긴 컨텍스트 LLM 시스템에서 가장 쉬운 선택은 “컨텍스트 창을 더 크게 쓰자”다.
하지만 실제 서비스에서는 토큰 비용, 지연 시간, 캐시 재사용, 전처리 비용이 함께 움직인다.
긴 문맥을 한 번 더 넣는 것이 정확도에는 조금 도움이 되더라도, 그 비용이 워크로드 전체에서 정당화되는지는 별도의 질문이다.
The Efficiency Frontier: A Unified Framework for Cost-Performance Optimization in LLM Context Management는 이 질문을 정면으로 다룬다.
이 논문은 새로운 retrieval 모델이나 압축 알고리즘 하나를 제안하기보다, 컨텍스트 관리 전략을 비용-성능 프런티어 위의 선택 문제로 모델링한다.
즉 full-context prompting, TF-IDF 검색, query-aware 검색, semantic retrieval, LLM 기반 memory compression을 같은 축에서 비교하고, 어떤 배포 조건에서 어떤 전략이 효율적인지 보여 주려는 작업이다.
핵심 메시지는 꽤 실무적이다.
단일 쿼리처럼 재사용이 거의 없는 상황에서는 가벼운 retrieval이 유리할 수 있다.
반대로 같은 문서나 메모리 표현을 여러 질의에서 반복해 쓰는 persistent assistant, enterprise knowledge system, shared retrieval pipeline에서는 초기 전처리 비용을 여러 요청에 나눠 부담할 수 있으므로 memory compression이 프런티어의 더 넓은 구간을 차지한다.
무엇을 해결하려는가
기존 context reduction 평가는 대개 정확도와 효율을 따로 보고한다.
어떤 논문은 F1이나 EM을 강조하고, 다른 논문은 compression ratio나 token count를 강조한다.
문제는 실제 운영자가 묻는 질문이 그보다 구체적이라는 점이다.
예를 들어 “F1 0.78 정도면 충분한데 가장 싼 전략은 무엇인가”, “같은 문서 묶음을 100번 재사용한다면 LLM 기반 압축이 retrieval보다 싸지는가”, “최고 성능을 위해 full context를 유지할 때 추가 토큰은 얼마나 비싼가” 같은 질문에는 단일 지표가 답하기 어렵다.
논문은 이 공백을 deployment-aware optimization 문제로 다시 쓴다.
여기서 중요한 전환은 컨텍스트를 “많이 넣을수록 좋은 입력”으로 보지 않는다는 것이다.
컨텍스트는 성능을 올릴 수도 있지만, distractor를 늘리고, attention dilution을 만들고, 비용을 증가시킨다.
따라서 좋은 컨텍스트 관리는 단순 압축률 경쟁이 아니라 목표 성능과 운영 조건에 맞춰 정보량을 배분하는 문제다.
핵심 아이디어 / 구조 / 동작 방식
프레임워크의 출발점은 비용을 두 단계로 나누는 것이다.
Stage 1은 memory compression 같은 전처리 비용이고, Stage 2는 각 질의마다 실제 추론에 들어가는 비용이다.
전처리 결과를 N개의 질의에서 재사용할 수 있다면 논문은 유효 토큰 비용을 다음처럼 본다.
EffectiveTokens = T_stage2 + T_stage1 / N
이 식은 간단하지만, 컨텍스트 시스템 평가에서는 의미가 크다.
LLM 기반 압축은 단일 요청에서는 비싸 보일 수 있다.
그러나 같은 압축 표현을 여러 요청에서 공유하면 초기 비용이 상각되고, per-query 관점에서는 더 저렴한 전략이 될 수 있다.
논문은 여기에 선호 가중치 w를 둔 효율 점수를 붙인다.
EfficiencyScore(w) = w · F1 - (1 - w) · log(EffectiveTokens)
w가 크면 성능을 더 중시하고, 작으면 비용을 더 중시한다.
로그 비용 항을 쓰는 이유는 토큰 비용 증가에 대한 체감 민감도가 선형이 아니라고 보기 때문이다.
이 점수로 각 전략 내부의 최적 설정을 찾고, 다시 전체 전략을 통합해 global efficiency frontier를 만든다.
| 구성 요소 | 논문에서의 역할 | 실무적 의미 |
|---|---|---|
| Full-context prompting | 모든 문맥을 넣는 고비용 baseline | 최고 성능 상한에 가깝지만 비용이 큼 |
| Oracle retrieval | 정답 supporting document만 쓰는 비배포 upper bound | 선택 오류와 추론 오류를 분리해 보는 기준점 |
| TF-IDF / query-aware TF-IDF | 전처리 비용이 없는 lightweight retrieval | 단일 쿼리·저비용 구간에서 유리 |
| Semantic embedding retrieval | dense representation 기반 top-k 선택 | 검색 품질을 높이되 LLM 전처리는 쓰지 않는 중간 지점 |
| Memory compression | LLM으로 문맥을 압축하는 Stage 1 전처리 | 재사용이 많을수록 상각 효과가 커짐 |
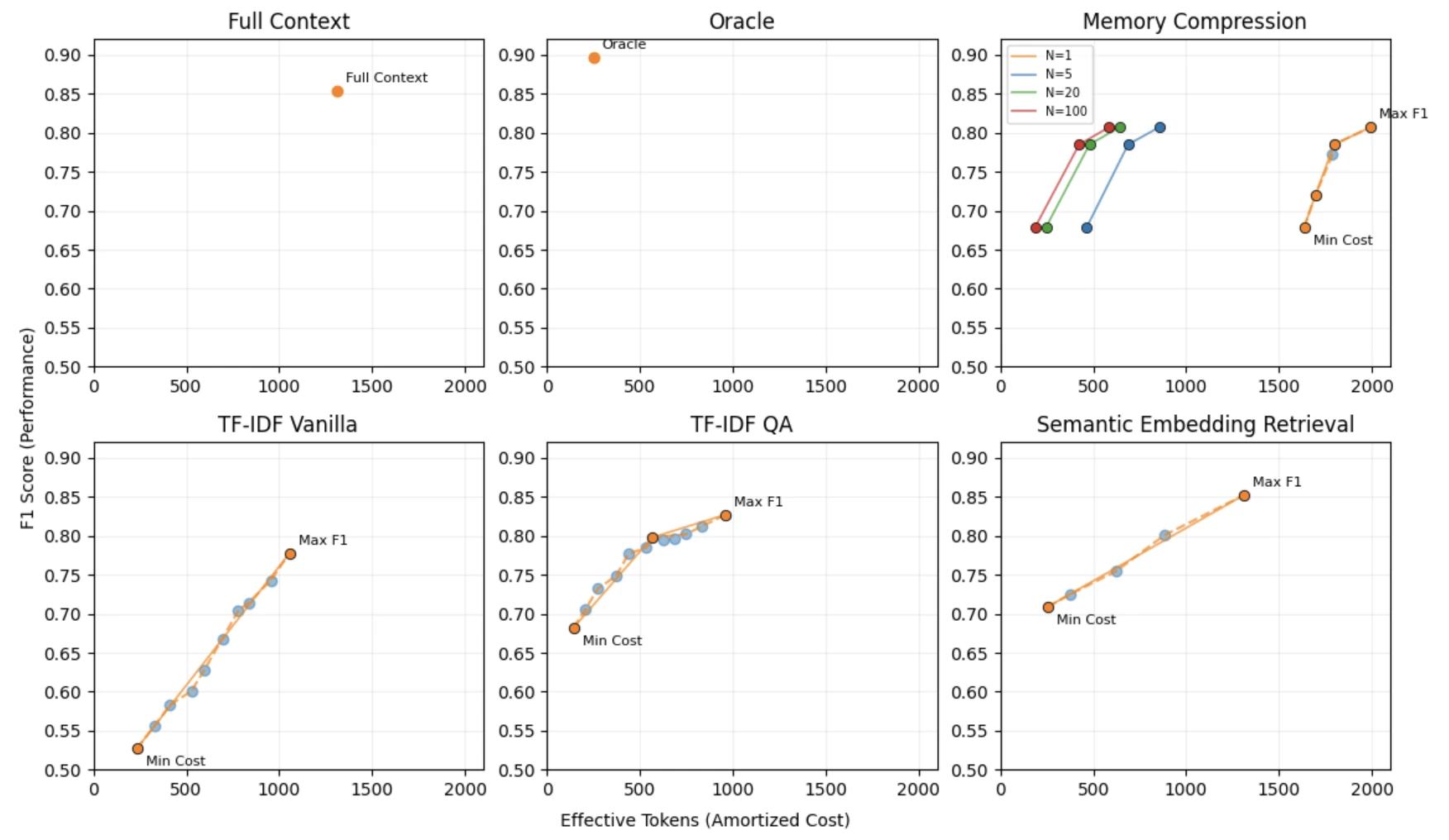
공개된 근거에서 확인되는 점
논문은 HotpotQA 5,000개 샘플을 고정 seed로 뽑아 평가한다.
HotpotQA는 multi-hop question answering benchmark라서 관련 문서와 distractor 문서가 함께 들어가며, context selection과 reasoning failure를 동시에 드러내기에 적합하다.
모든 전략은 논문 기준 GPT-5.4 mini와 표준화된 prompt, deterministic inference 설정에서 비교된다.
가장 직접적인 결과는 재사용 조건에 따라 프런티어가 이동한다는 점이다.
Figure 2는 N=1, N=20, N=100 재사용 조건에서 global frontier가 어떻게 바뀌는지 보여 준다.N이 커질수록 memory compression처럼 초기 비용이 큰 전략이 더 넓은 balanced regime에서 최적 선택으로 올라온다.
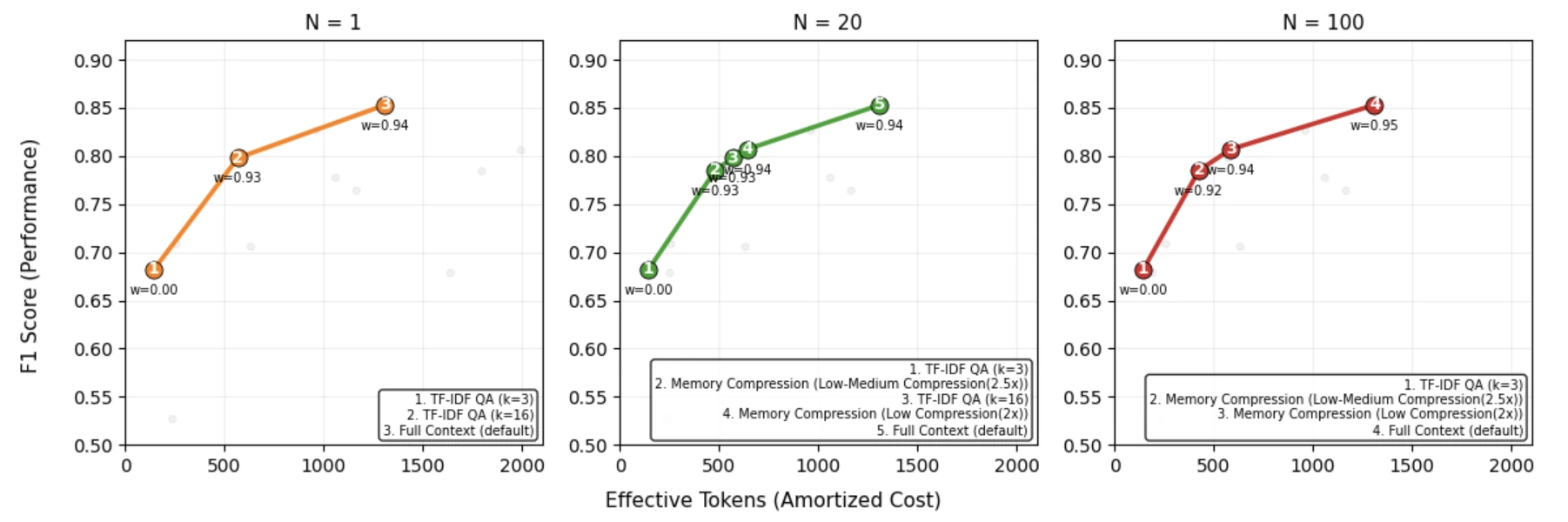
논문이 제시한 대표 운영 구간은 다음처럼 정리된다.
| 성능 구간 | N=1에서의 우세 전략 | N=100에서의 우세 전략 | 해석 |
|---|---|---|---|
| Efficiency-oriented, F1 0.70–0.78 | TF-IDF QA, k=16 | Memory Compression, 2.5× | 낮은 비용 구간도 재사용이 많으면 압축이 경쟁력을 갖는다. |
| Balanced, F1 0.78–0.82 | Full-Context | Memory Compression, 2× | 중간 성능 목표에서는 상각된 압축이 가장 실무적인 선택지가 될 수 있다. |
| High-performance, F1 0.82–0.84 | Full-Context | Full-Context | 최고 성능 구간에서는 여전히 전체 문맥이 필요하지만 비용이 급증한다. |
headline 수치도 이 구조를 따른다.
Balanced regime에서 재사용이 N=1에서 N=100으로 늘면 최적 운영점이 TF-IDF QA 566 EffectiveTokens에서 memory compression 424 EffectiveTokens로 바뀌며, F1 0.78 수준에서 약 25%의 유효 토큰 절감이 나온다.
또 balanced regime 상단, F1 약 0.80 근처에서는 full-context 1308 EffectiveTokens 대신 memory compression 584 EffectiveTokens가 선택되어 50% 이상 낮은 비용을 보인다.
반대로 최고 성능 구간은 여전히 비싸다.
논문은 F1 0.82 이상에서 full-context prompting이 필요하지만, 이 영역의 비용은 balanced operating point보다 두 배 이상 커질 수 있다고 설명한다.
성능을 몇 포인트 더 올리기 위해 전체 문맥을 유지하는 선택은 가능하지만, marginal gain 대비 비용이 빠르게 커진다는 뜻이다.
공개 소스 관점에서는 이 논문이 현재 arXiv paper와 HTML figure를 중심으로 읽히는 작업이라는 점도 중요하다. arXiv abstract와 HTML 본문에서는 별도 공식 GitHub 저장소, project page, Hugging Face artifact 링크를 확인하지 못했다.
따라서 이 글의 해석도 runnable framework release가 아니라 평가 프레임워크와 HotpotQA 실험 결과를 중심으로 둔다.
실무 관점에서의 해석
내가 보기에 이 논문의 가장 유용한 포인트는 “컨텍스트 관리 전략은 모델 성능표가 아니라 운영 모델과 함께 평가해야 한다”는 점이다.
RAG, memory, summarization, compression은 흔히 서로 다른 논문/라이브러리의 기능처럼 비교된다.
하지만 실제 서비스에서는 질문 빈도, 문서 재사용률, 캐시 수명, update 주기, latency budget이 함께 결정한다.
예를 들어 고객지원 봇이 같은 제품 문서 묶음을 하루에 수천 번 참조한다면, 문서를 미리 압축하거나 구조화하는 Stage 1 비용은 충분히 상각될 수 있다.
반대로 사용자가 매번 전혀 다른 긴 파일을 한 번만 던지는 ad hoc 분석 도구라면, 비싼 compression을 먼저 돌리는 것보다 query-aware retrieval로 필요한 부분만 자르는 편이 낫다.
논문이 말하는 N은 단순한 수식 변수가 아니라 제품의 사용 패턴을 나타내는 운영 변수다.
또 하나의 함의는 benchmark report 방식이다.
앞으로 context management 논문이나 내부 평가가 “F1은 얼마, 토큰은 얼마”만 말한다면 부족하다.
어떤 재사용 가정에서의 토큰 비용인지, 전처리 비용을 요청마다 새로 부담하는지 공유하는지, full-context 대비 어느 성능 구간에서 이득이 나는지를 함께 보여 줘야 한다.
이 논문은 그 형식을 efficiency frontier라는 이름으로 제안한다.
물론 제한도 있다.
결과는 HotpotQA와 논문이 설정한 전략 후보군, 모델, prompt 조건에 묶여 있다.
실제 제품에서는 토큰 수뿐 아니라 latency, dollar cost, cache hit rate, embedding index 갱신 비용, 개인정보·보안 제약, 답변 품질의 human preference도 같이 봐야 한다.
Oracle retrieval은 배포 가능한 방법이 아니라 upper bound이고, memory compression의 압축 품질도 도메인마다 다르게 흔들릴 수 있다.
그럼에도 방향은 설득력 있다.
긴 컨텍스트 시대의 병목은 단순히 “얼마나 많은 토큰을 넣을 수 있는가”에서 “어떤 토큰과 압축 표현을 어떤 비용으로 반복 사용할 것인가”로 이동하고 있다.
Efficiency Frontier는 이 전환을 정량화하려는 프레임워크다.
실무자는 이 논문을 새로운 라이브러리로 보기보다, RAG·memory·long-context serving을 설계할 때 평가표에 추가해야 할 의사결정 레이어로 읽는 편이 더 정확하다.