/update writer로 붙이면 된다”보다, 저렴한 evolver 후보와 검증 루프를 조합해 update 품질을 측정하는 방식이 더 합리적일 수 있다.
반대로 task-solving agent 쪽은 대체하기 어렵다.
업데이트된 harness가 있어도 agent가 해당 스킬을 호출하지 못하거나, 읽고도 절차를 지키지 못하면 이득이 사라진다.
이건 retrieval 문제와 instruction-following 문제가 섞인 형태다. agent runtime 관점에서는 skill router, load action grammar, context insertion policy, long-horizon adherence monitoring이 모두 성능의 일부가 된다.
이 논문은 agent memory나 skill library를 만들 때의 평가 기준도 바꾼다.
단순히 “좋은 스킬을 생성했는가”만 보면 부족하다.
다음 지표를 함께 봐야 한다.
| 운영 지표 | 질문 | 왜 필요한가 |
|---|---|---|
| Skill-load rate | 필요한 순간에 관련 harness를 실제로 불러오는가 | 검색/라우팅/도구 호출 형식 실패를 잡는다 |
| Harness-following rate | 불러온 지침을 trajectory 동안 실제로 따르는가 | 단순 context injection과 실행 순응을 분리한다 |
| Pass-when-loaded | harness가 들어간 실행에서 실제 성공으로 이어지는가 | “읽었지만 못 쓴다”는 병목을 드러낸다 |
| Phase-level adherence | 초반에는 따르다가 중후반에 drift하지 않는가 | 긴 작업의 instruction decay를 측정한다 |
특히 스킬 기반 에이전트에서는 “스킬 문서가 존재한다”와 “모델이 그 스킬을 활용한다” 사이의 간극이 크다.
좋은 SKILL.md를 많이 만들어도, 약한 agent가 load action을 잘못 내거나 중간에 절차를 잊으면 library는 성능 자산이 아니라 장식이 된다.
따라서 skill ecosystem을 운영하는 팀은 authoring보다 invocation과 adherence를 별도 제품 기능처럼 다뤄야 한다.
또 하나의 함의는 모델 학습 목표다.
논문은 약한 tier의 낮은 이득을 harness activation failure와 adherence failure로 추적한다.
이는 agent training이나 SFT/RL 데이터에서 “문제를 푼 최종 답”뿐 아니라, 언제 어떤 외부 artifact를 불러오고, 불러온 지침을 긴 실행 동안 어떻게 유지하는지를 포함해야 한다는 뜻이다.
앞으로 agent model의 능력은 pure reasoning score뿐 아니라 persistent external instruction을 다루는 능력으로 평가될 가능성이 크다.
한계와 caveat
이 연구는 harness self-evolution만 다룬다.
모델 가중치 fine-tuning, RL, hybrid adaptation은 실험하지 않는다.
따라서 결론을 “가중치 학습보다 harness 업데이트가 낫다”로 읽으면 안 된다.
더 정확한 메시지는, 외부 harness만 업데이트하는 설정에서는 업데이트 작성 능력과 활용 능력이 다르게 움직이며, 현재 실험에서는 활용 능력이 더 큰 병목으로 보인다는 것이다.
모델 grid도 넓지만 완전하지는 않다.
특정 모델 family, provider routing, benchmark 구현, evolver prompt가 결과에 영향을 줄 수 있다.
HFR과 phase adherence는 LLM judge 기반 분석이므로 judge bias 가능성도 남는다.
또한 SkillsBench, MCP-Atlas, SWE-bench Verified는 agentic benchmark로 유용하지만, 각 조직의 실제 도구·권한·승인·보안 경계를 모두 대표하지는 않는다.
그럼에도 이 논문의 분해 방식은 꽤 실용적이다. self-evolving agent를 만들 때 “좋은 업데이트를 생성한다”와 “좋은 업데이트를 사용한다”를 같은 숫자로 합치지 말라는 경고이기 때문이다.
앞으로 에이전트가 prompts, skills, memories, tools를 지속적으로 고치는 방향으로 간다면, 진짜 병목은 더 똑똑한 반성문 생성기가 아니라, 업데이트된 harness를 제때 불러오고 끝까지 따르는 실행 에이전트일 수 있다.