긴 문맥 LLM에서 attention은 더 이상 교과서적인 Transformer 블록 한 줄로 끝나지 않는다.
컨텍스트가 길어질수록 모든 과거 토큰을 매번 다시 보는 비용이 커지고, KV cache는 메모리와 bandwidth를 동시에 압박한다.
그래서 최근 모델들은 full attention을 그대로 키우기보다 sliding window, latent attention, KV sharing, sparse selection 같은 비용 절감 장치를 섞기 시작했다.
Sebastian Raschka의 rasbt/LLMs-from-scratch 저장소에 추가된 ch04/09_dsa는 이 변화 중 하나인 DeepSeek Sparse Attention(DSA) 을 교육용 GPT 구현으로 낮춘 bonus material이다.
이 폴더는 DeepSeek-V3.2 / V3.2-Exp에서 소개된 DSA를 작은 PyTorch 코드로 재구성한다.
중요한 점은 이 코드가 DeepSeek 전체 모델을 복제하는 것이 아니라, DSA의 “과거 토큰을 learned scorer로 고르고 top-k만 attention에 남긴다”는 핵심 선택 로직을 inspectable하게 만든다는 데 있다.
이 자료의 가치는 성능 숫자보다 추상화 경계에 있다.
논문·모델 카드에서는 DSA가 long-context 비용을 줄이는 구조로 설명되지만, 실제로는 indexer, top-k selector, causal mask, attention softmax, KV cache가 맞물려야 한다.09_dsa는 그 연결부를 500줄 안팎의 코드와 테스트로 보여 주기 때문에, “sparse attention이 대략 무엇인지”가 아니라 어디에서 sparse해지고, 어디에서는 여전히 dense하게 계산되는지를 확인하기 좋다.
무엇을 해결하려는가
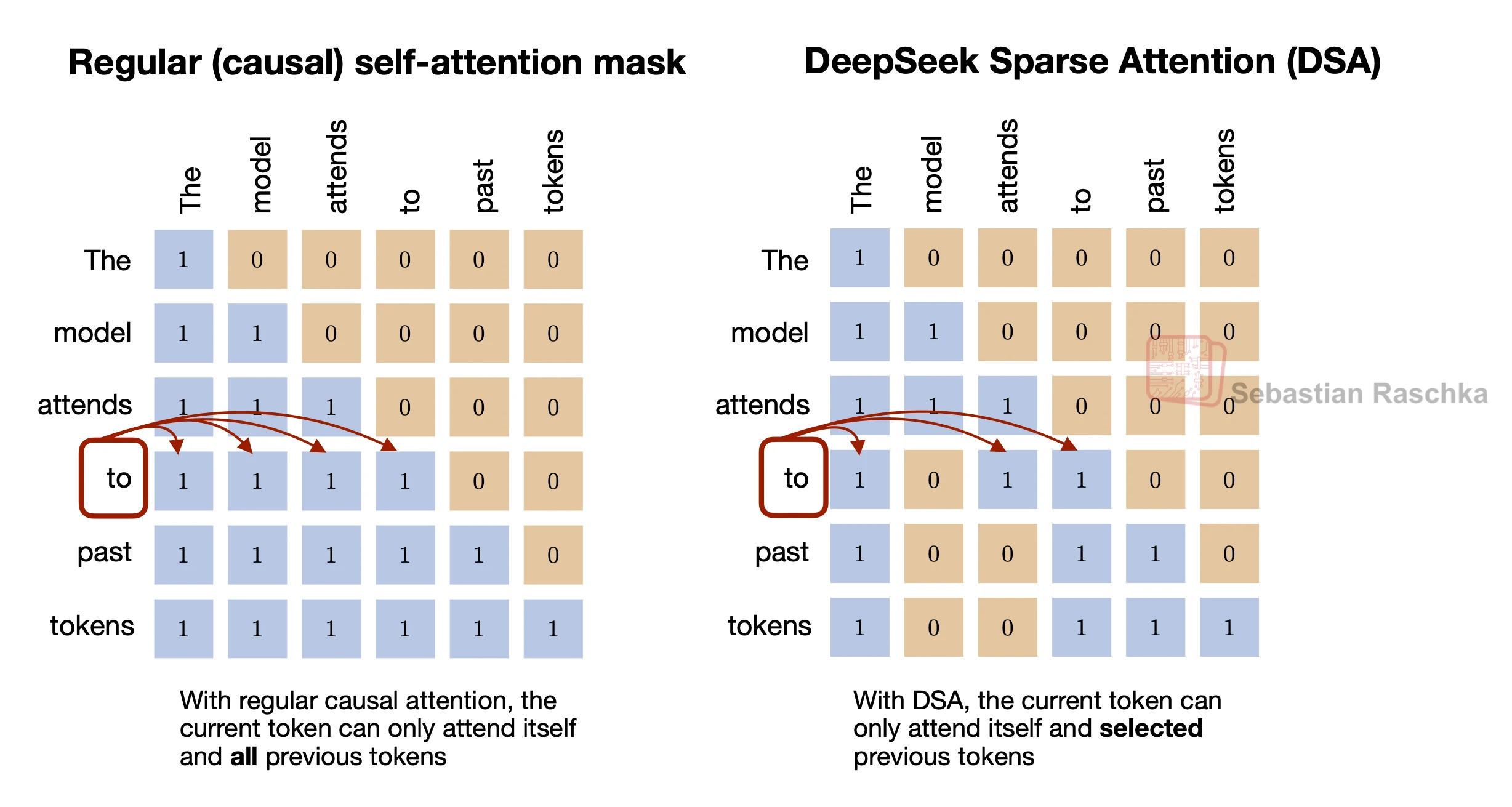
표준 causal self-attention은 query마다 이전 모든 key/value와 점수를 계산한다. sequence length를 L이라고 하면 attention score matrix는 대략 O(L²)로 커지고, 생성 단계에서는 이전 토큰의 K/V를 계속 저장하고 읽어야 한다.
짧은 문맥에서는 단순함이 장점이지만, 128K 이상의 context, 긴 tool trace, repository-scale coding context, reasoning trace가 붙는 순간 이 비용은 제품 latency와 serving 비용으로 바로 드러난다.
Sliding Window Attention(SWA)은 이 문제를 고정된 local window로 줄인다.
가까운 토큰만 본다는 단순한 규칙 덕분에 비용은 예측 가능해지지만, 멀리 있는 중요한 토큰을 놓칠 수 있다.
DSA의 방향은 조금 다르다. window를 고정하지 않고, query마다 “지금 이 query에 유용해 보이는 과거 토큰”을 learned indexer가 점수화한 뒤 top-k만 남긴다.
즉 고정된 거리 기반 sparsity가 아니라, learned relevance 기반 sparsity다.
LLMs-from-scratch의 09_dsa가 해결하려는 문제도 여기에 있다. production DeepSeek 구현은 MLA, FP8, sparse kernel, 분산 inference stack까지 얽혀 있어 곧바로 읽기 어렵다.
반면 이 폴더는 Chapter 4의 GPT 구현 스타일을 유지하면서 DSA만 끼워 넣는다.
학습용 독자는 attention 대체 기법을 black box로 소비하지 않고, 기존 GPT block의 어느 지점에 어떤 mask가 들어가는지 따라갈 수 있다.
핵심 아이디어 / 구조 / 동작 방식
폴더의 공개 표면은 작다.README.md가 DSA 배경과 사용법을 설명하고, gpt_with_kv_dsa.py가 standalone GPT 구현을 제공하며, test_dsa.py가 shape, causality, sparsity, reference alignment, KV cache consistency를 검증한다.
저장소 전체는 Build a Large Language Model (From Scratch) 책의 공식 코드 저장소이고, 이 DSA 폴더는 Chapter 4의 attention alternatives 계열 bonus material이다.
핵심 클래스는 세 가지로 정리된다.
| 구성 요소 | 코드상 역할 | 해석 |
|---|---|---|
LightningIndexer |
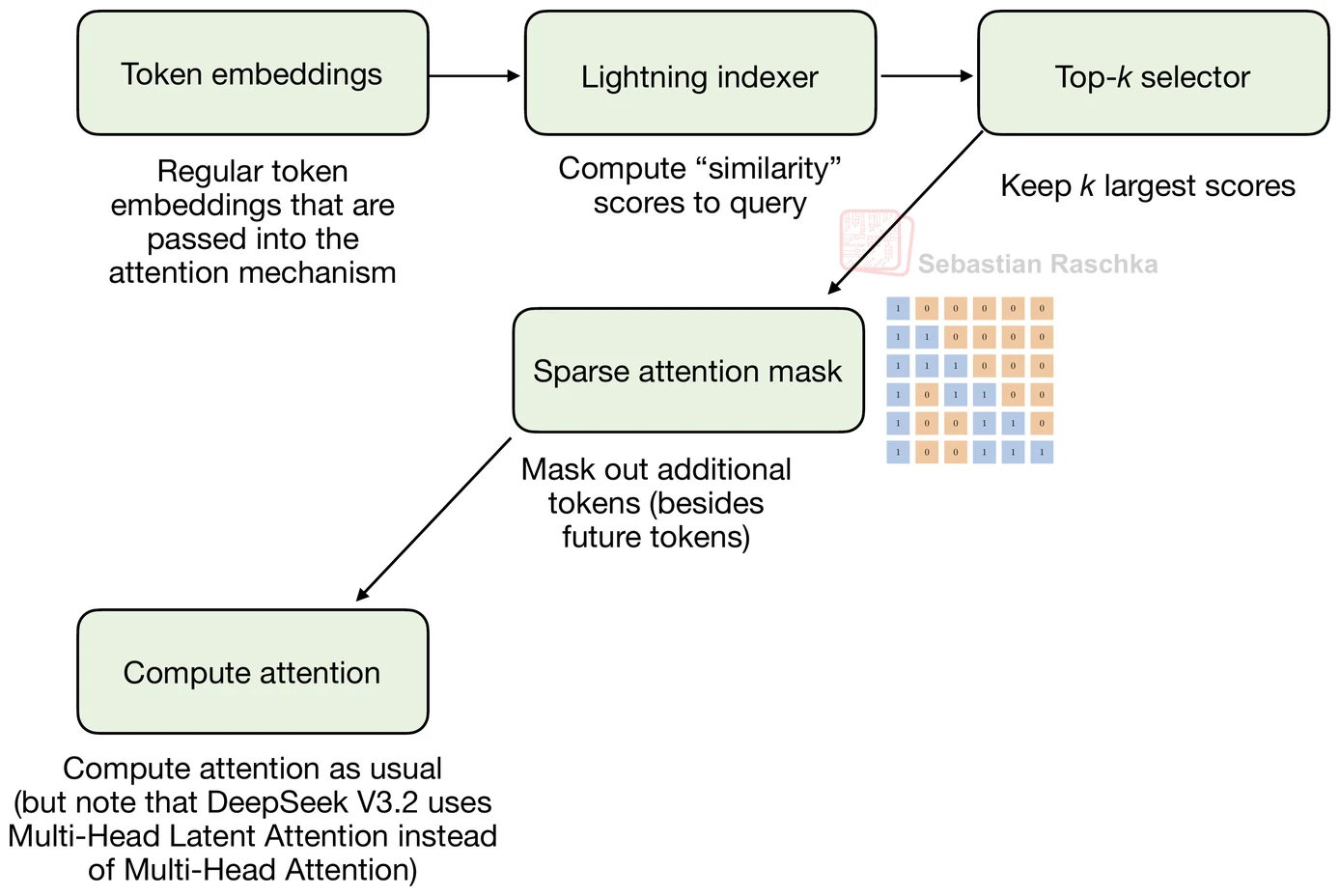
현재 token query와 과거 token key 사이의 relevance score를 계산하고 top-k index를 반환 | DSA의 learned selector에 해당한다. ReLU dot product와 per-head gate를 쓰지만, 최종 sparsity는 top-k 선택에서 생긴다. |
MultiHeadAttentionWithDSA |
표준 MHA score matrix를 만든 뒤 DSA top-k mask와 causal mask를 합쳐 softmax 전에 적용 | 교육용 구현에서는 dense attention score를 먼저 계산한다. 따라서 선택 로직은 보이지만 fused sparse kernel의 실제 O(L·k) 절감은 재현하지 않는다. |
GPTModel |
기존 GPT block 안의 attention을 MultiHeadAttentionWithDSA로 교체 |
Chapter 4 스타일의 작은 GPT에서 DSA가 어디에 들어가는지 보여 주는 wrapper다. |
LightningIndexer는 입력 hidden state에서 세 종류의 projection을 만든다. query 쪽은 index_n_heads * index_head_dim 차원으로, key 쪽은 shared index_head_dim으로, gate 쪽은 index head 수만큼의 scalar로 보낸다.
그다음 각 query token t와 candidate past token s에 대해 대략 다음 형태의 점수를 계산한다.
ReLU(q · k / sqrt(d_I))를 index head별로 만들고, learned gate w를 1 / sqrt(H_I)로 스케일한 뒤 head 방향으로 합산한다.
README가 강조하듯 ReLU 자체가 최종 sparse pattern을 만드는 것은 아니다.
여러 head 점수를 합치면 대부분의 위치가 여전히 nonzero일 수 있다.
실제 sparsity는 index_scores.topk(k)로 상위 k개 위치만 남길 때 만들어진다.
MultiHeadAttentionWithDSA의 구현은 의도적으로 투명하다.
먼저 일반 attention처럼 Q/K/V projection을 만들고 queries @ keys.T로 full score matrix를 계산한다.
이후 query position과 key position으로 causal mask를 만들고, indexer가 고른 top-k 위치에는 0, 나머지에는 -inf를 채운 sparse mask를 scatter_로 구성한다.
마지막으로 causal mask와 sparse mask를 더해 softmax 전에 score에 적용한다.
KV cache도 단순히 K/V만 저장하지 않는다. indexer가 과거 token hidden state에서 key projection을 다시 만들 수 있어야 하므로 cache_x도 함께 유지한다. cached generation에서는 prompt 전체로 cache를 초기화한 뒤 새 token만 다시 넣고, non-cached mode에서는 매 step 전체 context를 다시 계산한다.
테스트는 topk를 충분히 크게 잡으면 sparse mask가 사실상 full attention이 되어 dense reference와 같은 결과가 나오는지도 확인한다.
공개된 근거에서 확인되는 점
GitHub API와 raw 파일 기준으로 ch04/09_dsa는 2026년 5월 23일 Add Deepseek Sparse Attention (DSA) implementation (ch04/09_dsa) (#1014) 커밋으로 추가된 최근 bonus 폴더다.
폴더에는 README.md, gpt_with_kv_dsa.py, test_dsa.py 세 파일이 있고, gpt_with_kv_dsa.py는 약 495줄, test_dsa.py는 약 194줄이다.
저장소 전체는 조회 시점 기준 약 95.8k stars와 14.7k forks를 가진 대형 교육용 코드베이스지만, GitHub Releases와 tags는 비어 있다.
따라서 이 폴더는 installable inference framework라기보다 책/강의 흐름 안에 들어온 architecture study artifact로 보는 편이 정확하다.
라이선스도 repo metadata만 보고 단정하면 안 된다.
GitHub API의 license field는 NOASSERTION에 가깝게 잡히지만, repository의 LICENSE.txt는 Apache License 2.0을 담고 있고 책·관련 이미지에 대한 제외 조항을 포함한다.
코드 파일 상단도 Sebastian Raschka의 Apache License 2.0 copyright notice를 갖는다.
즉 코드 재사용성과 이미지/책 자료의 권리 범위는 구분해서 읽어야 한다.
DeepSeek 쪽 공개 표면과의 관계도 분명하다.
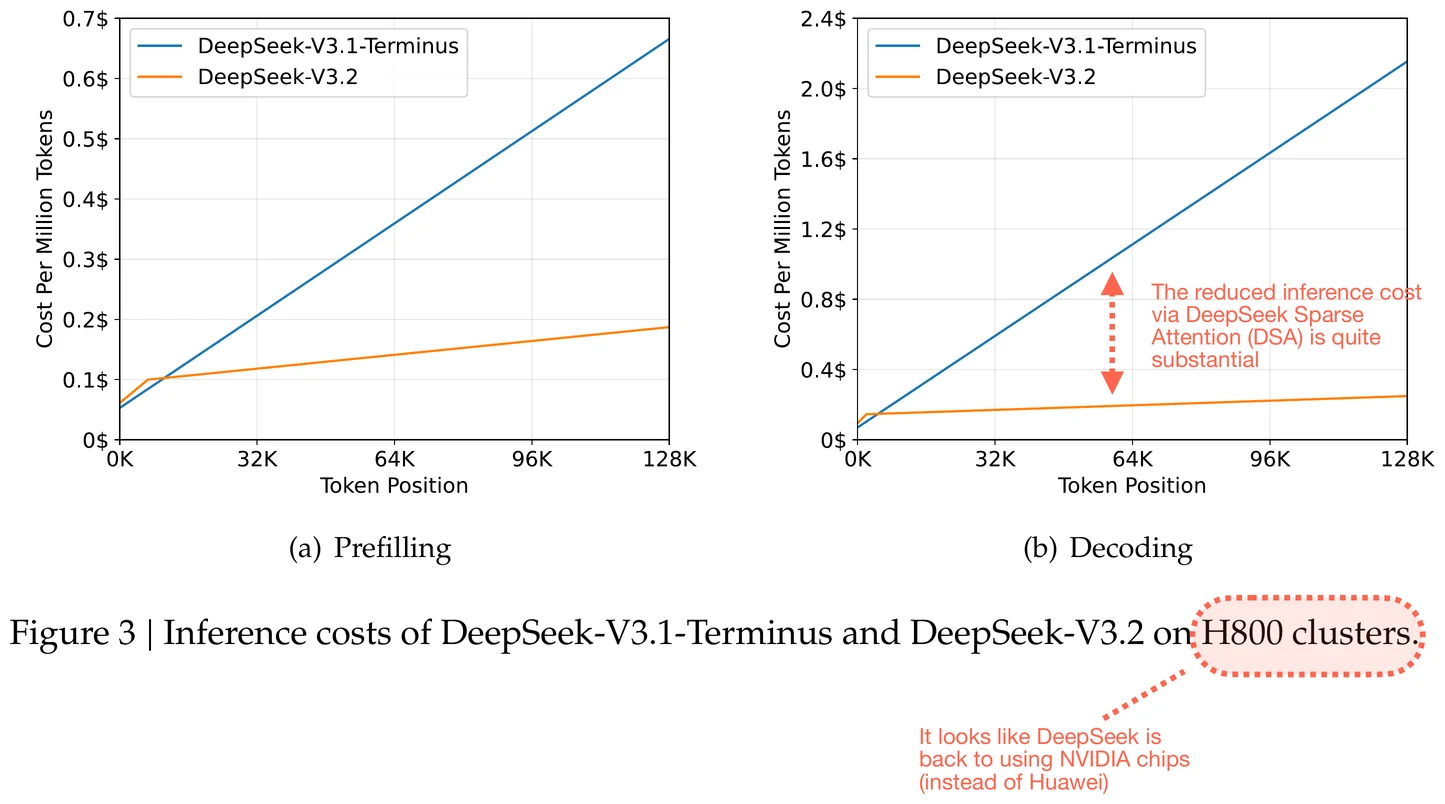
DeepSeek-V3.2-Exp model card는 V3.1-Terminus 위에 DSA를 도입한 experimental release라고 설명하며, DSA가 long-context training/inference efficiency를 높이면서 모델 성능을 거의 유지하는 방향이라고 적는다.
DeepSeek-V3.2 model card도 DSA를 long-context serving에 최적화된 효율적 attention mechanism으로 소개한다.
Hugging Face API상 V3.2 / V3.2-Exp 모두 MIT license tag, transformers, text-generation, FP8 관련 tag와 inference/config 파일을 포함하는 공개 release surface를 갖고 있다.
다만 09_dsa는 그 전체 surface를 그대로 옮기지 않는다.
README가 명시하듯 DeepSeek의 full-scale 모델은 Multi-Head Latent Attention(MLA)와 DSA를 함께 쓰고, indexer query도 compressed latent representation에서 나온다.
반면 이 폴더는 regular hidden state에서 indexer query/key를 만들고, dense attention matrix를 계산한 뒤 mask를 적용한다.
그러므로 다음 구분이 중요하다.
| 확인 항목 | 09_dsa에서 확인되는 사실 |
실무적 해석 |
|---|---|---|
| DSA 핵심 선택 로직 | Lightning indexer → top-k token selector → sparse mask | sparse attention이 “어떤 token을 남기는가”를 코드로 읽기 좋다. |
| Attention 계산 방식 | full score matrix를 만든 뒤 mask를 적용 | production sparse kernel의 계산량 절감까지 보여 주지는 않는다. |
| DeepSeek full architecture | MLA, FP8 kernel, 분산 serving stack은 제외 | DeepSeek-V3.2 재현이 아니라 DSA 개념 교육용 축소판이다. |
| 테스트 범위 | output shape, causal property, sparsity, Transformers DSA indexer path alignment, cache consistency, full-attention equivalence | 작은 구현으로서의 정확성 체크는 충실하지만, 학습·성능 benchmark는 아니다. |
| 실행 방식 | uv run gpt_with_kv_dsa.py --index_n_heads 4 --index_head_dim 64 --topk 64 등 CLI 인자 제공 |
architecture knob를 바꿔 보기에 좋지만, checkpoint 배포나 serving package는 아니다. |
실무 관점에서의 해석
이 예제의 가장 큰 장점은 frontier architecture를 “읽을 수 있는 작은 코드”로 바꾼다는 점이다. sparse attention은 이름만 보면 단순히 몇몇 attention weight를 0으로 만드는 기법처럼 보이지만, 실제 구현에서는 어떤 hidden state로 index score를 만들지, top-k를 causal 제약과 어떻게 합칠지, KV cache가 있을 때 indexer context를 어떻게 유지할지 같은 세부가 중요하다.09_dsa는 바로 그 접합부를 보여 준다.
특히 long-context inference를 다루는 팀에는 좋은 mental model을 준다.
비용 절감은 하나의 마법 같은 trick이 아니라, “모든 token을 항상 full precision으로 본다”는 기본값을 어디서 깨는지의 문제다.
SWA는 거리로 깨고, KV sharing은 layer 간 상태 중복으로 깨고, MLA는 representation dimension으로 깨며, DSA는 query별 token selection으로 깬다.
이 관점에서 DSA는 attention의 정보 선택 문제를 모델 내부의 learned scorer로 옮기는 설계라고 볼 수 있다.
반대로 이 코드를 production 성능 근거로 쓰면 안 된다.09_dsa는 sparse mask를 만들기 전에 이미 dense attention score matrix를 계산한다. indexer도 모든 candidate past token을 점수화한다.
실제 serving 비용을 줄이려면 sparse kernel, memory layout, page cache, batching, compiler/runtime support가 함께 있어야 한다.
DeepSeek-V3.2의 비용 절감은 그 전체 stack의 결과이지, Python-level mask 하나만으로 자동 재현되는 것이 아니다.
그래도 이 한계는 단점이라기보다 교육용 artifact의 정직함에 가깝다. production 최적화를 걷어 내면 DSA가 어떤 abstraction boundary를 추가하는지 더 잘 보인다.
기존 attention block에 “먼저 relevance를 예측하고, 그 예측으로 softmax 후보군을 줄인다”는 작은 정책 네트워크가 들어간다.
그리고 KV cache가 있을 때는 attention용 K/V뿐 아니라 indexer가 과거 토큰을 다시 평가할 수 있는 context 표현도 설계해야 한다.
결국 LLMs-from-scratch의 DSA bonus material은 “DeepSeek를 집에서 재현한다”가 아니라, DeepSeek식 long-context efficiency 아이디어를 GPT 내부 구조 위에서 해부한다에 가깝다.
최신 LLM 아키텍처를 따라가는 데 필요한 것은 모델 이름을 외우는 것이 아니라, 비용 축이 어디에서 바뀌는지 읽는 능력이다.
이 폴더는 DSA라는 하나의 사례를 통해 그 읽는 법을 꽤 좋은 밀도로 보여 준다.