요즘 reasoning RL 논문을 읽다 보면 같은 질문이 반복된다.
RL은 정말 모델에 새로운 추론 능력을 만들어 주는가, 아니면 이미 모델 안에 있던 행동을 더 잘 꺼내고 조합하게 만드는가.Mid-Training with Self-Generated Data Improves Reinforcement Learning in Language Models는 이 질문을 정면으로 다룬다.
결론부터 말하면, 이 논문은 RL 자체보다 RL 이전에 모델이 어떤 풀이 분포를 보았는지가 중요하다고 주장한다.
핵심 아이디어는 간단하다.
같은 수학 문제를 하나의 정답 풀이만으로 학습시키지 말고, Pólya의 문제 해결 휴리스틱에 따라 여러 개의 올바른 풀이 경로로 먼저 mid-training한다.
그런 다음 GRPO 기반 RL을 붙이면, RL은 좁은 단일 reasoning mode를 강화하는 대신 여러 풀이법을 더 잘 탐색하고 조합할 수 있다.
중요한 점은 이 풀이들이 강한 teacher 모델에서 증류된 것이 아니라, 이후 RL을 받을 같은 base model이 스스로 생성한 데이터라는 점이다.
이 논문은 “RL이 emergent reasoning을 만든다”는 식의 큰 주장보다 더 조심스러운 해석을 제안한다.
RL은 완전히 새로운 행동을 무에서 창조하기보다, mid-training 단계에서 노출된 여러 문제 해결 접근법을 보상 신호 아래에서 재조합할 수 있다.
그래서 이 글의 중심은 성능표 하나가 아니라, 데이터 다양성 → next-token 분포의 다중 모드화 → RL 중 조합 행동 증가라는 메커니즘이다.
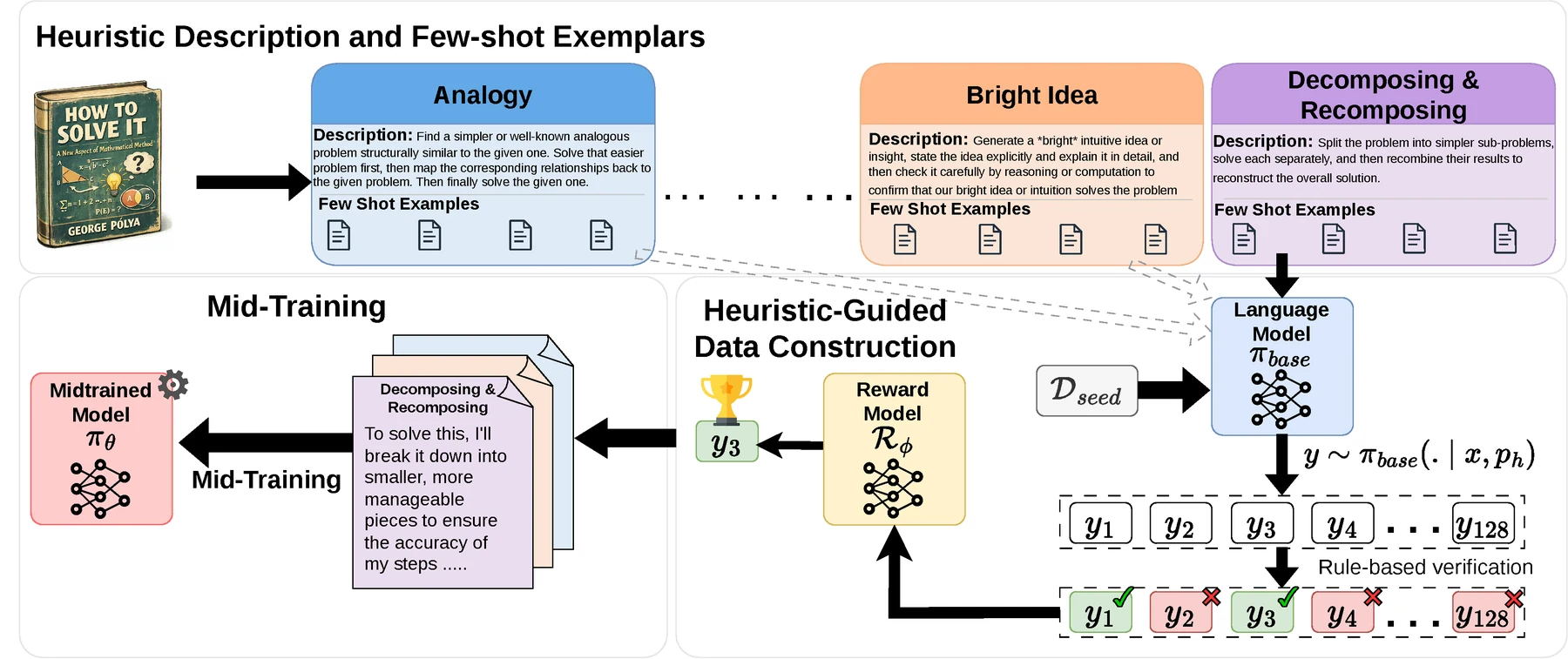
무엇을 해결하려는가
기존 reasoning post-training에서는 같은 문제에 대해 하나의 정답 reasoning trace를 강화하거나, STaR처럼 self-generated rationale을 반복적으로 모아 fine-tuning하는 흐름이 많았다.
하지만 수학 문제는 보통 하나의 풀이법만 갖지 않는다.
뒤에서부터 풀기, 보조량을 도입하기, 문제를 더 작은 하위 문제로 나누기, 대칭성이나 불변량을 보는 식의 서로 다른 접근이 모두 정답으로 이어질 수 있다.
문제는 RL이 이런 다양성을 자동으로 만들어 준다고 가정하기 어렵다는 데 있다. base model이 rollout에서 특정 풀이 패턴만 자주 내고, 그중 일부만 보상을 받으면 RL은 그 좁은 basin을 더 강화할 가능성이 크다.
특히 pass@1만 보면 단일 고확률 경로를 강화하는 것이 좋아 보일 수 있지만, pass@k나 hard benchmark에서는 여러 풀이 경로를 보존하는 능력이 더 중요할 수 있다.
논문은 그래서 RL 이전의 supervised 단계를 다시 본다.
Mid-training은 pre-training과 post-training 사이에서 특정 능력을 유도하는 중간 학습 단계다.
이 연구에서는 GSM8K training set을 seed로 삼고, 각 문제에 대해 Pólya식 휴리스틱을 조건으로 한 여러 정답 풀이를 생성한다.
이후 정답 검증과 reward model scoring으로 걸러낸 풀이들을 사용해 Llama 3.2-3B-Instruct를 mid-train한 뒤, DAPO-Math-17K 기반 GRPO를 적용한다.
핵심 아이디어 / 구조 / 동작 방식
데이터 생성 절차는 네 단계로 읽을 수 있다.
| 단계 | 논문에서의 역할 | 실무적으로 읽히는 의미 |
|---|---|---|
| Pólya 휴리스틱 정의 | How to Solve It의 문제 해결 접근을 prompt 조건으로 사용 |
다양성을 무작위 temperature가 아니라 구조화된 reasoning axis로 만든다 |
| self-generation | 같은 base model이 휴리스틱별 candidate solution을 생성 | 강한 teacher distillation 효과와 혼동하지 않도록 통제한다 |
| correctness filtering | Math-Verify 같은 rule-based verifier로 최종 정답을 확인 | 다양성만으로는 부족하고, 정답에 도달한 풀이만 남긴다 |
| reward-model selection | Skywork reward model로 휴리스틱 부합도를 평가해 대표 풀이를 선택 | “정답이지만 같은 풀이”가 아니라 의도한 접근법 차이를 보존한다 |
실험 설정도 이 메시지에 맞춰 설계되어 있다.
논문은 GSM8K 7,473개 training question에서 필터링된 7,112개 문제를 사용하고, 각 문제에 대해 n ∈ {1, 2, 4, 8, 16, 32, 64}개의 휴리스틱별 풀이 variant를 붙인 mid-training dataset을 만든다. mid-training은 trl로 수행하고, 이후 RL은 verl의 GRPO와 vLLM rollout을 사용한다.
Appendix 기준 전체 실험은 4×NVIDIA H100 GPU에서 수행되며, RL 단계는 prompt 1024 token, response 3072 token, prompt당 16개 response sampling, KL regularization 없이 1 epoch로 진행된다.
이론적 설명은 다음처럼 요약할 수 있다.
하나의 문제 prefix에서 모델이 단일 풀이만 보았다면 다음 token 분포는 특정 경로에 더 뾰족해진다.
반대로 같은 prefix 뒤에 여러 올바른 풀이가 존재한다는 것을 mid-training에서 보았다면, 모델은 여러 next-token 후보에 의미 있는 확률 질량을 둘 수 있다.
논문은 이를 n-modal next-token distribution으로 보고, policy-gradient update가 보상받은 trajectory를 강화할 때 여러 모드 사이의 조합을 유도할 수 있다고 해석한다.
즉 여기서 중요한 것은 “더 많은 데이터”가 아니라 “같은 문제에 대해 여러 방식으로 맞는 데이터”다.
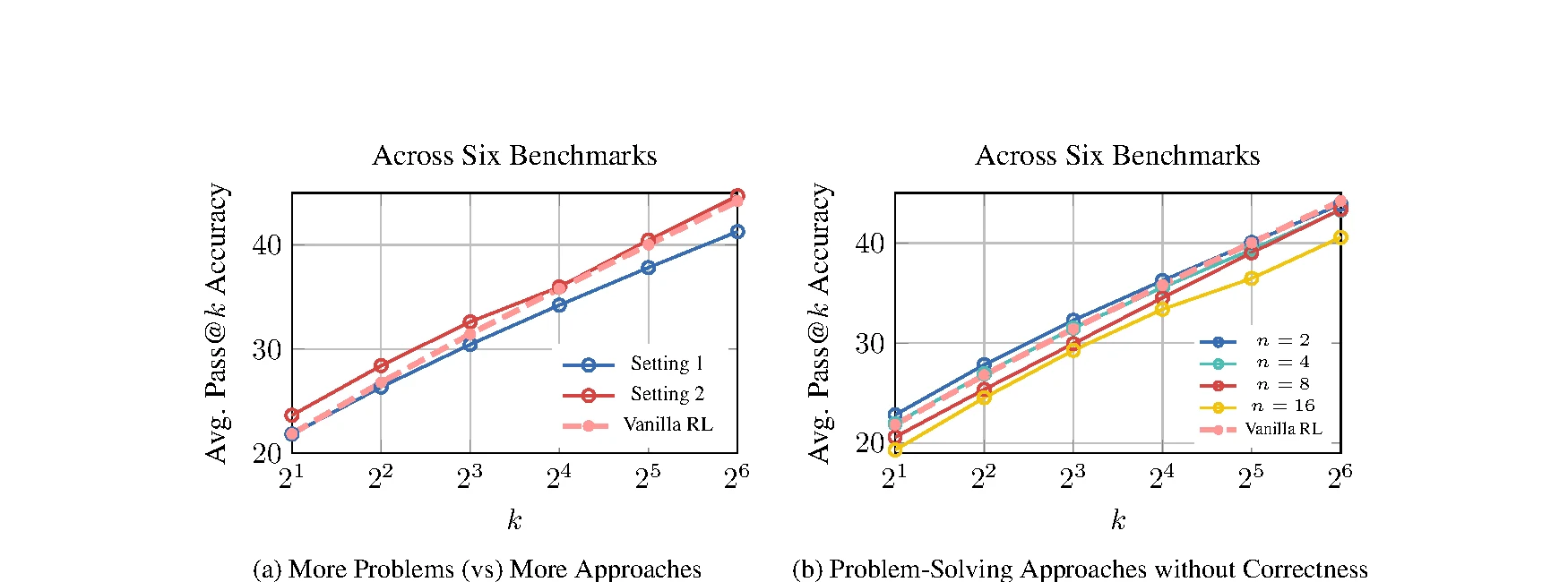
이 차이를 분리하기 위해 논문은 같은 총 training instance 수를 고정하고, 많은 문제에 하나의 풀이를 붙이는 설정과 적은 문제에 여러 풀이를 붙이는 설정도 비교한다.
공개된 근거에서 확인되는 점
첫 번째 근거는 mid-training만 했을 때의 pass@k 변화다.
Llama 3.2-3B-Instruct 기준, Pólya mid-training은 pass@1에서는 STaR보다 낮지만 pass@64에서는 더 강한 패턴을 보인다.
평균 pass@64는 zero-shot 46.30, STaR 46.32에 머무는 반면, Pólya n=64는 48.17까지 올라간다.
절대값으로는 +1.87p 수준의 modest한 개선이지만, 이 논문이 보는 신호는 “최상위 한 샘플”보다 “여러 샘플 안에서 다른 풀이를 찾는 능력”에 있다.
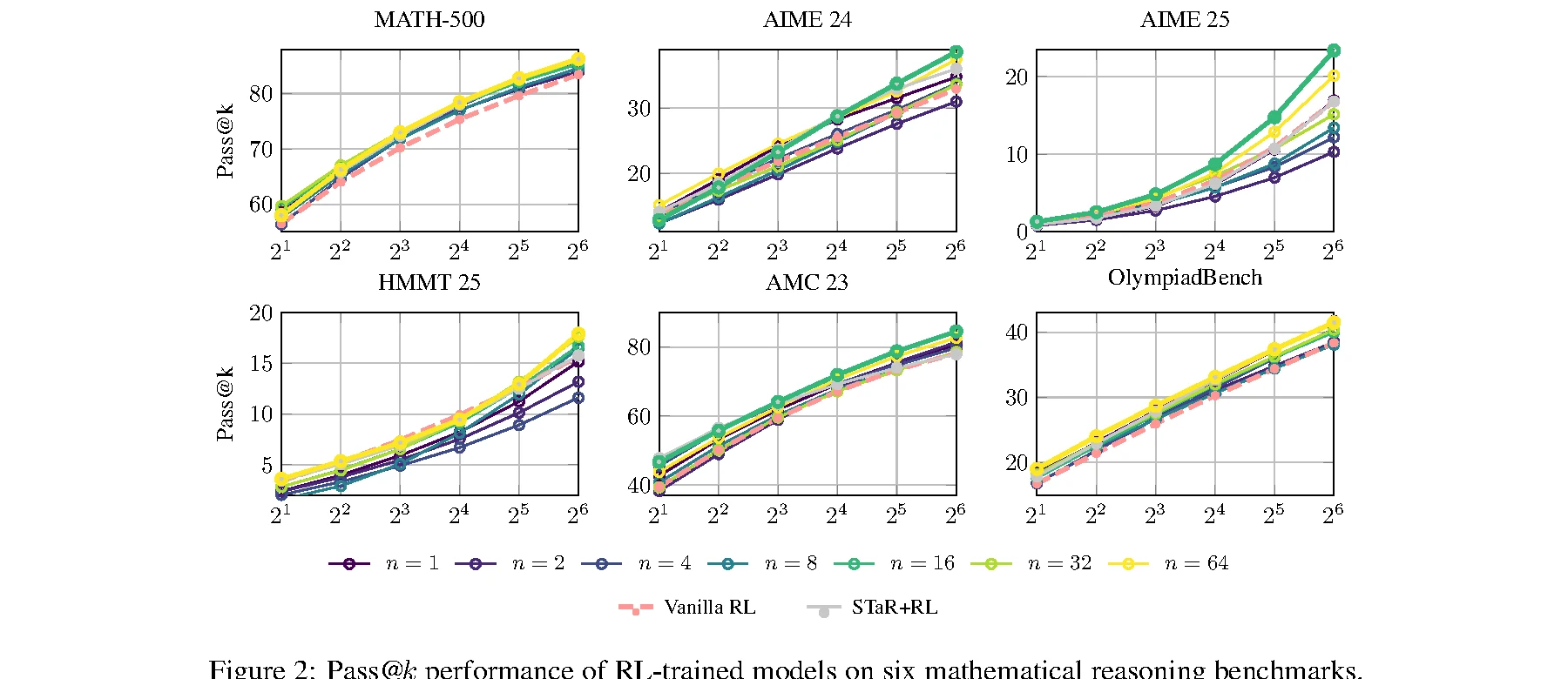
RL을 붙이면 차이가 더 분명해진다.
논문 본문은 GRPO 이후 평균 pass@64에서 Vanilla RL이 44.21, STaR+RL이 45.69인 반면, Pólya mid-training 후 RL은 n=16에서 48.09, n=64에서 47.62를 기록한다고 보고한다. n=16 기준 Vanilla RL 대비 +3.88p다.
개별 benchmark로 보면 MATH-500 pass@64는 83.42에서 86.27로, AIME 2025는 16.91에서 23.34로, AMC 2023은 78.18에서 84.52로 오른다.
| 비교 지점 | 보고된 결과 | 해석 |
|---|---|---|
Mid-training 평균 pass@64: zero-shot → Pólya n=64 |
46.30 → 48.17 | RL 전에도 다양한 정답 풀이 노출이 pass@k를 넓힌다 |
RL 평균 pass@64: Vanilla RL → Pólya n=16+RL |
44.21 → 48.09 | RL 초기화 분포가 달라지면 같은 GRPO도 더 잘 작동한다 |
AIME 2025 pass@64: Vanilla RL → Pólya n=64+RL |
16.91 → 23.34 | 어려운 수학 문제에서 탐색 폭의 이득이 크게 나타난다 |
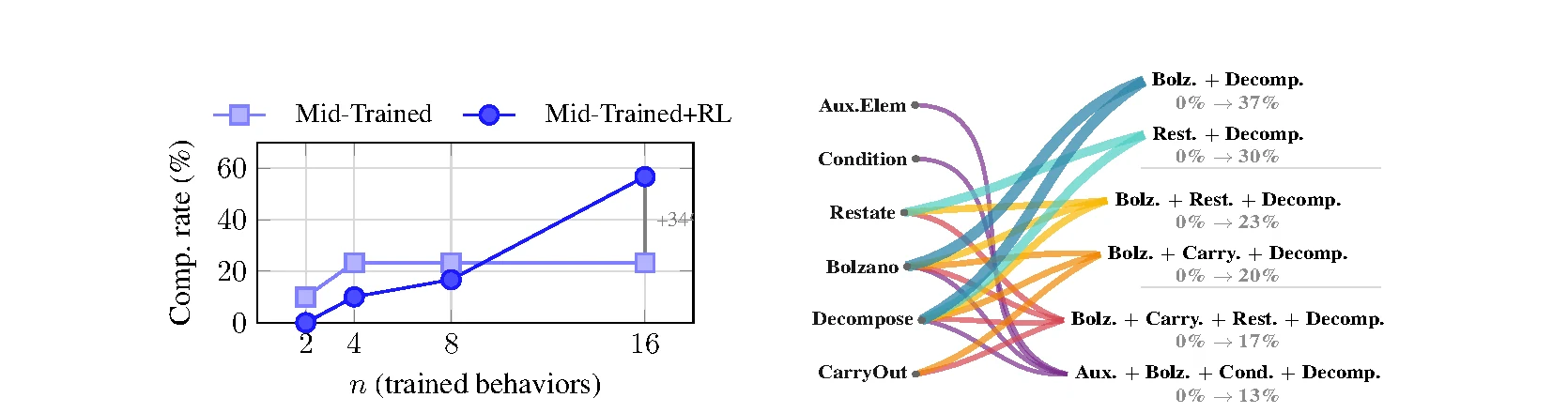
Composition rate at n=16: mid-trained → mid-trained+RL |
23.3% → 56.7% | RL 후 하나의 reasoning chain 안에서 여러 접근법을 섞는 비율이 증가한다 |
Vendi Score: QwQ-32B distillation vs Pólya n=16 data |
10.95 vs 13.81 | 강한 teacher 증류보다 구조화된 self-generated data가 더 다양한 경우가 있다 |
두 번째 근거는 reasoning trace 분석이다.
저자들은 GPT-4o-mini judge를 사용해 AIME 2024에서 생성된 풀이가 어떤 Pólya식 접근을 보이는지 분류한다.
그 결과 n=16 설정에서 RL 이전 mid-trained model의 multi-behavior composition rate는 23.3%였지만, RL 이후에는 56.7%로 오른다.
오른쪽 Sankey-style 그림은 RL 후 자주 나타나는 휴리스틱 조합을 보여준다.
세 번째 근거는 통제 실험이다.
같은 7,408개의 mid-training instance를 쓸 때, 더 많은 서로 다른 문제를 하나의 풀이로 학습하는 것보다 더 적은 문제에 여러 풀이법을 붙이는 설정이 평균적으로 더 좋다.
논문은 이 차이를 평균 상대 개선 약 7%로 보고한다.
반대로 다양한 접근법이더라도 최종 답이 틀린 reasoning trace로 mid-training하면 성능은 좋아지지 않고, n이 커질수록 평균 pass@k가 오히려 내려간다.
이 결과는 “다양성” 자체가 아니라 정답으로 이어지는 다양한 접근법이 필요하다는 점을 분명히 한다.
부가 실험도 흥미롭다.
QwQ-32B 같은 강한 reasoning teacher에서 16개 trace를 증류하는 방식은 자연스러운 baseline이지만, 논문은 이 distillation dataset의 Vendi Score가 10.95로 Pólya n=16 dataset의 13.81보다 낮다고 보고한다.
또한 distilled model은 RL rollout에서 더 장황하고 반복적인 경향을 보였다고 설명한다.
즉 강한 teacher의 답을 많이 모으는 것과, 같은 문제에 대해 명시적으로 다른 문제 해결 접근을 유도하는 것은 같은 일이 아니다.
Out-of-domain 결과도 제한적이지만 의미 있는 신호를 준다.
HumanEval에서는 Vanilla RL 51.14에 비해 n=64 RL 모델이 52.82를 기록한다.
MuSR의 Murder Mystery는 53.15에서 57.36으로 오르고, Team Allocations는 Vanilla RL 23.46에 비해 n=32 모델이 39.07까지 오른다.
Pólya 휴리스틱은 수학 중심이지만, 여러 단계 reasoning이 필요한 코드·내러티브 과제에도 일부 전이될 수 있다는 주장이다.
다만 공개 release 관점에서는 보수적으로 봐야 한다.
HF Papers 페이지와 arXiv/PDF/source bundle은 확인되지만, 논문 결과를 바로 재현할 수 있는 공식 코드 저장소나 Hugging Face checkpoint bundle은 확인되지 않는다.
GitHub에서 발견되는 관련 저장소는 논문 설명용 animated tweet GIF 모음에 가깝고, 구현 release로 보기는 어렵다.
따라서 현재 이 논문은 “즉시 가져다 쓰는 toolkit”보다는 training recipe와 분석 관점을 제시하는 paper-only 연구에 가깝다.
실무 관점에서의 해석
내가 보기에 이 논문의 가장 중요한 메시지는 RL을 “마지막에 성능을 올리는 마법 단계”로 보지 말라는 것이다.
RL은 초기 policy가 이미 어떤 행동 모드를 갖고 있는지에 크게 의존한다.
초기 policy가 단일 풀이법만 강하게 갖고 있으면 RL은 그 경로를 더 강하게 만들 수 있고, 초기 policy가 여러 올바른 풀이법을 갖고 있으면 RL은 그중 어떤 조합이 보상을 받는지 탐색할 여지가 생긴다.
이 관점은 reasoning model 학습뿐 아니라 agent post-training에도 이어진다.
도구 사용, 코드 수정, 장기 계획 수립 같은 작업에서도 하나의 성공 trajectory만 모아 SFT하는 방식은 모델을 좁은 workflow에 고정할 수 있다.
반대로 같은 목표를 여러 전략으로 달성한 정답 trajectory를 준비하면, RL이나 preference optimization이 단순 imitation을 넘어 조합적 탐색을 할 수 있다.
물론 한계도 있다.
첫째, 핵심 실험은 수학 reasoning 중심이고, OOD 평가는 HumanEval과 MuSR 일부 task에 한정된다.
둘째, 휴리스틱 설계와 reward-model selection이 pipeline 품질을 크게 좌우한다.
Pólya식 접근이 수학에는 자연스럽지만, 코드 에이전트나 비즈니스 workflow에서는 어떤 “전략 축”을 정의해야 하는지가 별도 연구 문제가 된다.
셋째, pass@k 개선은 sampling budget이 있는 평가에서 특히 잘 드러나므로, 제품의 single-shot latency/cost 환경에서는 다른 trade-off를 봐야 한다.
그럼에도 이 논문은 최근 RLVR 논쟁에서 꽤 좋은 균형점을 제시한다.
RL이 모든 것을 새로 만든다고 과장하지도 않고, RL을 단순 정답 강화로 축소하지도 않는다.
대신 RL이 잘 작동하려면 그 전에 모델이 여러 개의 정답 경로를 확률적으로 가질 수 있게 만드는 데이터 설계가 필요하다고 말한다.
앞으로 reasoning RL의 병목은 optimizer보다, 같은 문제를 얼마나 다양한 “맞는 방식”으로 보여줄 수 있는가에 더 가까워질 수 있다.