긴 컨텍스트 모델의 병목은 이제 단순히 “창을 얼마나 크게 만들 것인가”가 아니다.
128K 이상 문맥에서 Transformer는 attention의 정확한 기억력을 유지하지만, KV cache와 decode bandwidth가 serving 비용을 빠르게 밀어 올린다.
반대로 State Space Model(SSM)은 과거를 압축된 recurrent state로 유지할 수 있지만, 모든 정보를 같은 fidelity로 붙잡는 full attention과는 다른 손실을 감수해야 한다.
Priming: Hybrid State Space Models From Pre-trained Transformers는 이 둘을 섞는 Hybrid architecture를 다시 본다.
핵심은 Hybrid 모델을 처음부터 pretraining하지 않고, 이미 학습된 Transformer에서 출발해 일부 attention layer를 SSM layer로 치환한 뒤 짧은 alignment와 task adaptation으로 품질을 회복하는 것이다.
논문은 이 과정을 Priming이라고 부르고, source model pretraining token budget의 0.5% 미만으로 downstream 품질을 되살릴 수 있다고 주장한다.
이 접근이 흥미로운 이유는 성능 숫자 하나보다 더 구조적이다.
Hybrid SSM 연구의 큰 장벽은 “어떤 layer를 어떤 SSM으로 바꿀지”를 대규모로 실험하려면 매번 새 모델을 pretrain해야 한다는 점이었다.
Priming은 이 문제를 architecture pretraining이 아니라 사전학습 Transformer에서 Hybrid 모델로 지식을 옮기는 문제로 바꾼다.
실제로 저자들은 Qwen3 기반 8B/32B Hybrid 모델 zoo, training/inference code, vLLM serving plugin을 함께 공개했다.
무엇을 해결하려는가
Hybrid 모델의 직관은 간단하다.
Attention layer는 eidetic memory, 즉 최근·정확한 token-level 상호작용을 잘 보존한다.
SSM layer는 fading memory, 즉 긴 과거를 고정 크기 상태에 압축해 더 싸게 전달한다.
긴 agent trace, retrieval-augmented reasoning, 장문 코드/문서 처리에서는 두 종류의 기억이 모두 필요하다.
모든 layer가 full attention이면 비싸고, 모든 layer가 recurrent state면 정확한 위치 기반 기억이 약해질 수 있다.
문제는 설계 공간이 너무 크다는 데 있다.
몇 번째 layer를 SSM으로 바꿀지, SSM layer로 Mamba-2, Gated DeltaNet(GDN), Gated KalmaNet(GKA), B’MOJO-F 중 무엇을 쓸지, GQA head 구조를 어떻게 맞출지, long-context adaptation을 어떤 순서로 할지 모두 성능에 영향을 준다.
지금까지는 이 설계 공간을 제대로 탐색하려면 모델을 scratch로 학습해야 했고, 그래서 대규모 Hybrid 연구는 소수 architecture에 갇히기 쉬웠다.
Priming의 목표는 이 병목을 줄이는 것이다.
이미 좋은 Transformer가 있다면, 그 모델의 knowledge와 tokenizer, embedding, feed-forward layer, 일부 attention layer를 보존하고, long-context serving에서 비싼 일부 attention layer만 SSM으로 대체한다.
즉 “새로운 foundation model을 처음부터 만든다”가 아니라 기존 Transformer의 계산 그래프를 Hybrid로 재배선한 뒤 품질을 정렬한다는 문제로 바꾼다.
핵심 아이디어 / 구조 / 동작 방식
Priming pipeline은 세 단계로 읽으면 된다.
먼저 Stage 0에서는 source Transformer의 parameter를 Hybrid student로 옮긴다. attention을 유지하는 layer는 그대로 가져오고, SSM으로 바뀌는 layer에는 query/key/value projection, output projection, gating projection 등을 가능한 범위에서 초기화한다.
GQA 구조가 맞지 않는 경우에는 Adaptive GQA(AGQA)로 state width를 확장해 SSM layer가 더 많은 key-value 정보를 쓸 수 있게 한다.
그다음 Stage 1은 layerwise alignment다.
논문은 teacher Transformer와 student Hybrid를 하나의 fused architecture 안에 같이 두고, SSM으로 바뀐 layer마다 teacher attention output과 student SSM output을 맞춘다.
Stage 2에서는 long-context instruction tuning이나 reasoning SFT 같은 task adaptation을 수행한다.
이 순서 덕분에 Hybrid student는 처음부터 무작위로 긴 학습을 시작하지 않고, source Transformer의 기능을 가능한 한 유지한 상태에서 SSM layer를 학습한다.
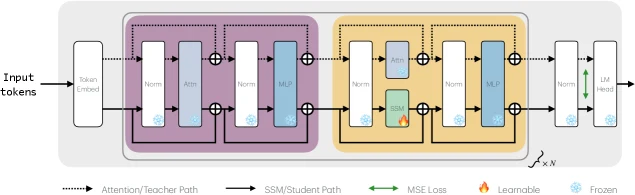
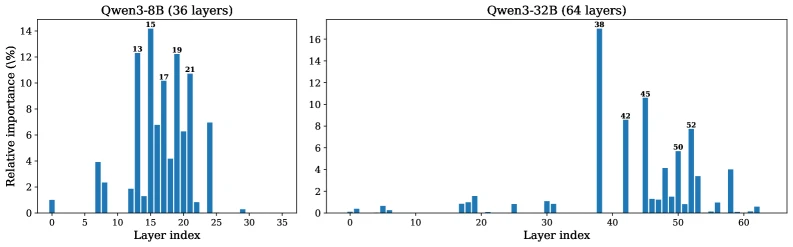
Layer 선택도 단순히 균등하게 반반 바꾸는 방식이 아니다.
저자들은 각 attention layer를 sliding-window attention으로 하나씩 바꿨을 때 HELMET 계열 long-context score가 얼마나 떨어지는지 측정해 layer importance를 구한다.
성능 손실이 큰 layer는 attention으로 남기고, 상대적으로 덜 중요한 layer를 SSM으로 바꾸는 selective pattern을 쓴다.
논문은 Qwen3-8B와 Qwen3-32B 모두에서 중요도가 일부 중후반 layer에 몰린다고 보고한다.
SSM layer 쪽의 핵심 비교는 GKA, GDN, Mamba-2다.
논문은 이들을 generic recurrence의 transition operator와 write operator 관점에서 비교하고, expressiveness hierarchy를 GKA > GDN > Mamba-2로 정리한다.
실험에서도 같은 조건에서 GKA가 긴 추론·long-context task에서 가장 강한 패턴을 보인다.
다만 이 hierarchy는 논문이 설정한 Hybrid 비율, Qwen3 source model, training recipe, benchmark 묶음 안에서 읽어야 한다.
모든 SSM layer와 모든 모델 계열에 자동으로 일반화되는 정리라기보다는, controlled comparison의 결과에 가깝다.
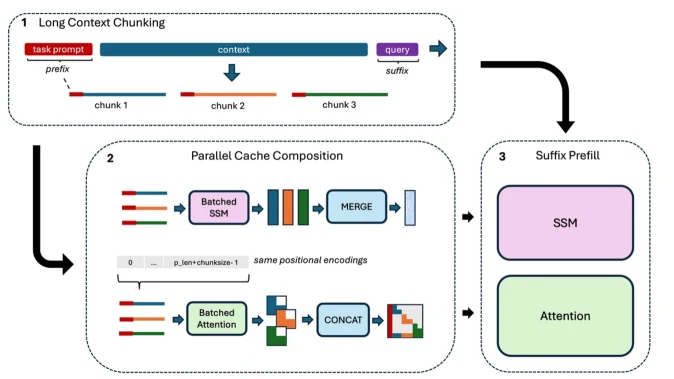
또 하나의 흥미로운 구성은 training-free context extension이다.
Hybrid 모델은 긴 입력을 native context length 단위로 chunking한 뒤, attention KV cache는 concatenate하고 SSM state는 merge한다.
이렇게 하면 128K native window를 넘어 256K나 512K 입력을 처리할 수 있다.
SSM state가 과거 chunk의 압축된 정보를 들고 있기 때문에 가능한 방식이지만, attention layer가 완전히 사라지는 것은 아니므로 KV cache와 RoPE/attention scaling 문제는 여전히 남는다.
공개된 근거에서 확인되는 점
논문의 headline은 품질과 효율을 동시에 본다.
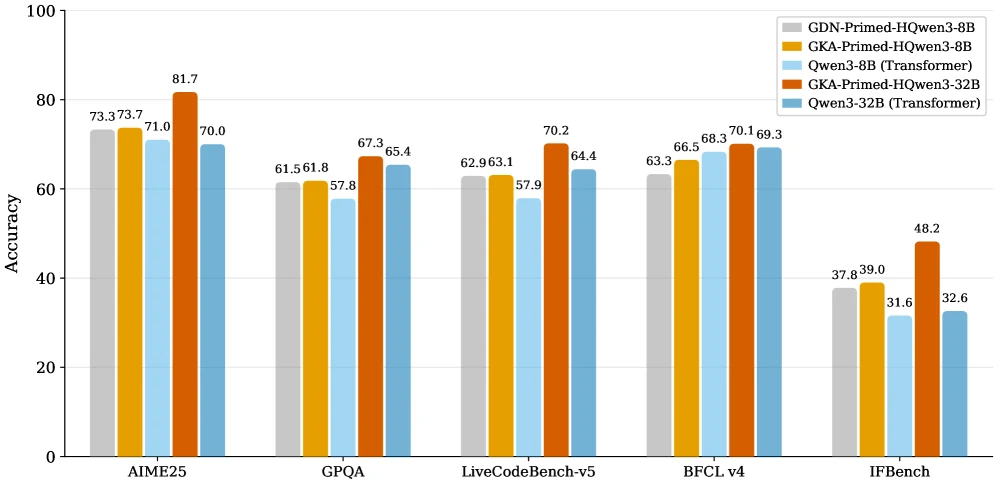
32B reasoning 설정에서 GKA-Primed-HQwen3-Reasoner는 AIME24, AIME25, GPQA, LiveCodeBench, BFCL, IFBench, SciCode 등 8개 benchmark 평균 63.0을 기록한다. source Qwen3-32B의 59.2보다는 높고, 같은 reasoning recipe로 fine-tune한 Transformer baseline 64.1보다는 1.7% relative gap 안에 있다.
8B reasoning에서도 GKA Hybrid는 평균 56.8로 source Qwen3-8B 55.3을 넘지만, Reasoner-SFT baseline 57.4에는 약간 못 미친다.
Instruction-tuned long-context 모델도 비슷한 패턴이다.
32B short-context Tulu3-Dev 평균에서 Qwen3-32B Long baseline은 77.6, GKA-Primed-HQwen3-IT는 76.1, GDN-Primed-HQwen3-IT는 76.5다.
8B에서는 B’MOJO-F-Primed-HQwen3-IT가 평균 71.3으로 Qwen3-8B Long baseline 71.2를 사실상 맞추고, GKA/GDN/Mamba-2는 68.0~69.2 범위에 있다.
즉 모든 Hybrid가 Transformer를 무조건 이긴다는 이야기가 아니라, 일부 Hybrid는 품질 손실을 작게 유지하면서 cache와 decode 효율을 얻는다는 쪽에 가깝다.
효율 쪽 숫자는 더 직접적이다.
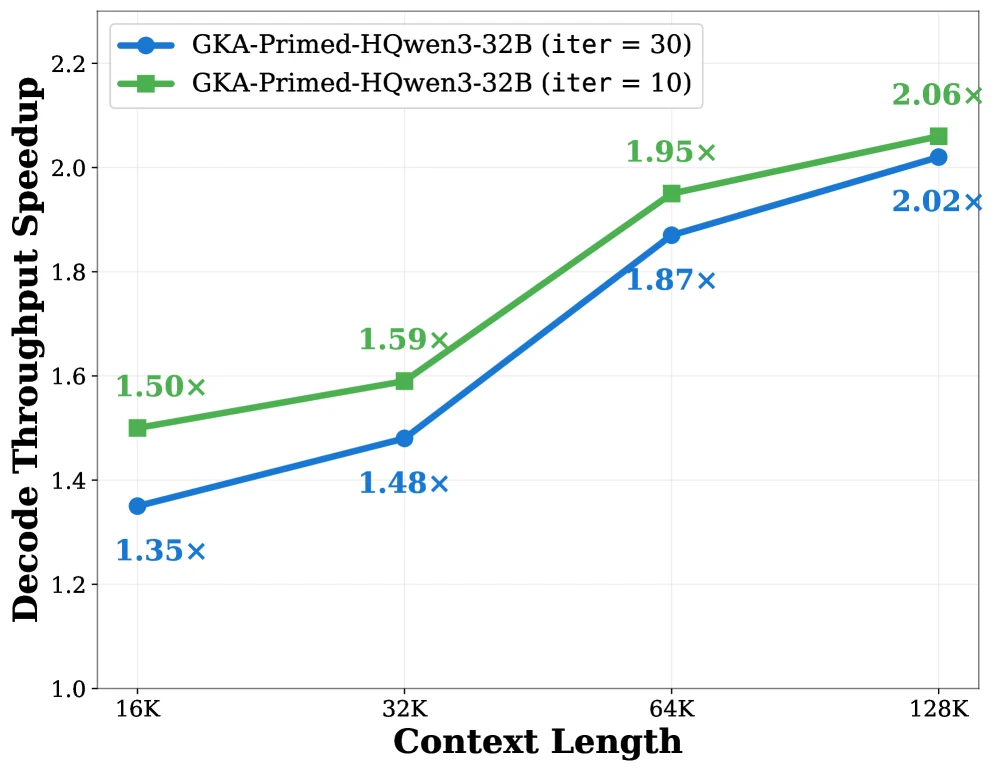
논문 Table 13/14에 따르면 32B 모델을 8×H200 TP=8 조건에서 측정했을 때, 128K context decode throughput은 Qwen3-32B Transformer 586 tokens/s, GKA-Primed-HQwen3 1,187 tokens/s, GDN-Primed-HQwen3 1,238 tokens/s다.
8B에서는 128K context에서 Qwen3-8B 1,227 tokens/s, GKA 2,772 tokens/s, GDN 2,863 tokens/s, Mamba-2 2,825 tokens/s로 보고된다.
논문이 말하는 “up to 2.3×”는 이 긴 context와 KV-cache saturation 조건에서 나온다.
Test-time scaling에서도 같은 관점이 나온다.
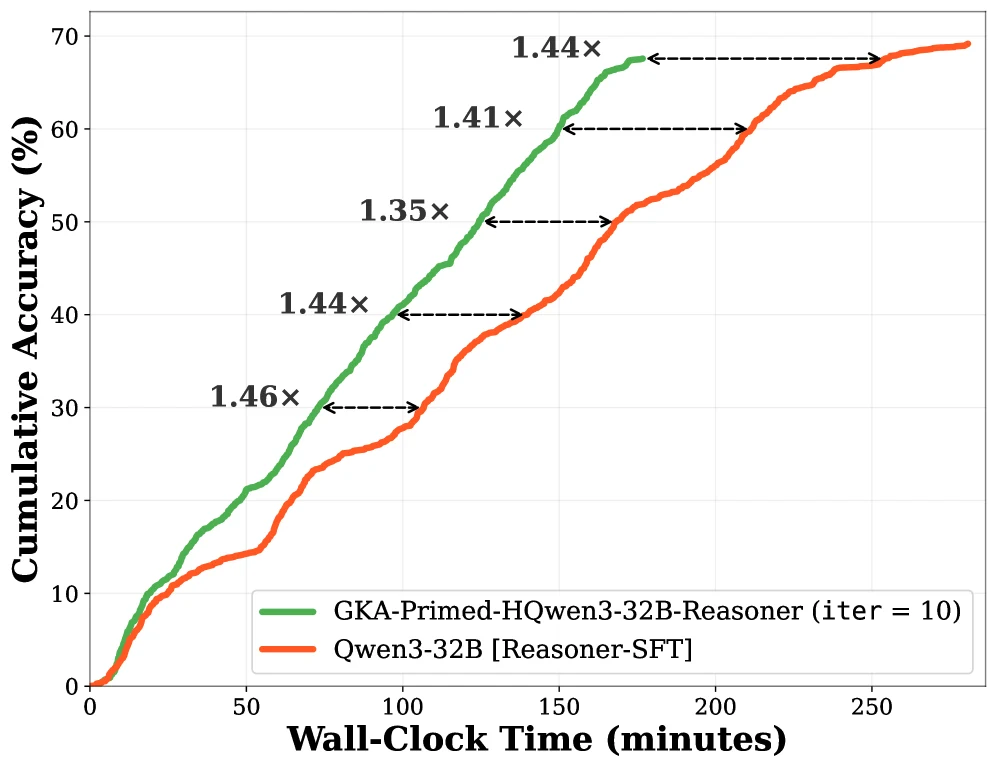
AIME 2025 full set에서 GKA-Primed-HQwen3-Reasoner는 accuracy threshold에 도달하는 wall-clock time 기준으로 일부 낮은 rollout 영역에서는 Transformer가 더 빠른 구간이 있지만, KV cache가 포화되고 rollouts가 늘어날수록 Hybrid 쪽 speedup이 커진다. hardest subset에서는 4801440 rollouts 전반에서 대체로 1.2×1.6× 수준의 time-to-accuracy 이점을 보인다.
즉 Hybrid의 이점은 단일 prompt latency보다 긴 추론 trace와 다중 rollout serving에서 더 선명해진다.
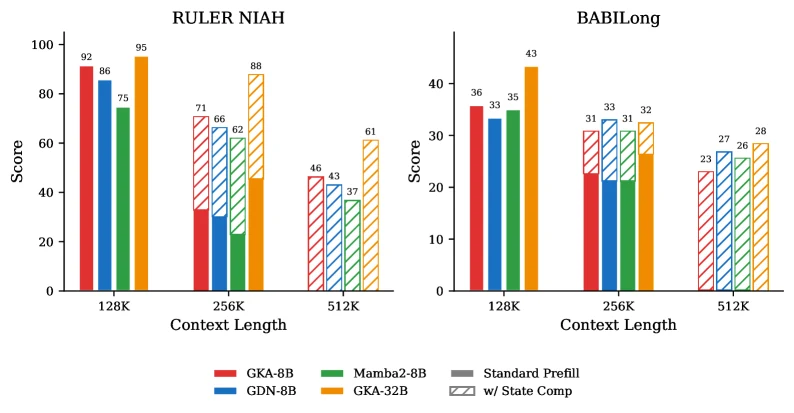
Context extension 실험은 조금 더 조심해서 읽어야 한다.
Figure 10은 128K native, 256K, 512K에서 RULER NIAH와 BABILong 점수를 비교한다.
Standard prefill만으로는 native window 밖에서 성능이 급격히 무너지지만, 128K chunk별 state composition을 쓰면 일부 점수를 회복한다.
그러나 512K에서도 항상 128K 성능이 유지되는 것은 아니다.
이 결과는 “무한 context가 공짜로 생긴다”가 아니라, Hybrid state를 합성하면 학습 없이도 native window 밖에서 일부 long-context 신호를 보존할 수 있다는 근거로 보는 편이 맞다.
릴리스 표면은 비교적 구체적이다. arXiv HTML은 공식 GitHub awslabs/hybrid-model-factory와 Hugging Face amazon/primed-hybrid-models-collection을 직접 링크한다.
GitHub API 기준 repository는 2026-02-24 생성, 2026-05-09 최근 push, Apache-2.0 license, stars 69, forks 5, open issues 0이며, root에는 training, vllm-inference, docs, examples가 있다.
다만 조회 시점 기준 GitHub Releases와 tags는 비어 있다.
Hugging Face collection은 “Primed Hybrid Models Collection”이라는 이름으로 9개 public model을 담고 있다.
모두 gated가 아니고, model cards와 API metadata는 Apache-2.0 license tag를 표시한다.
대표 모델들의 config.json은 HybridQwen3ForCausalLM, model_type: hybrid_qwen3, max_position_embeddings: 131072를 노출한다.
8B 계열은 약 8.5B safetensors, 32B 계열은 약 34B safetensors 규모이며, Reasoner와 Instruct variant가 나뉜다.
| 공개 표면 | 확인되는 내용 | 실무 해석 |
|---|---|---|
| arXiv paper / HTML | Priming 방법, SSM layer 비교, long-context·reasoning·throughput 결과 | 논문 주장과 figure/table의 1차 근거 |
GitHub awslabs/hybrid-model-factory |
training code, vLLM inference plugin, evaluation examples, Apache-2.0 | 단순 placeholder가 아니라 실제 toolkit 공개에 가깝다 |
| GitHub releases/tags | latest release 404, tags 0개 | production dependency로 보기 전 버전 고정과 내부 검토가 필요하다 |
| Hugging Face collection | 9개 ungated Primed Hybrid Qwen3 모델, 128K config, Apache-2.0 card | checkpoint release surface는 분명하지만 custom architecture/runtime 검토가 필요하다 |
| Inference docs | vLLM plugin, Docker/pip install, tensor parallelism, GKA compute control 설명 | 표준 Transformers 로드만으로 끝나는 release가 아니라 serving stack 통합까지 봐야 한다 |
| 모델 계열 | 공개 variant | SSM layer | 확인되는 packaging 신호 |
|---|---|---|---|
| GKA-primed-HQwen3 | 8B/32B Instruct, 8B/32B Reasoner | Gated KalmaNet | 128K context, HybridQwen3ForCausalLM, Apache-2.0, 8B는 4 shard·32B는 15 shard safetensors |
| GDN-primed-HQwen3 | 8B/32B Instruct, 8B Reasoner | Gated DeltaNet | 128K context, text-generation pipeline, ungated public model |
| Mamba2-primed-HQwen3 | 8B Instruct | Mamba-2 | 128K context, Mamba-2 SSM 비교 축 |
| BMOJOF-primed-HQwen3 | 8B Instruct | B’MOJO-F | sliding-window attention과 SSM을 한 layer 안에 결합한 hybrid layer variant |
실무 관점에서의 해석
Priming의 실용적 의미는 Hybrid SSM이 Transformer를 대체했다는 선언이 아니다.
더 정확히는 Hybrid architecture search의 비용 모델을 바꾼다는 점이다.
지금까지는 긴 context를 싸게 만들고 싶어도, 어떤 layer를 recurrent state로 바꾸면 품질이 얼마나 떨어질지 대규모로 확인하기 어려웠다.
Priming은 이미 강한 Transformer를 source로 삼아, layer 선택·SSM 종류·alignment recipe를 통제된 조건에서 비교할 수 있게 만든다.
Serving 관점에서는 KV cache 압박이 핵심이다.
Reasoning model은 더 긴 thought trace와 더 많은 rollout을 쓰는 방향으로 가고 있고, agentic workflow는 context가 자연스럽게 누적된다.
이때 모든 layer가 full attention이면 context length가 늘어날수록 memory와 bandwidth가 병목이 된다.
Hybrid 모델은 일부 layer에서 과거를 SSM state로 압축해, 긴 context에서 decode throughput을 높일 여지를 만든다.
논문의 throughput 결과가 특히 64K/128K에서 좋아지는 것도 이 맥락에서 읽힌다.
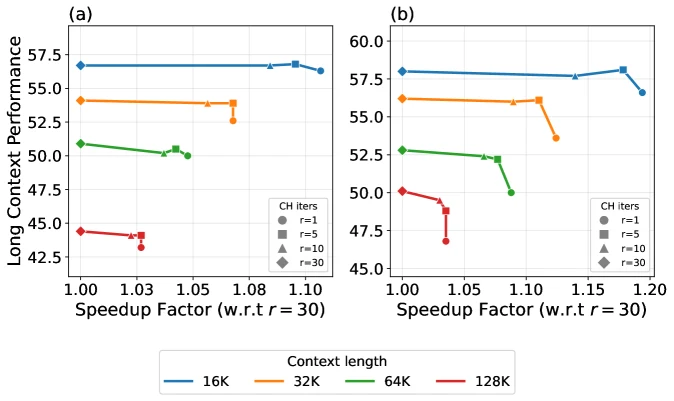
GKA의 variable test-time compute도 중요하다.
논문은 GKA layer의 Chebyshev iteration 수를 training value 30에서 10, 5, 1 등으로 줄이면 throughput은 오르고 long-context 성능은 일부 떨어지는 trade-off가 생긴다고 보고한다.
이건 단순 pruning이나 quantization과 조금 다르다.
하나의 model checkpoint 안에서 workload, latency budget, context length에 따라 recurrent computation을 조절할 수 있다는 뜻이다.
다만 caveat도 분명하다.
첫째, 32B reasoning에서 GKA Hybrid는 source Transformer보다 좋지만, 같은 data로 post-train한 Transformer SFT보다는 평균이 낮다.
일부 benchmark, 특히 BFCL v3나 SciCode 쪽에서는 source 대비 손실도 보인다.
둘째, long-context extension은 chunked state composition의 가능성을 보여 주지만, 512K에서도 모든 task가 안정적으로 유지되는 것은 아니다.
셋째, 공개 repo는 코드와 문서가 있지만 formal release/tag가 없고, custom HybridQwen3ForCausalLM과 vLLM plugin을 포함하므로 일반적인 Hugging Face checkpoint처럼 바로 모든 serving 환경에 drop-in된다고 보면 위험하다.
그래도 이 논문은 long-context architecture 논의에서 꽤 중요한 방향을 제시한다.
긴 문맥의 해법이 단순히 “attention을 더 최적화한다”나 “SSM으로 전부 바꾼다”가 아니라, layer마다 필요한 memory fidelity를 다르게 배치하고, 사전학습 Transformer의 지식을 최대한 보존한 채 그 배치를 실험하는 쪽으로 갈 수 있기 때문이다.
Priming은 그 전환을 연구 아이디어가 아니라 공개 model zoo와 toolkit 형태로 내놓았다는 점에서 의미가 있다.
앞으로의 질문은 두 가지다.
하나는 이 방법이 Qwen3 중심의 8B/32B 실험을 넘어 더 다양한 source model, MoE, multilingual, tool-use setting에서도 같은 안정성을 보일지다.
다른 하나는 deployment 측면에서 Hybrid runtime이 vLLM, quantization, speculative decoding, batching scheduler와 얼마나 자연스럽게 결합될지다.
Priming이 성공한다면, 다음 세대 long-context model은 “Transformer냐 SSM이냐”가 아니라 어느 layer가 어떤 기억 방식을 가져야 하는가의 문제로 설계될 가능성이 크다.