긴 컨텍스트 LLM 추론에서 attention은 두 가지 압력을 동시에 받는다.
컨텍스트가 길어질수록 query-key 상호작용 수는 제곱으로 늘고, decode 단계에서는 KV cache를 계속 읽어야 한다.
그래서 Blackwell 세대의 FP4 Tensor Core처럼 더 낮은 정밀도와 더 높은 처리량을 쓰고 싶어진다.
문제는 논문이 관찰하듯, 긴 컨텍스트에서는 FP4 attention이 단순히 “조금 거칠어진다”가 아니라 품질 저하가 컨텍스트 길이에 따라 체계적으로 커질 수 있다는 점이다.
ThriftAttention: Selective Mixed Precision for Long-Context FP4 Attention(arXiv:2605.23081)은 이 문제를 전부 FP16으로 되돌리는 것과 전부 FP4로 밀어붙이는 것 사이의 선택으로 보지 않는다.
저자는 FP4 quantization error의 영향이 모든 query-key block에 균등하지 않고, attention output에 실제로 큰 영향을 주는 소수 block에 집중된다고 본다.
따라서 핵심은 “어떤 block을 높은 정밀도로 살릴 것인가”다.
ThriftAttention의 요지는 간단하다.
빠른 heuristic으로 중요한 query-key block pair를 고르고, 그 block만 FP16으로 계산한다.
나머지 대부분의 block은 FP4로 계산한 뒤, 두 경로를 online softmax로 합쳐 하나의 attention output을 만든다.
논문은 5%의 query-key block만 FP16으로 계산해도 평균적으로 FP4→FP16 성능 격차의 89.1%를 회복한다고 보고한다.
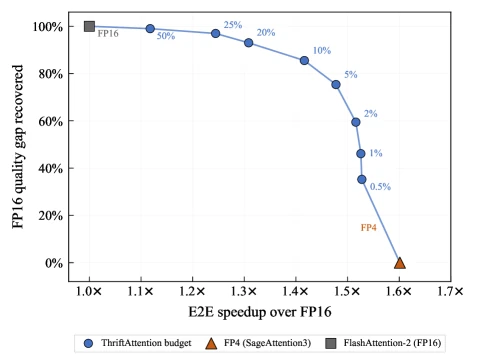
arXiv HTML Figure 1.
Qwen3-8B, 131k context에서 NLL recovery와 inference efficiency의 Pareto frontier.
논문은 ThriftAttention이 FP4 latency에 가까워지면서 near-FP16 품질을 유지한다고 설명한다.
무엇을 해결하려는가
기존 FP4 attention은 Blackwell GPU에서 attention 계산을 4-bit precision으로 내려 inference throughput을 높이는 방향이다.
SageAttention3처럼 FP4 microscaling을 쓰는 흐름은 특히 이 배경에서 중요하다.
하지만 ThriftAttention 논문은 long-context workload에서 uniform FP4 quantization이 품질을 크게 깎을 수 있다고 지적한다.
반대편에는 sparse attention이 있다.
Quest나 SpargeAttention 같은 방법은 중요한 query-key interaction만 계산하고 나머지는 버리는 방식으로 비용을 낮춘다.
그런데 논문은 generation phase에서 FP4 latency에 맞추려면 sparse method가 KV block의 75% 이상을 drop해야 할 수 있다고 설명한다.
누락된 block은 아예 output에 기여하지 못하므로 tail error가 커질 수 있다.
ThriftAttention은 여기서 절충한다.
중요한 block은 FP16으로 살리고, 중요도가 낮은 block도 버리지는 않고 FP4로 남긴다.
즉 sparse attention처럼 support를 잘라내는 것이 아니라, 모든 interaction을 유지하되 민감한 interaction에만 정밀도를 더 쓰는 구조다.
핵심 아이디어와 동작 방식
논문이 제안하는 forward path는 두 단계다.
| 단계 | 동작 | 실무적 의미 |
|---|---|---|
| Block-importance scoring | query block과 key block의 token mean을 이용해 block pair 점수를 빠르게 계산한다. | attention matrix 전체를 고정밀로 훑지 않고 FP16 후보를 고른다. |
| Mixed-precision attention | top-k block은 FP16, 나머지는 FP4로 계산하고 online softmax로 병합한다. | FP4 처리량을 최대한 유지하면서 중요한 경로의 quantization error를 줄인다. |
논문은 score heuristic을 S_hat_ij = mean(q_i) · mean(k_j) 형태로 설명한다.
이 값이 높은 block pair는 attention score가 크고 output에 더 민감할 가능성이 높으므로 FP16으로 승격한다.
FP4 quantization 자체는 Blackwell NVFP4 microscaling format을 가정하며, Q/K/V에 독립적으로 적용된다.
중요한 점은 ThriftAttention이 training-free라는 것이다.
모델을 다시 학습하거나 low-rank adapter를 붙이는 방법이 아니라, attention kernel과 block selection policy를 바꿔 inference 시점에 품질-속도 trade-off를 조절한다.
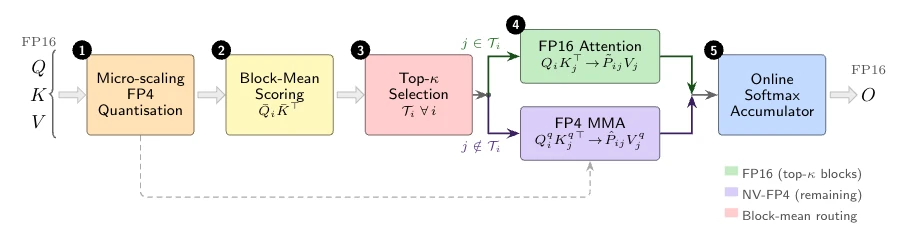
arXiv HTML Figure 2.
ThriftAttention은 중요한 query-key block을 FP16 path로 보내고, 나머지는 FP4 path로 보낸 뒤 online softmax로 합친다.
공개된 근거에서 확인되는 점
논문은 LongBench-v1, HELMET, RULER, PG-19를 사용하고, Llama, Qwen, Ministral 계열 모델에서 결과를 제시한다. headline 수치는 명확하다.
- FP16 block budget 5%: 평균 FP4→FP16 gap recovery 89.1%
- FP16 block budget 10%: 평균 recovery 91.8%
- FP16 block budget 25%: 평균 recovery 92.4%
즉 가장 중요한 block 일부를 먼저 FP16으로 올릴 때 수익이 크고, 이후 budget을 늘릴수록 marginal gain이 줄어드는 모양이다.
논문은 benchmark별 반응도 다르다고 설명한다.
LongBench v1은 5%에서 거의 포화되고, RULER는 5%에서 25%까지 더 꾸준히 오른다.
HELMET은 그 중간에 있다.
속도 측면에서는 RTX PRO 6000 Blackwell에서 FlashAttention-2 및 SageAttention3와 비교한다.
저자는 prefill에서 FlashAttention-2 대비 최대 1.7× kernel speedup, 131k context에서 FP16 attention 대비 약 1.2× end-to-end prefill speedup을 보고한다.
Decode kernel은 FlashAttention-2 대비 3×–5.5× speedup이고, Qwen3-8B 131k context generation에서는 full FP16 attention 대비 거의 2× end-to-end speedup으로 이어진다고 설명한다.
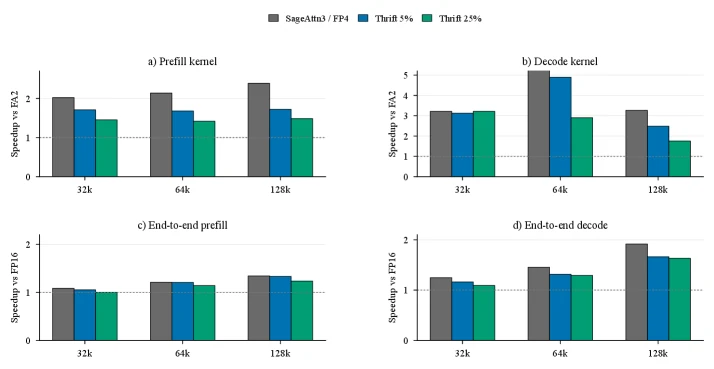
arXiv HTML Figure 4.
RTX PRO 6000에서 prefill/decode kernel speedup과 Qwen3-8B end-to-end generation speedup을 비교한다.
NLL 분석도 핵심이다.
PG-19 300개 문서에서 per-token NLL을 보면, 16k 이하에서는 FP4의 ΔNLL이 약 0.04 수준으로 비교적 일정하지만 32k 이후 positional dependence가 나타난다.
64k와 128k에서는 sequence 끝부분의 FP4 ΔNLL이 0.10까지 나빠진다.
ThriftAttention은 이를 context length 전반에서 0.02 이하로 낮춘다고 보고한다.
그래서 상대적 ΔNLL 감소폭은 8k에서 약 2×, 128k sequence 끝에서는 약 5×까지 커진다.
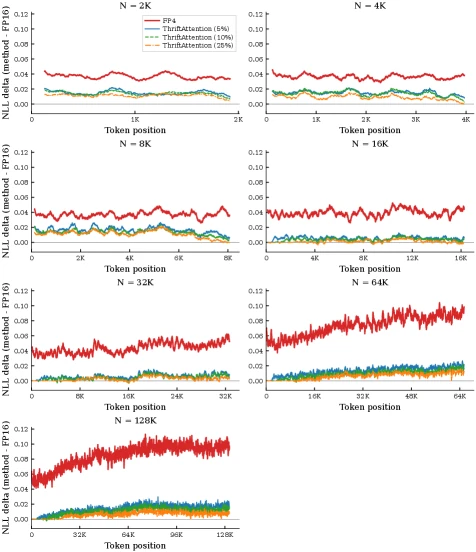
arXiv HTML Figure 5.
Qwen3-8B, PG-19 문서에서 FP16 baseline 대비 per-token ΔNLL을 context length별로 비교한다.
Sparse baseline과의 비교도 ThriftAttention의 포지셔닝을 보여준다.
65,536 sequence length의 HELMET subset에서 matched FP16-equivalent compute 조건을 맞추기 위해 sparse method는 block의 71.3%를 skip하고 28.7%만 FP16으로 계산한다.
같은 compute budget에서 ThriftAttention 5%는 5% FP16 + 95% FP4 + 0% skip으로 score 0.599를 기록했고, Sparse Top-k 28.7%는 0.036, Quest 28.7%는 0.142로 보고된다.
저자의 해석은 분명하다.
ThriftAttention은 missed block도 FP4로 남기기 때문에 “삭제”가 아니라 “저정밀 degradation”으로 흡수하고, 공격적인 sparsity보다 tail error가 부드럽다.
코드와 사용 조건
arXiv abstract와 GitHub README 모두 코드 저장소를 joesharratt1229/ThriftAttention로 연결한다.
GitHub 확인 시 저장소는 public이고 Apache-2.0 라이선스를 사용한다.
README에는 thriftattention Python package 형태의 사용 예시와 Transformers integration 예시가 있다.
실행 조건은 가볍지 않다.
README 기준 Python 3.10+, CUDA toolkit 12.8+, CUDA 12.8 기반 PyTorch 2.8.0+, Transformers 4.52+가 필요하다.
또한 논문 자체가 Blackwell FP4 path를 중심으로 설명하므로, 일반 GPU에서 “그냥 설치하면 같은 숫자가 나온다”고 보기는 어렵다.
GitHub 페이지 확인 시 별도 stable release는 아직 없다.
실무 관점에서의 해석
ThriftAttention은 모델 아키텍처 제안이라기보다 attention kernel의 precision routing에 가깝다.
제품 관점에서 흥미로운 이유는 low-bit inference의 흔한 trade-off를 더 세밀하게 쪼갠다는 데 있다.
지금까지는 “FP16은 정확하지만 느림, FP4는 빠르지만 품질 저하”처럼 전체 attention path의 dtype을 고르는 식으로 말하기 쉬웠다.
ThriftAttention은 block 단위로 어느 부분만 FP16이어야 하는지 선택한다.
이 접근은 긴 컨텍스트에서 특히 그럴듯하다. sequence length가 늘수록 가능한 query-key block interaction은 제곱으로 늘지만, attention mass를 크게 좌우하는 block의 비율은 그보다 느리게 늘 수 있다.
그렇다면 fixed top-k fraction으로도 긴 문맥에서 더 많은 중요한 mass를 잡을 수 있고, 논문이 관찰한 것처럼 ThriftAttention의 advantage가 context length와 함께 커질 수 있다.
다만 제한도 분명하다.
현재 kernel implementation은 consumer Blackwell GPU를 대상으로 한다.
논문은 data-center Blackwell로 확장하면 SM100 기능과 더 높은 asynchrony를 활용할 수 있을 것이라고 보지만, 이는 아직 future work다.
또한 ThriftAttention은 FP16 cache와 FP4 cache를 함께 저장하기 때문에 KV-cache memory footprint가 28% 증가한다고 밝힌다.
마지막으로 현재 설계는 inference acceleration용이며, training에서 sub-byte attention stability를 해결한 것은 아니다.
따라서 실무적으로는 “FP4 attention의 품질 저하를 거의 공짜로 없애는 범용 해법”이라기보다, Blackwell FP4 inference를 장기 컨텍스트에 적용하려는 팀이 품질 손실을 줄이기 위해 검토할 selective precision kernel로 보는 편이 안전하다.
특히 64k~128k context, decode-heavy serving, 그리고 sparse attention의 drop error가 부담스러운 워크로드라면 평가해볼 만하다.
반대로 hardware target이 Blackwell이 아니거나 KV cache memory headroom이 빡빡한 환경에서는 논문 수치가 그대로 옮겨오지 않을 가능성이 크다.