비디오 멀티모달 모델에서 “저 사람”, “파란 모자를 쓴 선수”, “오른쪽에서 계속 움직이는 개체”처럼 특정 객체를 가리키는 일은 생각보다 어렵다.
기존 fine-grained object understanding 계열은 사용자가 점, 박스, 마스크 같은 시각 프롬프트를 함께 넣어 주면 더 안정적으로 동작한다.
하지만 실제 사용자가 모델과 대화할 때 매번 마스크를 그리는 것은 자연스럽지 않다.
대부분의 인터페이스에서는 텍스트로 대상을 설명하고, 모델이 그 지시를 영상 안의 올바른 객체에 연결해 주기를 기대한다.
See What I Mean: Aligning Vision and Language Representations for Video Fine-grained Object Understanding는 이 간극을 직접 겨냥한다.
Boyuan Sun, Bowen Yin, Yuanming Li, Xihan Wei, Qibin Hou가 제안한 SWIM은 추론 시에는 순수 자연어 프롬프트만 받되, 학습 중에는 객체 마스크를 이용해 텍스트 토큰과 시각 영역의 cross-attention을 직접 맞춘다.
이름 그대로 사용자가 말로 “무엇을 의미하는지”를 모델이 영상 안에서 찾아내게 만드는 훈련 전략이다.
핵심은 마스크를 버리는 것이 아니라 마스크를 학습 신호로만 쓰는 것이다.
SWIM은 VideoRefer 계열의 mask annotation을 자연어 지칭 표현으로 바꾼 NL-Refer를 만들고, <ins>...</ins>로 표시된 객체 지칭 토큰의 attention map이 해당 객체 마스크와 공간적으로 일치하도록 보조 손실을 건다.
그 결과 추론 때는 별도 visual prompt 없이 텍스트만으로 객체를 가리키는 쪽을 노린다.
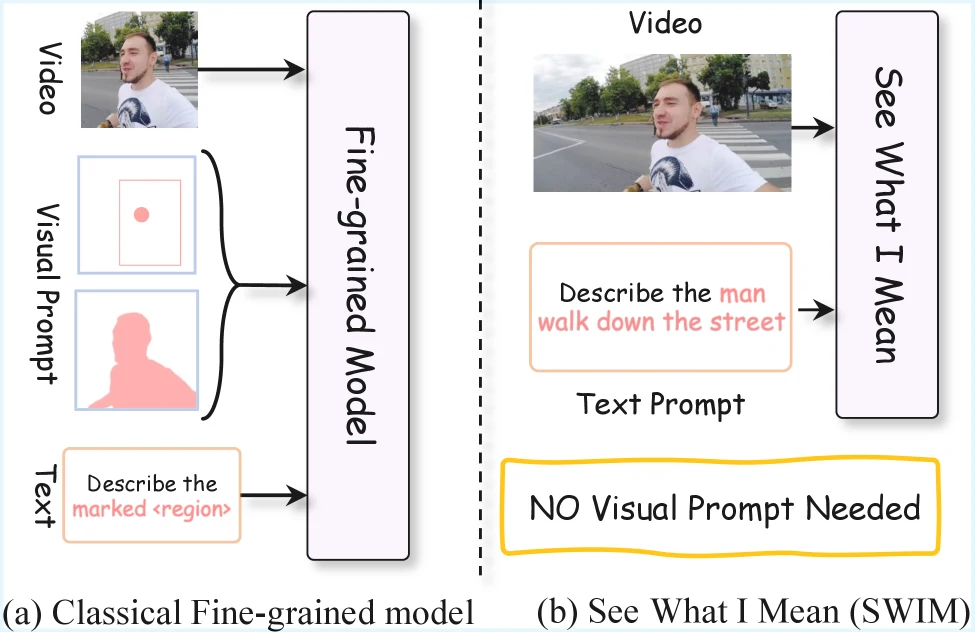
논문 Figure 1.
기존 fine-grained model은 비디오와 함께 visual prompt를 요구하지만, SWIM은 자연어 설명만으로 대상 객체를 가리키는 방향을 목표로 한다.
무엇을 해결하려는가
일반적인 VLM은 이미지나 비디오 전체를 설명하는 데는 강해졌지만, 사용자가 지정한 특정 객체를 안정적으로 따라가는 데는 아직 흔들린다.
특히 영상 안에 비슷한 객체가 여러 개 있거나, 대상이 시간에 따라 움직이거나, 질문이 “그 객체의 행동/상태/관계”를 묻는 경우에는 전역 캡션 능력만으로 부족하다.
기존 object-centric 방법들은 이 문제를 점, 박스, 마스크 같은 명시적 시각 신호로 풀었다.
시각 프롬프트는 강력하지만 인터페이스 비용이 크다.
사용자가 영상에서 객체를 먼저 선택해야 하고, 모델 구조도 region encoder나 추가 모듈에 의존하기 쉽다.
SWIM의 문제 정의는 여기서 다르다.
사용자는 자연어로만 객체를 가리키고, 모델 내부의 언어-시각 정렬이 그 지칭을 실제 영상 영역에 붙일 수 있어야 한다는 것이다.
논문이 흥미로운 이유는 이 실패를 단순히 “모델이 약하다”로 보지 않는다는 점이다.
저자들은 Qwen2.5-VL의 cross-attention을 시각화해, 색·질감 같은 attribute word는 비교적 뚜렷한 시각 영역에 붙는 반면 object noun은 더 넓고 산만하게 퍼지는 패턴을 보인다.
즉 “brown”, “striped” 같은 속성 단어는 낮은 수준의 시각 패턴과 잘 연결되지만, “man”, “object” 같은 명사는 다양한 맥락에 등장해 공간적 대응이 흐려진다는 해석이다.
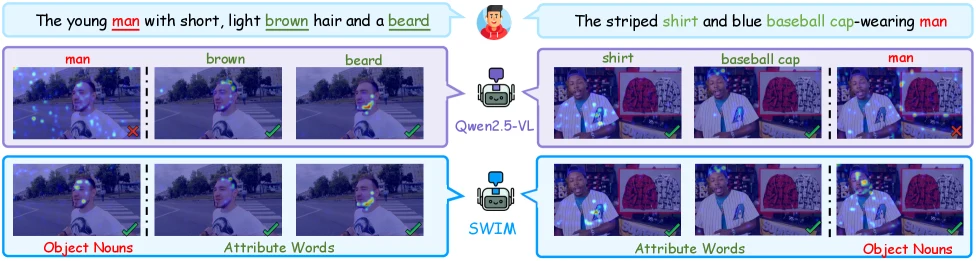
논문 Figure 2.
Qwen2.5-VL에서는 attribute word가 더 국소적인 attention을 만들고, object noun은 산만하게 퍼지는 경향이 관찰된다.
SWIM은 이 지점을 학습 신호로 직접 보정한다.
핵심 아이디어 / 구조 / 동작 방식
SWIM의 첫 번째 구성 요소는 NL-Refer다.
원래 VideoRefer-700K는 <objectx><region> 같은 placeholder와 visual prompt를 이용해 객체를 지정한다.
SWIM은 GPT-4o 기반 refinement pipeline으로 이 placeholder를 “짧고 모호하지 않은 자연어 지칭 표현”으로 바꾸고, 그중 핵심 객체 단어를 <ins>...</ins> 태그로 감싼다.
이렇게 하면 하나의 학습 예제는 비디오, 자연어 지칭 표현, 원래의 객체 mask를 함께 갖게 된다.
두 번째 구성 요소는 attention regularization이다.
SWIM은 Qwen2.5-VL-7B 기반 모델을 학습하면서 중간 layer들의 text-to-vision cross-attention map을 꺼낸다.
GitHub README의 코드 가이드에 따르면 공개 구현은 [2, 7, 12, 17, 22, 27] layer에서 attention을 추출·융합하고, <ins>로 표시된 entity token과 ground-truth instance mask를 짝지어 BCE loss를 계산한다.
최종 loss는 표준 텍스트 생성 loss와 mask attention loss를 결합하는 형태다.
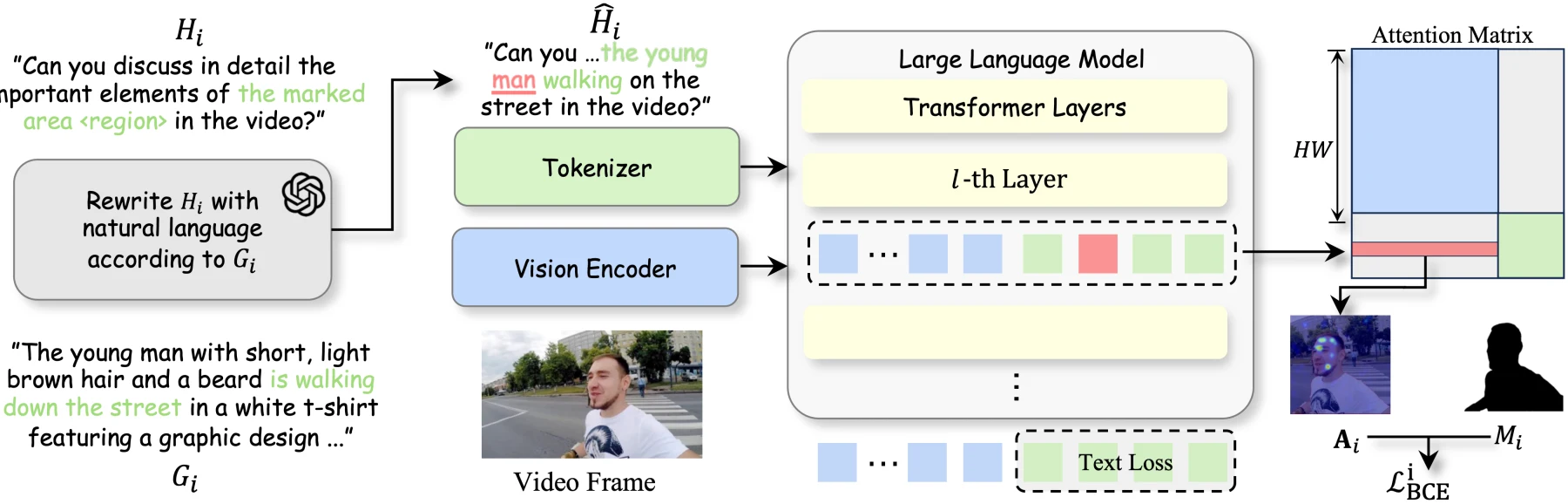
공식 GitHub/Hugging Face 자산의 SWIM pipeline.
VideoRefer의 visual-prompt 기반 표기를 자연어 지칭 표현으로 바꾸고, 지칭 토큰의 cross-attention이 해당 객체 mask와 맞도록 학습한다.
훈련 데이터도 이 설계와 맞물려 있다.
논문은 NL-Refer-D로 정리한 VideoRefer-700K 상세 캡션 subset 125K개, LLaVA-Video-178K에서 추출한 single-turn QA 100K개, videorefer-qa-75k에서 샘플링한 10K개를 합쳐 총 235K 예제를 사용했다고 설명한다.
모델 쪽은 Qwen2.5-VL-7B 구조를 바탕으로 하며, README는 SigLIP vision encoder와 Qwen2.5-7B-Instruct LLM decoder를 포함한 Qwen2.5-VL 계열로 설명한다.
이 구조의 중요한 해석은 “새로운 segmentation model을 붙인다”가 아니라는 점이다.
SWIM은 추론 시 추가 마스크 입력이나 region encoder를 요구하지 않는다.
대신 학습 중 attention 자체가 객체 지칭과 시각 영역을 더 강하게 맞추도록 압력을 주고, 그 정렬을 자연어 지시 기반 비디오 이해로 가져오려 한다.
공개된 근거에서 확인되는 점
주요 결과는 VideoRefer-Bench-Q와 VideoRefer-Bench-D에서 제시된다.
논문 Table 1 기준 SWIM은 VideoRefer-Bench-Q 평균 78.3을 기록해 Qwen2.5-VL-7B의 71.8, GPT-4o의 71.3, VideoRefer-7B의 71.9보다 높다.
VideoRefer-Bench-D 평균도 3.78로, Qwen2.5-VL-7B의 3.24와 visual prompt를 쓰는 VideoRefer-7B의 3.46보다 높게 제시된다.
| 모델 | 프롬프트 유형 | VideoRefer-Bench-Q Avg. | VideoRefer-Bench-D Avg. | 해석 |
|---|---|---|---|---|
| Qwen2.5-VL-7B | Text | 71.8 | 3.24 | 강한 generalist VLM이지만 객체 지칭 정렬은 제한적 |
| GPT-4o | Text | 71.3 | 3.25 | 폐쇄형 generalist 모델도 fine-grained target tracking에서는 압도적이지 않음 |
| VideoRefer-7B | Mask | 71.9 | 3.46 | visual prompt를 쓰는 specialist baseline |
| SWIM | Text | 78.3 | 3.78 | visual prompt 없이 자연어 지칭만으로 가장 높은 평균 |
일반 비디오 이해 벤치마크에서도 완전히 무너지지는 않는다.
같은 표의 하단 결과에서 SWIM은 MVBench 62.1, VideoMME 55.9, ActivityNetQA 55.6을 보고한다.
이 수치는 SWIM이 fine-grained object task에 과도하게 맞춰져 일반 비디오 QA 능력을 잃었다기보다, Qwen2.5-VL 기반의 일반 능력을 어느 정도 유지하면서 객체 지칭 정렬을 보강했다는 근거로 읽을 수 있다.
스케일링 실험도 중요하다. mask annotation을 30K, 50K, 80K, 100K, 125K로 늘릴수록 VideoRefer-D 점수가 3.27에서 3.78까지 올라가며, 125K 지점에서도 명확한 plateau가 보이지 않는다.
저자들은 더 크고 다양한 mask-annotated corpus가 있으면 SWIM류 attention supervision이 추가 이득을 얻을 가능성이 있다고 해석한다.
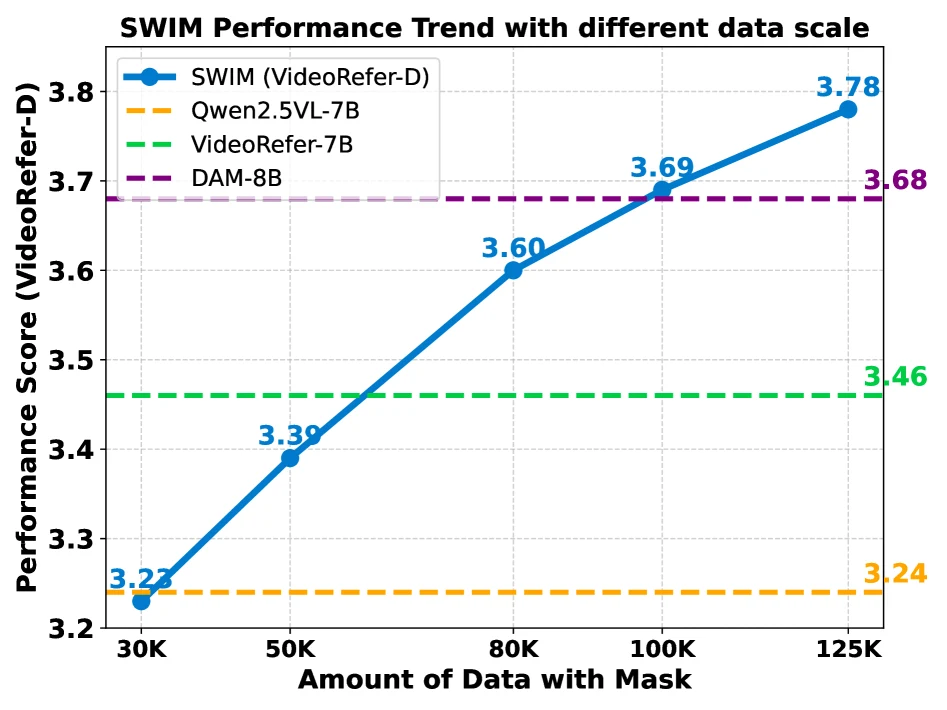
논문 Figure 4. mask가 붙은 학습 데이터를 늘릴수록 SWIM의 VideoRefer-D 점수가 꾸준히 상승한다.
125K에서도 포화가 뚜렷하지 않다는 점이 핵심이다.
정렬 자체를 보는 지표도 제시된다.
GamePoint@P에서는 attention score가 가장 높은 시각 위치가 실제 객체 mask 안에 들어가는지를 본다.
Table 6 기준 SWIM은 P=1/5/10 모두에서 Qwen2.5-VL-7B보다 높다.
Figure 6의 AP, AUC, NSS, Precision 비교도 SWIM이 baseline보다 더 집중된 target-region attention을 만든다는 방향을 보여 준다.
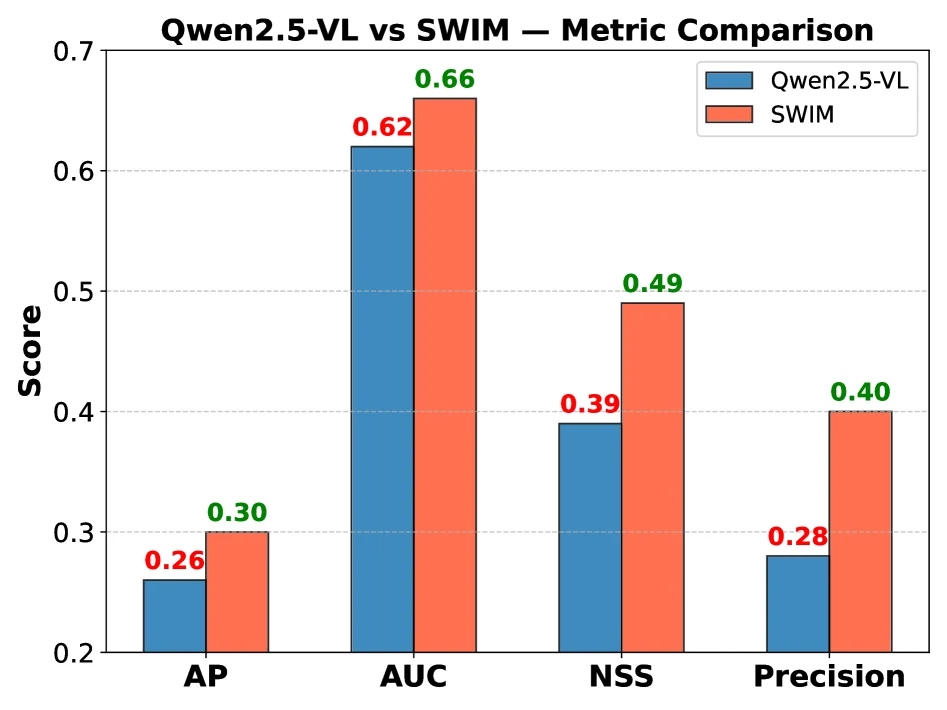
논문 Figure 6.
SWIM은 Qwen2.5-VL baseline보다 AP, AUC, NSS, Precision 전반에서 더 높은 text-visual alignment 지표를 보인다.
정성 예시도 같은 메시지를 준다.
Qwen2.5-VL은 질문 속 객체 지칭을 다른 객체나 배경으로 잘못 붙이는 경우가 있고, SWIM은 동일한 텍스트 지시에서 더 맞는 선택지를 고르는 사례를 보인다.
물론 이런 그림은 대표 사례이므로 일반화는 benchmark table과 함께 읽어야 하지만, 방법이 겨냥하는 실패 모드는 꽤 분명하다.

논문 Figure 5.
자연어로 지정된 target object를 놓치는 baseline과, 더 정확히 대상 객체를 따라가는 SWIM의 정성 비교.
공개 릴리스도 paper-only는 아니다.
GitHub HumanMLLM/SWIM은 2026-05-18 생성된 공식 코드 저장소이며, 2026-05-25 조회 기준 stars 80, forks 0, formal release와 tag는 아직 없다.
루트에는 README, Q-R1, 수정된 transformers, assets가 있고, README는 custom Transformers fork를 설치해야 attention supervision 경로를 쓸 수 있다고 명시한다.
Hugging Face에는 BBBBCHAN/SWIM-7B 모델과 BBBBCHAN/NL-Refer 데이터셋이 공개되어 있으며, 모델 repo는 4개 safetensors shard와 Qwen2.5-VL config, tokenizer, chat template을 포함한다.
| 공개 표면 | 확인되는 내용 | 실무 해석 |
|---|---|---|
| arXiv paper / HTML | 방법, Figure, benchmark table, ablation | 실험 주장과 정렬 지표의 1차 근거 |
GitHub HumanMLLM/SWIM |
Q-R1 기반 학습 코드, 수정된 Transformers, 평가 스크립트, pipeline asset | 단순 placeholder가 아니라 연구 artifact 형태의 코드 공개 |
Hugging Face BBBBCHAN/SWIM-7B |
Qwen2.5-VL 계열 7B 모델, safetensors 4 shards, video-text-to-text tag | 표준 Qwen2.5-VL 로딩 경로로 시험 가능한 모델 카드 |
Hugging Face BBBBCHAN/NL-Refer |
train/bench annotation, construction scripts, CC-BY-NC-4.0 card | 원본 비디오는 별도 다운로드가 필요한 annotation 중심 데이터셋 |
| 라이선스 / 성숙도 | README와 HF card는 CC BY-NC 4.0 계열, GitHub API license는 null, release/tag 없음 | 비상업·연구용 공개에 가깝고 production dependency로는 추가 검토 필요 |
실무 관점에서의 해석
SWIM의 실무적 의미는 “VLM이 객체를 더 잘 본다”보다 조금 더 구체적이다.
많은 멀티모달 제품에서 사용자는 객체를 화면에서 직접 선택하기보다 말로 지정한다.
“왼쪽 아이가 들고 있는 물건”, “아까 지나간 빨간 차”, “파란 모자를 쓴 사람” 같은 지시는 텍스트 인터페이스의 기본 단위다.
그런데 모델 내부에서 object noun이 시각 영역에 약하게 붙는다면, 아무리 전체 장면 이해가 좋아도 targeted reasoning은 흔들릴 수 있다.
SWIM은 이 문제를 post-hoc grounding 모듈로 보정하지 않고, 학습 중 attention 자체를 object mask와 맞춘다.
이 접근은 데이터가 있으면 비교적 직접적이다.
기존 visual-prompt dataset의 mask를 버리지 않고, 그 mask를 자연어 지칭 표현과 연결하는 supervision으로 재활용한다.
따라서 “마스크가 필요한 모델”에서 “마스크로 학습한 뒤 텍스트만 받는 모델”로 넘어가는 중간 다리로 볼 수 있다.
다만 한계도 분명하다.
첫째, 좋은 지칭 표현과 mask가 함께 있는 데이터가 필요하다.
NL-Refer는 이 문제를 GPT-4o refinement로 풀지만, 도메인이 바뀌면 표현 품질과 mask coverage가 다시 병목이 될 수 있다.
둘째, 공개 구현은 custom Transformers fork와 Q-R1 기반 구조를 포함하므로, 일반적인 pip install transformers 생태계에 그대로 얹는 경량 adapter라고 보기는 어렵다.
셋째, 논문의 핵심 benchmark는 VideoRefer 계열 fine-grained object task에 강하게 맞춰져 있으므로, 장시간 비디오, dense multi-object tracking, safety-critical surveillance 같은 배포 시나리오까지 바로 확장된다고 읽으면 과장이다.
그래도 방향은 중요하다.
멀티모달 모델의 다음 병목 중 하나는 더 큰 이미지 encoder만이 아니라 언어가 가리키는 대상과 시각 token이 실제로 어디서 만나는가다.
SWIM은 이 만남을 attention map과 mask의 supervised alignment로 드러내고, 자연어만으로 특정 비디오 객체를 다루는 쪽으로 모델을 밀어붙인다.
앞으로 더 큰 mask-text corpus, 더 다양한 지칭 표현, 그리고 long video memory와 결합되면, VLM의 “전체 장면 설명”과 “사용자가 의미한 그 객체 이해” 사이의 간극을 줄이는 중요한 학습 패턴이 될 수 있다.