멀티모달 모델을 둘러싼 최근 경쟁은 더 이상 “이미지를 읽을 수 있는가” 수준에서 갈리지 않는다. 실제로는 하나의 모델이 이미지와 텍스트를 함께 이해할 뿐 아니라, 이미지 생성과 편집까지 같은 내부 표현 위에서 처리할 수 있는지가 더 중요해졌다. 하지만 많은 unified multimodal model은 여전히 CLIP류 representation encoder, VAE, generation head 같은 모듈을 조합한 구조에 기대고 있다. 이 조합은 강력하지만, 이해용 표현과 생성용 표현이 분리되기 쉽고 end-to-end 최적화도 제한된다.
Tuna-2는 이 병목을 정면으로 건드린다. Meta, 홍콩대, 워털루대 연구진이 공개한 이 모델은 pretrained vision encoder와 VAE를 모두 걷어내고, raw pixel을 단순 patch embedding으로 넣은 뒤 하나의 transformer decoder에서 이해와 생성을 함께 처리하는 native unified multimodal model이다. 핵심 주장은 단순하다. 충분한 scale의 end-to-end 시각 pretraining이 가능하다면, 복잡한 비전 인코더 없이도 고품질 생성과 세밀한 시각 이해를 동시에 달성할 수 있다는 것이다.
이 문제제기가 중요한 이유는 향후 멀티모달 모델 설계의 기본값을 바꿀 수 있기 때문이다. 지금까지는 “좋은 비전 인코더를 먼저 만들고 LLM에 붙인다”가 사실상 정석에 가까웠다. Tuna-2는 오히려 그 반대로, 인코더가 없는 편이 fine-grained perception에서는 더 유리할 수 있다고 주장한다.
무엇을 해결하려는가
Tuna-2가 겨냥하는 문제는 unified model 내부의 표현 불일치다. 기존 멀티모달 시스템은 이해에는 representation encoder를, 생성에는 VAE나 latent diffusion 경로를 쓰는 경우가 많다. 이 방식은 각 작업에 특화된 표현을 주기 때문에 출발 성능은 좋을 수 있지만, 이해와 생성이 서로 다른 시각 표현 위에서 돌아가게 만들고, 결국 하나의 모델이 정말로 같은 visual world model을 공유하는지에 대한 의문을 남긴다.
논문은 이 지점을 두 단계로 쪼개서 본다. 먼저 Tuna-R은 VAE를 제거하되 representation encoder는 남겨둔 중간 형태다. 이어 Tuna-2는 그 representation encoder까지 제거하고, 이미지 자체를 patch embedding으로 바꿔 곧바로 decoder에 투입한다. 즉 해결하려는 핵심은 “좋은 비전 인코더를 무엇으로 바꿀까”가 아니라, 아예 사전학습 비전 인코더 없이도 통합 멀티모달을 성립시킬 수 있는가다.
이 문제는 실무적으로도 의미가 있다. 비전 인코더와 생성 경로가 여러 개 얽힐수록 학습·서빙·확장 비용이 올라가고, 입력 해상도나 low-level detail 처리에서도 제약이 커질 수 있다. Tuna-2는 이런 복잡도를 줄이면서 더 세밀한 시각 지각을 확보하려는 설계로 읽힌다.
핵심 아이디어 / 구조 / 동작 방식
Tuna-2의 구조는 크게 세 가지 축으로 요약할 수 있다.
첫째는 encoder-free visual tokenization이다. Tuna-2는 pretrained representation encoder 대신 simple patch embedding layer로 이미지를 visual token으로 바꾼다. 이 토큰은 텍스트 토큰과 함께 단일 LMM decoder에서 처리된다. 결과적으로 모델의 중심부는 비전 인코더 + LLM 조합이 아니라, 멀티모달 입력을 공동으로 다루는 하나의 unified transformer가 된다.
둘째는 pixel-space flow matching이다. VAE를 제거했기 때문에 기존 latent diffusion 경로를 그대로 쓸 수 없다. 대신 Tuna-2는 noisy sample을 pixel space에서 직접 만들고, x-prediction과 v-loss를 활용한 rectified flow 기반 학습으로 이미지 생성과 편집을 수행한다. 이 선택은 생성 경로를 latent 공간의 별도 시각 압축기 위에 두지 않고, raw pixel 수준에서 end-to-end로 묶겠다는 선언에 가깝다.
셋째는 masking-based feature learning이다. raw pixel을 직접 다루면 학습 난도가 커지기 때문에, 논문은 일부 image patch를 learnable mask token으로 치환하는 학습 방식을 추가한다. 이는 생성 쪽에서는 더 어려운 denoising 문제를 만들고, 이해 쪽에서는 부분 관측 상태에서 중요한 시각 단서를 복원하도록 유도한다. 쉽게 말해 pixel-space 학습의 난도를 완화하는 동시에, 더 강한 fine-grained visual representation을 유도하는 장치다.
또한 공개 자료 기준 Tuna-2는 두 단계 훈련 파이프라인을 갖는다. 먼저 image captioning과 image generation 데이터를 활용한 full-model pretraining을 수행하고, 이후 supervised fine-tuning으로 instruction following과 고품질 이미지 생성을 보강한다. GitHub README는 video training/inference 코드도 포함하지만, 정책 제약으로 video generation model weight는 아직 공개하지 않았다고 밝힌다.
| 구성 요소 | 공개 자료에서 확인되는 내용 | 의미 |
|---|---|---|
| Visual input path | pretrained encoder 대신 patch embedding 사용 | 시각 이해를 외부 인코더가 아니라 decoder 내부 표현으로 흡수 |
| Generation path | pixel-space flow matching, x-prediction, v-loss | latent diffusion 의존도를 줄이고 raw pixel에서 직접 생성 |
| Intermediate baseline | Tuna-R는 representation encoder만 남긴 비교 모델 | encoder 제거 효과를 통제된 조건에서 분석 가능 |
| Regularization | masking-based feature learning | 부분 관측 기반 지각 학습과 generation stability 개선 |
| Training | pretraining + SFT 2단계 | 이해와 생성을 모두 end-to-end로 묶되 후반 품질을 별도로 보정 |

공개된 근거에서 확인되는 점
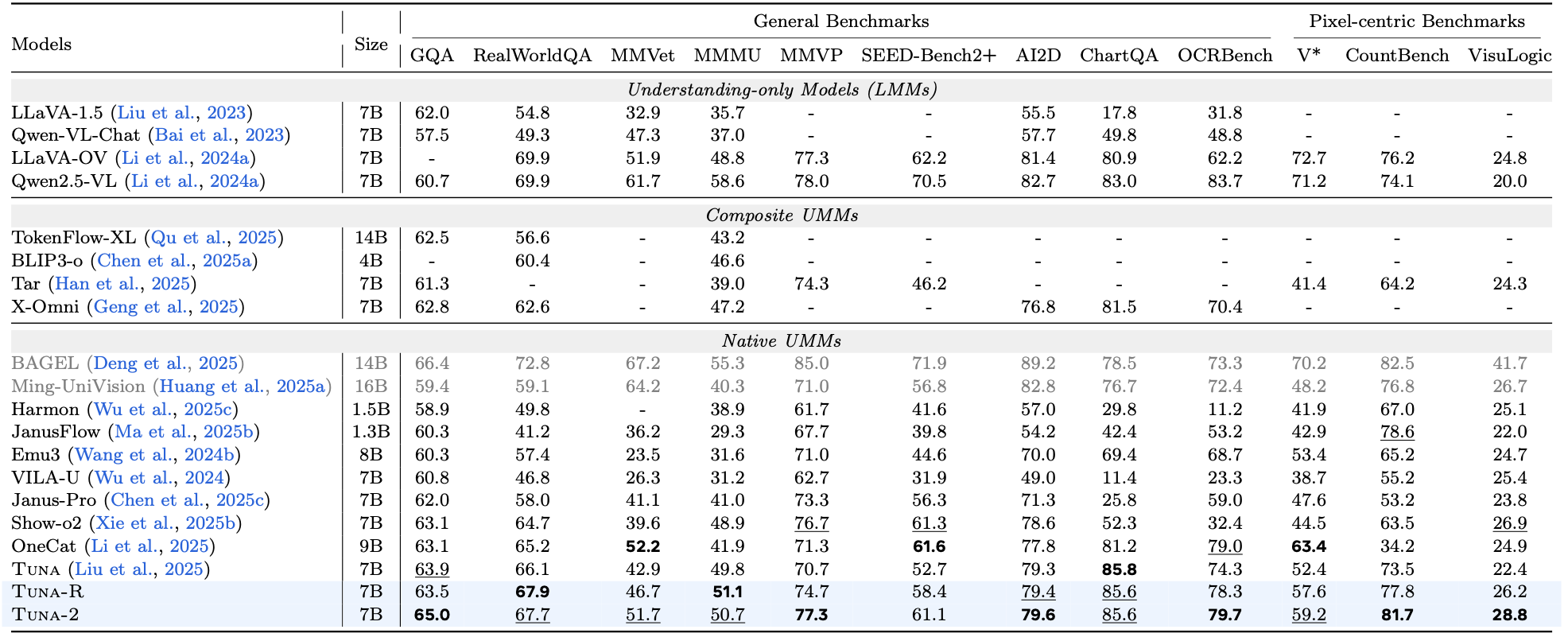
가장 중요한 근거는 Tuna-2가 단순 아이디어 제안에 그치지 않고, Tuna·Tuna-R·Tuna-2를 나란히 비교하는 통제 실험을 제시한다는 점이다. arXiv HTML의 Table 1 기준으로 Tuna-2 7B는 Tuna-R 7B 대비 GQA 65.0 vs 63.5, MMVet 51.7 vs 46.7, SEED-Bench2+ 61.1 vs 58.4, OCRBench 79.7 vs 78.3, CountBench 81.7 vs 77.8, VisuLogic 28.8 vs 26.2를 기록했다. 즉 전체 평균을 압도적으로 벌리기보다는, 세밀한 시각 단서와 픽셀 중심 지각이 중요한 항목에서 꾸준히 우세하다는 패턴이 보인다.
반면 생성은 조금 더 미묘하다. Table 2 기준 Tuna-2의 GenEval 세부 항목은 일부에서 Tuna-R와 비슷하거나 약간 낮고, DPG-Bench는 열별로 우열이 엇갈린다. 논문 초록과 본문이 강조하듯, encoder-based Tuna-R가 초반 pretraining 수렴은 더 빠르지만 충분한 시각 pretraining 이후에는 Tuna-2가 생성에서도 경쟁 가능해지고 이해에서는 더 강해진다는 것이 저자들의 핵심 해석이다. 즉 Tuna-2는 “생성까지 포함한 완전한 승리”보다는 이해 성능을 해치지 않으면서 encoder-free 구조가 실전 가능함을 보인 사례에 가깝다.
프로젝트 페이지와 GitHub README에서 확인되는 공개 범위도 중요하다. 저장소는 2026-04-22에 생성됐고 GitHub API 기준 stars 576, forks 23, license는 Apache-2.0, default branch는 main이다. 하지만 /releases/latest는 404이고 tags도 비어 있다. 더 중요한 점은 README의 모델 릴리스 노트다. 저자들은 조직 정책상 full production-trained model weight는 공개하지 못하며, 일부 레이어가 제거된 foundation checkpoint를 우선 공개할 계획이라고 적었다. 즉 코드와 구조, 학습 경로는 공개됐지만, 완전한 복원 없이 바로 논문 성능을 재현할 수 있는 패키지라고 보기는 어렵다.
또 하나의 운영 신호는 video 쪽 공개 범위다. README는 video training/inference code는 제공하지만, video generation model 자체는 정책상 미공개라고 명시한다. 따라서 Tuna-2를 지금 당장 “텍스트-이미지-비디오를 다루는 완전 배포형 멀티모달 생성 시스템”으로 읽는 것은 과장이다. 현재 공개물은 강한 연구용 코드베이스와 부분적 모델 공개 계획에 더 가깝다.
| 항목 | 확인된 내용 | 의미 |
|---|---|---|
| 이해 벤치마크 | Tuna-2가 MMVet, OCRBench, CountBench, VisuLogic 등에서 Tuna-R 대비 우세 | encoder-free 설계가 fine-grained perception에서 강점을 보일 가능성 |
| 생성 벤치마크 | GenEval/DPG-Bench에서 Tuna-R와 근접하거나 일부 열세 | 생성만 놓고 보면 encoder-free 전환의 비용이 완전히 사라진 것은 아님 |
| 공개 저장소 상태 | stars 576, forks 23, Apache-2.0, release/tag 부재 | 활발한 관심은 있으나 안정 버저닝 체계는 아직 약함 |
| 가중치 공개 상태 | full production weights 미공개, 일부 레이어 제거 foundation checkpoint 계획 | 재현성과 즉시 사용성에는 제약이 있음 |
| 비디오 공개 범위 | 코드 공개, video generation weights 미공개 | capability 서사와 실제 배포 가능 범위는 구분해서 봐야 함 |

실무 관점에서의 해석
내가 보기에 Tuna-2의 진짜 가치는 “비전 인코더가 필요 없다”는 자극적인 문장 자체보다, unified multimodal model의 복잡도를 어디까지 줄일 수 있는지 보여준 데 있다. 지금까지 많은 시스템은 이해 모델과 생성 모델, 또는 understanding encoder와 generation tokenizer를 분리한 뒤 orchestration으로 문제를 풀어왔다. Tuna-2는 이 분리를 줄이는 대신 학습 난도를 정면으로 감수하고, 그 대가로 더 일관된 visual representation을 얻으려 한다.
이 선택은 특히 세밀한 OCR, counting, diagram/chart 해석, localized attention 같은 영역에서 설득력이 있다. pretrained encoder는 강력하지만, 특정 입력 해상도나 사전학습 목표의 inductive bias를 함께 가져온다. Tuna-2가 patch embedding과 masking 학습으로 low-level visual detail을 더 직접적으로 다루려는 이유도 여기에 있다. Table 1과 attention visualization이 함께 말해주는 것도 바로 이런 서사다. 더 단순한 입력 경로가 오히려 더 정밀한 시각 집중을 만들 수 있다는 주장이다.
다만 현실적인 한계도 분명하다. 첫째, 생성 품질에서는 아직 encoder-based 경로를 완전히 압도한다고 보기 어렵다. 둘째, full production weights가 공개되지 않았기 때문에 외부 팀이 논문 주장 전체를 곧바로 검증하기 어렵다. 셋째, release/tag가 비어 있고 foundation checkpoint도 “복원형” 공개 계획에 가까워, 당장 패키징된 오픈 모델 제품으로 받아들이기에는 이르다.
그럼에도 Tuna-2는 중요한 방향 신호다. 멀티모달 모델의 다음 경쟁은 더 큰 비전 인코더를 붙이는 쪽이 아니라, 이해와 생성을 truly native한 하나의 visual-language substrate로 통합하는 쪽일 수 있다는 점을 보여준다. 그런 의미에서 Tuna-2는 단순한 한 편의 모델 논문이 아니라, 멀티모달 아키텍처에서 “무엇을 반드시 모듈로 남겨야 하는가”라는 가정 자체를 다시 묻는 작업에 가깝다.