LLM 애플리케이션의 품질 문제는 이제 모델 선택 하나로 끝나지 않는다.
같은 모델이라도 프롬프트가 바뀌면 결과가 흔들리고, RAG 파이프라인은 검색과 생성이 함께 무너지며, 에이전트는 정답 텍스트보다 도구 사용 과정에서 더 자주 실패한다.
결국 팀이 실제로 필요한 것은 “좋은 모델” 자체보다 좋은 실패를 빨리 찾고, 반복 가능하게 비교하고, 배포 전에 깨지는 지점을 테스트로 고정하는 방법이다.
confident-ai/deepeval은 바로 이 문제를 겨냥한다.
README는 DeepEval을 “The LLM Evaluation Framework”라고 부르지만, 공개 자료를 따라가 보면 핵심은 단순 점수 계산기가 아니다.
DeepEval은 pytest 스타일 단위 테스트, 50개 이상의 ready-to-use 메트릭, LLM-as-a-judge, agent tracing, synthetic goldens 생성, 고전 벤치마크 실행, 그리고 선택적으로 Confident AI 플랫폼 연동까지 하나의 흐름으로 묶으려 한다.
즉 모델 출력 한 줄을 채점하는 도구가 아니라, LLM 시스템 품질을 코드와 실험 자산으로 관리하는 운영 프레임에 가깝다.
이 프로젝트가 특히 눈에 띄는 이유는 local-first 철학과 제품형 확장성이 동시에 보인다는 점이다. docs introduction은 DeepEval을 로컬 환경에서 실행되는 오픈소스 프레임워크로 설명하면서, 팀 단위 대시보드·회귀 추적·관측성·프로덕션 모니터링이 필요할 때만 Confident AI와 네이티브하게 연결하라고 안내한다.
이런 구조는 오픈소스 평가 러너와 상용 품질 플랫폼 사이를 깔끔하게 분리하면서도, 둘을 자연스럽게 이어 붙이려는 전략으로 읽힌다.
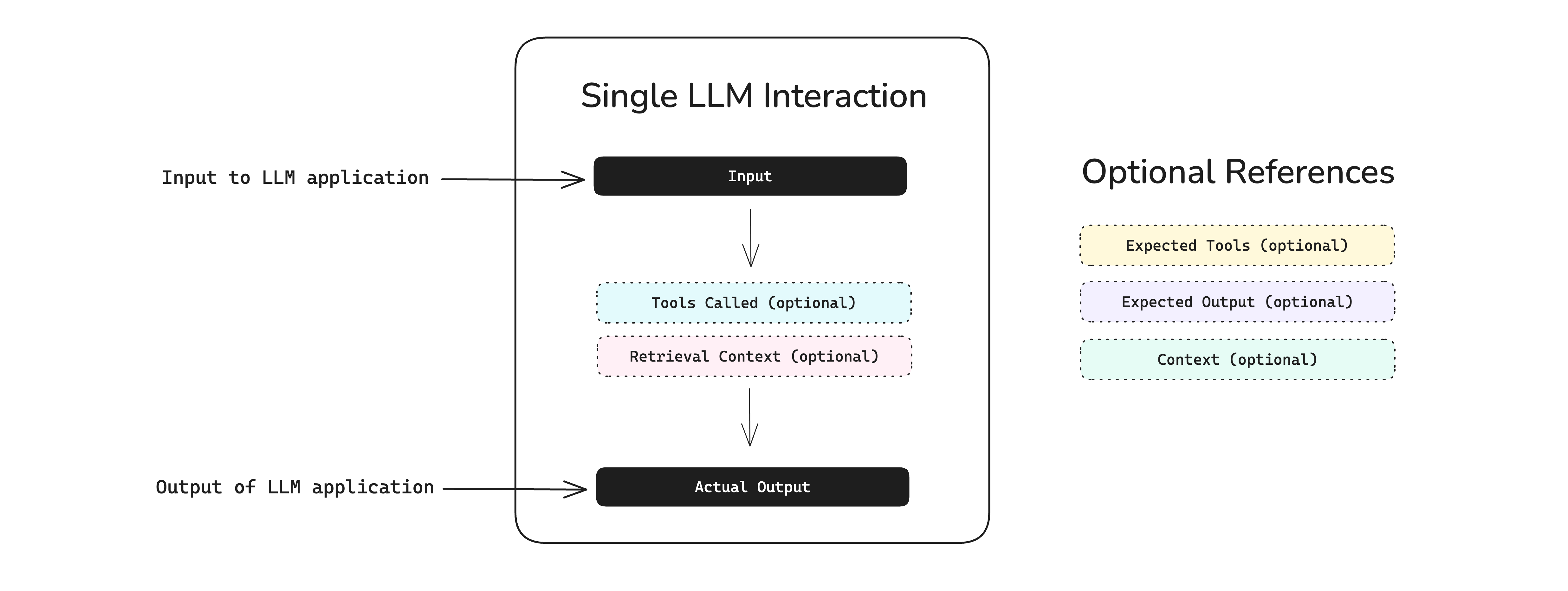
무엇을 해결하려는가
DeepEval이 푸는 문제는 LLM 평가의 세 가지 단절이다.
첫째는 테스트와 평가의 단절이다.
많은 팀이 프롬프트 실험은 하지만, 그 결과를 소프트웨어 테스트처럼 자동화하지는 못한다.
둘째는 출력 평가와 시스템 평가의 단절이다.
단답형 QA만 보는 메트릭으로는 에이전트의 단계별 실패, 도구 호출 오류, 대화 맥락 유지 문제를 잡기 어렵다.
셋째는 오프라인 검증과 운영 확장의 단절이다.
로컬에서 몇 개 샘플을 돌려 본 뒤 그것을 팀 단위 회귀 실험, 공유 리포트, 모니터링 체계로 연결하기가 어렵다.
DeepEval은 이 세 지점을 한 번에 묶으려 한다. quickstart 문서는 첫 예제로 deepeval test run을 중심에 두고, LLMTestCase, GEval, assert_test를 이용한 pytest형 평가부터 시작한다.
즉 평가를 별도 대시보드 작업이 아니라, 코드 저장소 안에서 실행되는 테스트 스위트로 취급한다.
이는 기존 소프트웨어 엔지니어링 습관을 LLM 품질 관리에 그대로 가져오려는 접근이다.
또한 docs와 README는 시스템 유형별로 평가를 쪼갠다.
RAG, agentic, multi-turn, MCP, multimodal, safety, benchmark, synthetic data generation이 각각 독립 섹션으로 존재한다.
이건 단순히 기능이 많다는 뜻이 아니라, DeepEval이 더 이상 “답변 한 문장”만 보는 프레임워크가 아니라는 신호다.
특히 최근 릴리스 v3.9.9가 Task Completion, Tool Correctness, Argument Correctness, Step Efficiency, Plan Adherence, Plan Quality 같은 에이전트 메트릭을 전면에 내세운 것은, 평가의 무게중심이 텍스트 평가에서 행동 평가로 이동하고 있음을 잘 보여 준다.
핵심 아이디어 / 구조 / 동작 방식
내가 보기에 DeepEval의 구조는 다섯 개 층으로 나눠 보면 가장 이해하기 쉽다.
1) pytest 스타일 테스트 러너
DeepEval은 처음부터 “테스트”라는 은유를 강하게 쓴다. pyproject.toml에는 pytest11 플러그인으로 deepeval.plugins.plugin이 등록돼 있고, quickstart는 pip install -U deepeval 뒤 deepeval test run으로 첫 평가를 실행하게 한다.
사용자는 LLMTestCase에 input, actual_output, 필요하면 expected_output을 넣고, GEval 같은 메트릭을 붙여 단일 테스트 함수를 작성한다.
이 구조의 장점은 분명하다.
평가가 노트북 실험이나 ad-hoc 스크립트가 아니라 CI/CD에 들어갈 수 있는 테스트 자산이 된다.
README도 DeepEval을 “Pytest but specialized for unit testing LLM apps”에 가깝게 설명한다.
즉 프롬프트 회귀, 모델 변경, RAG 체인 수정, 에이전트 도구 교체를 모두 코드 diff와 함께 추적하기 쉬워진다.
2) 메트릭 카탈로그와 LLM-as-a-judge
docs introduction과 metrics 페이지를 보면 DeepEval은 50개 이상의 ready-to-use 메트릭을 제공한다고 밝힌다.
흥미로운 점은 단순 정확도 수치가 아니라, LLM-as-a-judge를 기본 모델로 삼는다는 것이다. metrics 문서는 G-Eval, DAG, QAG 같은 기법을 언급하며, 대부분의 사전 정의 메트릭이 점수뿐 아니라 reasoning도 함께 반환한다고 설명한다.
점수 범위는 0~1이고, 기본 threshold는 0.5다.
메트릭 카테고리도 넓다.
README 기준으로 agentic metrics, RAG metrics, multi-turn metrics, MCP metrics, multimodal metrics, safety/other metrics가 분리되어 있다.
예를 들어 RAG 쪽은 Answer Relevancy, Faithfulness, Contextual Recall/Precision/Relevancy가 있고, agentic 쪽은 Tool Correctness, Goal Accuracy, Step Efficiency, Plan Adherence 등이 들어간다.
즉 이 프레임워크는 “정답 비교”보다 시스템 유형별 실패 양상을 메트릭 설계에 반영하려 한다.
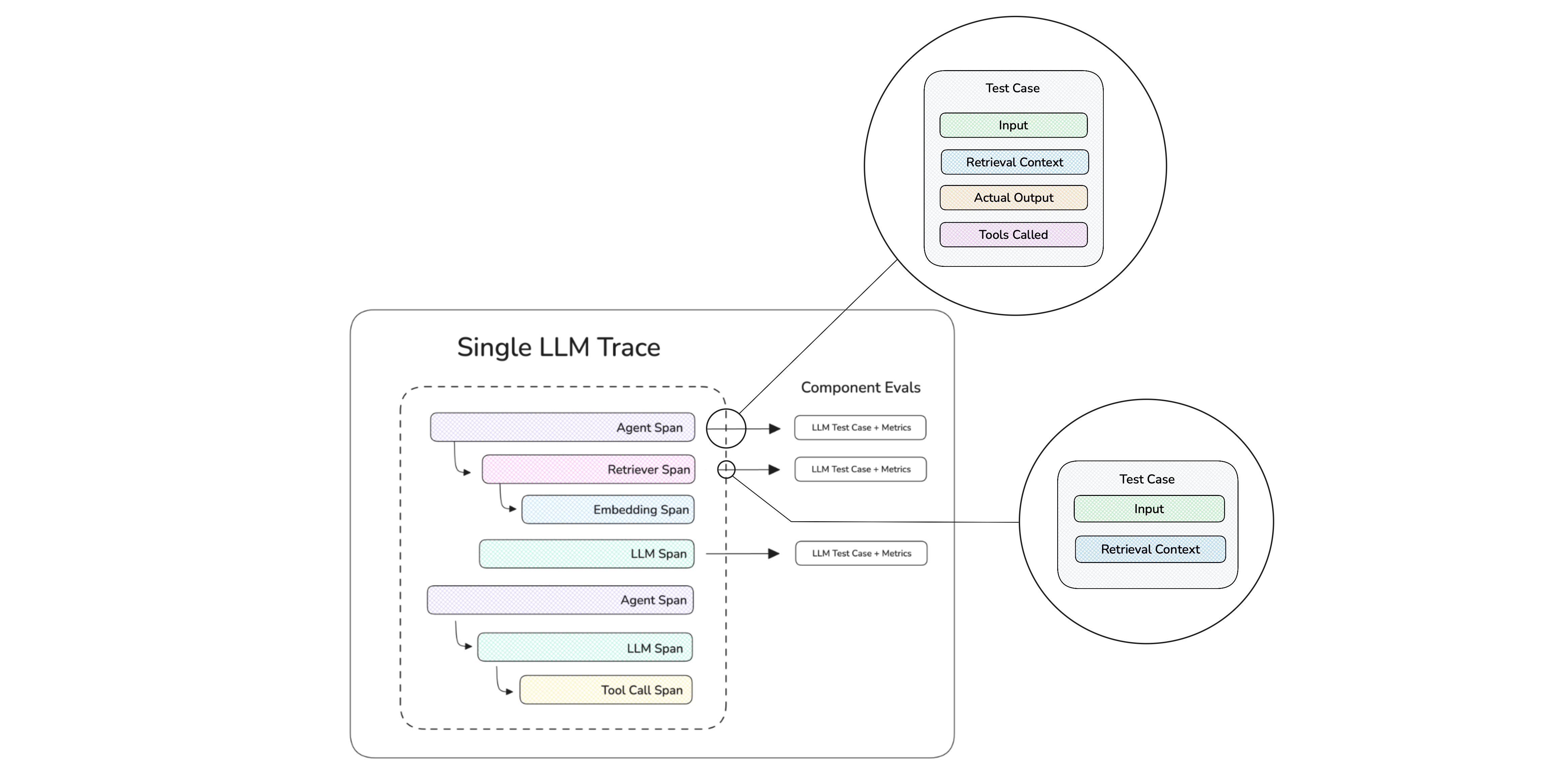
3) tracing과 component-level evals
quickstart와 introduction은 DeepEval이 end-to-end evals뿐 아니라 component-level evals도 지원한다고 반복해서 설명한다. docs quickstart는 tracing을 추가해 AI agent나 내부 컴포넌트를 평가할 수 있다고 말하고, 이미지 자료에서도 component-level eval 구조를 따로 보여 준다.
이것은 중요한 차이다.
단순 블랙박스 출력 점수만 보면 왜 실패했는지 알기 어렵지만, tracing이 있으면 검색 단계, 툴 호출, 계획 생성, 최종 응답 같은 중간 계층을 나눠 볼 수 있다.
최근 릴리스에서 agentic evals를 전면에 세운 것도 이 레이어와 연결된다. release notes는 최종 답이 그럴듯해 보이는지보다, agent가 실제로 task를 완수했는지, 적절한 도구를 썼는지, 인자를 올바르게 구성했는지, 불필요한 detour 없이 효율적으로 움직였는지를 측정하는 방향을 강조한다.
DeepEval은 에이전트를 “대화형 모델”이 아니라 실행 trace를 남기는 프로그램처럼 평가하려는 쪽에 가깝다.
4) 합성 데이터와 multi-turn goldens
평가 프레임워크가 실전에서 막히는 지점은 데이터셋 부재다.
DeepEval은 이 문제를 Synthesizer로 푼다. synthetic-data 문서는 single-turn뿐 아니라 multi-turn goldens 생성도 지원한다고 설명하며, 문서·지식베이스에서 시나리오를 만들고 이를 더 복잡하고 현실적인 형태로 진화시킨 뒤 EvaluationDataset으로 변환하는 과정을 소개한다. optional parameters도 async_mode, max_concurrent, filtration_config, evolution_config, styling_config, cost_tracking 등 꽤 세밀하다.
이 기능은 단순 부가 옵션이 아니라 DeepEval의 운영 모델을 완성하는 축이다.
즉 이 프레임워크는 메트릭만 제공하는 것이 아니라, 테스트 케이스 생성 → 시뮬레이션 → 평가까지 한 파이프라인으로 엮으려 한다.
릴리스 v3.9.9가 multi-turn synthetic goldens generation을 별도 하이라이트로 올린 것도 그래서 자연스럽다.
5) 벤치마크와 플랫폼 확장
DeepEval은 애플리케이션 평가만 하지 않는다. benchmark docs는 BIG-Bench Hard, HellaSwag, MMLU, DROP, TruthfulQA, HumanEval, GSM8K를 지원한다고 밝히며, DeepEvalBaseLLM을 상속해 임의의 모델을 래핑한 뒤 벤치마크를 돌릴 수 있게 한다.
즉 custom app eval과 canonical benchmark eval을 같은 저장소 안에서 다룬다.
여기에 플랫폼 확장도 붙는다.
README는 OpenAI, OpenAI Agents, LangChain, LangGraph, Pydantic AI, CrewAI, Anthropic, AWS AgentCore, LlamaIndex 등 여러 프레임워크 통합을 전면에 두고, Confident AI를 observability·evals·monitoring 플랫폼으로 연결한다. repo 구조도 deepeval, docs, examples, tests, skills, .cursor-plugin 등을 함께 품고 있어 단순 라이브러리보다 생태계형 레포에 가깝다.
| 레이어 | 공개 자료에서 확인되는 구성요소 | 실무적 의미 |
|---|---|---|
| Test runner | pytest 플러그인, deepeval test run, assert_test |
평가를 코드 저장소 안의 자동 테스트로 고정 |
| Metrics | 50+ metrics, G-Eval, DAG, RAG/Agent/Multi-turn/MCP/Multimodal | 시스템 유형에 맞는 실패 양상을 메트릭으로 분해 |
| Tracing | end-to-end + component-level evals, agent trace 기반 scoring | 최종 출력뿐 아니라 중간 단계 품질을 진단 |
| Data generation | Synthesizer, single-turn + multi-turn goldens |
평가 데이터셋이 없을 때도 초기 세트를 빠르게 생성 |
| Benchmark + platform | MMLU/HellaSwag/GSM8K 등, Confident AI native integration | 연구용 벤치마크와 팀 운영용 리포트를 같은 스택으로 연결 |
공개된 근거에서 확인되는 점
현재 공개 GitHub 저장소 기준으로 confident-ai/deepeval은 약 15.2k stars, 1.4k forks, Apache-2.0 라이선스를 갖고 있다.
Python이 주 언어이며, default branch는 main이다. pyproject.toml의 패키지 버전은 3.9.9이고, GitHub latest release도 v3.9.9다.
즉 패키지 버전과 최신 릴리스 버전은 현재 시점에서 정렬되어 있다.
README와 docs introduction은 DeepEval을 local-first로 정의한다. quickstart는 pip install -U deepeval만으로 로컬에서 바로 평가를 시작하게 하고, 필요할 때만 deepeval login을 통해 Confident AI에 결과를 올리게 만든다.
이 구조는 SaaS 의존보다 로컬 실행을 기본값으로 둔다는 점에서 의미가 있다.
특히 metrics 페이지가 “ANY LLM judge”를 사용할 수 있고 custom LLM을 DeepEvalBaseLLM로 감쌀 수 있다고 설명하는 부분까지 고려하면, 이 프레임워크는 특정 모델 벤더 종속성보다 평가 인터페이스 표준화 쪽에 더 무게를 두고 있다.
메트릭 범위도 매우 넓다. introduction은 50+ metrics를 말하고, README는 agentic/RAG/multi-turn/MCP/multimodal/safety 계열을 상세 목록으로 나열한다. quickstart 문서에서는 첫 예제로 GEval 기반 correctness 평가를 보여 주고, metrics introduction은 대부분의 predefined metrics가 LLM-as-a-judge를 사용하며 score와 reasoning을 함께 제공한다고 명시한다.
점수 기본 threshold를 0.5로 둔 것도 확인된다.
최신 릴리스의 방향성은 특히 흥미롭다. v3.9.9 release notes는 Task Completion, Tool Correctness, Argument Correctness, Step Efficiency, Plan Adherence, Plan Quality를 새 핵심으로 내세운다.
동시에 multi-turn synthetic goldens generation을 별도 하이라이트로 올린다.
이는 DeepEval이 더 이상 RAG 평가 라이브러리 수준이 아니라, 에이전트 행동 평가 + 대화형 테스트 데이터 생성까지 범위를 확장하고 있음을 보여 준다.
레포 구조도 그 방향성과 맞아떨어진다. deepeval/metrics, deepeval/benchmarks, deepeval/tracing, deepeval/synthesizer, deepeval/integrations, deepeval/dataset 같은 디렉터리가 분리되어 있고, examples/ 아래에는 getting_started, rag_evaluation, mcp_evaluation, tracing 등이 존재한다. skills/와 .cursor-plugin/이 함께 들어 있는 점도 재미있다.
이는 DeepEval이 평가 프레임워크이면서 동시에 에이전트 코딩 도구에 바로 녹여 넣을 수 있는 워크플로우 자산까지 배포하고 있음을 의미한다.
| 공개 근거 | 확인된 내용 | 해석 |
|---|---|---|
| GitHub 저장소 메타데이터 | 약 15.2k stars, 1.4k forks, Apache-2.0, Python | 이미 널리 채택된 대형 LLM 평가 오픈소스 |
pyproject.toml |
버전 3.9.9, pytest 플러그인 등록, CLI 엔트리포인트 제공 |
라이브러리이면서 테스트 러너/CLI로도 동작 |
| docs introduction | local-first, 50+ metrics, technical audience, tracing/benchmarks/synthesizer 안내 | 단일 메트릭 도구보다 넓은 평가 운영 프레임 |
| metrics introduction | LLM-as-a-judge, G-Eval/DAG/QAG, score+reasoning, threshold 0.5 | 평가 논리를 설명 가능한 채점 체계로 구조화 |
latest release v3.9.9 |
agentic metrics 6종 강조, multi-turn synthetic goldens generation 추가 | 최근 초점이 agent behavior eval로 이동 중 |
| repo/examples structure | benchmarks, tracing, synthesizer, mcp_evaluation, skills |
프레임워크가 실제 워크플로우와 생태계까지 포괄 |
실무 관점에서의 해석
내가 보기에 DeepEval의 가장 큰 장점은 “평가를 개발자 친화적 형태로 번역한다”는 데 있다.
많은 평가 툴이 멋진 대시보드를 제공하지만, 개발자가 원하는 것은 결국 테스트 파일, 실패 재현, CI 통합, 코드 리뷰 가능한 평가 기준이다.
DeepEval은 그 점에서 상당히 설득력이 있다. pytest 스타일 인터페이스를 전면에 두고, 평가 기준을 메트릭 객체로 만들며, tracing과 datasets까지 같은 언어로 연결하기 때문이다.
또한 이 프레임워크는 최근 평가 트렌드를 꽤 빠르게 흡수하고 있다.
RAG 평가에서 agent eval로, 단일 응답에서 multi-turn으로, 정적 데이터셋에서 synthetic goldens로, 단순 pass/fail에서 trace-aware scoring으로 이동하는 흐름이 그대로 반영된다.
특히 latest release가 task completion, tool correctness, argument correctness를 핵심으로 내세운 것은 좋은 신호다.
에이전트 시대의 실패는 최종 답안보다 과정의 품질에서 더 많이 발생하기 때문이다.
물론 한계도 있다.
첫째, 범위가 넓은 만큼 어떤 메트릭 조합이 실제로 자기 시스템에 맞는지 사용자가 신중히 골라야 한다. docs도 메트릭을 5개 이하로 제한하라고 권한다.
둘째, LLM-as-a-judge는 유연하지만 비용과 변동성 문제를 완전히 없애지는 못한다.
README가 DAG 기반 deterministic metric builder를 강조하는 것도 바로 그런 불안정성을 보완하려는 움직임으로 보인다.
셋째, Confident AI 연동은 매끄럽지만, 오픈소스 프레임워크와 플랫폼 결합이 강해질수록 장기적으로는 사용자들이 어느 레이어까지 self-host/local로 남길지 판단해야 한다.
그럼에도 불구하고 DeepEval은 지금 시점에서 꽤 강한 포지션에 있다.
이유는 간단하다.
이 프로젝트는 “평가”를 연구자의 사후 분석이 아니라, 엔지니어가 매일 돌리는 테스트와 데이터 파이프라인의 일부로 재정의하고 있기 때문이다.
RAG 앱, 챗봇, 에이전트, MCP 시스템을 운영하는 팀이라면 DeepEval은 또 하나의 메트릭 모음집이 아니라, LLM 품질 관리의 기본 런타임으로 검토할 가치가 있다.